ViTaPEs: Visuotactile Position Encodings for Cross-Modal Alignment in Multimodal Transformers
Pith reviewed 2026-05-19 13:16 UTC · model grok-4.3
The pith
ViTaPEs aligns vision and tactile inputs in transformers by adding local positional encodings per modality and a shared global encoding on the joint sequence before attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViTaPEs introduces a transformer-based model for task-agnostic visuotactile representation learning in which local positional encodings are injected within each modality stream and a global positional encoding is injected on the joint token sequence immediately before self-attention, providing an explicit shared positional vocabulary at the stage of cross-modal interaction.
What carries the argument
Two-stage positional injection, consisting of modality-specific local encodings added inside each stream and a shared global encoding added on the combined tokens immediately before self-attention.
If this is right
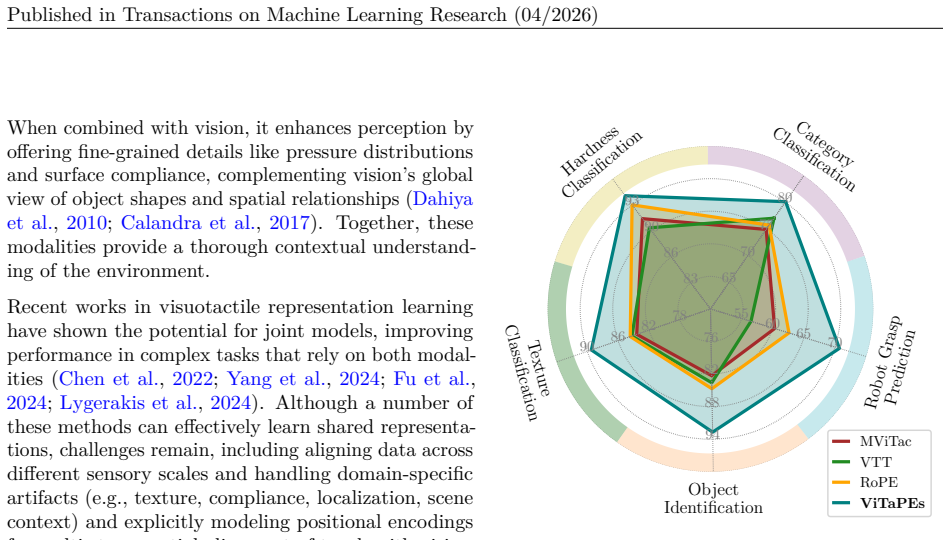
- The model surpasses state-of-the-art baselines on multiple recognition tasks across large-scale real-world datasets.
- It achieves zero-shot generalization to unseen out-of-domain scenarios.
- It improves grasp-success prediction over baselines in robotic transfer-learning experiments.
- Explicit ablations demonstrate the separate effects of local versus global positional injection points.
Where Pith is reading between the lines
- The same two-stage injection pattern could be tested on other paired sensory inputs such as audio-visual or proprioceptive-visual data.
- Reducing dependence on large pre-trained vision models might make visuotactile systems easier to deploy on resource-limited robots.
- The explicit separation of injection points offers a testable lever for studying how transformers build spatial correspondences across modalities.
Load-bearing premise
That controlled ablations isolating the timing of positional injection before nonlinearity versus before attention can cleanly credit performance gains to the two-stage global encoding strategy without interference from other model or data choices.
What would settle it
Running the same visuotactile recognition and grasping experiments after removing the global positional encoding before attention and observing no drop in accuracy or zero-shot performance.
Figures



read the original abstract
Tactile sensing provides local essential information that is complementary to visual perception, such as texture, compliance, and force. Despite recent advances in visuotactile representation learning, challenges remain in fusing these modalities and generalizing across tasks and environments without heavy reliance on pre-trained vision-language models. Moreover, existing methods do not study positional encodings, thereby overlooking the multi-stage spatial reasoning needed to capture fine-grained visuotactile correlations. We introduce ViTaPEs, a transformer-based architecture for learning task-agnostic visuotactile representations from paired vision and tactile inputs. Our key idea is a two-stage positional injection: local (modality-specific) positional encodings are added within each stream, and a global positional encoding is added on the joint token sequence immediately before attention, providing a shared positional vocabulary at the stage where cross-modal interaction occurs. We make the positional injection points explicit and conduct controlled ablations that isolate their effect before a token-wise nonlinearity versus immediately before self-attention. Experiments on multiple large-scale real-world datasets show that ViTaPEs not only surpasses state-of-the-art baselines across various recognition tasks but also demonstrates zero-shot generalization to unseen, out-of-domain scenarios. We further demonstrate the transfer-learning strength of \emph{ViTaPEs} in a robotic grasping task, where it outperforms state-of-the-art baselines in predicting grasp success. Project page: https://sites.google.com/view/vitapes
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ViTaPEs, a transformer-based architecture for task-agnostic visuotactile representation learning from paired vision and tactile inputs. Its central idea is a two-stage positional injection: local modality-specific encodings added within each stream, plus a global positional encoding on the joint token sequence immediately before self-attention to provide a shared vocabulary at the cross-modal stage. The authors report that this yields performance gains over state-of-the-art baselines on recognition tasks, zero-shot generalization to out-of-domain scenarios, and superior grasp-success prediction in robotic transfer learning, backed by experiments on multiple large-scale real-world datasets and controlled ablations isolating the injection timing.
Significance. If the empirical results are robust, the work would usefully emphasize the role of explicit positional encodings at the point of cross-modal interaction in multimodal transformers, with potential benefits for generalization in robotics and tactile sensing. The explicit treatment of injection points and the stated intent to run controlled ablations are positive elements that help isolate the contribution of the proposed global positional scheme.
major comments (1)
- [Ablation studies / Experiments] The ablation studies comparing positional injection before a token-wise nonlinearity versus immediately before self-attention do not state that every other factor (hyperparameters, data-augmentation pipeline, tokenization details, optimizer schedule, and random seeds) is held fixed across variants. Without this guarantee, performance deltas cannot be unambiguously credited to the two-stage global encoding at the cross-modal stage, weakening the causal link to the central architectural claim.
minor comments (2)
- [Abstract] The abstract asserts that ViTaPEs 'surpasses state-of-the-art baselines' and 'outperforms' in grasp success without supplying any quantitative metrics, baseline identifiers, or effect sizes; adding these would allow readers to gauge the claims immediately.
- [Method] Notation for the local and global positional encodings should be introduced with explicit equations or pseudocode early in the method section to avoid ambiguity when the two-stage scheme is later ablated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recommending major revision. We address the single major comment below regarding the ablation studies. We agree that explicit confirmation of experimental controls is important for strengthening the causal claims and will incorporate the necessary clarification in the revised manuscript.
read point-by-point responses
-
Referee: The ablation studies comparing positional injection before a token-wise nonlinearity versus immediately before self-attention do not state that every other factor (hyperparameters, data-augmentation pipeline, tokenization details, optimizer schedule, and random seeds) is held fixed across variants. Without this guarantee, performance deltas cannot be unambiguously credited to the two-stage global encoding at the cross-modal stage, weakening the causal link to the central architectural claim.
Authors: We thank the referee for this observation. Our ablation studies were designed as controlled experiments in which all other factors were held fixed: the same hyperparameter settings, data-augmentation pipeline, tokenization procedure, optimizer schedule, and random seeds were used for both variants, with the sole difference being the timing of the global positional encoding (before the token-wise nonlinearity versus immediately before self-attention). This setup was intended to isolate the contribution of the injection point at the cross-modal stage. We acknowledge that the manuscript does not explicitly state this guarantee and will add a clear sentence in the revised Experiments section confirming that all listed factors were identical across ablation variants. revision: yes
Circularity Check
No circularity in architecture or empirical claims
full rationale
The paper introduces ViTaPEs as a transformer architecture with explicit two-stage positional encodings (local modality-specific plus global on joint tokens before attention) and reports empirical gains from controlled ablations and experiments on real-world datasets. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present; the central claims rest on standard transformer building blocks plus reported performance deltas rather than reducing to inputs by construction. The ablations isolate injection timing but do not create self-referential loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit positional encodings are required to capture fine-grained spatial correlations when processing paired visual and tactile token sequences in transformers.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our key idea is a two-stage positional injection: local (modality-specific) positional encodings are added within each stream, and a global positional encoding is added on the joint token sequence immediately before attention
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We make the positional injection points explicit and conduct controlled ablations that isolate their effect before a token-wise nonlinearity versus immediately before self-attention
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Tactile-based Multimodal Fusion in Embodied Intelligence: A Survey of Vision, Language, and Contact-Driven Paradigms
A survey proposing a hierarchical taxonomy for multimodal tactile fusion datasets and methods across perception, generation, and interaction in embodied intelligence.
Reference graph
Works this paper leans on
-
[1]
doi: https://doi.org/10.1016/j.pneurobio.2023.102401
ISSN 0301-0082. doi: https://doi.org/10.1016/j.pneurobio.2023.102401. URL https: //www.sciencedirect.com/science/article/pii/S0301008223000011. Roberto Calandra, Andrew Owens, Dinesh Jayaraman, Justin Lin, Wenzhen Yuan, Jitendra Malik, Edward Adelson, and Sergey Levine. The feeling of success: Does touch sensing help predict grasp outcomes? In Proceedings...
-
[2]
doi: https://doi.org/10.1016/j.neubiorev.2023.105161
ISSN 0149-7634. doi: https://doi.org/10.1016/j.neubiorev.2023.105161. URL https://www.sciencedirect.com/science/article/pii/S0149763423001306. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An im...
-
[3]
doi: https://doi.org/10.1016/j.neunet.2023.12.042
ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2023.12.042. URL https://www.sciencedirect.com/science/ article/pii/S0893608023007499. 12 Published in Transactions on Machine Learning Research (04/2026) Letian Fu, Gaurav Datta, Huang Huang, William Chung-Ho Panitch, Jaimyn Drake, Joseph Ortiz, Mustafa Mukadam, Mike Lambeta, Roberto Calandra, and Ken...
-
[4]
Self-Attention with Relative Position Representations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations.arXiv preprint arXiv:1803.02155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
13 Published in Transactions on Machine Learning Research (04/2026) Tito Pradhono Tomo, Massimo Regoli, Alexander Schmitz, Lorenzo Natale, Harris Kristanto, Sophon Somlor, Lorenzo Jamone, Giorgio Metta, and Shigeki Sugano. A new silicone structure for uskin—a soft, distributed, digital 3-axis skin sensor and its integration on the humanoid robot icub.IEEE...
work page 2026
-
[6]
URLhttps://arxiv.org/abs/2502.14786. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, pp. 5998–6008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp
doi: 10.1109/ICCV51070. 2023.02017. Fengyu Yang et al. Binding touch to everything: Learning unified multimodal tactile representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26340–26353,
-
[8]
Wenzhen Yuan, Siyuan Dong, and Edward H Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017a. Wenzhen Yuan, Shaoxiong Wang, Siyuan Dong, and Edward H. Adelson. Connecting look and feel: Associating the visual and tactile properties of physical materials.IEEE Conference on Computer Vision an...
work page 2026
-
[9]
for data augmentation. For SSL training with MAE, target an effective batch size of 1024 via gradient accumulation, and apply random resized cropping as the augmentation strategy. A masking ratio of 75% is used to promote robust representation learning. Crucially, these augmentations are applied independently to the visual and tactile streams. This delibe...
work page 2026
-
[10]
features paired visual and tactile data captured in naturalistic settings, with tactile sensors interacting with various objects while simultaneously recording egocentric video. This dataset encompasses approximately 13,900 tactile interactions involving around 4,000 unique objects across 20 material categories, providing a diverse range of real-world sce...
work page 2022
-
[11]
provides comprehensive multisensory data for 100 common household items. Each object is documented through high-quality 3D meshes, HD rotation videos, and multiple tactile recordings from a GelSight sensor (Yuan et al., 2017a). The tactile recordings detail gel deformations upon contact, complemented by in-hand and third-view camera angles, enabling a com...
work page 2026
-
[12]
provides aligned RGB–tactile sliding interactions for 10 standard YCB objects (e.g., sugar box, tomato soup can, mustard bottle, bleach cleanser, mug, power drill, scissors, adjustable wrench, hammer, baseball). Data were captured by moving each object over a fixed DIGIT sensor mount, yielding over 180 000 frames pairing a 224×224 RGB crop with a 64×64 ta...
work page 2018
-
[13]
It consists the backbone architecture for all ResNet-based baselines in this paper
is often limited by its local receptive field and lack of attention-based mechanisms, making it less effective in capturing global spatial relationships across modalities. It consists the backbone architecture for all ResNet-based baselines in this paper. SSVTP (Kerr et al., 2023a)The Self-Supervised Visuotactile Pre-training (SSVTP) framework employs con...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.