Critical Challenges and Guidelines in Evaluating Synthetic Tabular Data: A Systematic Review
Pith reviewed 2026-05-22 21:10 UTC · model grok-4.3
The pith
A review of 134 studies finds no consensus on evaluating synthetic tabular health data and offers taxonomies plus guidelines to fix inconsistent practices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
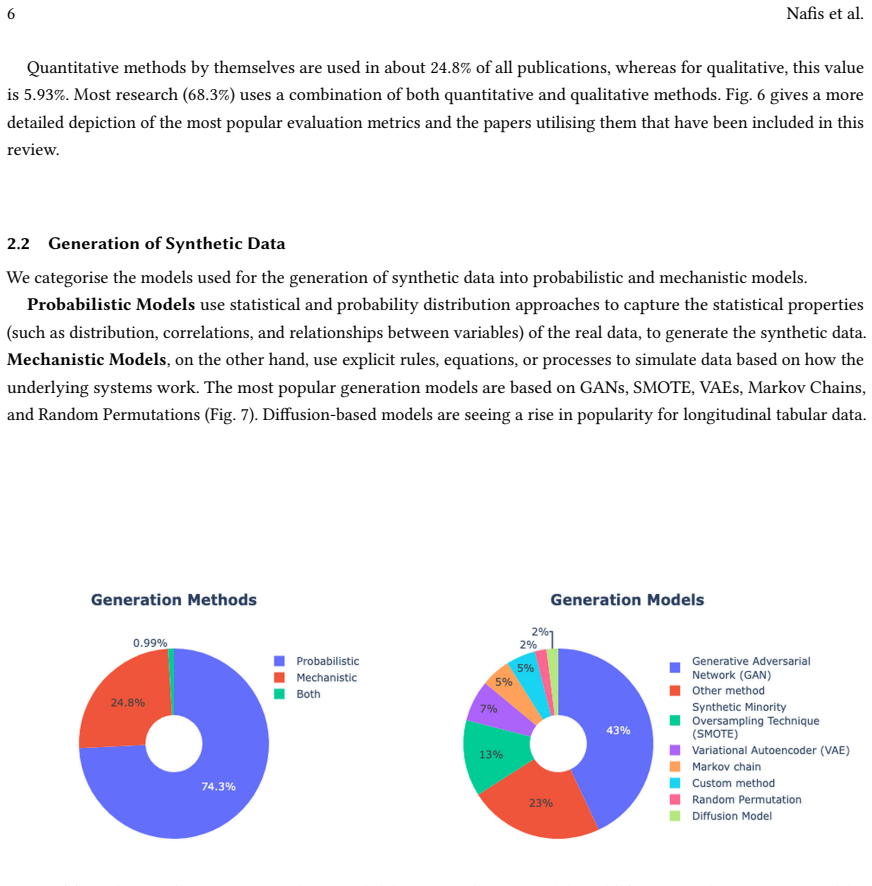
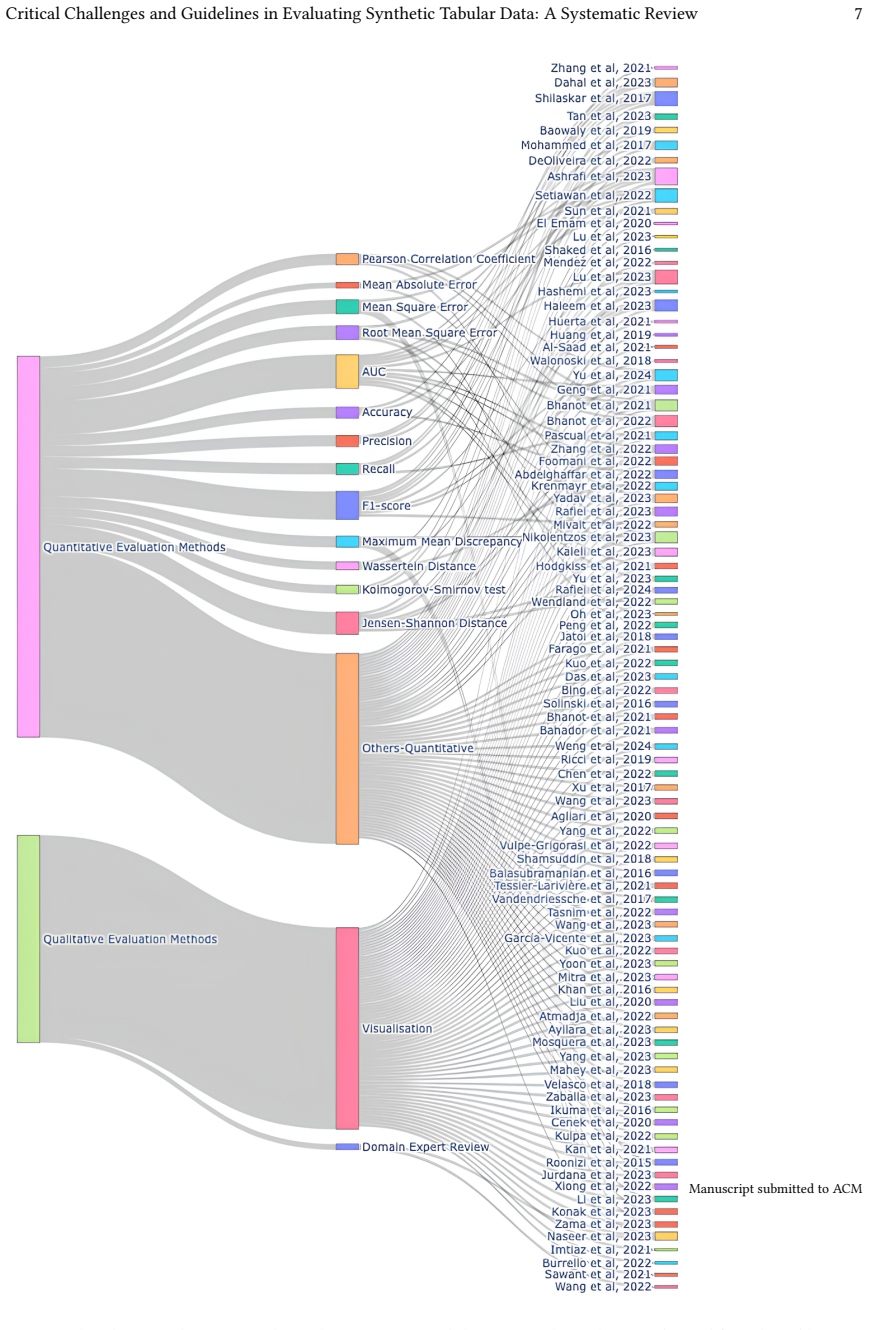
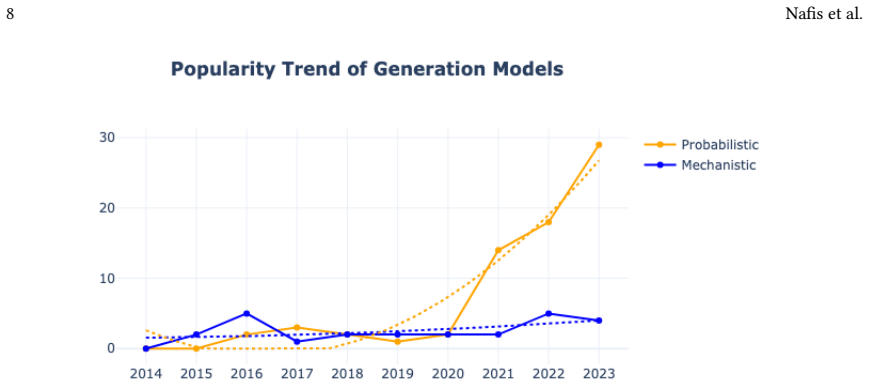
The review identifies key challenges in evaluating synthetic tabular health data, including the lack of consensus on evaluation methods, inconsistent application of evaluation metrics, limited involvement of domain experts, inadequate reporting of dataset characteristics, and limited reproducibility of results. In response, the authors provide a structured consolidation of synthetic data generation and evaluation methods into taxonomies, alongside practical guidelines to support more robust and standardised evaluation practices.
What carries the argument
The taxonomies classifying synthetic data generation techniques and evaluation approaches, which organize existing methods to reveal inconsistencies and guide standardized reporting.
If this is right
- Researchers adopting the guidelines will produce evaluations that can be compared more directly across different synthetic data generators.
- Increased involvement of domain experts in evaluation will raise the clinical usefulness of the resulting synthetic datasets.
- Standardized reporting of dataset characteristics will make it easier for other teams to reproduce and build on published results.
- The taxonomies will help new studies select appropriate generation and evaluation methods rather than defaulting to the most common but inconsistent ones.
Where Pith is reading between the lines
- The same challenges and taxonomies could apply to synthetic data in non-health domains such as finance or social science where privacy is also a concern.
- The guidelines might serve as a starting point for developing automated software tools that check adherence to recommended evaluation steps.
Load-bearing premise
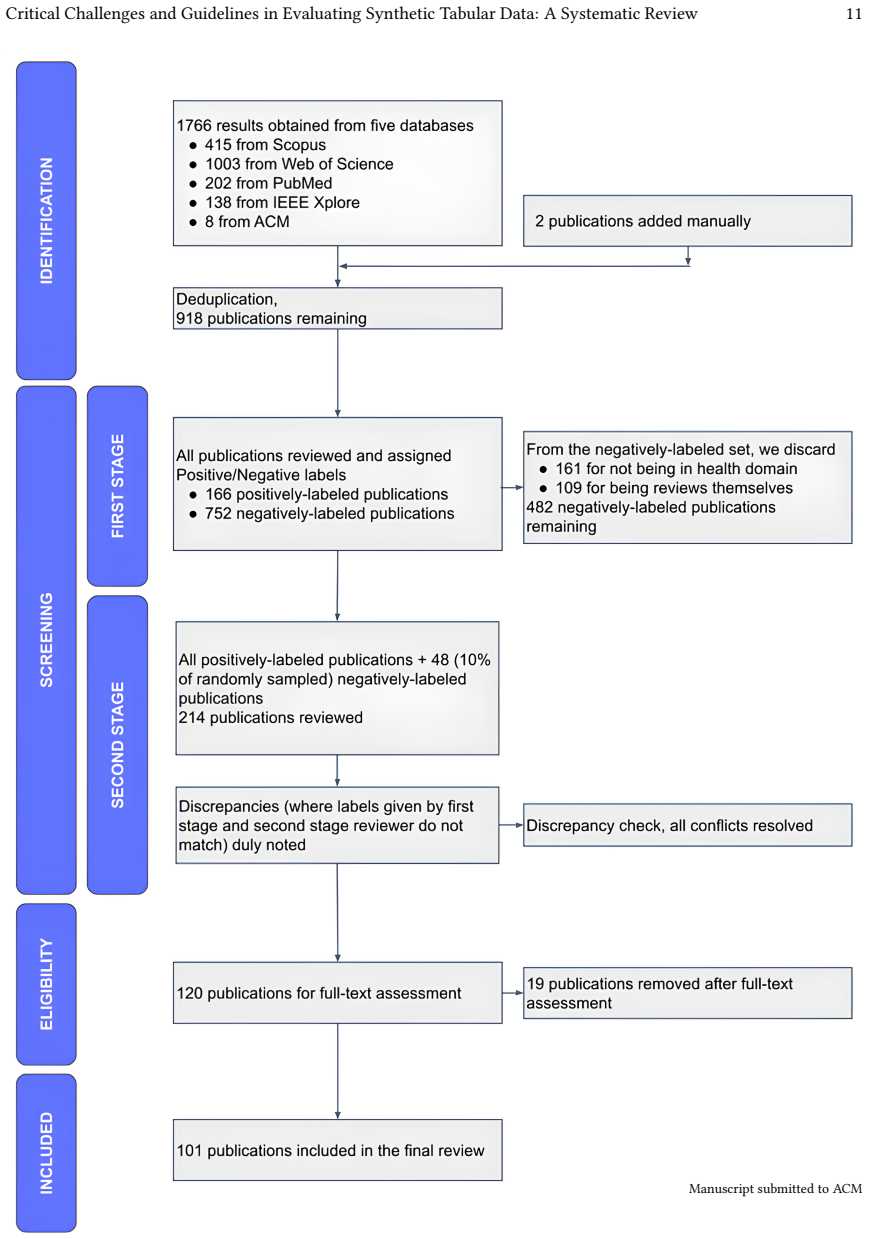
The search strategy and inclusion criteria that selected 134 studies from 2067 papers accurately represent the field without major bias in which papers were chosen or how challenges were interpreted.
What would settle it
A follow-up systematic review using similar methods but different databases that finds widespread agreement on a single set of evaluation metrics across most studies.
Figures


read the original abstract
Generating synthetic tabular health data is challenging, and evaluating their quality is equally, if not more, complex. This systematic review highlights the critical importance of rigorous evaluation of synthetic health data to ensure reliability, clinical relevance, and appropriate use. From an initial identification of 2067 relevant papers published in the last ten years, 134 studies were selected for detailed analysis. Our review identifies key challenges, including lack of consensus on evaluation methods, inconsistent application of evaluation metrics, limited involvement of domain experts, inadequate reporting of dataset characteristics, and limited reproducibility of results. In response, we provide a structured consolidation of synthetic data generation and evaluation methods into taxonomies, alongside practical guidelines to support more robust and standardised evaluation practices. These findings aim to support the responsible development and use of synthetic health data, aligned with emerging expectations around transparency, reproducibility, and governance, ultimately enabling the community to fully harness its transformative potential and accelerate innovation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This systematic review examines evaluation practices for synthetic tabular health data. From 2067 papers identified over the last decade, the authors select and analyze 134 studies. They report five key challenges: lack of consensus on evaluation methods, inconsistent metric use, limited domain-expert involvement, inadequate reporting of dataset characteristics, and limited reproducibility. In response, the paper consolidates generation and evaluation methods into taxonomies and supplies practical guidelines intended to promote standardized, transparent evaluation.
Significance. If the selection of 134 studies is representative and the challenge extraction is reproducible, the taxonomies and guidelines would provide a useful consolidation for the field, directly addressing gaps in standardization and reproducibility. The systematic-review framing and explicit provision of structured taxonomies constitute a clear strength.
major comments (2)
- [Methods] Methods section (search and selection procedure): the manuscript states that 2067 papers were identified and 134 selected but supplies no explicit search strategy, database list, search strings, inclusion/exclusion criteria, or PRISMA-style flow diagram. Because the central claims rest on the representativeness of these 134 studies and the reproducibility of the identified challenges, this omission is load-bearing.
- [Results] Results section (challenge extraction): the paper lists five challenges but does not describe the coding scheme, inter-rater process, or how many papers contributed evidence to each challenge. Without this, it is impossible to assess whether the listed challenges are exhaustive or whether selection bias in the 134 studies could have produced them.
minor comments (2)
- [Abstract] Abstract: the sentence reporting the 2067-to-134 reduction should be accompanied by a parenthetical reference to the Methods section so readers immediately know where the protocol is described.
- [Taxonomies] Taxonomy figures: the generation and evaluation taxonomies would benefit from explicit cross-references in the text to the specific tables or figures that present them.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that greater methodological transparency is required to support the reproducibility and credibility of our systematic review. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] Methods section (search and selection procedure): the manuscript states that 2067 papers were identified and 134 selected but supplies no explicit search strategy, database list, search strings, inclusion/exclusion criteria, or PRISMA-style flow diagram. Because the central claims rest on the representativeness of these 134 studies and the reproducibility of the identified challenges, this omission is load-bearing.
Authors: We agree that the current Methods section provides only a high-level summary and lacks the necessary details. In the revised manuscript we will expand this section to include: the complete list of databases searched (PubMed, Scopus, Web of Science, IEEE Xplore, ACM Digital Library, and arXiv), the exact search strings and Boolean operators used, the full inclusion/exclusion criteria applied at title/abstract and full-text stages, and a PRISMA flow diagram documenting the screening process from 2067 records to the final 134 studies. These additions will directly substantiate the representativeness of the selected corpus and enable independent reproduction of the study selection. revision: yes
-
Referee: [Results] Results section (challenge extraction): the paper lists five challenges but does not describe the coding scheme, inter-rater process, or how many papers contributed evidence to each challenge. Without this, it is impossible to assess whether the listed challenges are exhaustive or whether selection bias in the 134 studies could have produced them.
Authors: We acknowledge this limitation in transparency. The challenges were derived via thematic analysis of the 134 papers, yet the manuscript does not report the coding protocol. We will revise the Results (and/or Methods) section to describe the coding scheme and thematic framework employed, clarify whether coding was conducted by one or multiple reviewers with discrepancy resolution, and report the number (or proportion) of papers providing evidence for each of the five challenges. This information will allow readers to evaluate exhaustiveness and potential selection bias. revision: yes
Circularity Check
No significant circularity; review synthesizes external literature without self-referential reductions.
full rationale
This systematic review derives its claims (challenges, taxonomies, guidelines) from analysis of 134 externally selected papers. No equations, fitted parameters, or predictions exist that reduce to the authors' own inputs by construction. No self-citation chains are load-bearing for the core findings. The search/inclusion process is a methodological step whose validity is separate from circularity as defined (no self-definitional, fitted-input, or uniqueness-imported patterns apply).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Systematic reviews following established protocols provide a comprehensive and unbiased overview of the literature on synthetic data evaluation.
Reference graph
Works this paper leans on
-
[1]
Ngo, Taridzo Chomutare, Hercules Dalianis, Elisa Salvi, Andrius Budrionis, and Fred Godtliebsen
Maryam Tayefi, Phuong D. Ngo, Taridzo Chomutare, Hercules Dalianis, Elisa Salvi, Andrius Budrionis, and Fred Godtliebsen. Challenges and opportunities beyond structured data in analysis of electronic health records.Wiley Interdisciplinary Reviews: Computational Statistics, 13, 2021
work page 2021
-
[2]
Antonio Cruz, Samantha Marshall, Christine Daum, Hector Perez, John Hirdes, and Lili Liu. Data silos undermine efforts to characterize, predict, and mitigate dementia-related missing person incidents.Healthcare Management Forum, 35:084047042211061, 06 2022
work page 2022
-
[3]
Rebecca Asiimwe, Stephanie Lam, Samuel Leung, Shanzhao Wang, Rachel Wan, Anna Tinker, Jessica Mcalpine, Michelle Woo, David Huntsman, and Aline Talhouk. From biobank and data silos into a data commons: convergence to support translational medicine, 08 2021
work page 2021
-
[4]
Data democratization: toward a deeper understanding
Hippolyte Lefebvre, Christine Legner, and Martin Fadler. Data democratization: toward a deeper understanding. 09 2021
work page 2021
-
[5]
Filipe Bernardi, Domingos Alves, Nathalia Crepaldi, Diego Yamada, Vinícius Lima, and Rui Rijo. Data quality in health research: an integrative literature review (preprint).Journal of Medical Internet Research, 25, 08 2022
work page 2022
-
[6]
Julie-Anne Smit, Menno Mostert, and Johannes Delden. Protecting privacy while optimizing the use of (health)data: The importance of measures and safeguards.The American Journal of Bioethics, 22:79–81, 07 2022
work page 2022
-
[7]
Reg Joseph, Antonio Bruni, and Chris Carvalho. Health city: Transforming health and driving economic development.Healthcare Management Forum, 34:084047042094226, 08 2020
work page 2020
-
[8]
Synthetic data in medical research.BMJ Medicine, 1, 09 2022
Theodora Kokosi and Katie Harron. Synthetic data in medical research.BMJ Medicine, 1, 09 2022
work page 2022
-
[9]
Mauro Giuffrè and Dennis Shung. Harnessing the power of synthetic data in healthcare: innovation, application, and privacy.npj Digital Medicine, 6, 10 2023
work page 2023
-
[10]
Generative ai mitigates representation bias using synthetic health data.medRxiv, 2024
Nicolo Micheletti, Raffaele Marchesi, Nicholas I-Hsien Kuo, Sebastiano Barbieri, Giuseppe Jurman, and Venet Osmani. Generative ai mitigates representation bias using synthetic health data.medRxiv, 2024
work page 2024
-
[11]
Generative ai mitigates representation bias using synthetic health data, 09 2023
Nicolo Micheletti, Raffaele Marchesi, Nicholas Kuo, Sebastiano Barbieri, Giuseppe Jurman, and Venet Osmani. Generative ai mitigates representation bias using synthetic health data, 09 2023
work page 2023
-
[12]
Enrico Barbierato, Marco Della Vedova, Daniele Tessera, Daniele Toti, and Nicola Vanoli. A methodology for controlling bias and fairness in synthetic data generation.Applied Sciences, 12:4619, 05 2022
work page 2022
-
[13]
Decaf: Generating fair synthetic data using causally-aware generative networks, 10 2021
Boris Breugel, Trent Kyono, Jeroen Berrevoets, and Mihaela Schaar. Decaf: Generating fair synthetic data using causally-aware generative networks, 10 2021
work page 2021
-
[14]
Rodríguez-Almeida, Himar Fabelo, Samuel Ortega, Alejandro Deniz, Francisco J
Antonio J. Rodríguez-Almeida, Himar Fabelo, Samuel Ortega, Alejandro Deniz, Francisco J. Balea-Fernandez, Eduardo Quevedo, Cristina Soguero- Ruíz, Ana Maria Wägner, and Gustavo Marrero Callicó. Synthetic patient data generation and evaluation in disease prediction using small and imbalanced datasets.IEEE Journal of Biomedical and Health Informatics, 27:26...
work page 2022
-
[15]
Measuring the quality of synthetic data for use in competitions, 06 2018
James Jordon, Jinsung Yoon, and Mihaela Schaar. Measuring the quality of synthetic data for use in competitions, 06 2018
work page 2018
-
[16]
Ahmed Alaa, Boris van Breugel, Evgeny Saveliev, and Mihaela Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models, 02 2021
work page 2021
-
[17]
Mikel Hernandez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Synthetic data generation for tabular health records: A systematic review.Neurocomputing, 493, 04 2022. Manuscript submitted to ACM Critical Challenges and Guidelines in Evaluating Synthetic Tabular Data: A Systematic Review 15
work page 2022
-
[18]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. 12 2017
work page 2017
-
[19]
Bertscore: Evaluating text generation with bert, 04 2019
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert, 04 2019
work page 2019
-
[20]
Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9, 2016
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9, 2016
work page 2016
-
[21]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
work page 2023
-
[22]
The prisma 2020 statement: an updated guideline for reporting systematic reviews.Bmj, 372, 2021
Matthew J Page, Joanne E McKenzie, Patrick M Bossuyt, Isabelle Boutron, Tammy C Hoffmann, Cynthia D Mulrow, Larissa Shamseer, Jennifer M Tetzlaff, Elie A Akl, Sue E Brennan, et al. The prisma 2020 statement: an updated guideline for reporting systematic reviews.Bmj, 372, 2021
work page 2020
-
[23]
M. A. Jatoi and Nidal S. Kamel. Brain source localization using reduced eeg sensors.Signal, Image and Video Processing, 12:1447 – 1454, 2018
work page 2018
-
[24]
Emma Farago and Adrian Chan. Motion artifact synthesis for research in biomedical signal quality analysis.Biomedical Signal Processing and Control, 68:102611, 07 2021
work page 2021
-
[25]
Chih-En Kuo, Tsung-Hua Lu, Guan-Ting Chen, and Po-Yu Liao. Towards precision sleep medicine: Self-attention gan as an innovative data augmentation technique for developing personalized automatic sleep scoring classification.Computers in Biology and Medicine, 148:105828, 2022
work page 2022
-
[26]
Alireza Rafiei, Milad Ghiasi Rad, Andrea Sikora, and Rishikesan Kamaleswaran. Improving irregular temporal modeling by integrating synthetic data to the electronic medical record using conditional gans: a case study of fluid overload prediction in the intensive care unit.medRxiv, pages 2023–06, 2023
work page 2023
-
[27]
Har-ctgan: a mobile sensor data generation tool for human activity recognition
Joshua DeOliveira, Walter Gerych, Aruzhan Koshkarova, Elke Rundensteiner, and Emmanuel Agu. Har-ctgan: a mobile sensor data generation tool for human activity recognition. In2022 IEEE International Conference on Big Data (Big Data), pages 5233–5242. IEEE, 2022
work page 2022
-
[28]
Twin: Personalized clinical trial digital twin generation
Trisha Das, Zifeng Wang, and Jimeng Sun. Twin: Personalized clinical trial digital twin generation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 402–413, 2023
work page 2023
-
[29]
Simon Bing, Andrea Dittadi, Stefan Bauer, and Patrick Schwab. Conditional generation of medical time series for extrapolation to underrepresented populations.PLOS Digital Health, 1(7):e0000074, 2022
work page 2022
-
[30]
Quantifying resemblance of synthetic medical time-series
Karan Bhanot, Saloni Dash, Joseph Pedersen, Isabelle Guyon, and Kristin P Bennett. Quantifying resemblance of synthetic medical time-series. In ESANN, 2021
work page 2021
-
[31]
Khaled El Emam, Lucy Mosquera, and Jason Bass. Evaluating identity disclosure risk in fully synthetic health data: model development and validation.Journal of medical Internet research, 22(11):e23139, 2020
work page 2020
-
[32]
Ya-Ting Lu, Horng-Jiun Chao, Yi-Chun Chiang, and Hsiang-Yin Chen. Explainable machine learning techniques to predict amiodarone-induced thyroid dysfunction risk: multicenter, retrospective study with external validation.Journal of Medical Internet Research, 25:e43734, 2023
work page 2023
-
[33]
Mateusz Soliński, Jan Gierałtowski, and Jan Żebrowski. Modeling heart rate variability including the effect of sleep stages.Chaos: An Interdisciplinary Journal of Nonlinear Science, 26(2), 2016
work page 2016
-
[34]
The problem of fairness in synthetic healthcare data.Entropy, 23(9):1165, 2021
Karan Bhanot, Miao Qi, John S Erickson, Isabelle Guyon, and Kristin P Bennett. The problem of fairness in synthetic healthcare data.Entropy, 23(9):1165, 2021
work page 2021
-
[35]
Publishing differentially private medical events data
Sigal Shaked and Lior Rokach. Publishing differentially private medical events data. InA vailability, Reliability, and Security in Information Systems: IFIP WG 8.4, 8.9, TC 5 International Cross-Domain Conference, CD-ARES 2016, and Workshop on Privacy A ware Machine Learning for Health Data Science, PAML 2016, Salzburg, Austria, August 31-September 2, 201...
work page 2016
-
[36]
Nooshin Bahador, Guoying Zhao, Jarno Jokelainen, Seppo Mustola, and Jukka Kortelainen. Morphology-preserving reconstruction of times series with missing data for enhancing deep learning-based classification.Biomedical Signal Processing and Control, 70:103052, 2021
work page 2021
-
[37]
Xutao Weng, Hong Song, Yucong Lin, You Wu, Xi Zhang, Bowen Liu, and Jian Yang. A joint learning method for incomplete and imbalanced data in electronic health record based on generative adversarial networks.Computers in Biology and Medicine, 168:107687, 2024
work page 2024
-
[38]
Investigating synthetic medical time-series resemblance.Neurocomputing, 494:368–378, 2022
Karan Bhanot, Joseph Pedersen, Isabelle Guyon, and Kristin P Bennett. Investigating synthetic medical time-series resemblance.Neurocomputing, 494:368–378, 2022
work page 2022
-
[39]
Giannis Nikolentzos, Michalis Vazirgiannis, Christos Xypolopoulos, Markus Lingman, and Erik G Brandt. Synthetic electronic health records generated with variational graph autoencoders.NPJ Digital Medicine, 6(1):83, 2023
work page 2023
-
[40]
Leonardo Ricci, Michele Castelluzzo, Ludovico Minati, and Alessio Perinelli. Generation of surrogate event sequences via joint distribution of successive inter-event intervals.Chaos: An Interdisciplinary Journal of Nonlinear Science, 29(12), 2019
work page 2019
-
[41]
Jack Hodgkiss, Soufiene Djahel, and Zonghua Zhang. A new attack method against ecg-based key generation and agreement schemes in body area networks.IEEE Sensors Journal, 21(15):17300–17307, 2021
work page 2021
-
[42]
Epileptic seizure prediction based on eeg by auto-machine learning
Cai Chen, Fulai Peng, Yue Sun, Danyang Lv, Ningling Zhang, Xingwei Wang, and Lin Wang. Epileptic seizure prediction based on eeg by auto-machine learning. In2022 IEEE International Conference on Real-time Computing and Robotics (RCAR), pages 710–715. IEEE, 2022
work page 2022
-
[43]
Hongteng Xu, Weichang Wu, Shamim Nemati, and Hongyuan Zha. Patient flow prediction via discriminative learning of mutually-correcting processes.IEEE transactions on Knowledge and Data Engineering, 29(1):157–171, 2016
work page 2016
-
[44]
Ameer Mohammed, Majid Zamani, Richard Bayford, and Andreas Demosthenous. Toward on-demand deep brain stimulation using online parkinson’s disease prediction driven by dynamic detection.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 25(12):2441–2452, 2017. Manuscript submitted to ACM 16 Nafis et al
work page 2017
-
[45]
Xianglong Wang, Berkman Sahiner, Christopher G Scully, and Kenny H Cha. Afe-gan: Synthesizing electrocardiograms with atrial fibrillation characteristics using generative adversarial networks. In2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 1–5. IEEE, 2023
work page 2023
-
[46]
Synthetic and private smart health care data generation using gans
Sana Imtiaz, Muhammad Arsalan, Vladimir Vlassov, and Ramin Sadre. Synthetic and private smart health care data generation using gans. In2021 International Conference on Computer Communications and Networks (ICCCN), pages 1–7. IEEE, 2021
work page 2021
-
[47]
Protect and extend-using gans for synthetic data generation of time-series medical records
Navid Ashrafi, Vera Schmitt, Robert P Spang, Sebastian Möller, and Jan-Niklas Voigt-Antons. Protect and extend-using gans for synthetic data generation of time-series medical records. In2023 15th International Conference on Quality of Multimedia Experience (QoMEX), pages 171–176. IEEE, 2023
work page 2023
-
[48]
Alireza Rafiei, Milad Ghiasi Rad, Andrea Sikora, and Rishikesan Kamaleswaran. Improving mixed-integer temporal modeling by generating synthetic data using conditional generative adversarial networks: A case study of fluid overload prediction in the intensive care unit.Computers in Biology and Medicine, 168:107749, 2024
work page 2024
-
[49]
Elena Agliari, Francesco Alemanno, Adriano Barra, Orazio Antonio Barra, Alberto Fachechi, Lorenzo Franceschi Vento, and Luciano Moretti. Analysis of temporal correlation in heart rate variability through maximum entropy principle in a minimal pairwise glassy model.Scientific Reports, 10(1):15353, 2020
work page 2020
-
[50]
Jin Li, Benjamin J Cairns, Jingsong Li, and Tingting Zhu. Generating synthetic mixed-type longitudinal electronic health records for artificial intelligent applications.NPJ Digital Medicine, 6(1):98, 2023
work page 2023
-
[51]
Ziqi Zhang, Chao Yan, and Bradley A Malin. Keeping synthetic patients on track: feedback mechanisms to mitigate performance drift in longitudinal health data simulation.Journal of the American Medical Informatics Association, 29(11):1890–1898, 2022
work page 2022
-
[52]
In-Sun Oh, Han Eol Jeong, Hyesung Lee, Kristian B Filion, Yunha Noh, and Ju-Young Shin. Validating an approach to overcome the immeasurable time bias in cohort studies: a real-world example and monte carlo simulation study.International Journal of Epidemiology, 52(5):1534–1544, 2023
work page 2023
-
[53]
Improving ppg-based heart-rate monitoring with synthetically generated data
Alessio Burrello, Daniele Jahier Pagliari, Marzia Bianco, Enrico Macii, Luca Benini, Massimo Poncino, and Simone Benatti. Improving ppg-based heart-rate monitoring with synthetically generated data. In2022 IEEE Biomedical Circuits and Systems Conference (BioCAS), pages 153–157. IEEE, 2022
work page 2022
-
[54]
Emg data augmentation for grasp classification using generative adversarial networks
Vincent Mendez, Clément Lhoste, and Silvestro Micera. Emg data augmentation for grasp classification using generative adversarial networks. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 3619–3622. IEEE, 2022
work page 2022
-
[55]
Zhenyi Yang, Rebecca Miao, Marina Orlova, Ivan Nechepurenko, and Valeriy Gavrishchaka. Discovery of early-alert indicators using hybrid ensemble learning and generative physics-based models. In2022 5th International Conference on Information and Computer Technologies (ICICT), pages 224–232. IEEE, 2022
work page 2022
-
[56]
Gan based synthetic ecg for psychological stress
Adrian Vulpe-Grigoraşi and Ovidiu Grigore. Gan based synthetic ecg for psychological stress. In2022 E-Health and Bioengineering Conference (EHB), pages 1–4. IEEE, 2022
work page 2022
-
[57]
Virtual patient model: an approach for generating synthetic healthcare time series data
Rittika Shamsuddin, Barbara M Maweu, Ming Li, and Balakrishnan Prabhakaran. Virtual patient model: an approach for generating synthetic healthcare time series data. In2018 IEEE International Conference on Healthcare Informatics (ICHI), pages 208–218. IEEE, 2018
work page 2018
-
[58]
Arvind Balasubramanian, Jun Wang, and Balakrishnan Prabhakaran. Discovering multidimensional motifs in physiological signals for personalized healthcare.IEEE journal of selected topics in signal processing, 10(5):832–841, 2016
work page 2016
-
[59]
Olivier Tessier-Larivière, Luke Y Prince, Pascal Fortier-Poisson, Lorenz Wernisch, Oliver Armitage, Emil Hewage, Guillaume Lajoie, and Blake A Richards. Pns-gan: Conditional generation of peripheral nerve signals in the wavelet domain via adversarial networks. In2021 10th International IEEE/EMBS Conference on Neural Engineering (NER), pages 778–782. IEEE, 2021
work page 2021
-
[60]
Benjamin Vandendriessche, Mustafa Abas, Thomas E Dick, Kenneth A Loparo, and Frank J Jacono. A framework for patient state tracking by classifying multiscalar physiologic waveform features.IEEE Transactions on Biomedical Engineering, 64(12):2890–2900, 2017
work page 2017
-
[61]
An approach for analyzing cognitive behavior of autism spectrum disorder using p300 bci data
Nabila Tasnim, Joyita Halder, Shahed Ahmed, and Shaikh Anowarul Fattah. An approach for analyzing cognitive behavior of autism spectrum disorder using p300 bci data. In2022 IEEE Region 10 Symposium (TENSYMP), pages 1–6. IEEE, 2022
work page 2022
-
[62]
Winston Wang and Tun-Wen Pai. enhancing small tabular clinical trial dataset through hybrid data augmentation: combining smote and wcgan-gp. Data, 8(9):135, 2023
work page 2023
-
[63]
Clara García-Vicente, David Chushig-Muzo, Inmaculada Mora-Jiménez, Himar Fabelo, Inger Torhild Gram, Maja-Lisa Løchen, Conceição Granja, and Cristina Soguero-Ruiz. Evaluation of synthetic categorical data generation techniques for predicting cardiovascular diseases and post-hoc interpretability of the risk factors.Applied Sciences, 13(7):4119, 2023
work page 2023
-
[64]
Nicholas I-Hsien Kuo, Mark N Polizzotto, Simon Finfer, Federico Garcia, Anders Sönnerborg, Maurizio Zazzi, Michael Böhm, Rolf Kaiser, Louisa Jorm, and Sebastiano Barbieri. The health gym: synthetic health-related datasets for the development of reinforcement learning algorithms. Scientific data, 9(1):693, 2022
work page 2022
-
[65]
Jinsung Yoon, Michel Mizrahi, Nahid Farhady Ghalaty, Thomas Jarvinen, Ashwin S Ravi, Peter Brune, Fanyu Kong, Dave Anderson, George Lee, Arie Meir, et al. Ehr-safe: generating high-fidelity and privacy-preserving synthetic electronic health records.NPJ Digital Medicine, 6(1):141, 2023
work page 2023
-
[66]
Anumita Mitra, Palash Kumar Kundu, Rajarshi Gupta, Jayanta Saha, and Arunansu Talukdar. Cardiosim: a pc-based cardiac signal simulator using segmental modeling of electrocardiogram.Computer Methods in Biomechanics and Biomedical Engineering, 26(13):1532–1548, 2023
work page 2023
-
[67]
Using genetic algorithms for optimal change point detection in activity monitoring
Naveed Khan, Sally McClean, Shuai Zhang, and Chris Nugent. Using genetic algorithms for optimal change point detection in activity monitoring. In2016 IEEE 29th International Symposium on Computer-Based Medical Systems (CBMS), pages 318–323. IEEE, 2016. Manuscript submitted to ACM Critical Challenges and Guidelines in Evaluating Synthetic Tabular Data: A S...
work page 2016
-
[68]
A comparison of three methodologies for the computation of v-index
Ebadollah Kheirati Roonizi, Massimo W Rivolta, Luca T Mainardi, and Roberto Sassi. A comparison of three methodologies for the computation of v-index. In2015 Computing in Cardiology Conference (CinC), pages 593–596. IEEE, 2015
work page 2015
-
[69]
Overcoming data scarcity in human activity recognition
Orhan Konak, Lucas Liebe, Kirill Postnov, Franz Sauerwald, Hristijan Gjoreski, Mitja Luštrek, and Bert Arnrich. Overcoming data scarcity in human activity recognition. In2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 1–7. IEEE, 2023
work page 2023
-
[70]
Tabular gan-based oversampling of imbalanced time-to-event data for survival prediction
Huaning Tan, Renxing Chen, Meng Qin, Lining Tang, Zhibing Wu, Qianlin Luo, and Yujuan Quan. Tabular gan-based oversampling of imbalanced time-to-event data for survival prediction. In2023 8th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), pages 376–380. IEEE, 2023
work page 2023
-
[71]
Estimating individual treatment effects with time-varying confounders
Ruoqi Liu, Changchang Yin, and Ping Zhang. Estimating individual treatment effects with time-varying confounders. In2020 IEEE International Conference on Data Mining (ICDM), pages 382–391. IEEE, 2020
work page 2020
-
[72]
Generated tabular data with multi-gans for arrhythmia classification based on dnn models
Hendrico Yehezky Nata Atmadja, Alhadi Bustamam, et al. Generated tabular data with multi-gans for arrhythmia classification based on dnn models. In2022 International Conference of Science and Information Technology in Smart Administration (ICSINTESA), pages 69–74. IEEE, 2022
work page 2022
-
[73]
Time-series anonymization of tabular health data using generative adversarial network
Atiye Sadat Hashemi, Kobra Etminani, Amira Soliman, Omar Hamed, and Jens Lundström. Time-series anonymization of tabular health data using generative adversarial network. In2023 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2023
work page 2023
-
[74]
Plasek, Yun Xiong, Yangyong Zhu, D
Xiaoxia Wang, Chun-Pong Tang, Yanming He, Joseph M. Plasek, Yun Xiong, Yangyong Zhu, D. Bates, and Li Zhou. Using an optimized generative model to infer the progression of complications in type 2 diabetes patients.BMC Medical Informatics and Decision Making, 22, 2022
work page 2022
-
[75]
Ecg quality assessment via deep learning and data augmentation
Álvaro Huerta, Arturo Martínez-Rodrigo, José Joaquín Rieta, and Raúl Alcaraz. Ecg quality assessment via deep learning and data augmentation. 2021 Computing in Cardiology (CinC), 48:1–4, 2021
work page 2021
-
[76]
Olawale F. Ayilara, Robert W. Platt, Matt Dahl, Janie Coulombe, Pablo Gonzalez Ginestet, Dan Chateau, and Lisa M. Lix. Generating synthetic data from administrative health records for drug safety and effectiveness studies.International Journal of Population Data Science, 8, 2023
work page 2023
-
[77]
Muhammad Salman Haleem, Audrey Ekuban, Alessio Antonini, Silvio Marcello Pagliara, Leandro Pecchia, and Carlo Allocca. Deep-learning-driven techniques for real-time multimodal health and physical data synthesis.Electronics, 2023
work page 2023
-
[78]
Md Haider Zama and Friedhelm Schwenker. Ecg synthesis via diffusion-based state space augmented transformer.Sensors (Basel, Switzerland), 23, 2023
work page 2023
-
[79]
Lucy Mosquera, Khaled El Emam, Lei Ding, Vishal Sharma, Xue Hua Zhang, Samer El Kababji, Chris Carvalho, Brian Hamilton, Dan Palfrey, Linglong Kong, Bei Jiang, and Dean T. Eurich. A method for generating synthetic longitudinal health data.BMC Medical Research Methodology, 23, 2023
work page 2023
-
[80]
Ming Huang, Nilay D. Shah, and Lixia Yao. Evaluating global and local sequence alignment methods for comparing patient medical records.BMC Medical Informatics and Decision Making, 19, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.