Variational Visual Question Answering for Uncertainty-Aware Selective Prediction
Pith reviewed 2026-05-22 15:24 UTC · model grok-4.3
The pith
Variational Bayes enables effective selective prediction in Visual Question Answering by using posterior samples and variance-aware selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
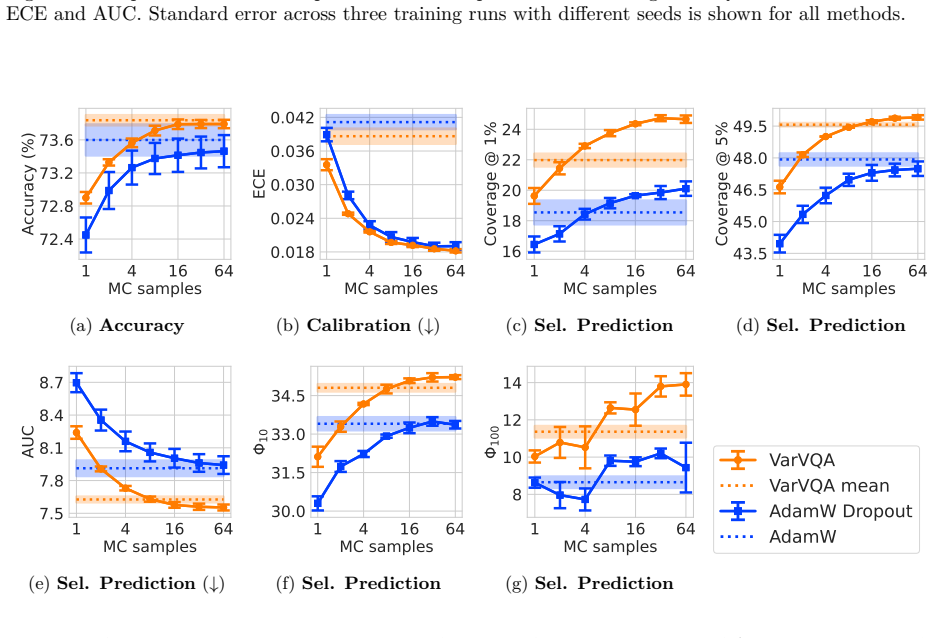
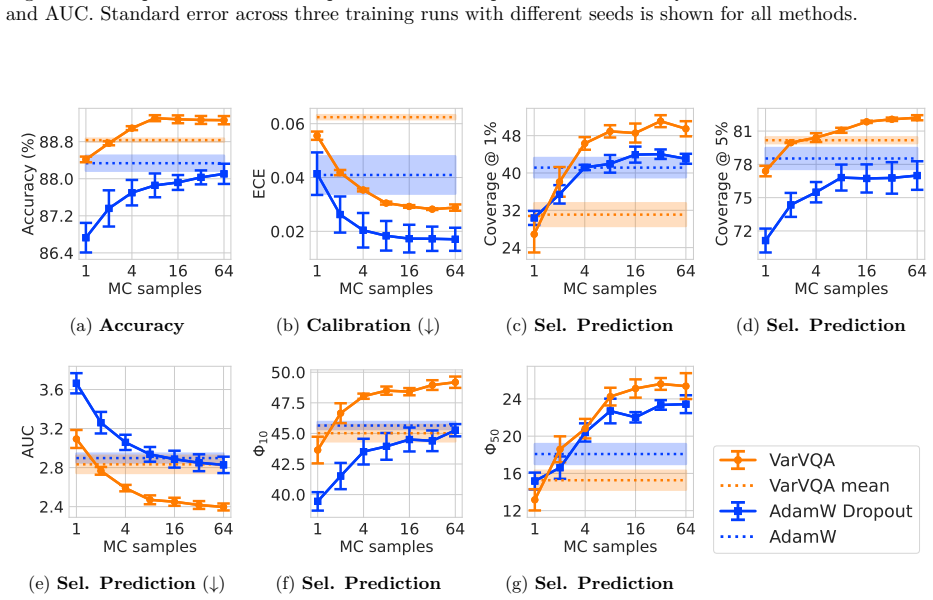
We show for the first time the effectiveness and competitive edge of variational Bayes for selective prediction in VQA. We build on recent advances in variational methods for deep learning and propose an extension called Variational VQA. This method improves calibration and yields significant gains for selective prediction on VQA and Visual Reasoning, particularly when the error tolerance is low (≤1%). Often, just one posterior sample yields more reliable answers than those given by models trained with AdamW. In addition, we propose a new risk-averse selector that outperforms standard sample averaging by considering the variance of predictions.
What carries the argument
Variational VQA, an extension of variational inference to vision-language models that supports uncertainty-aware selective prediction via posterior sampling combined with a variance-based risk-averse selector.
If this is right
- Selective prediction performance improves markedly at error tolerances of 1% or below.
- A single draw from the variational posterior often suffices for more reliable answers than deterministic training.
- Accounting for prediction variance in the selector yields better abstention decisions than averaging.
- Variational learning offers a practical route to safer, more trustworthy large VLMs.
Where Pith is reading between the lines
- The same variational treatment could be tested on related multimodal tasks such as visual reasoning or caption generation.
- If the approach scales, it may become a standard way to add built-in uncertainty awareness to deployed vision-language systems.
- Combining the variance selector with other calibration techniques could produce further reliability gains in safety-critical settings.
Load-bearing premise
Variational inference stays computationally tractable and effective on large vision-language models, and the variance-based selector adds gains beyond what posterior averaging already provides.
What would settle it
If experiments on standard VQA benchmarks show no meaningful improvement in selective prediction accuracy at 1% error tolerance compared to non-variational baselines, the central claim would not hold.
Figures



















read the original abstract
Despite remarkable progress in recent years, Vision Language Models (VLMs) remain prone to overconfidence and hallucinations on tasks such as Visual Question Answering (VQA) and Visual Reasoning. Bayesian methods can potentially improve reliability by helping models predict selectively, that is, models respond only when they are sufficiently confident. Unfortunately, such approaches can be costly and ineffective for large models, and there exists little evidence to show otherwise for multimodal applications. Here, we show for the first time the effectiveness and competitive edge of variational Bayes for selective prediction in VQA. We build on recent advances in variational methods for deep learning and propose an extension called "Variational VQA". This method improves calibration and yields significant gains for selective prediction on VQA and Visual Reasoning, particularly when the error tolerance is low ($\leq 1\%$). Often, just one posterior sample yields more reliable answers than those given by models trained with AdamW. In addition, we propose a new risk-averse selector that outperforms standard sample averaging by considering the variance of predictions. Overall, we present compelling evidence that variational learning is a viable option to make large VLMs safer and more trustworthy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Variational VQA, an extension of variational Bayesian methods to vision-language models for uncertainty-aware selective prediction on VQA and visual reasoning tasks. It claims that variational inference improves calibration, enables reliable selective prediction (especially at error tolerances ≤1%), and that a single posterior sample often outperforms AdamW-trained models. A new risk-averse selector based on prediction variance is proposed and shown to outperform standard posterior averaging.
Significance. If the central experimental claims hold, the work would be significant for demonstrating that variational Bayes can be made tractable and effective for selective prediction in large multimodal models, offering a practical route to reduce overconfidence and hallucinations in VLMs. This could influence reliability-focused research in vision-language systems by providing evidence that uncertainty-aware methods yield gains beyond standard training and averaging.
major comments (3)
- [§5.2, Table 2] §5.2, Table 2: the reported improvement of the risk-averse selector over posterior averaging (approximately 1–2% absolute on VQA accuracy at 1% error tolerance) is not compared against a non-variational baseline trained to the same total compute budget or against simple averaging with an equal number of forward passes; without this, it is unclear whether the variance term provides gains beyond what posterior averaging already achieves.
- [§4.1, Eq. (8)–(10)] §4.1, Eq. (8)–(10): the variational posterior parameterization for the full-scale VLM is described at a high level but lacks explicit details on the number of additional parameters introduced by the variational distribution or the memory/compute overhead relative to standard fine-tuning; this information is load-bearing for the tractability claim when scaling to large multimodal transformers.
- [§5.1, Figure 3] §5.1, Figure 3: the claim that one posterior sample yields more reliable answers than AdamW models is supported by point estimates but lacks error bars across random seeds or statistical tests; given the known sensitivity of VQA metrics to initialization, this weakens the assertion that variational sampling is reliably superior at low sample counts.
minor comments (2)
- [Abstract] The abstract states performance claims without referencing the specific datasets or metrics used; the introduction or experimental section should explicitly list the VQA and visual reasoning benchmarks together with their statistics.
- [§3.3] Notation for the risk-averse selector (variance of predictions) is introduced in §3.3 but not contrasted with existing uncertainty-aware abstention methods in the related-work section; adding 1–2 sentences would improve context.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5.2, Table 2] the reported improvement of the risk-averse selector over posterior averaging (approximately 1–2% absolute on VQA accuracy at 1% error tolerance) is not compared against a non-variational baseline trained to the same total compute budget or against simple averaging with an equal number of forward passes
Authors: We agree that direct comparisons to non-variational baselines under matched compute and to simple averaging with an equal number of forward passes would strengthen the evidence that the variance term adds value beyond posterior averaging. In the revised manuscript we will add these baselines, trained to the same total compute budget, and report the corresponding selective prediction results at low error tolerances. revision: yes
-
Referee: [§4.1, Eq. (8)–(10)] the variational posterior parameterization for the full-scale VLM is described at a high level but lacks explicit details on the number of additional parameters introduced by the variational distribution or the memory/compute overhead relative to standard fine-tuning
Authors: We acknowledge that explicit quantification of the additional parameters and overhead is necessary to substantiate the tractability claim. In the revised version we will provide the exact number of extra parameters introduced by the variational distribution, together with a breakdown of memory and compute overhead relative to standard AdamW fine-tuning of the same VLM backbone. revision: yes
-
Referee: [§5.1, Figure 3] the claim that one posterior sample yields more reliable answers than AdamW models is supported by point estimates but lacks error bars across random seeds or statistical tests
Authors: We agree that error bars and statistical tests are important given the known sensitivity of VQA metrics to initialization. We will recompute the results in Figure 3 across multiple random seeds, add error bars, and include statistical significance tests in the revised manuscript to support the claim that a single posterior sample is reliably superior at low sample counts. revision: yes
Circularity Check
No circularity: method extends standard variational inference to VQA with independent empirical claims
full rationale
The paper introduces Variational VQA as an application of existing variational deep learning techniques to selective prediction in VQA and visual reasoning. Claims of improved calibration, gains from a variance-based selector over averaging, and superiority of single posterior samples over AdamW are presented as empirical findings rather than derivations that reduce to inputs by construction. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the central result are evident from the provided text. The work is self-contained against external benchmarks via proposed extensions and reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lawrence Zitnick, and Devi Parikh
13 Published in Transactions on Machine Learning Research (04/2026) Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. InInternational Conference on Computer Vision (ICCV),
work page 2026
-
[2]
Improving LoRA with Variational Learning.arXiv preprint arXiv:2506.14280,
Bai Cong, Nico Daheim, Yuesong Shen, Rio Yokota, Mohammad Emtiyaz Khan, and Thomas Möllenhoff. Improving LoRA with Variational Learning.arXiv preprint arXiv:2506.14280,
-
[3]
Why Language Models Hallucinate
14 Published in Transactions on Machine Learning Research (04/2026) Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why Language Models Hallucinate. arXiv preprint arXiv:2509.04664,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Variational Learning is Effective for Large Deep Networks
15 Published in Transactions on Machine Learning Research (04/2026) Yuesong Shen, Nico Daheim, Bai Cong, Peter Nickl, Gian Maria Marconi, Clement Bazan, Rio Yokota, Iryna Gurevych, Daniel Cremers, Mohammad Emtiyaz Khan, and Thomas Möllenhoff. Variational Learning is Effective for Large Deep Networks. InInternational Conference on Machine Learning (ICML),
work page 2026
-
[5]
Overpruning in Variational Bayesian Neural Networks
Brian Trippe and Richard Turner. Overpruning in Variational Bayesian Neural Networks.arXiv preprint arXiv:1801.06230,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
•Section B: Training and inference time differences between AdamW and VarVQA
16 Published in Transactions on Machine Learning Research (04/2026) Supplement •Section A: Hyperparameters for training and inference. •Section B: Training and inference time differences between AdamW and VarVQA. •Section C: The impact of common calibration methods on the baseline and on VarVQA. •Section D: Extended results from the main paper. •Section E...
work page 2026
-
[8]
to our VarVQA method and the baselines. •Section G: Measuringthreshold generalization(Section 4.2, seeCoverage at Risk),i.e.how close the test risk is to the target, given a validation-selected abstention threshold. •Section H: Comparing VarVQA to using a task-specific selector head (Whitehead et al., 2022), which requires an additional training phase. A ...
work page 2022
-
[9]
•BEiT-3 large is trained in mixed precision (bf16)
•As the default ViLT implementation has dropout = 0, we performed a hyperparameter search to find the optimal lr-dropout combination, which resulted in a slightly lower learning rate than the default (3·10−5vs.10 −4). •BEiT-3 large is trained in mixed precision (bf16). •Modest gradient clipping is added for all models. IVON Training.We generally follow Sh...
work page 2024
-
[10]
Our high-level findings and guidelines are as follows. •IVON needs gradient clapping for stability, as with no clipping, the Hessian estimate will frequently diverge. •The gradient clipping for IVON needs to be slightly higher than that of AdamW, as AdamW typically produces smaller gradients. 17 Published in Transactions on Machine Learning Research (04/2...
work page 2026
-
[11]
8a) and moderately higher for BEiT-3 large (Fig
Peak GPU memory when training on VQAv2 is slightly higher for BEiT-3 base (Fig. 8a) and moderately higher for BEiT-3 large (Fig. 8b), indicating that more work might be needed to improve the efficiency of IVON on large models. The training overhead also increases for larger models, from just 0.8%longer training with ViLT to4.2%with BEiT-3 large, partially...
work page 2026
-
[12]
on top of our trained models. For VQA, the models we investigate use sigmoids in the output layer5, therefore, temperature scaling cannot change relative confidence rankings (due to the strict monotonicity of the sigmoid). We thus use vector scaling and train a linear layer to learn the parameters, following Whitehead et al. (2022). For NLVR2, the binary ...
work page 2022
-
[13]
That, in turn, is due to the way that labels are inferred from the answers of 10 annotators,cf.Section 4.2. 19 Published in Transactions on Machine Learning Research (04/2026) NLVR2(cf.Tab.2), theadditionalstepoftemperaturescalingreversestheorder,i.e.VarVQA+temperature scaling achieves a lower ECE than AdamW Dropout + temperature scaling. As temperature s...
work page 2026
-
[14]
•Variational VQA reduces miscalibration in terms of the Expected Calibration Error (ECE)
The findings of the main paper for BEiT-3 large hold true across BEiT-3 base and ViLT, namely: 20 Published in Transactions on Machine Learning Research (04/2026) •Variational VQA is as effective as AdamW for training large multimodal models - it matches or sometimes even surpasses the accuracy obtained with AdamW. •Variational VQA reduces miscalibration ...
work page 2026
-
[15]
and NLVR2 (Fig. 21). For all examples, we set the abstention thresholdγby optimizingΦ100 on ID validation data6. We always pick examples where the answers of AdamW and VarVQA are identical and where the gap in their confidence is largest. Interestingly, a large number of examples where VarVQA performs better on NLVR2 seem to be related to counting, we lea...
work page 2026
-
[16]
The results for VQAv2 and NLVR2 are shown in Table 11 and Table 12, respectively
on top of all other previously explored confidence estimation methods, as training multiple models constitutes an orthogonal direction of investigation. The results for VQAv2 and NLVR2 are shown in Table 11 and Table 12, respectively. OnVQAv2, whichisthemuchlargerandthusmuchmorerobustdatasetintermsofthesensitive selective prediction metrics, VarVQA combin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.