Judge a Book by its Cover: Investigating Multi-Modal LLMs for Multi-Page Handwritten Document Transcription
Pith reviewed 2026-05-23 01:59 UTC · model grok-4.3
The pith
New prompting strategies let multi-modal LLMs transcribe multi-page handwritten documents by sharing context across pages without added complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that OCR+PAGE-1 and OCR+PAGE-N prompting strategies enable multi-modal LLMs to achieve higher accuracy on multi-page handwritten transcription tasks by selectively incorporating shared content from earlier pages, while avoiding the prompt overload that comes from simply concatenating all prior text.
What carries the argument
OCR+PAGE-1 and OCR+PAGE-N prompting strategies, which combine OCR output with selective reuse of prior-page context inside MLLM prompts to carry semantic and stylistic information forward without full document concatenation.
If this is right
- Multi-page documents can be transcribed more accurately in zero-shot settings without retraining models on new labeled sets.
- Prompt length stays manageable even as page count grows, because only targeted prior content is reused.
- The same strategies can be applied to other MLLM tasks that involve sequential or related inputs.
- Benchmarks built from single-page datasets become usable for evaluating multi-page performance.
- Combining OCR with selective MLLM prompting outperforms both pure OCR post-processing and pure image-based MLLM transcription.
Where Pith is reading between the lines
- The approach could reduce the need for page-by-page manual correction in archives of long handwritten records.
- It may generalize to tasks such as multi-page form filling or table extraction where style and content persist across pages.
- If the strategies scale, they might lower the cost of digitizing historical collections that currently require extensive fine-tuning.
- Testing on documents with varying handwriting consistency would reveal how much the shared-context benefit depends on document uniformity.
Load-bearing premise
That adding shared context from prior pages through these prompts will raise transcription accuracy on actual multi-page documents rather than triggering overload, dilution, or extra hallucinations.
What would settle it
A controlled test on real multi-page handwritten documents showing no accuracy gain or a drop when using OCR+PAGE-1 or OCR+PAGE-N compared with single-page OCR-plus-LLM baselines.
Figures










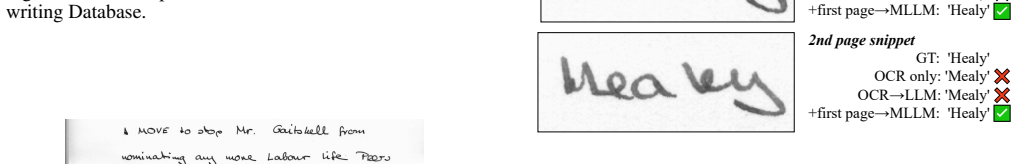


read the original abstract
Handwriting text recognition (HTR) remains a challenging task. Existing approaches require fine-tuning on labeled data, which is impractical to obtain for real-world problems, or rely on zero-shot tools such as OCR engines and multi-modal LLMs (MLLMs). MLLMs have shown promise both as end-to-end transcribers and as OCR post-processors, but to date there is little empirical research evaluating different MLLM prompting strategies for HTR, particularly for the case of multi-page documents. Most handwritten documents are multi-page, and share context such as semantic content and handwriting style across pages, yet MLLMs are typically used for transcription at the page level, meaning they throw away this shared context. They are also typically used as either text-only post-processors or image-only OCR alternatives, rather than leveraging multiple modes. This paper investigates a suite of methods combining OCR, LLM post-processing and MLLM end-to-end transcription, for the task of zero-shot multi-page handwritten document transcription. We introduce a benchmark for this task from existing single-page datasets, including a new dataset, Malvern-Hills. Finally, we introduce OCR+PAGE-1 and OCR+PAGE-N, prompting strategies for multi-page transcription that outperform existing methods by sharing content across pages while minimizing prompt complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates zero-shot multi-page handwritten document transcription using multi-modal LLMs (MLLMs). It argues that page-level usage of MLLMs discards shared context such as semantic content and handwriting style across pages in real multi-page documents. The authors construct a benchmark by combining existing single-page datasets with a new Malvern-Hills dataset, and introduce two prompting strategies (OCR+PAGE-1 and OCR+PAGE-N) that share context across pages while limiting prompt length. They evaluate combinations of OCR, LLM post-processing, and MLLM end-to-end transcription, claiming the new strategies outperform prior approaches.
Significance. If the results are robust, the work offers practical guidance on leveraging shared document context in MLLM prompting for HTR without fine-tuning, addressing a gap in handling authentic multi-page documents. The new Malvern-Hills dataset and multi-page benchmark constitute a concrete contribution that could support future research in zero-shot document transcription.
major comments (2)
- [Benchmark Construction] Benchmark section: The benchmark is assembled from existing single-page datasets. No details are provided on whether concatenated pages preserve consistent author style, topic continuity, or layout. This is load-bearing for the central claim, as the reported gains of OCR+PAGE-1 and OCR+PAGE-N are attributed to exploiting shared cross-page context; an artificial construction risks measuring artifacts rather than genuine multi-page benefits.
- [Experiments] Experimental evaluation: The abstract asserts outperformance by the proposed strategies, yet the manuscript must include explicit quantitative comparisons (e.g., CER/WER tables against page-level baselines) with error analysis to confirm that gains arise from context sharing rather than other factors.
minor comments (2)
- [Abstract] Abstract: The claim of outperformance should be accompanied by at least one concrete metric or baseline comparison to orient readers.
- [Methods] Methods: Provide precise prompt templates or pseudocode for OCR+PAGE-1 versus OCR+PAGE-N to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of benchmark construction and experimental reporting. We address each major comment below and will revise the manuscript to incorporate additional details and explicit comparisons.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark section: The benchmark is assembled from existing single-page datasets. No details are provided on whether concatenated pages preserve consistent author style, topic continuity, or layout. This is load-bearing for the central claim, as the reported gains of OCR+PAGE-1 and OCR+PAGE-N are attributed to exploiting shared cross-page context; an artificial construction risks measuring artifacts rather than genuine multi-page benefits.
Authors: We agree that the manuscript should provide more explicit details on benchmark construction. The existing single-page datasets were grouped by original document source where metadata permitted, and the new Malvern-Hills dataset comprises authentic multi-page handwritten documents. We will add a dedicated subsection describing the concatenation procedure, any available metadata on author and topic continuity, and a discussion of limitations arising from the use of single-page sources. revision: yes
-
Referee: [Experiments] Experimental evaluation: The abstract asserts outperformance by the proposed strategies, yet the manuscript must include explicit quantitative comparisons (e.g., CER/WER tables against page-level baselines) with error analysis to confirm that gains arise from context sharing rather than other factors.
Authors: We acknowledge that the experimental results section would be strengthened by expanded quantitative tables and error analysis. The manuscript already reports CER/WER metrics for the proposed strategies versus baselines, but we will add comprehensive side-by-side tables, statistical significance tests, and a dedicated error analysis subsection that examines whether improvements correlate with cross-page context sharing. revision: yes
Circularity Check
No circularity: purely empirical prompting comparison with no derivation chain
full rationale
The paper introduces OCR+PAGE-1 and OCR+PAGE-N prompting strategies and evaluates them empirically against baselines on a benchmark assembled from single-page datasets plus Malvern-Hills. No equations, fitted parameters, uniqueness theorems, or self-citations are used to derive results; performance claims rest on direct measurement of transcription accuracy. The central claims do not reduce to inputs by construction, satisfying the self-contained empirical case (score 0-2).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F. L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Azawi, M. A.; Afzal, M. Z.; and Breuel, T. M. 2013. Normalizing historical orthography for OCR historical documents using LSTM. In Proceedings of the 2nd International Workshop on Historical Document Imaging and Processing, 80--85
work page 2013
-
[5]
B.; Daimary, D.; Amitab, K.; and Kandar, D
Bora, M. B.; Daimary, D.; Amitab, K.; and Kandar, D. 2020. Handwritten character recognition from images using CNN-ECOC. Procedia Computer Science, 167: 2403--2409
work page 2020
-
[6]
Breuel, T. M.; Ul-Hasan, A.; Al-Azawi, M. A.; and Shafait, F. 2013. High-performance OCR for printed English and Fraktur using LSTM networks. In 2013 12th international conference on document analysis and recognition, 683--687. IEEE
work page 2013
-
[7]
Carbonell, M.; Mas, J.; Villegas, M.; Forn \'e s, A.; and Llad \'o s, J. 2019. End-to-end handwritten text detection and transcription in full pages. In 2019 International conference on document analysis and recognition workshops (ICDARW), volume 5, 29--34. IEEE
work page 2019
-
[8]
Causer, T.; Grint, K.; Sichani, A.-M.; and Terras, M. 2018. ‘Making such bargain’: Transcribe Bentham and the quality and cost-effectiveness of crowdsourced transcription. Digital Scholarship in the Humanities, 33(3): 467--487
work page 2018
- [9]
-
[10]
Devlin, J. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Diem, M.; Fiel, S.; Kleber, F.; Sablatnig, R.; Saavedra, J. M.; Contreras, D.; Barrios, J. M.; and Oliveira, L. S. 2014. ICFHR 2014 competition on handwritten digit string recognition in challenging datasets (HDSRC 2014). In 2014 14th International Conference on Frontiers in Handwriting Recognition, 779--784. IEEE
work page 2014
-
[12]
Dolfing, H. J.; Bellegarda, J.; Chorowski, J.; Marxer, R.; and Laurent, A. 2020. The “ScribbleLens” Dutch historical handwriting corpus. In 2020 17th international conference on frontiers in handwriting recognition (ICFHR), 67--72. IEEE
work page 2020
-
[13]
Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Ma, J.; Li, R.; Xia, H.; Xu, J.; Wu, Z.; Liu, T.; et al. 2022. A survey on in-context learning. arXiv preprint arXiv:2301.00234
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Dosovitskiy, A. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Floridi, L.; and Chiriatti, M. 2020. GPT-3: Its nature, scope, limits, and consequences. Minds and Machines, 30: 681--694
work page 2020
-
[16]
Fujitake, M. 2024. Dtrocr: Decoder-only transformer for optical character recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 8025--8035
work page 2024
- [17]
-
[18]
Huang, Y.; Lv, T.; Cui, L.; Lu, Y.; and Wei, F. 2022. Layoutlmv3: Pre-training for document ai with unified text and image masking. In Proceedings of the 30th ACM International Conference on Multimedia, 4083--4091
work page 2022
-
[19]
Huang, Z.; Chen, K.; He, J.; Bai, X.; Karatzas, D.; Lu, S.; and Jawahar, C. 2019. Icdar2019 competition on scanned receipt ocr and information extraction. In 2019 International Conference on Document Analysis and Recognition (ICDAR), 1516--1520. IEEE
work page 2019
- [20]
- [21]
- [22]
-
[23]
Li, M.; Lv, T.; Chen, J.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; and Wei, F. 2023. Trocr: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 13094--13102
work page 2023
-
[24]
F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; and Liang, P
Liu, N. F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; and Liang, P. 2024. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12: 157--173
work page 2024
-
[25]
Liu, Y. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 364
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Liu, Y.; Li, Z.; Yang, B.; Li, C.; Yin, X.; Liu, C.-l.; Jin, L.; and Bai, X. 2023. On the hidden mystery of ocr in large multimodal models. arXiv preprint arXiv:2305.07895
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, 10012--10022
work page 2021
-
[28]
Lund, W. B.; Walker, D. D.; and Ringger, E. K. 2011. Progressive alignment and discriminative error correction for multiple OCR engines. In 2011 International Conference on Document Analysis and Recognition, 764--768. IEEE
work page 2011
-
[29]
Marti, U.-V.; and Bunke, H. 2002. The IAM-database: an English sentence database for offline handwriting recognition. International journal on document analysis and recognition, 5: 39--46
work page 2002
-
[30]
Morris, A. C.; Maier, V.; and Green, P. D. 2004. From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition. In Interspeech, 2765--2768
work page 2004
-
[31]
Park, S.; Shin, S.; Lee, B.; Lee, J.; Surh, J.; Seo, M.; and Lee, H. 2019. CORD: a consolidated receipt dataset for post-OCR parsing. In Workshop on Document Intelligence at NeurIPS 2019
work page 2019
- [32]
-
[33]
Rigaud, C.; Doucet, A.; Coustaty, M.; and Moreux, J.-P. 2019. ICDAR 2019 competition on post-OCR text correction. In 2019 international conference on document analysis and recognition (ICDAR), 1588--1593. IEEE
work page 2019
-
[34]
S \'a nchez, J. A.; Romero, V.; Toselli, A. H.; Villegas, M.; and Vidal, E. 2019. A set of benchmarks for handwritten text recognition on historical documents. Pattern Recognition, 94: 122--134
work page 2019
-
[35]
Schaefer, R.; and Neudecker, C. 2020. A two-step approach for automatic OCR post-correction. In Proceedings of the 4th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, 52--57
work page 2020
-
[36]
Schick, T.; Dwivedi-Yu, J.; Dess \` , R.; Raileanu, R.; Lomeli, M.; Hambro, E.; Zettlemoyer, L.; Cancedda, N.; and Scialom, T. 2024. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36
work page 2024
-
[37]
Serrano, N.; Castro, F.; and Juan, A. 2010. The RODRIGO Database. In LREC, 19--21
work page 2010
- [38]
-
[39]
Stanis awek, T.; Grali \'n ski, F.; Wr \'o blewska, A.; Lipi \'n ski, D.; Kaliska, A.; Rosalska, P.; Topolski, B.; and Biecek, P. 2021. Kleister: key information extraction datasets involving long documents with complex layouts. In International Conference on Document Analysis and Recognition, 564--579. Springer
work page 2021
-
[40]
Vaswani, A. 2017. Attention is all you need. arXiv preprint arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Veninga, M. 2024. LLMs for OCR Post-Correction. Master's thesis, University of Twente
work page 2024
-
[42]
Wigington, C.; Tensmeyer, C.; Davis, B.; Barrett, W.; Price, B.; and Cohen, S. 2018. Start, follow, read: End-to-end full-page handwriting recognition. In Proceedings of the European conference on computer vision (ECCV), 367--383
work page 2018
-
[43]
Wu, D.; Ahmad, W. U.; Zhang, D.; Ramanathan, M. K.; and Ma, X. 2024. REPOFORMER: Selective retrieval for repository-level code completion. arXiv preprint arXiv:2403.10059
-
[44]
Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; and Zhou, M. 2020. Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 1192--1200
work page 2020
-
[45]
Yang, J.; Ren, P.; and Kong, X. 2019. Handwriting text recognition based on faster R-CNN. In 2019 Chinese Automation Congress (CAC), 2450--2454. IEEE
work page 2019
-
[46]
Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; and Chen, E. 2024. A survey on multimodal large language models. National Science Review, nwae403
work page 2024
- [47]
-
[48]
Yuan, Y.; Liu, X.; Dikubab, W.; Liu, H.; Ji, Z.; Wu, Z.; and Bai, X. 2022. Syntax-aware network for handwritten mathematical expression recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4553--4562
work page 2022
-
[49]
Zhang, R.; Zhou, Y.; Jiang, Q.; Song, Q.; Li, N.; Zhou, K.; Wang, L.; Wang, D.; Liao, M.; Yang, M.; et al. 2019. Icdar 2019 robust reading challenge on reading chinese text on signboard. In 2019 international conference on document analysis and recognition (ICDAR), 1577--1581. IEEE
work page 2019
-
[50]
A Survey of Large Language Models
Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.