Tactile-based Multimodal Fusion in Embodied Intelligence: A Survey of Vision, Language, and Contact-Driven Paradigms
Pith reviewed 2026-05-20 12:48 UTC · model grok-4.3
The pith
This survey unifies fragmented tactile-vision-language research in robotics through a new hierarchical taxonomy of datasets and methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
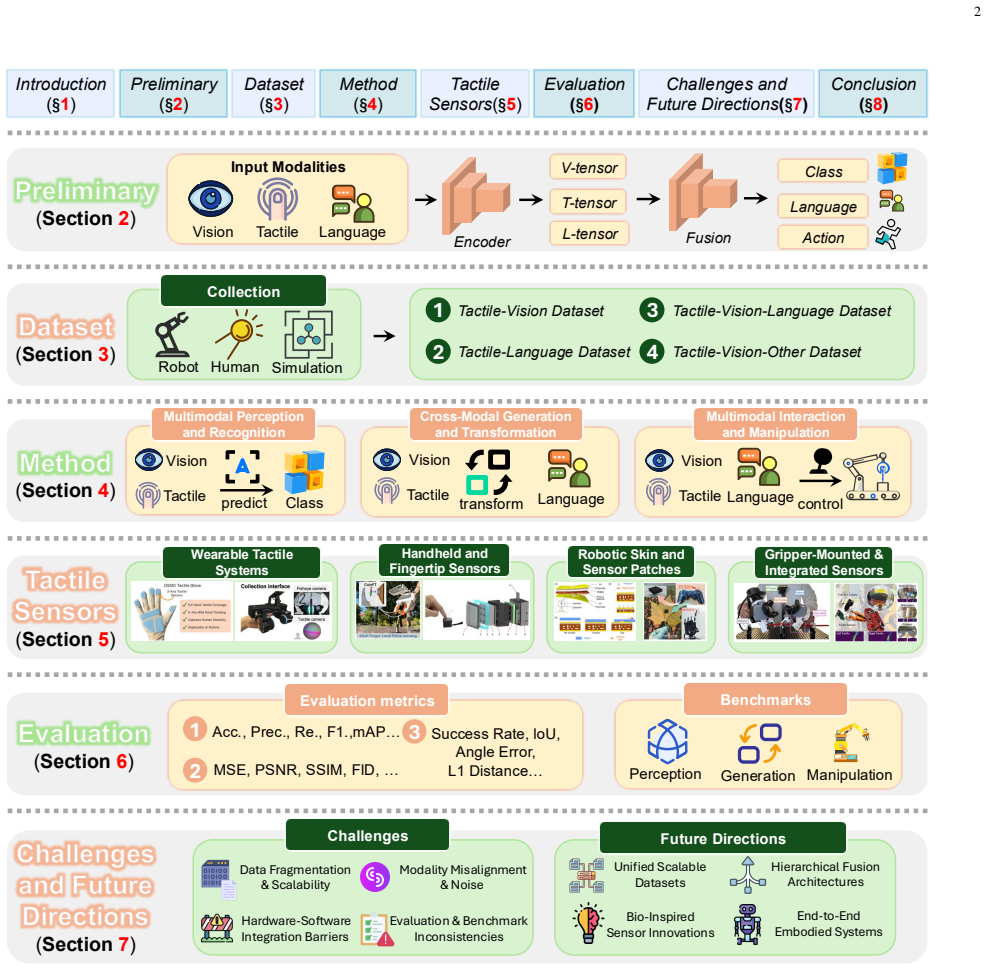
The paper establishes a hierarchical taxonomy that organizes multimodal tactile fusion research into multimodal datasets (Tactile-Vision, Tactile-Language, Tactile-Vision-Language, and Tactile-Vision-Other) and three core method pillars: Multimodal Perception and Recognition for object understanding and grasp prediction, Cross-Modal Generation for bidirectional translation between tactile, vision, and text, and Multimodal Interaction for feedback control and language-guided manipulation. It also reviews tactile hardware, evaluation metrics, benchmark settings, challenges, and future directions up to the first quarter of 2026.
What carries the argument
The hierarchical taxonomy that divides the field into modality-based datasets and the three method pillars of perception, cross-modal generation, and interaction.
If this is right
- Datasets can be systematically located by whether they pair tactile data with vision, language, both, or other signals.
- Perception and recognition methods improve grasp prediction by fusing local contact information with global visual context.
- Cross-modal generation allows models to produce tactile outputs from images or text descriptions and vice versa.
- Multimodal interaction supports closed-loop control where language instructions adjust actions based on real-time tactile feedback.
- Standardized metrics and benchmarks become comparable once work is mapped onto the same taxonomy.
Where Pith is reading between the lines
- The taxonomy could be extended by adding a fourth pillar for long-horizon planning that combines all three existing ones.
- Hardware reviews in the survey imply that future sensor designs should prioritize dense spatial coverage to better match vision resolution.
- Language-guided manipulation results suggest that large language models could be fine-tuned directly on tactile sequences to improve physical commonsense.
- Benchmark summaries point to the need for new testbeds that measure transfer from simulation to real contact-rich tasks.
Load-bearing premise
Existing tactile fusion studies are fragmented enough across datasets and tasks that a single new taxonomy can organize them without major omissions or overlaps through early 2026.
What would settle it
Discovery of a substantial body of post-2026 work or pre-2026 studies that cannot be placed into any of the four dataset categories or three method pillars without forcing overlaps or gaps.
Figures







read the original abstract
Tactile sensing is a fundamental modality for embodied intelligence, offering unique and direct feedback on contact geometry, material properties, and interaction dynamics that remote sensors cannot replace. However, unimodal tactile perception is inherently limited by its sparse spatial coverage and lack of global semantic context. With the recent explosion in deep learning and large language models, integrating tactile with vision and language has become essential to bridge physical interaction with semantic reasoning, leading to the emergence of Multimodal Tactile Fusion. Despite rapid progress, the existing researches remain fragmented across disparate datasets, sensing modalities, and tasks, lacking a unified theoretical framework. To address this gap, this paper provides a comprehensive survey of multimodal tactile fusion research up to the first quarter of 2026. We propose a hierarchical taxonomy that organizes the field into two primary dimensions: multimodal datasets and multimodal methods. On the data side, we categorize resources ranging from Tactile-Vision datasets, Tactile-Language datasets, Tactile-Vision-Language datasets, and Tactile-Vision-Other datasets. On the method side, we structure prior work into three core pillars: (1) Multimodal Perception and Recognition, which focuses on object understanding and grasp prediction; (2) Cross-Modal Generation, focusing on bidirectional translation between tactile, vision, and text; and (3) Multimodal Interaction, emphasizing feedback control and language-guided manipulation. Furthermore, we summarize representative tactile sensing hardware, review commonly used evaluation metrics and benchmark settings, and discuss current challenges and promising future directions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey paper reviews multimodal tactile fusion research in embodied intelligence up to the first quarter of 2026. It proposes a hierarchical taxonomy organizing the literature along two dimensions: multimodal datasets (categorized as Tactile-Vision, Tactile-Language, Tactile-Vision-Language, and Tactile-Vision-Other) and multimodal methods (structured into three pillars: Multimodal Perception and Recognition for object understanding and grasp prediction; Cross-Modal Generation for bidirectional translation between tactile, vision, and text; and Multimodal Interaction for feedback control and language-guided manipulation). The manuscript additionally summarizes tactile sensing hardware, common evaluation metrics and benchmarks, current challenges, and future directions.
Significance. If the taxonomy proves comprehensive and the coverage thorough without major omissions or overlaps, the paper would offer a valuable unifying framework for a fragmented research area. This could help researchers efficiently navigate datasets and methods for integrating tactile sensing with vision and language in robotics applications such as grasp prediction and language-guided manipulation. The organizational synthesis itself constitutes the primary contribution, as is typical for high-quality surveys.
minor comments (3)
- Abstract: the phrase 'existing researches remain fragmented' should be revised to 'existing research remains fragmented' or 'existing studies remain fragmented' for grammatical accuracy.
- Dataset categorization section: the boundary between 'Tactile-Vision-Language datasets' and 'Tactile-Vision-Other datasets' would benefit from an explicit statement of the decision criteria used to assign papers to each category, to minimize potential reader confusion about overlaps.
- Hardware review: a comparative table listing key specifications (spatial resolution, sensing area, sampling rate, and typical use cases) for the representative tactile sensors would improve clarity and utility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our survey and the recommendation for minor revision. The report accurately captures the scope, taxonomy, and contributions of the manuscript. No specific major comments were provided in the referee report.
Circularity Check
No significant circularity in survey taxonomy or synthesis
full rationale
The paper is a literature survey whose central contribution is a proposed hierarchical taxonomy that organizes existing multimodal tactile fusion research into dataset categories and three method pillars. This taxonomy is presented as an organizational synthesis of prior work rather than a derivation, prediction, or proof that reduces to the paper's own inputs by construction. All load-bearing elements rely on citations to external literature, with no self-referential definitions, fitted parameters renamed as predictions, or uniqueness theorems imported from the authors' prior work. The structure is self-contained as a review and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a hierarchical taxonomy that organizes the field into two primary dimensions: multimodal datasets and multimodal methods. On the data side, we categorize resources ranging from Tactile-Vision datasets, Tactile-Language datasets, Tactile-Vision-Language datasets, and Tactile-Vision-Other datasets. On the method side, we structure prior work into three core pillars: (1) Multimodal Perception and Recognition... (2) Cross-Modal Generation... (3) Multimodal Interaction...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multimodal tactile fusion process comprises the following hierarchical stages... Modality-Specific Representation Learning... Cross-Modal Fusion and Joint Representation... Embodied Decoding and Task Execution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
V . Dave, F. Lygerakis, and E. Rueckert, “Multimodal visual- tactile representation learning through self-supervised con- trastive pre-training,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 8013– 8020
work page 2024
-
[2]
Bind- ing touch to everything: Learning unified multimodal tactile representations,
F. Yang, C. Feng, Z. Chen, H. Park, D. Wang, Y . Dou, Z. Zeng, X. Chen, R. Gangopadhyay, A. Owenset al., “Bind- ing touch to everything: Learning unified multimodal tactile representations,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024, pp. 26 340–26 353
work page 2024
-
[3]
A touch, vision, and language dataset for multimodal alignment,
L. Fu, G. Datta, H. Huang, W. C.-H. Panitch, J. Drake, J. Ortiz, M. Mukadam, M. Lambeta, R. Calandra, and K. Goldberg, “A touch, vision, and language dataset for multimodal alignment,” arXiv preprint arXiv:2402.13232, 2024
-
[4]
Towards comprehensive multimodal perception: Introducing the touch- language-vision dataset,
N. Cheng, Y . Li, J. Gao, B. Fang, J. Xu, and W. Han, “Towards comprehensive multimodal perception: Introducing the touch- language-vision dataset,”arXiv preprint arXiv:2403.09813, 2024
-
[5]
Cltp: Contrastive language- tactile pre-training for 3d contact geometry understanding,
W. Ma, X. Cao, Y . Zhang, C. Zhang, S. Yang, P. Hao, B. Fang, Y . Cai, S. Cui, and S. Wang, “Cltp: Contrastive language- tactile pre-training for 3d contact geometry understanding,” arXiv preprint arXiv:2505.08194, 2025
-
[6]
Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation,
N. Cheng, J. Xu, C. Guan, J. Gao, W. Wang, Y . Li, F. Meng, J. Zhou, B. Fang, and W. Han, “Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation,”Information Fusion, p. 103305, 2025
work page 2025
-
[7]
Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation,
C. Zhang, P. Hao, X. Cao, X. Hao, S. Cui, and S. Wang, “Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation,”arXiv preprint arXiv:2505.09577, 2025
-
[8]
Universal visuo-tactile video understanding for em- bodied interaction,
Y . Xie, M. Li, S. Li, X. Li, G. Chen, F. Ma, F. R. Yu, and W. Ding, “Universal visuo-tactile video understanding for em- bodied interaction,”arXiv preprint arXiv:2505.22566, 2025
-
[9]
Anytouch: Learning unified static-dynamic repre- sentation across multiple visuo-tactile sensors,
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y . Sun, B. Fang, and D. Hu, “Anytouch: Learning unified static-dynamic repre- sentation across multiple visuo-tactile sensors,”arXiv preprint arXiv:2502.12191, 2025
-
[10]
Vitac: Feature sharing between vision and tactile sensing for cloth texture recognition,
S. Luo, W. Yuan, E. Adelson, A. G. Cohn, and R. Fuentes, “Vitac: Feature sharing between vision and tactile sensing for cloth texture recognition,” in2018 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2018, pp. 2722–2727
work page 2018
-
[11]
Can vision feel touch? tactile-aware visual grasping for transparent objects,
L. Tong, K. Qian, Z. Yue, and S. Luo, “Can vision feel touch? tactile-aware visual grasping for transparent objects,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[12]
Surformer v1: Transformer-based surface classification using 18 tactile and vision features,
M. Kansana, E. Hossain, S. Rahimi, and N. Amiri Golilarz, “Surformer v1: Transformer-based surface classification using 18 tactile and vision features,”Information, vol. 16, no. 10, p. 839, 2025
work page 2025
-
[13]
Ra- touch: Retrieval-augmented touch understanding with enriched visual data,
Y . Cho, H. Kim, S. Kim, Y . Zhang, Y . Choi, and S. Hong, “Ra- touch: Retrieval-augmented touch understanding with enriched visual data,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 1288–1297
work page 2025
-
[14]
A survey of deep learning and its applications: a new paradigm to machine learning,
S. Dargan, M. Kumar, M. R. Ayyagari, and G. Kumar, “A survey of deep learning and its applications: a new paradigm to machine learning,”Archives of computational methods in engineering, vol. 27, no. 4, pp. 1071–1092, 2020
work page 2020
-
[15]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[16]
A Survey of Large Language Models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Donget al., “A survey of large language models,”arXiv preprint arXiv:2303.18223, vol. 1, no. 2, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 180– 15 190
work page 2023
-
[18]
Transformer in touch: A survey,
J. Gao, N. Cheng, B. Fang, and W. Han, “Transformer in touch: A survey,”arXiv preprint arXiv:2405.12779, 2024
-
[19]
Tactile data generation and applications based on visuo-tactile sensors: A review,
Y . Sun, N. Cheng, S. Zhang, W. Li, L. Yang, S. Cui, H. Liu, F. Sun, J. Zhang, D. Guoet al., “Tactile data generation and applications based on visuo-tactile sensors: A review,”Infor- mation Fusion, vol. 121, p. 103162, 2025
work page 2025
-
[20]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770– 778
work page 2016
-
[21]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Trans- formers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[22]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[23]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[24]
J. Yu, K. Zhang, and Y . Deng, “Recent progress in pressure and temperature tactile sensors: principle, classification, integration and outlook,”Soft Science, vol. 1, no. 1, pp. N–A, 2021
work page 2021
-
[25]
Classification of vision-based tactile sensors: A review,
H. Li, Y . Lin, C. Lu, M. Yang, E. Psomopoulou, and N. F. Lep- ora, “Classification of vision-based tactile sensors: A review,” IEEE Sensors Journal, 2025
work page 2025
-
[26]
M. Meribout, N. A. Takele, O. Derege, N. Rifiki, M. El Khalil, V . Tiwari, and J. Zhong, “Tactile sensors: A review,”Measure- ment, vol. 238, p. 115332, 2024
work page 2024
-
[27]
Recent progresses on flexi- ble tactile sensors,
Y . Wan, Y . Wang, and C. F. Guo, “Recent progresses on flexi- ble tactile sensors,”Materials Today Physics, vol. 1, pp. 61–73, 2017
work page 2017
-
[28]
A review of tactile information: Perception and action through touch,
Q. Li, O. Kroemer, Z. Su, F. F. Veiga, M. Kaboli, and H. J. Ritter, “A review of tactile information: Perception and action through touch,”IEEE Transactions on Robotics, vol. 36, no. 6, pp. 1619–1634, 2020
work page 2020
-
[29]
Biomimetic tactile sensors and signal processing with spike trains: A review,
Z. Yi, Y . Zhang, and J. Peters, “Biomimetic tactile sensors and signal processing with spike trains: A review,”Sensors and Actuators A: Physical, vol. 269, pp. 41–52, 2018
work page 2018
-
[30]
Gelsight: High- resolution robot tactile sensors for estimating geometry and force,
W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High- resolution robot tactile sensors for estimating geometry and force,”Sensors, vol. 17, no. 12, p. 2762, 2017
work page 2017
-
[31]
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammereret al., “Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation,”IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 3838–3845, 2020
work page 2020
-
[32]
L. Zhang, Y . Wang, and Y . Jiang, “Tac3d: A novel vision- based tactile sensor for measuring forces distribution and estimating friction coefficient distribution,”arXiv preprint arXiv:2202.06211, 2022
-
[33]
Gelstereo 2.0: An improved gelstereo sensor with multimedium refractive stereo calibration,
C. Zhang, S. Cui, S. Wang, J. Hu, Y . Cai, R. Wang, and Y . Wang, “Gelstereo 2.0: An improved gelstereo sensor with multimedium refractive stereo calibration,”IEEE Transactions on Industrial Electronics, vol. 71, no. 7, pp. 7452–7462, 2023
work page 2023
-
[34]
I. H. Taylor, S. Dong, and A. Rodriguez, “Gelslim 3.0: High- resolution measurement of shape, force and slip in a compact tactile-sensing finger,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 10 781– 10 787
work page 2022
-
[35]
Omnitact: A multi-directional high-resolution touch sensor,
A. Padmanabha, F. Ebert, S. Tian, R. Calandra, C. Finn, and S. Levine, “Omnitact: A multi-directional high-resolution touch sensor,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 618–624
work page 2020
-
[36]
Seeing through your skin: Rec- ognizing objects with a novel visuotactile sensor,
F. R. Hogan, M. Jenkin, S. Rezaei-Shoshtari, Y . Girdhar, D. Meger, and G. Dudek, “Seeing through your skin: Rec- ognizing objects with a novel visuotactile sensor,” inProceed- ings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 1218–1227
work page 2021
-
[37]
Multimodal alignment and fusion: A sur- vey,
S. Li and H. Tang, “Multimodal alignment and fusion: A sur- vey,”arXiv preprint arXiv:2411.17040, 2024
-
[38]
A survey on multimodal large language models,
S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, and E. Chen, “A survey on multimodal large language models,”National Science Review, vol. 11, no. 12, p. nwae403, 2024
work page 2024
-
[39]
L. Li, G. Chen, H. Wang, B. Li, B. Wang, Z. Yi, and C. Zhao, “Vhtformer: A joint query perception method for visual-haptic- textual information based on transformer,”Applied Soft Com- puting, p. 113529, 2025
work page 2025
-
[40]
Visual–tactile fusion for object recognition,
H. Liu, Y . Yu, F. Sun, and J. Gu, “Visual–tactile fusion for object recognition,”IEEE Transactions on Automation Science and Engineering, vol. 14, no. 2, pp. 996–1008, 2016
work page 2016
-
[41]
The feeling of success: Does touch sensing help predict grasp outcomes?
R. Calandra, A. Owens, M. Upadhyaya, W. Yuan, J. Lin, E. H. Adelson, and S. Levine, “The feeling of success: Does touch sensing help predict grasp outcomes?”arXiv preprint arXiv:1710.05512, 2017
-
[42]
Connecting look and feel: Associating the visual and tactile properties of physical materials,
W. Yuan, S. Wang, S. Dong, and E. Adelson, “Connecting look and feel: Associating the visual and tactile properties of physical materials,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5580–5588
work page 2017
-
[43]
More than a feeling: Learning to grasp and regrasp using vision and touch,
R. Calandra, A. Owens, D. Jayaraman, J. Lin, W. Yuan, J. Ma- lik, E. H. Adelson, and S. Levine, “More than a feeling: Learning to grasp and regrasp using vision and touch,”IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3300–3307, 2018
work page 2018
-
[44]
Multimodal grasp data set: A novel visual–tactile data set for robotic manipulation,
T. Wang, C. Yang, F. Kirchner, P. Du, F. Sun, and B. Fang, “Multimodal grasp data set: A novel visual–tactile data set for robotic manipulation,”International Journal of Advanced Robotic Systems, vol. 16, no. 1, p. 1729881418821571, 2019
work page 2019
-
[45]
Connecting touch and vision via cross-modal prediction,
Y . Li, J.-Y . Zhu, R. Tedrake, and A. Torralba, “Connecting touch and vision via cross-modal prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 609–10 618
work page 2019
-
[46]
Touch and go: Learning from human-collected vision and touch,
F. Yang, C. Ma, J. Zhang, J. Zhu, W. Yuan, and A. Owens, “Touch and go: Learning from human-collected vision and touch,”arXiv preprint arXiv:2211.12498, 2022
-
[47]
Controllable visual-tactile synthesis,
R. Gao, W. Yuan, and J.-Y . Zhu, “Controllable visual-tactile synthesis,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision, 2023, pp. 7040–7052
work page 2023
-
[48]
Learning to jointly understand visual and tactile signals,
Y . Li, Y . Du, C. Liu, F. Williams, M. Foshey, B. Eckart, J. Kautz, J. B. Tenenbaum, A. Torralba, and W. Matusik, “Learning to jointly understand visual and tactile signals,” in 19 The Twelfth International Conference on Learning Represen- tations, 2023
work page 2023
-
[49]
Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile grip- per,
X. Zhu, B. Huang, and Y . Li, “Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile grip- per,”arXiv preprint arXiv:2507.15062, 2025
-
[50]
Octopi: Object property reasoning with large tactile-language models,
S. Yu, K. Lin, A. Xiao, J. Duan, and H. Soh, “Octopi: Object property reasoning with large tactile-language models,”arXiv preprint arXiv:2405.02794, 2024
-
[51]
N. Cheng, J. Xu, J. Chen, and W. Han, “Stola: Self- adaptive touch-language framework with tactile common- sense reasoning in open-ended scenarios,”arXiv preprint arXiv:2505.04201, 2025
-
[52]
Multi-modal representation learning with tactile data,
H.-G. Chi, J. Barreiros, J. Mercat, K. Ramani, and T. Kol- lar, “Multi-modal representation learning with tactile data,” in 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 9660–9667
work page 2024
-
[53]
Damf: A semantic-guided dynamic attention frame- work for visual-haptic-textual multimodal fusion,
B. Wang, B. Li, T. Gao, L. Li, H. Wang, C. Zhao, and Z. Yi, “Damf: A semantic-guided dynamic attention frame- work for visual-haptic-textual multimodal fusion,”Knowledge- Based Systems, p. 114244, 2025
work page 2025
-
[54]
Tvt- transformer: A tactile-visual-textual fusion network for object recognition,
B. Li, L. Li, H. Wang, G. Chen, B. Wang, and S. Qiu, “Tvt- transformer: A tactile-visual-textual fusion network for object recognition,”Information Fusion, vol. 118, p. 102943, 2025
work page 2025
-
[55]
Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing,
Z. Cheng, Y . Zhang, W. Zhang, H. Li, K. Wang, L. Song, and H. Zhang, “Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing,”arXiv preprint arXiv:2508.08706, 2025
-
[56]
Ob- jectfolder: A dataset of objects with implicit visual, auditory, and tactile representations,
R. Gao, Y .-Y . Chang, S. Mall, L. Fei-Fei, and J. Wu, “Ob- jectfolder: A dataset of objects with implicit visual, auditory, and tactile representations,”arXiv preprint arXiv:2109.07991, 2021
-
[57]
Objectfolder 2.0: A multisensory object dataset for sim2real transfer,
R. Gao, Z. Si, Y .-Y . Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, and J. Wu, “Objectfolder 2.0: A multisensory object dataset for sim2real transfer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 598–10 608
work page 2022
-
[58]
The objectfolder benchmark: Multisensory learning with neural and real objects,
R. Gao, Y . Dou, H. Li, T. Agarwal, J. Bohg, Y . Li, L. Fei- Fei, and J. Wu, “The objectfolder benchmark: Multisensory learning with neural and real objects,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2023, pp. 17 276–17 286
work page 2023
-
[59]
Tla: Tactile-language-action model for contact-rich manipu- lation,
P. Hao, C. Zhang, D. Li, X. Cao, X. Hao, S. Cui, and S. Wang, “Tla: Tactile-language-action model for contact-rich manipu- lation,”arXiv preprint arXiv:2503.08548, 2025
-
[60]
Freetacman: Robot-free visuo-tactile data col- lection system for contact-rich manipulation,
L. Wu, C. Yu, J. Ren, L. Chen, Y . Jiang, R. Huang, G. Gu, and H. Li, “Freetacman: Robot-free visuo-tactile data col- lection system for contact-rich manipulation,”arXiv preprint arXiv:2506.01941, 2025
-
[61]
Opentouch: Bring- ing full-hand touch to real-world interaction,
Y . R. Song, J. Li, R. Fu, D. Murphy, K. Zhou, R. Shiv, Y . Li, H. Xiong, C. E. Owens, Y . Duet al., “Opentouch: Bring- ing full-hand touch to real-world interaction,”arXiv preprint arXiv:2512.16842, 2025
-
[62]
Hoi! - A Multimodal Dataset for Force-Grounded, Cross-View Articulated Manipulation
T. Engelbracht, R. Zurbr ¨ugg, M. Wohlrapp, M. B ¨uchner, A. Valada, M. Pollefeys, H. Blum, and Z. Bauer, “Hoi!–a multimodal dataset for force-grounded, cross-view articulated manipulation,”arXiv preprint arXiv:2512.04884, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Vint-6d: A large-scale object-in-hand dataset from vision, touch and proprioception,
Z. Wan, Y . Ling, S. Yi, L. Qi, W. Lee, M. Lu, S. Yang, X. Teng, P. Lu, X. Yanget al., “Vint-6d: A large-scale object-in-hand dataset from vision, touch and proprioception,”arXiv preprint arXiv:2501.00510, 2024
-
[64]
Omnivta: Visuo-tactile world modeling for contact- rich robotic manipulation,
Y . Zheng, S. Gu, W. Li, Y . Zheng, Y . Zang, S. Tian, X. Li, R. Wu, C. Hao, C. Gao, S. Liu, H. Li, Y . Chen, S. Yan, and W. Ding, “Omnivta: Visuo-tactile world modeling for contact- rich robotic manipulation,” 2026
work page 2026
-
[65]
Imagenet clas- sification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet clas- sification with deep convolutional neural networks,”Advances in neural information processing systems, vol. 25, 2012
work page 2012
-
[66]
See, feel, act: Hierarchical learning for complex manipula- tion skills with multisensory fusion,
“See, feel, act: Hierarchical learning for complex manipula- tion skills with multisensory fusion,”Science Robotics, vol. 4, no. 26, p. eaav3123, 2019
work page 2019
-
[67]
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” inProceedings of the IEEE international conference on com- puter vision, 2017, pp. 2961–2969
work page 2017
-
[68]
I. Kononenko, “Bayesian neural networks,”Biological Cyber- netics, vol. 61, no. 5, pp. 361–370, 1989
work page 1989
-
[69]
X. Li, H. Liu, J. Zhou, and F. Sun, “Learning cross-modal visual-tactile representation using ensembled generative adver- sarial networks,”Cognitive Computation and Systems, vol. 1, no. 2, pp. 40–44, 2019
work page 2019
-
[70]
Gen- erative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Gen- erative adversarial nets,”Advances in neural information pro- cessing systems, vol. 27, 2014
work page 2014
-
[71]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei- Fei, A. Garg, and J. Bohg, “Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks,” in2019 International conference on robotics and automation (ICRA). IEEE, 2019, pp. 8943–8950
work page 2019
-
[72]
Flownet: Learning optical flow with convolutional networks,
A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V . Golkov, P. Van Der Smagt, D. Cremers, and T. Brox, “Flownet: Learning optical flow with convolutional networks,” inProceedings of the IEEE international conference on com- puter vision, 2015, pp. 2758–2766
work page 2015
-
[73]
Lifelong visual-tactile cross- modal learning for robotic material perception,
W. Zheng, H. Liu, and F. Sun, “Lifelong visual-tactile cross- modal learning for robotic material perception,”IEEE transac- tions on neural networks and learning systems, vol. 32, no. 3, pp. 1192–1203, 2020
work page 2020
-
[74]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[75]
Visuo-tactile transformers for manipulation,
Y . Chen, A. Sipos, M. Van der Merwe, and N. Fazeli, “Visuo-tactile transformers for manipulation,”arXiv preprint arXiv:2210.00121, 2022
-
[76]
Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,
J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek, “Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,” in2022 Interna- tional Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8298–8304
work page 2022
-
[77]
Mastering vi- sual continuous control: Improved data-augmented reinforce- ment learning,
D. Yarats, R. Fergus, A. Lazaric, and L. Pinto, “Mastering vi- sual continuous control: Improved data-augmented reinforce- ment learning,”arXiv preprint arXiv:2107.09645, 2021
-
[78]
Vito-transformer: a visual-tactile fusion network for object recognition,
B. Li, J. Bai, S. Qiu, H. Wang, and Y . Guo, “Vito-transformer: a visual-tactile fusion network for object recognition,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–10, 2023
work page 2023
-
[79]
Mlp-mixer: An all-mlp architecture for vision,
I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai, T. Unterthiner, J. Yung, A. Steiner, D. Keysers, J. Uszkoreit et al., “Mlp-mixer: An all-mlp architecture for vision,”Ad- vances in neural information processing systems, vol. 34, pp. 24 261–24 272, 2021
work page 2021
-
[80]
Fine-tuned clip models are efficient video learners,
H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan, “Fine-tuned clip models are efficient video learners,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6545–6554
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.