Exposing the Ghost in the Transformer: Abnormal Detection for Large Language Models via Hidden State Forensics
Pith reviewed 2026-05-22 22:24 UTC · model grok-4.3
The pith
Inspecting layer-specific activation patterns in LLMs detects hallucinations, jailbreaks, and backdoors in real time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
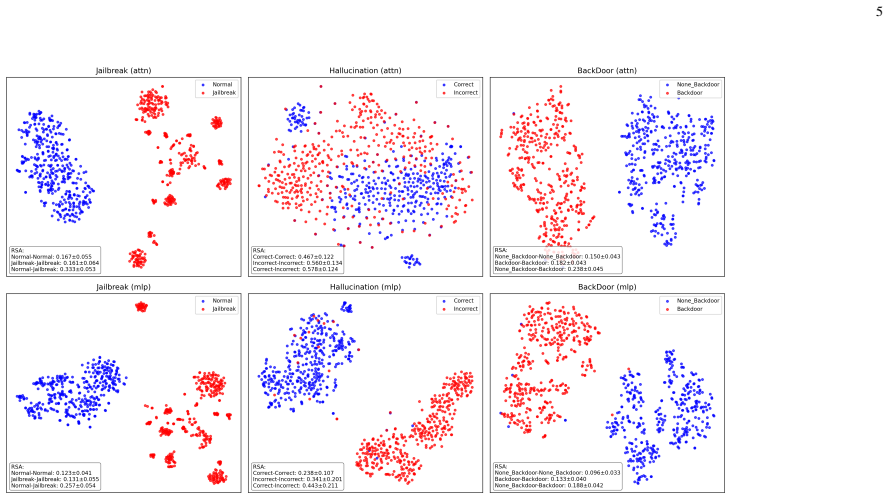
By systematically inspecting layer-specific activation patterns, a general framework can efficiently identify a range of security threats in real-time without imposing prohibitive computational costs, with experiments showing detection accuracies exceeding 95 percent, robust performance across multiple models, and effective detection of novel attacks.
What carries the argument
Layer-specific hidden state activation patterns examined for distinguishable signatures of threats.
If this is right
- Detection accuracies exceed 95 percent across tested scenarios.
- Performance stays robust on multiple different LLMs without per-model adjustments.
- Inference overhead stays minimal, completing in fractions of a second.
- Novel attacks remain detectable without additional tuning.
- The same signals can support subsequent mitigation of detected abnormal behaviors.
Where Pith is reading between the lines
- The method could be added as a lightweight sidecar process to existing LLM inference servers for continuous monitoring.
- Similar layer-wise analysis might apply to detecting other anomalies such as prompt injection or data leakage not tested here.
- If the patterns prove architecture-agnostic, the approach could transfer to smaller or fine-tuned variants with minimal adaptation.
Load-bearing premise
Layer-specific hidden state activation patterns contain distinguishable, generalizable signatures for hallucinations, jailbreaks, and backdoors that remain detectable across different model architectures and for novel attacks without retraining.
What would settle it
Running the detector on a new model architecture with an unseen attack type and obtaining accuracy below 80 percent or requiring architecture-specific retraining.
Figures




read the original abstract
The widespread adoption of Large Language Models (LLMs) in critical applications has introduced severe reliability and security risks, as LLMs remain vulnerable to notorious threats such as hallucinations, jailbreak attacks, and backdoor exploits. These vulnerabilities have been weaponized by malicious actors, leading to unauthorized access, widespread misinformation, and compromised LLM-embedded system integrity. In this work, we introduce a novel approach to detecting abnormal behaviors in LLMs via hidden state forensics. By systematically inspecting layer-specific activation patterns, we develop a general framework that can efficiently identify a range of security threats in real-time without imposing prohibitive computational costs. Extensive experiments indicate detection accuracies exceeding 95% and consistently robust performance across multiple models in most scenarios, while preserving the ability to detect novel attacks effectively. Furthermore, the computational overhead remains minimal, with detector inference taking merely fractions of a second. The significance of this work lies in proposing a promising strategy to reinforce the security of LLM-integrated systems, paving the way for safer and more reliable deployment in high-stakes domains. By enabling real-time detection that can also support the mitigation of abnormal behaviors, it represents a meaningful step toward ensuring the trustworthiness of AI systems amid rising security challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a framework for detecting security threats in LLMs (hallucinations, jailbreaks, backdoors) by analyzing layer-specific hidden state activation patterns. It claims real-time identification of these threats with >95% accuracy, robustness across models, minimal overhead (fractions of a second inference), and the ability to detect novel attacks effectively without prohibitive costs or model-specific retraining.
Significance. If substantiated, the approach would offer a practical, low-overhead method for real-time threat detection in LLM systems, addressing a pressing need in AI security. The core idea of using hidden-state forensics for multiple threat types in a general framework has potential impact if the transferability claims are validated.
major comments (2)
- [Abstract] Abstract: The central claim that the method 'detect[s] novel attacks effectively' without retraining or tuning is load-bearing for the generality assertion, yet the reported experiments use only held-out examples from the same attack distributions; no zero-shot results on new attack families (e.g., unseen jailbreak templates or backdoor triggers) are described.
- [Experimental section] Experimental section: Assertions of accuracies exceeding 95% and 'consistently robust performance across multiple models in most scenarios' are presented without baselines, error analysis, dataset descriptions, or statistical details, preventing verification that the data support the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] The central claim that the method 'detect[s] novel attacks effectively' without retraining or tuning is load-bearing for the generality assertion, yet the reported experiments use only held-out examples from the same attack distributions; no zero-shot results on new attack families (e.g., unseen jailbreak templates or backdoor triggers) are described.
Authors: We acknowledge the distinction. Our experiments evaluate generalization to held-out instances drawn from the same attack distributions (e.g., unseen jailbreak prompts within the same template families and backdoor triggers from the same generation process). The manuscript uses 'novel attacks' to refer to these unseen instances rather than entirely new attack families. We will revise the abstract and discussion sections to clarify this scope and explicitly note the absence of zero-shot evaluation on new attack families as a limitation. revision: partial
-
Referee: [Experimental section] Assertions of accuracies exceeding 95% and 'consistently robust performance across multiple models in most scenarios' are presented without baselines, error analysis, dataset descriptions, or statistical details, preventing verification that the data support the claims.
Authors: We agree that additional experimental details are needed for verifiability. The revised manuscript will add baseline comparisons against existing detection methods, error analysis (including false-positive/negative breakdowns), complete dataset descriptions with sizes and sources, and statistical details such as standard deviations or significance tests supporting the >95% accuracy and cross-model robustness claims. revision: yes
Circularity Check
No derivation chain or fitted predictions; purely empirical framework with no self-referential reductions
full rationale
The paper presents an empirical detection framework based on inspecting layer-specific activation patterns, with claims supported by experimental accuracies (>95%) across models. No equations, parameter fittings, derivations, or mathematical predictions are described in the provided text. No self-citations are invoked as load-bearing for uniqueness theorems or ansatzes. The central claims rest on experimental results rather than any chain that reduces to its own inputs by construction, making the work self-contained against external benchmarks with no identifiable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Intellicode compose: code generation using transformer,
A. Svyatkovskiy, S. K. Deng, S. Fu, and N. Sundaresan, “Intellicode compose: code generation using transformer,” inESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, November 8-13, 2020, P. Devanbu, M. B. Cohen, and T. Zimmermann, Eds. ACM, 2020, pp. 1433–1443...
-
[2]
Healai: A healthcare LLM for effective medical documentation,
S. Goyal, E. Rastogi, S. P. Rajagopal, D. Yuan, F. Zhao, J. Chintagunta, G. Naik, and J. Ward, “Healai: A healthcare LLM for effective medical documentation,” inProceedings of the 17th ACM International Conference on Web Search and Data Mining, WSDM 2024, Merida, Mexico, March 4-8, 2024, L. A. Caudillo- Mata, S. Lattanzi, A. M. Medina, L. Akoglu, A. Gioni...
-
[3]
Large language models in finance: A survey,
Y . Li, S. Wang, H. Ding, and H. Chen, “Large language models in finance: A survey,” in4th ACM International Conference on AI in Finance, ICAIF 2023, Brooklyn, NY, USA, November 27-29, 2023. ACM, 2023, pp. 374–382. [Online]. Available: https://doi.org/10.1145/3604237.3626869
-
[4]
When llms meet cybersecurity: A systematic literature review,
J. Zhang, H. Bu, H. Wen, Y . Chen, L. Li, and H. Zhu, “When llms meet cybersecurity: A systematic literature review,”CoRR, vol. abs/2405.03644, 2024. [Online]. Available: https://doi.org/10.48550/ arXiv.2405.03644
-
[5]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Trans. Inf. Syst., Nov. 2024, just Accepted. [Online]. Available: https://doi.org/10.1145/3703155
-
[6]
A comprehensive study of jailbreak attack versus defense for large language models,
Z. Xu, Y . Liu, G. Deng, Y . Li, and S. Picek, “A comprehensive study of jailbreak attack versus defense for large language models,” inFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, L. Ku, A. Martins, and V . Srikumar, Eds. Association for Computational Linguistics, 2024, pp....
-
[7]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024
work page 2024
-
[8]
Baseline defenses for adversarial attacks against aligned language models,
N. Jain, A. Schwarzschild, Y . Wen, G. Somepalli, J. Kirchenbauer, P. yeh Chiang, M. Goldblum, A. Saha, J. Geiping, and T. Goldstein, “Baseline defenses for adversarial attacks against aligned language models,” 2023
work page 2023
-
[9]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “”do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, CCS 2024, Salt Lake City, UT, USA, October 14-18, 2024, B. Luo, X. Liao, J. Xu, E. Kirda, and D. Lie, Ed...
-
[10]
A systematic review of poisoning attacks against large language models,
N. Fendley, E. W. Staley, J. Carney, W. Redman, M. Chau, and N. Drenkow, “A systematic review of poisoning attacks against large language models,”CoRR, vol. abs/2506.06518, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.06518
-
[11]
Large legal fictions: Profiling legal hallucinations in large language models,
M. Dahl, V . Magesh, M. Suzgun, and D. E. Ho, “Large legal fictions: Profiling legal hallucinations in large language models,”CoRR, vol. abs/2401.01301, 2024. [Online]. Available: https://doi.org/10.48550/ arXiv.2401.01301
-
[12]
J. Vladika, A. Domres, M. Nguyen, R. Moser, J. Nano, F. Busch, L. C. Adams, K. K. Bressem, D. Bernhardt, S. E. Combs, K. J. Borm, F. Matthes, and J. C. Peeken, “Improving reliability and explainability of medical question answering through atomic fact checking in retrieval-augmented llms,”CoRR, vol. abs/2505.24830, 2025. [Online]. Available: https://doi.o...
-
[13]
S. Zhou, T. Li, K. Wang, Y . Huang, L. Shi, Y . Liu, and H. Wang, “Understanding the effectiveness of coverage criteria for large language models: A special angle from jailbreak attacks,” 2025. [Online]. Available: https://arxiv.org/abs/2408.15207
-
[14]
Deepxplore: Automated whitebox testing of deep learning systems,
K. Pei, Y . Cao, J. Yang, and S. Jana, “Deepxplore: Automated whitebox testing of deep learning systems,” inProceedings of the 26th Symposium on Operating Systems Principles, ser. SOSP ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 1–18. [Online]. Available: https://doi.org/10.1145/3132747.3132785
-
[15]
Deepgauge: multi-granularity testing criteria for deep learning systems,
L. Ma, F. Juefei-Xu, F. Zhang, J. Sun, M. Xue, B. Li, C. Chen, T. Su, L. Li, Y . Liu, J. Zhao, and Y . Wang, “Deepgauge: multi-granularity testing criteria for deep learning systems,” inProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, ser. ASE ’18. New York, NY , USA: Association for Computing Machinery, 2018, p...
-
[16]
Code coverage and test suite effectiveness: Empirical study with real bugs in large systems,
P. S. Kochhar, F. Thung, and D. Lo, “Code coverage and test suite effectiveness: Empirical study with real bugs in large systems,” in2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER), 2015, pp. 560–564. 16
work page 2015
-
[17]
Llama: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” 2023
work page 2023
-
[18]
AI@Meta, “Llama 3 model card,” 2024, accessed: 2025-1-7. [Online]. Available: https://github.com/meta-llama/llama3/blob/main/ MODEL CARD.md
work page 2024
-
[19]
Gemma: Open Models Based on Gemini Research and Technology
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivi `ere, M. S. Kale, J. Love, and et al., “Gemma: Open models based on gemini research and technology,” 2024. [Online]. Available: https://arxiv.org/abs/2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
B. Peng, C. Li, P. He, M. Galley, and J. Gao, “Instruction tuning with gpt-4,” 2023. [Online]. Available: https://arxiv.org/abs/2304.03277
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
W. Luo, S. Ma, X. Liu, X. Guo, and C. Xiao, “Jailbreakv-28k: A benchmark for assessing the robustness of multimodal large language models against jailbreak attacks,” 2024. [Online]. Available: https://arxiv.org/abs/2404.03027
-
[22]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,” 2023
work page 2023
-
[23]
arXiv preprint arXiv:2402.08679 (2024)
X. Guo, F. Yu, H. Zhang, L. Qin, and B. Hu, “Cold-attack: Jail- breaking llms with stealthiness and controllability,”arXiv preprint arXiv:2402.08679, 2024
-
[24]
arXiv preprint arXiv:2404.02151 (2024)
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking lead- ing safety-aligned llms with simple adaptive attacks,”arXiv preprint arXiv:2404.02151, 2024
-
[25]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” 2021
work page 2021
-
[26]
Halueval: A large-scale hallucination evaluation benchmark for large language models,
J. Li, X. Cheng, W. X. Zhao, J.-Y . Nie, and J.-R. Wen, “Halueval: A large-scale hallucination evaluation benchmark for large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2305.11747
-
[27]
Drowzee: Metamorphic testing for fact-conflicting hallucination detection in large language models,
N. Li, Y . Li, Y . Liu, L. Shi, K. Wang, and H. Wang, “Drowzee: Metamorphic testing for fact-conflicting hallucination detection in large language models,”Proc. ACM Program. Lang., vol. 8, no. OOPSLA2, Oct. 2024. [Online]. Available: https://doi.org/10.1145/3689776
-
[28]
Crowdsourcing multiple choice science questions,
M. G. Johannes Welbl, Nelson F. Liu, “Crowdsourcing multiple choice science questions,” 2017
work page 2017
-
[29]
Backdoorllm: A comprehensive benchmark for backdoor attacks on large language models
Y . Li, H. Huang, Y . Zhao, X. Ma, and J. Sun, “Backdoorllm: A comprehensive benchmark for backdoor attacks on large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2408.12798
-
[30]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the machine learning model supply chain,” 2019. [Online]. Available: https://arxiv.org/abs/1708.06733
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Backdooring instruction-tuned large language models with virtual prompt injection,
J. Yan, V . Yadav, S. Li, L. Chen, Z. Tang, H. Wang, V . Srinivasan, X. Ren, and H. Jin, “Backdooring instruction-tuned large language models with virtual prompt injection,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), K. Duh, H. Go...
work page 2024
-
[32]
GradSafe: Detecting jailbreak prompts for LLMs via safety-critical gradient analysis,
Y . Xie, M. Fang, R. Pi, and N. Gong, “GradSafe: Detecting jailbreak prompts for LLMs via safety-critical gradient analysis,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024...
work page 2024
-
[33]
Lynx: An open source hallucination evaluation model,
S. S. Ravi, B. Mielczarek, A. Kannappan, D. Kiela, and R. Qian, “Lynx: An open source hallucination evaluation model,” 2024. [Online]. Available: https://arxiv.org/abs/2407.08488
-
[34]
Onion: A simple and effective defense against textual backdoor attacks,
F. Qi, Y . Chen, M. Li, Y . Yao, Z. Liu, and M. Sun, “Onion: A simple and effective defense against textual backdoor attacks,”arXiv preprint arXiv:2011.10369, 2020
-
[35]
Cc: Causality-aware coverage cri- terion for deep neural networks,
Z. Ji, P. Ma, Y . Yuan, and S. Wang, “Cc: Causality-aware coverage cri- terion for deep neural networks,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 1788–1800
work page 2023
-
[36]
Revisiting neuron coverage for dnn testing: A layer-wise and distribution-aware criterion,
Y . Yuan, Q. Pang, and S. Wang, “Revisiting neuron coverage for dnn testing: A layer-wise and distribution-aware criterion,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 1200–1212
work page 2023
-
[37]
LLM-Abnormal-Detection, “Exposing the ghost in the transformer: Abnormal detection for large language models via hidden state forensics,” 2026, accessed: 2026-1-10. [Online]. Available: https: //sites.google.com/view/llm-abnormal-detection
work page 2026
-
[38]
Do llms know about hallucination? an empirical investigation of llm’s hidden states,
H. Duan, Y . Yang, and K. Y . Tam, “Do llms know about hallucination? an empirical investigation of llm’s hidden states,” 2024. [Online]. Available: https://arxiv.org/abs/2402.09733
-
[39]
MASTERKEY: automated jailbreaking of large language model chatbots,
G. Deng, Y . Liu, Y . Li, K. Wang, Y . Zhang, Z. Li, H. Wang, T. Zhang, and Y . Liu, “MASTERKEY: automated jailbreaking of large language model chatbots,” in31st Annual Network and Distributed System Security Symposium, NDSS 2024, San Diego, California, USA, February 26 - March 1, 2024. The Internet Society,
work page 2024
-
[40]
[Online]. Available: https://www.ndss-symposium.org/ndss-paper/ masterkey-automated-jailbreaking-of-large-language-model-chatbots/
-
[41]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,
L. Jiang, K. Rao, S. Han, A. Ettinger, F. Brahman, S. Kumar, N. Mireshghallah, X. Lu, M. Sap, Y . Choi, and N. Dziri, “Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.18510
-
[42]
X. Hu, P.-Y . Chen, and T.-Y . Ho, “Gradient cuff: Detecting jailbreak attacks on large language models by exploring refusal loss landscapes,”
-
[43]
Available: https://arxiv.org/abs/2403.00867
[Online]. Available: https://arxiv.org/abs/2403.00867
-
[44]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggine, and M. Khabsa, “Llama guard: Llm-based input-output safeguard for human-ai conversations,” 2023. [Online]. Available: https://arxiv.org/abs/2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
The Internal State of an LLM Knows When It's Lying
A. Azaria and T. Mitchell, “The internal state of an llm knows when it’s lying,” 2023. [Online]. Available: https://arxiv.org/abs/2304.13734
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Llm internal states reveal hallucination risk faced with a query,
Z. Ji, D. Chen, E. Ishii, S. Cahyawijaya, Y . Bang, B. Wilie, and P. Fung, “Llm internal states reveal hallucination risk faced with a query,” 2024. [Online]. Available: https://arxiv.org/abs/2407.03282
-
[47]
In-context sharpness as alerts: An inner representation perspective for hallucination mitigation,
S. Chen, M. Xiong, J. Liu, Z. Wu, T. Xiao, S. Gao, and J. He, “In-context sharpness as alerts: An inner representation perspective for hallucination mitigation,” 2024. [Online]. Available: https://arxiv.org/abs/2403.01548
-
[48]
Quantifying uncertainty in answers from any language model and enhancing their trustworthiness,
J. Chen and J. Mueller, “Quantifying uncertainty in answers from any language model and enhancing their trustworthiness,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, p...
work page 2024
-
[49]
Self-alignment for factuality: Mitigating hallucinations in LLMs via self-evaluation,
X. Zhang, B. Peng, Y . Tian, J. Zhou, L. Jin, L. Song, H. Mi, and H. Meng, “Self-alignment for factuality: Mitigating hallucinations in LLMs via self-evaluation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for...
work page 2024
-
[50]
Bddr: An effective defense against textual backdoor attacks,
K. Shao, J. Yang, Y . Ai, H. Liu, and Y . Zhang, “Bddr: An effective defense against textual backdoor attacks,”Computers & Security, vol. 110, p. 102433, 2021. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0167404821002571
work page 2021
-
[51]
Rap: Robustness-aware perturbations for defending against backdoor attacks on nlp models,
W. Yang, Y . Lin, P. Li, J. Zhou, and X. Sun, “Rap: Robustness-aware perturbations for defending against backdoor attacks on nlp models,” arXiv preprint arXiv:2110.07831, 2021
-
[52]
Bdmmt: Backdoor sample detection for language models through model mutation testing,
J. Wei, M. Fan, W. Jiao, W. Jin, and T. Liu, “Bdmmt: Backdoor sample detection for language models through model mutation testing,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 4285– 4300, 2024
work page 2024
-
[53]
Cleangen: Mitigating backdoor attacks for generation tasks in large language models,
Y . Li, Z. Xu, F. Jiang, L. Niu, D. Sahabandu, B. Ramasubramanian, and R. Poovendran, “Cleangen: Mitigating backdoor attacks for generation tasks in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.12257
-
[54]
Chain-of-scrutiny: Detecting backdoor attacks for large language models,
X. Li, Y . Zhang, R. Lou, C. Wu, and J. Wang, “Chain-of-scrutiny: Detecting backdoor attacks for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.05948
-
[55]
G. Zeng, J. Shao, K. Lu, G. Geng, and J. Weng, “Mocc-bd-fid: Multi-objective clustering combination-based backdoor defense for federated intrusion detection of industrial control systems,”IEEE Trans. Inf. Forensics Secur., vol. 20, pp. 6868–6883, 2025. [Online]. Available: https://doi.org/10.1109/TIFS.2025.3586479
-
[56]
Automated federated learning-based adversarial attack and defence in industrial control systems,
G.-Q. Zeng, J.-M. Shao, K.-D. Lu, G.-G. Geng, and J. Weng, “Automated federated learning-based adversarial attack and defence in industrial control systems,”IET Cyber-Systems and Robotics, vol. 6, no. 2, p. e12117, 2024. [Online]. Available: https://ietresearch. onlinelibrary.wiley.com/doi/abs/10.1049/csy2.12117
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.