Auditing LLMs for Algorithmic Fairness in Casenote-Augmented Tabular Prediction
Pith reviewed 2026-05-10 01:42 UTC · model grok-4.3
The pith
A fine-tuned LLM with casenote summaries improves accuracy and reduces fairness disparities in housing placement predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A fine-tuned model augmented with casenote summaries can improve accuracy while reducing algorithmic fairness disparities in multi-class classification for housing placement, and zero-shot LLM classification does not introduce additional textual biases beyond those in tabular classification.
What carries the argument
The casenote-augmented fine-tuned LLM for tabular classification, audited via multi-class classification error disparities.
Load-bearing premise
The specific casenote data and the multi-class error disparity metric adequately represent real-world fairness concerns in housing placement without unmeasured selection effects or redaction artifacts.
What would settle it
A new dataset of housing placements where applying the fine-tuned casenote-augmented model increases rather than decreases error disparities across groups, or fails to improve accuracy.
Figures
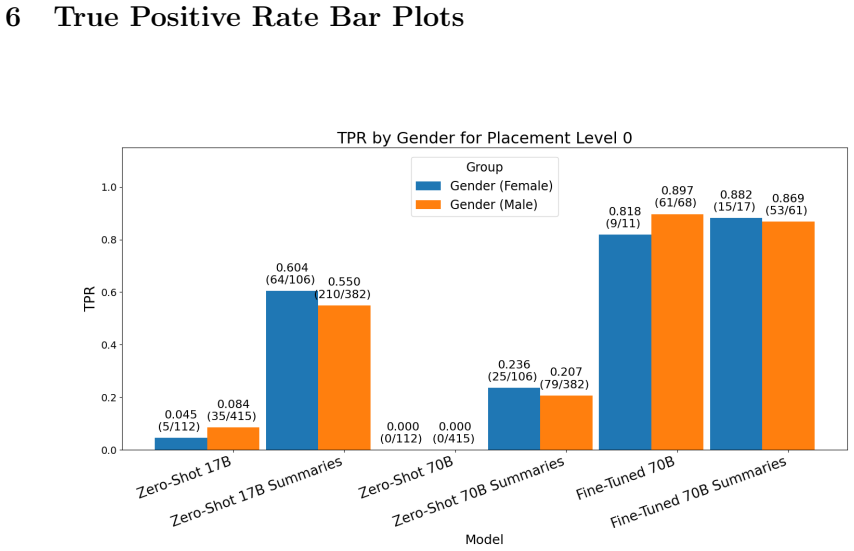
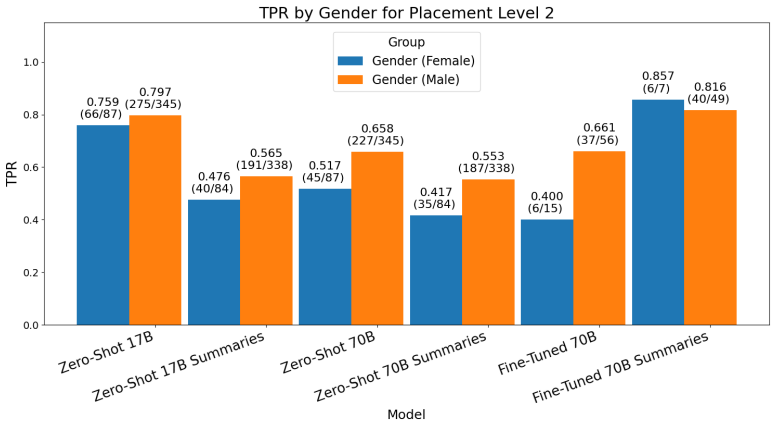








read the original abstract
LLMs are increasingly being considered for prediction tasks in high-stakes social service settings, but their algorithmic fairness properties in this context are poorly understood. In this short technical report, we audit the algorithmic fairness of LLM-based tabular classification on a real housing placement prediction task, augmented with street outreach casenotes from a nonprofit partner. We audit multi-class classification error disparities. We find that a fine-tuned model augmented with casenote summaries can improve accuracy while reducing algorithmic fairness disparities. We experiment with variable importance improvements to zero-shot tabular classification and find mixed results on resulting algorithmic fairness. Overall, given historical inequities in housing placement, it is crucial to audit LLM use. We find that leveraging LLMs to augment tabular classification with casenote summaries can safely leverage additional text information at low implementation burden. The outreach casenotes are fairly short and heavily redacted. Our assessment is that LLM zero-shot classification does not introduce additional textual biases beyond algorithmic biases in tabular classification. Combining fine-tuning and leveraging casenote summaries can improve accuracy and algorithmic fairness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits algorithmic fairness in LLM-augmented tabular classification for a real-world housing placement prediction task using short, heavily redacted street outreach casenotes. The central empirical claim is that fine-tuning an LLM model with casenote summaries improves predictive accuracy while reducing multi-class classification error disparities; zero-shot LLM use with variable importance yields mixed fairness results; and LLM augmentation introduces no additional textual biases beyond those already present in the tabular data.
Significance. If the reported experimental comparisons hold, this short technical report offers timely evidence on the fairness properties of LLMs in high-stakes social-service prediction. It demonstrates a low-implementation-burden approach to incorporating textual casenote information that can simultaneously boost accuracy and mitigate existing group disparities, while explicitly noting data limitations (redaction, brevity) that support the no-new-bias conclusion. Such grounded audits are valuable for informing responsible LLM deployment amid historical housing inequities.
minor comments (3)
- The abstract and results would benefit from explicit reporting of dataset size, number of classes/groups, exact definition of the multi-class error disparity metric, and any statistical tests or error bars accompanying the accuracy and disparity improvements.
- Baseline comparisons with purely tabular (non-LLM) models and with standard fairness-aware tabular methods should be added or clarified to better contextualize the magnitude of the reported gains from casenote augmentation.
- The discussion of casenote redaction and potential selection effects could be expanded with a brief sensitivity analysis or qualitative assessment to strengthen the claim that no additional textual biases are introduced.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our manuscript and for recommending minor revision. We appreciate the recognition that the work provides timely evidence on the fairness properties of LLMs in high-stakes social-service prediction and that our low-implementation-burden approach can boost accuracy while mitigating group disparities.
Circularity Check
No significant circularity
full rationale
The paper is an empirical audit reporting experimental results on LLM-augmented tabular classification for housing placement. The central claim—that fine-tuning with casenote summaries improves accuracy and reduces multi-class error disparities—is presented as a direct observation from model evaluations on the given dataset, not as a derivation, prediction, or quantity obtained by fitting parameters to a subset and then re-using them. No equations, self-definitional loops, uniqueness theorems, or load-bearing self-citations appear in the provided text; the fairness metrics and augmentation procedure are applied as standard evaluation steps without reducing the reported improvements to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Casenotes and tabular features are representative of the underlying population and decision process
- domain assumption Multi-class error disparity is an appropriate proxy for algorithmic fairness in housing placement
Reference graph
Works this paper leans on
-
[1]
Batch-Adaptive Causal Annotations
Batch-Adaptive Annotations for Causal Inference with Complex-Embedded Outcomes , author=. arXiv preprint arXiv:2502.10605 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proceedings of the 38th International Conference on Machine Learning , pages =
Towards Understanding and Mitigating Social Biases in Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.