Collision-Aware Object-Goal Visual Navigation via Two-Stage Deep Reinforcement Learning
Pith reviewed 2026-05-23 02:53 UTC · model grok-4.3
The pith
A two-stage deep reinforcement learning method with a separate collision predictor raises collision-free success rates in object-goal visual navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
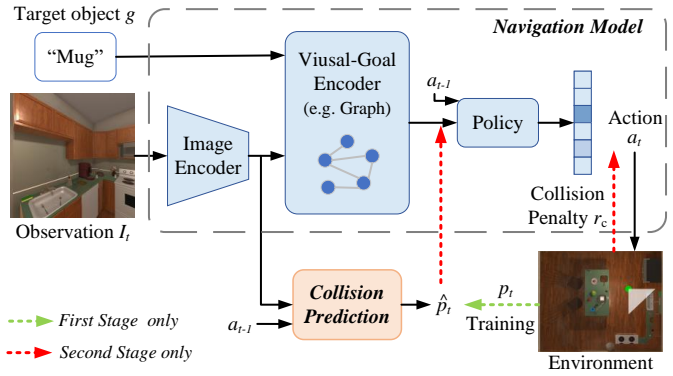
The central claim is that a collision prediction module trained by direct supervision of collision states during exploration can be reused in a second training stage to produce navigation policies that achieve higher collision-free success rate (CF-SR) and collision-free success weighted by path length (CF-SPL) than the same models trained without the module.
What carries the argument
A collision prediction module trained in the first stage by supervising the agent's collision states and then inserted into the second-stage navigation policy to penalize or avoid predicted collisions.
If this is right
- Multiple existing navigation models obtain higher CF-SR and CF-SPL after the two-stage procedure.
- The framework produces policies that generalize from simulation to real-robot object-goal tasks.
- Navigation evaluation now explicitly accounts for collisions rather than treating them as neutral or successful.
- The same collision predictor can be reused across different target objects and starting positions.
Where Pith is reading between the lines
- The separation of collision prediction from navigation might allow the predictor to be swapped for other safety modules without retraining the entire policy.
- The approach could be tested in environments containing moving obstacles to check whether the static collision predictor still suffices.
- If the collision predictor is made probabilistic, the second stage might trade off risk against path length in a more explicit way.
Load-bearing premise
The collision prediction module learned from exploration transfers to the navigation stage and improves collision-free performance without hurting the underlying task success.
What would settle it
Training the same navigation models with and without the collision prediction module in AI2-THOR and finding no statistically significant rise in CF-SR or CF-SPL would falsify the central claim.
Figures



read the original abstract
Object-goal visual navigation aims to reach a specific target object using egocentric visual observations. Recent deep reinforcement learning (DRL) approaches have achieved promising success rates but often neglect collisions during evaluation, limiting real-world deployment. To address this issue, this letter introduces a collision-aware evaluation metric, namely collision-free success rate (CF-SR), to explicitly measure navigation performance under collision constraints. In addition, collision-free success weighted by path length (CF-SPL) is adopted to further evaluate navigation efficiency. Furthermore, a two-stage DRL training framework with collision prediction is proposed to improve collision-free navigation performance. In the first stage, a collision prediction module is trained by supervising the agent's collision states during exploration. In the second stage, leveraging the trained collision prediction, the agent learns to navigate toward target objects while avoiding collision. Extensive experiments across multiple navigation models in the AI2-THOR environment demonstrate consistent improvements in both CF-SR and CF-SPL. Real-world experiments further validate the effectiveness and generalization capability of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces collision-free success rate (CF-SR) and collision-free success weighted by path length (CF-SPL) as evaluation metrics for object-goal visual navigation. It proposes a two-stage DRL framework: stage 1 trains a collision prediction module via supervised learning on collision states collected during exploration; stage 2 uses the trained predictor to guide an agent toward target objects while avoiding collisions. The abstract states that experiments across multiple navigation models in AI2-THOR demonstrate consistent improvements in the new metrics, with real-world experiments validating generalization and effectiveness.
Significance. If the transfer of the collision predictor is shown to be effective and the reported gains are causally attributable to it rather than other training changes, the work would usefully address a practical gap in visual navigation by making collision avoidance explicit in both training and evaluation. The new metrics provide a clearer signal for real-world applicability than standard SR/SPL. The two-stage separation is a pragmatic design choice that avoids requiring collision signals in the primary task reward.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent improvements in both CF-SR and CF-SPL' across models and 'real-world experiments further validate' is presented without any quantitative values, baseline comparisons, number of models, ablation results, or statistical details. This absence prevents verification that the two-stage collision-prediction approach is the driver of the gains.
- [Method (two-stage DRL training framework)] Two-stage framework description: the transfer assumption—that the collision predictor trained on exploration trajectories generalizes to the learned navigation policy without introducing false positives/negatives or degrading task performance—is load-bearing for the contribution but receives no isolated validation, out-of-distribution tests, or integration details (reward shaping, input concatenation, or constraint). If exploration and navigation state distributions differ in velocity or interaction patterns, the predictor may not function as intended.
minor comments (1)
- [Abstract] Abstract: clarify whether CF-SR is simply the success rate computed only over collision-free episodes or a distinct formulation; the current phrasing 'collision-aware evaluation metric' is ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvements in both CF-SR and CF-SPL' across models and 'real-world experiments further validate' is presented without any quantitative values, baseline comparisons, number of models, ablation results, or statistical details. This absence prevents verification that the two-stage collision-prediction approach is the driver of the gains.
Authors: We agree that the abstract would be strengthened by including key quantitative details. The experiments section provides these (results across multiple models with reported gains in CF-SR and CF-SPL, plus real-world validation), but we will revise the abstract to incorporate representative values and the number of models tested while respecting length limits. revision: yes
-
Referee: [Method (two-stage DRL training framework)] Two-stage framework description: the transfer assumption—that the collision predictor trained on exploration trajectories generalizes to the learned navigation policy without introducing false positives/negatives or degrading task performance—is load-bearing for the contribution but receives no isolated validation, out-of-distribution tests, or integration details (reward shaping, input concatenation, or constraint). If exploration and navigation state distributions differ in velocity or interaction patterns, the predictor may not function as intended.
Authors: Section 3 describes the integration: the predictor output is concatenated with visual features for the policy and used in reward shaping via collision penalties. Overall system results support effectiveness, but we acknowledge the lack of isolated predictor validation or explicit OOD tests on navigation states. We will add an ablation isolating predictor accuracy and transfer performance in the revision. revision: yes
Circularity Check
Two-stage DRL training and metrics are independent; no reduction to inputs by construction
full rationale
The paper defines a two-stage process in which a collision prediction module is first trained via supervision on exploration collision states, then incorporated into a second-stage RL policy for goal-directed navigation. The new metrics CF-SR and CF-SPL are defined directly from success and path length under an explicit collision constraint and are not algebraically or statistically forced by the training procedure. No equations appear that equate a reported gain to a fitted parameter or prior output by construction. No self-citation is used to import a uniqueness theorem or ansatz that would render the central claim tautological. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Collision states during exploration can be directly supervised to train a reliable prediction module.
Reference graph
Works this paper leans on
-
[1]
Learning to learn how to learn: Self-adaptive visual navigation using meta-learning,
M. Wortsman, K. Ehsani, M. Rastegari, A. Farhadi, and R. Mottaghi, “Learning to learn how to learn: Self-adaptive visual navigation using meta-learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2019, pp. 6743–6752
work page 2019
-
[2]
VTNet: Visual transformer network for object goal navigation,
H. Du, X. Yu, and L. Zheng, “VTNet: Visual transformer network for object goal navigation,” in Proc. Int. Conf. Learn. Representations , 2021, pp. 1–16
work page 2021
-
[3]
Object memory transformer for object goal navigation,
R. Fukushima, K. Ota, A. Kanezaki, Y . Sasaki, and Y . Yoshiyasu, “Object memory transformer for object goal navigation,” in Proc. Int. Conf. Robot. Automat. , 2022, pp. 11 288–11 294
work page 2022
-
[4]
Learning object relation graph and tentative policy for visual navigation,
H. Du, X. Yu, and L. Zheng, “Learning object relation graph and tentative policy for visual navigation,” in Proc. Eur . Conf. Comput. Vision, 2020, pp. 19–34
work page 2020
-
[5]
Hierarchical object-to-zone graph for object navigation,
S. Zhang, X. Song, Y . Bai, W. Li, Y . Chu, and S. Jiang, “Hierarchical object-to-zone graph for object navigation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. , 2021, pp. 15 110–15 120
work page 2021
-
[6]
Aligning knowledge graph with visual perception for object-goal navigation,
N. Xu, W. Wang, R. Yang, M. Qin, Z. Lin, W. Song, C. Zhang, J. Gu, and C. Li, “Aligning knowledge graph with visual perception for object-goal navigation,” in IEEE Int. Conf. Robot. Automat. , 2024, pp. 5214–5220
work page 2024
-
[7]
Learning hierarchical relationships for object-goal navigation,
A. Pal, Y . Qiu, and H. Christensen, “Learning hierarchical relationships for object-goal navigation,” in Proc. Conf. Robot Learn. , vol. 155, 2021, pp. 517–528
work page 2021
-
[8]
Visual object search by learning spatial context,
R. Druon, Y . Yoshiyasu, A. Kanezaki, and A. Watt, “Visual object search by learning spatial context,” IEEE Robot. Automat. Lett. , vol. 5, no. 2, pp. 1279–1286, 2020
work page 2020
-
[9]
Tdanet: Target-directed attention network for object-goal visual navigation with zero-shot ability,
S. Lian and F. Zhang, “Tdanet: Target-directed attention network for object-goal visual navigation with zero-shot ability,” IEEE Robot. Automat. Lett. , vol. 9, no. 9, pp. 8075–8082, 2024
work page 2024
-
[10]
Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song, “Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 23 171–23 181
work page 2023
-
[11]
M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y . Min, K. Shah, C. Paxton, S. Gupta, D. Batra, R. Mottaghi, J. Malik, and D. S. Chaplot, “Goat: Go to any thing,” 2023, arXiv:2311.06430
-
[12]
V oronav: V oronoi-based zero-shot object navigation with large lan- guage model,
P. Wu, Y . Mu, B. Wu, Y . Hou, J. Ma, S. Zhang, and C. Liu, “V oronav: V oronoi-based zero-shot object navigation with large lan- guage model,” in Proc. Int. Conf. Mach. Learn. , 2024. [Online]. Available: https://openreview.net/forum?id=Va7mhTVy5s
work page 2024
-
[13]
Zero-shot object goal visual navigation,
Q. Zhao, L. Zhang, B. He, H. Qiao, and Z. Liu, “Zero-shot object goal visual navigation,” in Proc. IEEE Int. Conf. Robot. Automat. , 2023, pp. 2025–2031
work page 2023
-
[14]
F.-F. Li, C. Guo, H. Zhang, and B. Luo, “Context vector-based visual mapless navigation in indoor using hierarchical semantic information and meta-learning,” Complex Intell. Syst., vol. 9, pp. 2031–2041, 2022
work page 2031
-
[15]
Layout- based causal inference for object navigation,
S. Zhang, X. Song, W. Li, Y . Bai, X. Yu, and S. Jiang, “Layout- based causal inference for object navigation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. , 2023, pp. 10 792–10 802
work page 2023
-
[16]
Visual navigation with spatial attention,
B. Mayo, T. Hazan, and A. Tal, “Visual navigation with spatial attention,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. , 2021, pp. 16 893–16 902
work page 2021
-
[17]
Towards generalization in target-driven visual navigation by using deep reinforcement learning,
A. Devo, G. Mezzetti, G. Costante, M. L. Fravolini, and P. Valigi, “Towards generalization in target-driven visual navigation by using deep reinforcement learning,” IEEE Trans. Robot. , vol. 36, no. 5, pp. 1546–1561, 2020
work page 2020
-
[18]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Advances Neural Inf. Process. Syst. , 2017, pp. 6000–6010
work page 2017
-
[19]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” in Proc. Int. Conf. Mach. Learn. , vol. 139, 2021, pp. 8748–8763
work page 2021
-
[20]
Visual navi- gation for biped humanoid robots using deep reinforcement learning,
K. Lobos-Tsunekawa, F. Leiva, and J. Ruiz-del Solar, “Visual navi- gation for biped humanoid robots using deep reinforcement learning,” IEEE Robot. Automat. Lett. , vol. 3, no. 4, pp. 3247–3254, 2018
work page 2018
-
[21]
DRQN-based 3D obstacle avoidance with a limited field of view,
Y . Chen, G. Chen, L. Pan, J. Ma, Y . Zhang, Y . Zhang, and J. Ji, “DRQN-based 3D obstacle avoidance with a limited field of view,” in IEEE/RSJ Int. Conf. Intell. Robots Syst. , 2021, pp. 8137–8143
work page 2021
-
[22]
Multigoal visual navigation with collision avoidance via deep reinforcement learning,
W. Xiao, L. Yuan, L. He, T. Ran, J. Zhang, and J. Cui, “Multigoal visual navigation with collision avoidance via deep reinforcement learning,” IEEE Trans. Instrum. Meas. , vol. 71, pp. 1–9, 2022
work page 2022
-
[23]
Towards target-driven visual navigation in indoor scenes via generative imita- tion learning,
Q. Wu, X. Gong, K. Xu, D. Manocha, J. Dong, and J. Wang, “Towards target-driven visual navigation in indoor scenes via generative imita- tion learning,” IEEE Robot. Automat. Lett. , vol. 6, no. 1, pp. 175–182, 2021
work page 2021
-
[24]
Asynchronous methods for deep reinforcement learning,
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in Proc. Int. Conf. Mach. Learn. , vol. 48, 2016, pp. 1928–1937
work page 2016
-
[25]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y . Zhu, A. Kembhavi, A. K. Gupta, and A. Farhadi, “Ai2-thor: An interactive 3d environment for visual ai,” 2017, arXiv:1712.05474
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
On Evaluation of Embodied Navigation Agents
P. Anderson, A. X. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva, and A. Zamir, “On evaluation of embodied navigation agents,” 2018, arXiv:1807.06757
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Target-driven visual navigation in indoor scenes using deep reinforcement learning,
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in Proc. IEEE Int. Conf. Robot. Automat., 2017, pp. 3357–3364
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.