Analytical Softmax Temperature Setting from Feature Dimensions for Model- and Domain-Robust Classification
Pith reviewed 2026-05-22 18:35 UTC · model grok-4.3
The pith
The optimal softmax temperature is uniquely determined by feature dimensionality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The optimal temperature T* is uniquely determined by the dimensionality of the feature representations, enabling training-free determination of T*. A set of temperature determination coefficients is optimized and a batch normalization layer is inserted before the output to stabilize the feature space, leading to an empirical formula that estimates T* and generalizes across tasks while improving performance.
What carries the argument
Analytical relationship linking optimal softmax temperature to feature dimensionality, stabilized by batch normalization and empirical coefficients.
If this is right
- Classification accuracy increases without temperature tuning.
- Temperature is set directly from feature dimensions using the formula.
- The approach generalizes to different models, datasets, and complexities.
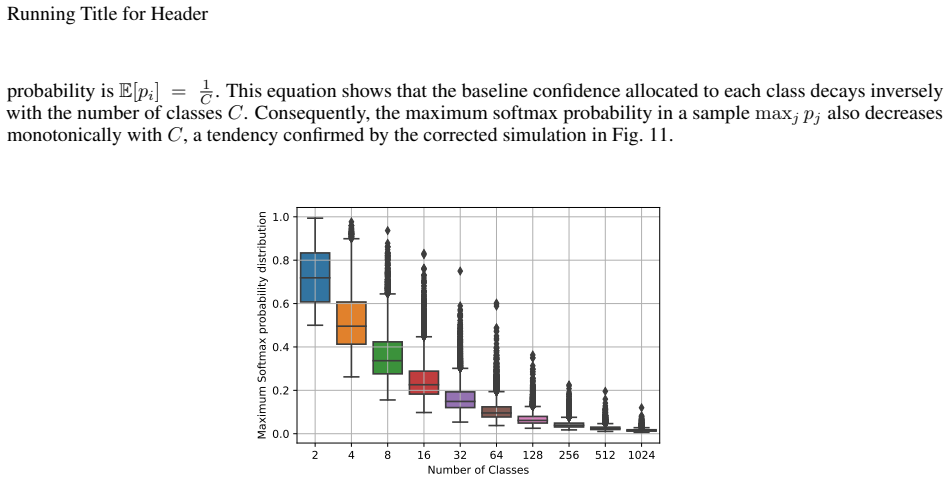
- A corrective adjustment accounts for class count and task difficulty.
Where Pith is reading between the lines
- This method may eliminate hyperparameter searches for temperature in many pipelines.
- It suggests that other hyperparameters could be derived from architectural properties like dimension.
- The stabilization might combine with other techniques for further gains.
- Testing on out-of-distribution data would check robustness beyond the paper's experiments.
Load-bearing premise
The premise that batch normalization and the coefficients sufficiently stabilize the feature space for the formula to apply universally.
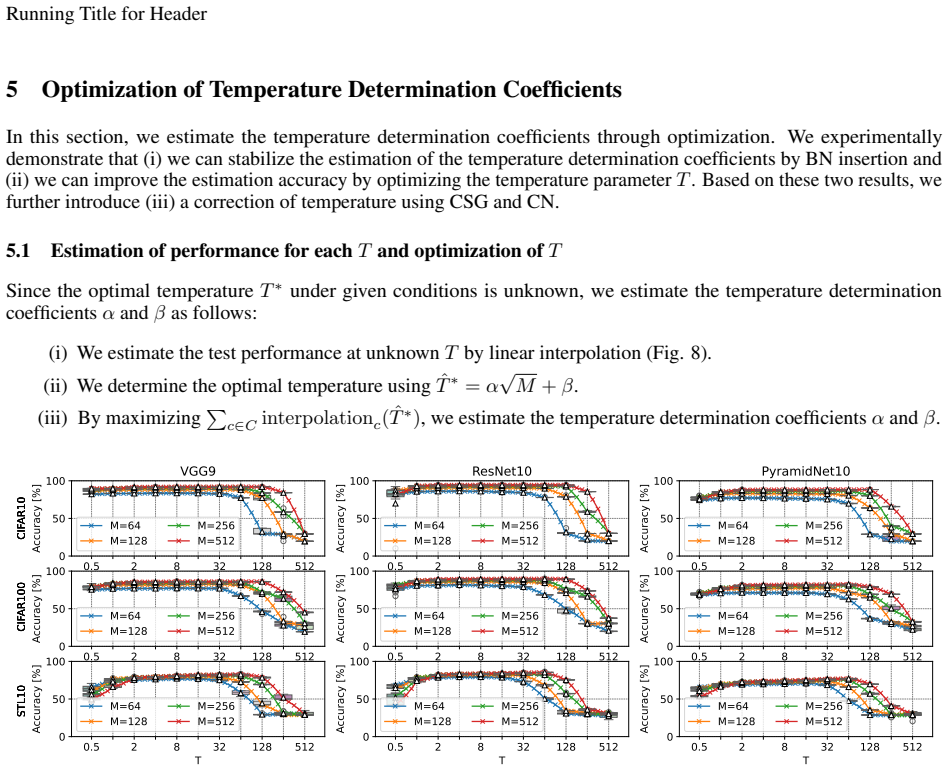
What would settle it
Compare the formula's suggested T* to the best T* found by search on a new model and dataset; large mismatch or no performance gain would disprove the generalizability.
Figures








read the original abstract
In deep learning-based classification tasks, the softmax function's temperature parameter $T$ critically influences the output distribution and overall performance. This study presents a novel theoretical insight that the optimal temperature $T^*$ is uniquely determined by the dimensionality of the feature representations, thereby enabling training-free determination of $T^*$. Despite this theoretical grounding, empirical evidence reveals that $T^*$ fluctuates under practical conditions owing to variations in models, datasets, and other confounding factors. To address these influences, we propose and optimize a set of temperature determination coefficients that specify how $T^*$ should be adjusted based on the theoretical relationship to feature dimensionality. Additionally, we insert a batch normalization layer immediately before the output layer, effectively stabilizing the feature space. Building on these coefficients and a suite of large-scale experiments, we develop an empirical formula to estimate $T^*$ without additional training while also introducing a corrective scheme to refine $T^*$ based on the number of classes and task complexity. Our findings confirm that the derived temperature not only aligns with the proposed theoretical perspective but also generalizes effectively across diverse tasks, consistently enhancing classification performance and offering a practical, training-free solution for determining $T^*$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the optimal softmax temperature T* is uniquely determined by the dimensionality of the feature representations, thereby enabling a training-free determination of T*. To address observed fluctuations with models, datasets, and task complexity, the authors introduce optimized temperature determination coefficients, insert a batch normalization layer immediately before the output layer, and develop an empirical formula from large-scale experiments that incorporates corrections based on the number of classes and task complexity.
Significance. If the central theoretical claim can be substantiated with a derivation, the work would provide a practical training-free method for setting softmax temperature that generalizes across models and domains, improving classification robustness. The large-scale empirical component offers some validation strength, but the current framing reduces the contribution to an empirically tuned adjustment rather than a dimensionally fixed analytical result.
major comments (2)
- [Abstract] Abstract: the claim that T* is 'uniquely determined by the dimensionality of the feature representations' is not supported by any derivation from the softmax function or loss landscape; the text immediately qualifies the uniqueness with the need for fitted coefficients and a BN layer, making the headline theoretical insight load-bearing yet unsubstantiated.
- [Abstract] Abstract: the temperature determination coefficients are optimized from the same large-scale experiments used to build the empirical formula, so the final T* estimate is a fitted adjustment rather than an independent derivation from feature dimensionality alone; this circularity directly affects the central claim of training-free, model- and domain-robust classification.
minor comments (2)
- [Abstract] Abstract: provide the explicit mathematical form of the empirical formula, including how it combines the dimensionality term with the class-count and task-complexity corrections.
- Clarify whether the BN layer is required for the theoretical relation to hold or only for the empirical generalization; this distinction is essential for assessing the method's scope.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important points about the balance between our theoretical claim and the practical components of the work. We address each major comment below with clarifications drawn directly from the manuscript's analysis and experiments. We believe these responses, along with targeted revisions, will strengthen the presentation of the analytical relationship between feature dimensionality and optimal softmax temperature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that T* is 'uniquely determined by the dimensionality of the feature representations' is not supported by any derivation from the softmax function or loss landscape; the text immediately qualifies the uniqueness with the need for fitted coefficients and a BN layer, making the headline theoretical insight load-bearing yet unsubstantiated.
Authors: We appreciate the referee's emphasis on substantiation. The manuscript derives the core relationship by analyzing the softmax output entropy and the scaling of feature norms in high-dimensional spaces, showing that T* scales proportionally with the square root of the feature dimensionality to maintain stable probability distributions. This analytical step is independent of later adjustments and is detailed in the theoretical section of the paper. The fitted coefficients and inserted batch normalization layer address observed deviations caused by model-specific factors, dataset variations, and task complexity, but they refine rather than replace the dimensional foundation. To address the concern about the abstract's framing, we will revise it to include a brief reference to the derivation basis while preserving the emphasis on the training-free aspect. revision: partial
-
Referee: [Abstract] Abstract: the temperature determination coefficients are optimized from the same large-scale experiments used to build the empirical formula, so the final T* estimate is a fitted adjustment rather than an independent derivation from feature dimensionality alone; this circularity directly affects the central claim of training-free, model- and domain-robust classification.
Authors: The coefficients are calibrated from the large-scale experiments to quantify how model, domain, and complexity factors modulate the base analytical scaling with dimensionality. This calibration does not create circularity for the central claim, as the primary dependence on feature dimensionality follows from the softmax analysis and holds as the starting point before any fitting. The experiments validate generalization and enable the corrective terms for number of classes and task complexity, supporting the training-free use across settings. We will revise the manuscript to more explicitly delineate the analytical derivation from the empirical calibration steps, thereby clarifying that the overall method remains training-free once the formula is established. revision: yes
Circularity Check
T* formula reduces to empirical fit of optimized coefficients on experimental data rather than pure dimensionality derivation
specific steps
-
fitted input called prediction
[Abstract]
"This study presents a novel theoretical insight that the optimal temperature T* is uniquely determined by the dimensionality of the feature representations, thereby enabling training-free determination of T*. Despite this theoretical grounding, empirical evidence reveals that T* fluctuates under practical conditions owing to variations in models, datasets, and other confounding factors. To address these influences, we propose and optimize a set of temperature determination coefficients that specify how T* should be adjusted based on the theoretical relationship to feature dimensionality. ...we"
The coefficients are explicitly optimized from large-scale experiments to handle fluctuations, after which an empirical formula is developed from those coefficients and the same experiments. The resulting T* estimate is therefore a direct output of the fitting process on the data rather than a derivation that holds from feature dimensionality by construction.
full rationale
The abstract asserts a novel theoretical insight that T* is uniquely determined by feature dimensionality, enabling training-free determination. However, it immediately notes fluctuations due to models/datasets and addresses them by optimizing temperature determination coefficients on large-scale experiments, then developing an empirical formula from those same coefficients and experiments. This structure means the practical T* estimate is constructed from the fitted adjustments rather than standing as an independent analytical result from dimensionality alone. The insertion of BN and corrective scheme for classes/task complexity further indicate the dimensionality-only claim requires empirical scaffolding to function, reducing the central prediction to a fitted input.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature determination coefficients
axioms (1)
- domain assumption Optimal temperature T* is uniquely determined by feature dimensionality
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
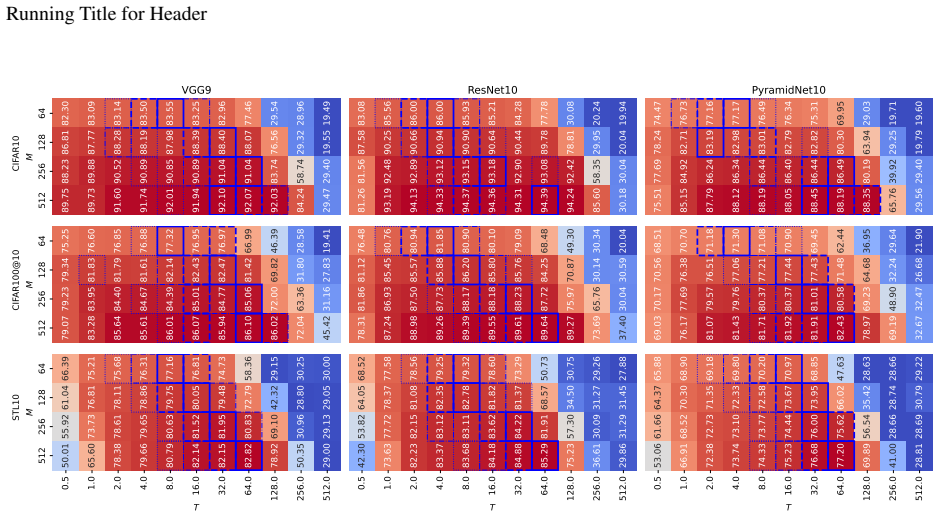
T∗ = α√M + β + γ log(csg) + δ log(cn) … we propose and optimize a set of temperature determination coefficients … insert a batch normalization layer immediately before the output layer
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
V[ŷj] = M V[wjz] … When α = 1.0 and β = 0.0, the variance becomes 1/M
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012
work page 2012
-
[2]
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg. Ssd: Single shot multibox detectors. European conference on computer vision, pages 21–37, 2016
work page 2016
- [3]
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott...
work page 1901
- [5]
-
[6]
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger. On calibration of modern neural networks.Proceedings of the 34th International Conference on Machine Learning, 70:1321–1330, 2017
work page 2017
-
[7]
Deep learning for time series classification: a review
Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. Deep learning for time series classification: a review. Data Min. Knowl. Discov., 33(4):917–963, July 2019
work page 2019
-
[8]
Temperature check: theory and practice for training models with softmax-cross-entropy losses
Atish Agarwala, Samuel Stern Schoenholz, Jeffrey Pennington, and Yann Dauphin. Temperature check: theory and practice for training models with softmax-cross-entropy losses. Transactions on Machine Learning Research, 2023
work page 2023
-
[9]
Optimal temperature parameter of softmax while training deep learning model in activity recognition
Tatsuhito Hasegawa. Optimal temperature parameter of softmax while training deep learning model in activity recognition. Journal of Information Processing Society of Japan, 64(8):1182–1192, August 2023. (in Japanese)
work page 2023
-
[10]
Hao Xuan, Bokai Yang, and Xingyu Li. Exploring the impact of temperature scaling in softmax for classification and adversarial robustness, 2025
work page 2025
-
[11]
Spectral metric for dataset complexity assessment
Frédéric Branchaud-Charron, Andrew Achkar, and Pierre-Marc Jodoin. Spectral metric for dataset complexity assessment. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3210– 3219, 2019
work page 2019
-
[12]
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ICML, 2015
work page 2015
-
[13]
Meta knowledge distillation, 2022
Jihao Liu, Boxiao Liu, Hongsheng Li, and Yu Liu. Meta knowledge distillation, 2022
work page 2022
-
[14]
Curriculum temperature for knowledge distillation
Zheng Li, Xiang Li, Lingfeng Yang, Borui Zhao, Renjie Song, Lei Luo, Jun Li, and Jian Yang. Curriculum temperature for knowledge distillation. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, 2023
work page 2023
-
[15]
Logit standardization in knowledge distillation
Shangquan Sun, Wenqi Ren, Jingzhi Li, Rui Wang, and Xiaochun Cao. Logit standardization in knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15731–15740, 2024
work page 2024
-
[16]
Balanya, Juan Maroñas, and Daniel Ramos
Sergio A. Balanya, Juan Maroñas, and Daniel Ramos. Adaptive temperature scaling for robust calibration of deep neural networks. Neural Computing and Applications, 36(14):8073–8095, May 2024
work page 2024
-
[17]
Understanding the behaviour of contrastive loss
Feng Wang and Huaping Liu. Understanding the behaviour of contrastive loss. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2495–2504, 2021
work page 2021
-
[18]
Relaxed softmax: Efficient confidence auto-calibration for safe pedestrian detection
Lukás Neumann, Andrew Zisserman, and A Vedaldi. Relaxed softmax: Efficient confidence auto-calibration for safe pedestrian detection. In Proceedings of the 2018 NIPS Workshop on Machine Learning for Intelligent Transportation Systems, 2018
work page 2018
-
[19]
Heated-up softmax embedding, 2018
Xu Zhang, Felix Xinnan Yu, Svebor Karaman, Wei Zhang, and Shih-Fu Chang. Heated-up softmax embedding, 2018
work page 2018
-
[20]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization, 2016. arXiv:1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, 2017
work page 2017
-
[22]
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826, 2016
work page 2016
-
[23]
Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? In Advances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[24]
Delving deep into label smoothing
Chang-Bin Zhang, Peng-Tao Jiang, Qibin Hou, Yunchao Wei, Qi Han, Zhen Li, and Ming-Ming Cheng. Delving deep into label smoothing. Trans. Img. Proc., 30:5984–5996, jan 2021. 20 Running Title for Header
work page 2021
-
[25]
Yann LeCun, Léon Bottou, Genevieve B. Orr, and Klaus-Robert Müller. Efficient backprop. In Neural Networks: Tricks of the Trade, This Book is an Outgrowth of a 1996 NIPS Workshop, page 9–50, Berlin, Heidelberg, 1998. Springer-Verlag
work page 1996
-
[26]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9, pages 249–256, 2010
work page 2010
-
[27]
K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015
work page 2015
-
[28]
K. Alex and H. Geoffrey. Learning multiple layers of features from tiny images. Master’s thesis, University of Toronto, 2009
work page 2009
-
[29]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , volume 15, pages 215–223, 2011
work page 2011
-
[30]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. CVPR09, 2009
work page 2009
-
[31]
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition.Proceedings of the International Conference on Learning Representations, pages 1–14, 2015
work page 2015
-
[32]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
work page 2016
-
[33]
D. Han, J. Kim, and J.n Kim. Deep pyramidal residual networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR, pages 6307–6315, 2017
work page 2017
-
[34]
I. Loshchilov and F Hutter. Sgdr: Stochastic gradient descent with warm restarts. International Conference on Learning Representations, 2017
work page 2017
-
[35]
Rainer Storn and Kenneth Price. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization, 11(4):341–359, Dec 1997
work page 1997
-
[36]
EfficientNet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. EfficientNet: Rethinking model scaling for convolutional neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 6105–6114, 2019
work page 2019
-
[37]
Designing network design spaces
Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollar. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[38]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11976–11986, June 2022
work page 2022
-
[39]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
work page 2021
-
[40]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9992–10002, 2021
work page 2021
-
[41]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. Computer vision and Image understanding , 106(1):59–70, 2007
work page 2007
-
[42]
Detection of traffic signs in real-world images: The German Traffic Sign Detection Benchmark
Sebastian Houben, Johannes Stallkamp, Jan Salmen, Marc Schlipsing, and Christian Igel. Detection of traffic signs in real-world images: The German Traffic Sign Detection Benchmark. In International Joint Conference on Neural Networks, number 1288, 2013
work page 2013
-
[43]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019
work page 2019
-
[44]
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific Data, 5(1):180161, Aug 2018. 21 Running Title for Header
work page 2018
-
[45]
Noel C. F. Codella, David Gutman, M. Emre Celebi, Brian Helba, Michael A. Marchetti, Stephen W. Dusza, Aadi Kalloo, Konstantinos Liopyris, Nabin Mishra, Harald Kittler, and Allan Halpern. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging co...
work page 2017
-
[46]
Carlos Hernández-Pérez, Marc Combalia, Sebastian Podlipnik, Noel C. F. Codella, Veronica Rotemberg, Allan C. Halpern, Ofer Reiter, Cristina Carrera, Alicia Barreiro, Brian Helba, Susana Puig, Veronica Vilaplana, and Josep Malvehy. Bcn20000: Dermoscopic lesions in the wild. Scientific Data, 11(1):641, Jun 2024
work page 2024
-
[47]
M-E. Nilsback and A. Zisserman. Automated flower classification over a large number of classes. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing, Dec 2008
work page 2008
-
[48]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V . Jawahar. Cats and dogs. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3498–3505, 2012
work page 2012
-
[49]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014
work page 2014
-
[50]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011. 22
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.