Rodrigues Network for Learning Robot Actions
Pith reviewed 2026-05-19 11:21 UTC · model grok-4.3
The pith
A learnable version of forward kinematics adds physical structure to neural nets for better robot action learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the Neural Rodrigues Operator generalizes the classical Rodrigues formula for computing rotations so that it becomes a differentiable, learnable module; when this module is used to build the Rodrigues Network, the resulting architecture demonstrates higher expressivity on kinematic and motion tasks and transfers effectively to improve imitation learning on robot benchmarks and 3D hand reconstruction from images.
What carries the argument
The Neural Rodrigues Operator, a learnable generalization of the classical forward kinematics operation that computes rotations while remaining trainable inside the network.
Load-bearing premise
The Neural Rodrigues Operator supplies a useful kinematic inductive bias that transfers from synthetic tasks to real robotic and vision applications without creating new failure modes.
What would settle it
Replacing the Neural Rodrigues Operator inside RodriNet with a standard linear or attention layer and observing equal or worse performance on the robotic imitation-learning benchmarks would falsify the claim that the kinematic prior is responsible for the gains.
Figures




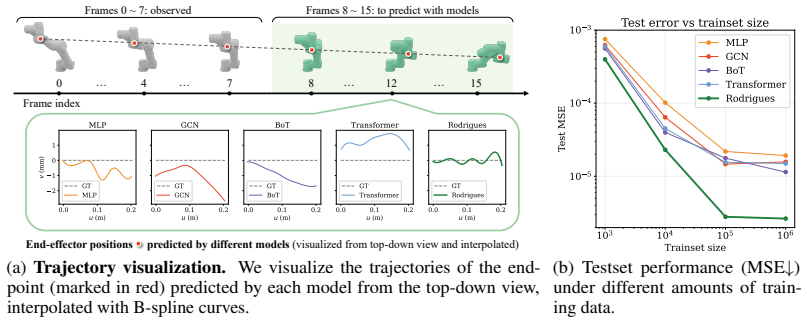

read the original abstract
Understanding and predicting articulated actions is important in robot learning. However, common architectures such as MLPs and Transformers lack inductive biases that reflect the underlying kinematic structure of articulated systems. To this end, we propose the Neural Rodrigues Operator, a learnable generalization of the classical forward kinematics operation, designed to inject kinematics-aware inductive bias into neural computation. Building on this operator, we design the Rodrigues Network (RodriNet), a novel neural architecture specialized for processing actions. We evaluate the expressivity of our network on two synthetic tasks on kinematic and motion prediction, showing significant improvements compared to standard backbones. We further demonstrate its effectiveness in two realistic applications: (i) imitation learning on robotic benchmarks with the Diffusion Policy, and (ii) single-image 3D hand reconstruction. Our results suggest that integrating structured kinematic priors into the network architecture improves action learning in various domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Neural Rodrigues Operator, a learnable generalization of the classical Rodrigues rotation formula, to embed kinematic inductive biases into neural architectures. It builds the Rodrigues Network (RodriNet) for action processing and reports performance gains on two synthetic tasks (kinematic and motion prediction) relative to standard backbones, plus downstream improvements when integrated into Diffusion Policy for robotic imitation learning and into single-image 3D hand reconstruction.
Significance. If the central claim holds after proper controls, the work would be significant for robot learning: it offers a concrete mechanism for injecting structured kinematic priors directly into network layers rather than relying solely on data or post-hoc regularization, with demonstrated transfer to both synthetic benchmarks and two realistic applications.
major comments (3)
- [Experiments] Synthetic tasks evaluation: no ablation studies or parameter-matched baselines (e.g., MLPs or Transformers with identical layer count and width) are reported, so it remains unclear whether observed gains arise from the kinematic structure of the Neural Rodrigues Operator or from increased model capacity alone.
- [Method] Neural Rodrigues Operator definition: the manuscript does not demonstrate that the learned operator reduces to the classical Rodrigues formula for suitable parameter settings, which is required to substantiate the claim that it functions as a generalization rather than an arbitrary reparameterization.
- [Applications] Real-world applications: the robotic benchmark and hand-reconstruction results lack error bars, statistical significance tests, or detailed hyperparameter reporting, leaving the transfer of the inductive bias to practical domains only weakly supported.
minor comments (2)
- [Abstract] Abstract states 'significant improvements' without any numerical metrics, error bars, or specific task names.
- [Method] Notation for the learnable parameters inside the Neural Rodrigues Operator should be made fully explicit to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have prepared revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Experiments] Synthetic tasks evaluation: no ablation studies or parameter-matched baselines (e.g., MLPs or Transformers with identical layer count and width) are reported, so it remains unclear whether observed gains arise from the kinematic structure of the Neural Rodrigues Operator or from increased model capacity alone.
Authors: We agree that parameter-matched controls are essential to isolate the effect of the kinematic inductive bias. In the revised version we will add ablation experiments comparing RodriNet against MLPs and Transformers that use identical layer counts, widths, and total parameter budgets on the same synthetic kinematic and motion-prediction tasks. These results will be reported alongside the original numbers to clarify the source of the observed improvements. revision: yes
-
Referee: [Method] Neural Rodrigues Operator definition: the manuscript does not demonstrate that the learned operator reduces to the classical Rodrigues formula for suitable parameter settings, which is required to substantiate the claim that it functions as a generalization rather than an arbitrary reparameterization.
Authors: We acknowledge that an explicit reduction to the classical Rodrigues formula is necessary to support the generalization claim. We will add a dedicated subsection (with accompanying derivation in the appendix) showing that, when the learnable parameters are constrained to the axis-angle representation and the scaling factors are set to unity, the Neural Rodrigues Operator exactly recovers the classical formula. This will be accompanied by a numerical verification on a set of rotation matrices. revision: yes
-
Referee: [Applications] Real-world applications: the robotic benchmark and hand-reconstruction results lack error bars, statistical significance tests, or detailed hyperparameter reporting, leaving the transfer of the inductive bias to practical domains only weakly supported.
Authors: We agree that more rigorous statistical reporting is required. The revised manuscript will include error bars (standard deviation over five independent runs), paired t-test p-values against the strongest baseline, and a comprehensive hyperparameter table in the supplementary material for both the Diffusion Policy integration and the hand-reconstruction experiments. revision: yes
Circularity Check
No circularity in derivation; architecture introduced as novel inductive bias with empirical validation
full rationale
The paper defines the Neural Rodrigues Operator explicitly as a learnable generalization of the classical Rodrigues formula for forward kinematics and constructs RodriNet around this operator. All reported results consist of direct empirical comparisons on synthetic kinematic tasks, robotic imitation learning, and hand reconstruction; no step equates a fitted parameter or self-cited premise to the final performance metric by algebraic construction. The central claim therefore rests on architectural design plus external benchmarks rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classical forward kinematics via the Rodrigues formula can be usefully generalized into a differentiable, learnable neural operator.
invented entities (1)
-
Neural Rodrigues Operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We identify Rodrigues’ rotation formula as the basic operator in articulated forward kinematics and generalize it into a learnable form... F_out = F_in(W_bias + W_cos cos Θ + W_sin sin Θ)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanD3_admits_circle_linking matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
forward kinematics... hierarchical composition of fixed coordinate transformations and dynamic rotations in the axis-angle representation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
ViTacFormer: Learning Cross-Modal Representation for Visuo-Tactile Dexterous Manipulation
ViTacFormer learns a cross-modal visuo-tactile latent space with autoregressive tactile prediction and an easy-to-hard curriculum, then uses the representation for imitation learning that yields ~50% higher success an...
Reference graph
Works this paper leans on
-
[1]
URL https://www.shadowrobot.com/dexterous-hand-series/, 2005
ShadowRobot. URL https://www.shadowrobot.com/dexterous-hand-series/, 2005
work page 2005
-
[2]
Skeleton-aware networks for deep motion retargeting
Kfir Aberman, Peizhuo Li, Dani Lischinski, Olga Sorkine-Hornung, Daniel Cohen-Or, and Baoquan Chen. Skeleton-aware networks for deep motion retargeting. ACM Transactions on Graphics (TOG), 39(4):62–1, 2020
work page 2020
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Spectral Networks and Locally Connected Networks on Graphs
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs. arXiv preprint arXiv:1312.6203, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
Jolo-gcn: mining joint-centered light-weight information for skeleton-based action recognition
Jinmiao Cai, Nianjuan Jiang, Xiaoguang Han, Kui Jia, and Jiangbo Lu. Jolo-gcn: mining joint-centered light-weight information for skeleton-based action recognition. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2735–2744, 2021
work page 2021
-
[6]
A computational approach to edge detection
John Canny. A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence, (6):679–698, 1986
work page 1986
-
[7]
Dexycb: A benchmark for capturing hand grasping of objects
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, et al. Dexycb: A benchmark for capturing hand grasping of objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9044–9053, 2021
work page 2021
-
[8]
Skeleton-aware graph- based adversarial networks for human pose estimation from sparse imus
Kaixin Chen, Lin Zhang, Zhong Wang, Shengjie Zhao, and Yicong Zhou. Skeleton-aware graph- based adversarial networks for human pose estimation from sparse imus. ACM Transactions on Multimedia Computing, Communications and Applications, 21(4):1–22, 2025
work page 2025
-
[9]
Decision transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084–15097, 2021
work page 2021
-
[10]
I2uv- handnet: Image-to-uv prediction network for accurate and high-fidelity 3d hand mesh modeling
Ping Chen, Yujin Chen, Dong Yang, Fangyin Wu, Qin Li, Qingpei Xia, and Yong Tan. I2uv- handnet: Image-to-uv prediction network for accurate and high-fidelity 3d hand mesh modeling. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12929– 12938, 2021. 10
work page 2021
-
[11]
Mobrecon: Mobile-friendly hand mesh reconstruction from monoc- ular image
Xingyu Chen, Yufeng Liu, Yajiao Dong, Xiong Zhang, Chongyang Ma, Yanmin Xiong, Yuan Zhang, and Xiaoyan Guo. Mobrecon: Mobile-friendly hand mesh reconstruction from monoc- ular image. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20544–20554, 2022
work page 2022
-
[12]
Channel-wise topology refinement graph convolution for skeleton-based action recognition
Yuxin Chen, Ziqi Zhang, Chunfeng Yuan, Bing Li, Ying Deng, and Weiming Hu. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 13359–13368, 2021
work page 2021
-
[13]
Skeleton- based action recognition with shift graph convolutional network
Ke Cheng, Yifan Zhang, Xiangyu He, Weihan Chen, Jian Cheng, and Hanqing Lu. Skeleton- based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 183–192, 2020
work page 2020
-
[14]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[15]
Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose
Hongsuk Choi, Gyeongsik Moon, and Kyoung Mu Lee. Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose. In Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pages 769–787. Springer, 2020
work page 2020
-
[16]
Optimizing network structure for 3d human pose estimation
Hai Ci, Chunyu Wang, Xiaoxuan Ma, and Yizhou Wang. Optimizing network structure for 3d human pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2262–2271, 2019
work page 2019
-
[17]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Robotics dexterous grasping: The methods based on point cloud and deep learning
Haonan Duan, Peng Wang, Yayu Huang, Guangyun Xu, Wei Wei, and Xiaofei Shen. Robotics dexterous grasping: The methods based on point cloud and deep learning. Frontiers in Neuro- robotics, 15:658280, 2021
work page 2021
-
[19]
Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time
Hao-Shu Fang, Jiefeng Li, Hongyang Tang, Chao Xu, Haoyi Zhu, Yuliang Xiu, Yong-Lu Li, and Cewu Lu. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE transactions on pattern analysis and machine intelligence, 45(6):7157–7173, 2022
work page 2022
-
[20]
arXiv preprint arXiv:2504.18904 , year=
Haoran Geng, Feishi Wang, Songlin Wei, Yuyang Li, Bangjun Wang, Boshi An, Charlie Tianyue Cheng, Haozhe Lou, Peihao Li, Yen-Jen Wang, Yutong Liang, Dylan Goetting, Chaoyi Xu, Haozhe Chen, Yuxi Qian, Yiran Geng, Jiageng Mao, Weikang Wan, Mingtong Zhang, Jiangran Lyu, Siheng Zhao, Jiazhao Zhang, Jialiang Zhang, Chengyang Zhao, Haoran Lu, Yufei Ding, Ran Gon...
-
[21]
Honnotate: A method for 3d annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. Honnotate: A method for 3d annotation of hand and object poses. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3196–3206, 2020
work page 2020
-
[22]
Structure-aware transformer policy for inhomogeneous multi-task reinforcement learning
Sunghoon Hong, Deunsol Yoon, and Kee-Eung Kim. Structure-aware transformer policy for inhomogeneous multi-task reinforcement learning. In International Conference on Learning Representations, 2021
work page 2021
-
[23]
Hand-object contact consis- tency reasoning for human grasps generation
Hanwen Jiang, Shaowei Liu, Jiashun Wang, and Xiaolong Wang. Hand-object contact consis- tency reasoning for human grasps generation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11107–11116, 2021. 11
work page 2021
-
[24]
Zheheng Jiang, Hossein Rahmani, Sue Black, and Bryan M Williams. A probabilistic attention model with occlusion-aware texture regression for 3d hand reconstruction from a single rgb image. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 758–767, 2023
work page 2023
-
[25]
Whole-body human pose estimation in the wild
Sheng Jin, Lumin Xu, Jin Xu, Can Wang, Wentao Liu, Chen Qian, Wanli Ouyang, and Ping Luo. Whole-body human pose estimation in the wild. In European Conference on Computer Vision, pages 196–214. Springer, 2020
work page 2020
-
[26]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012
work page 2012
-
[27]
SkillBlender: Towards versatile humanoid whole-body control via skill blending
Yuxuan Kuang, Amine Elhafsi, Haoran Geng, Marco Pavone, and Yue Wang. SkillBlender: Towards versatile humanoid whole-body control via skill blending. In CoRL 2024 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond
work page 2024
-
[28]
End-to-end human pose and mesh reconstruction with transformers
Kevin Lin, Lijuan Wang, and Zicheng Liu. End-to-end human pose and mesh reconstruction with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1954–1963, 2021
work page 1954
-
[29]
Kevin Lin, Lijuan Wang, and Zicheng Liu. Mesh graphormer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12939–12948, 2021
work page 2021
-
[30]
Deep differentiable grasp planner for high-dof grippers
Min Liu, Zherong Pan, Kai Xu, Kanishka Ganguly, and Dinesh Manocha. Deep differentiable grasp planner for high-dof grippers. arXiv preprint arXiv:2002.01530, 2020
-
[31]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
work page 2023
-
[32]
Gyeongsik Moon and Kyoung Mu Lee. I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single rgb image. In Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pages 752–768. Springer, 2020
work page 2020
-
[33]
Gyeongsik Moon, Shoou-I Yu, He Wen, Takaaki Shiratori, and Kyoung Mu Lee. Interhand2. 6m: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16, pages 548–564. Springer, 2020
work page 2020
-
[34]
Whole-body control of humanoid robots
Federico L Moro and Luis Sentis. Whole-body control of humanoid robots. Humanoid robotics: a reference, pages 1161–1183, 2019
work page 2019
-
[35]
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations. arXiv preprint arXiv:2107.14483, 2021
-
[36]
Learning convolutional neural networks for graphs
Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. Learning convolutional neural networks for graphs. In International conference on machine learning , pages 2014–2023. PMLR, 2016
work page 2014
-
[37]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024
work page 2024
-
[38]
Modeling human motion with quaternion-based neural networks
Dario Pavllo, Christoph Feichtenhofer, Michael Auli, and David Grangier. Modeling human motion with quaternion-based neural networks. International Journal of Computer Vision, 128: 855–872, 2020
work page 2020
-
[39]
Humanoid locomotion as next token prediction
Ilija Radosavovic, Bike Zhang, Baifeng Shi, Jathushan Rajasegaran, Sarthak Kamat, Trevor Darrell, Koushil Sreenath, and Jitendra Malik. Humanoid locomotion as next token prediction. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 12
work page 2024
-
[40]
Javier Romero, Dimitrios Tzionas, and Michael J Black. Embodied hands: Modeling and capturing hands and bodies together. arXiv preprint arXiv:2201.02610, 2022
-
[41]
Body transformer: Leveraging robot embodiment for policy learning
Carmelo Sferrazza, Dun-Ming Huang, Fangchen Liu, Jongmin Lee, and Pieter Abbeel. Body transformer: Leveraging robot embodiment for policy learning. arXiv preprint arXiv:2408.06316, 2024
-
[42]
Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning
Kenneth Shaw, Ananye Agarwal, and Deepak Pathak. Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning. arXiv preprint arXiv:2309.06440, 2023
-
[43]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. In Conference on Robot Learning, pages 785–799. PMLR, 2023
work page 2023
-
[44]
Hand keypoint detection in single images using multiview bootstrapping
Tomas Simon, Hanbyul Joo, Iain Matthews, and Yaser Sheikh. Hand keypoint detection in single images using multiview bootstrapping. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1145–1153, 2017
work page 2017
-
[45]
Yi-Fan Song, Zhang Zhang, Caifeng Shan, and Liang Wang. Stronger, faster and more explain- able: A graph convolutional baseline for skeleton-based action recognition. In proceedings of the 28th ACM international conference on multimedia, pages 1625–1633, 2020
work page 2020
-
[46]
Constructing stronger and faster baselines for skeleton-based action recognition
Yi-Fan Song, Zhang Zhang, Caifeng Shan, and Liang Wang. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE transactions on pattern analysis and machine intelligence, 45(2):1474–1488, 2022
work page 2022
-
[47]
Towards accurate alignment in real-time 3d hand- mesh reconstruction
Xiao Tang, Tianyu Wang, and Chi-Wing Fu. Towards accurate alignment in real-time 3d hand- mesh reconstruction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11698–11707, 2021
work page 2021
-
[48]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[49]
Neural kinematic networks for unsupervised motion retargetting
Ruben Villegas, Jimei Yang, Duygu Ceylan, and Honglak Lee. Neural kinematic networks for unsupervised motion retargetting. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8639–8648, 2018
work page 2018
-
[50]
Weikang Wan, Haoran Geng, Yun Liu, Zikang Shan, Yaodong Yang, Li Yi, and He Wang. Unidexgrasp++: Improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist-specialist learning. arXiv preprint arXiv:2304.00464, 2023
-
[51]
Monocular total capture: Posing face, body, and hands in the wild
Donglai Xiang, Hanbyul Joo, and Yaser Sheikh. Monocular total capture: Posing face, body, and hands in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10974, 2019
work page 2019
-
[52]
Sapien: A simulated part-based interactive environ- ment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive environ- ment. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
work page 2020
-
[53]
Yinzhen Xu, Weikang Wan, Jialiang Zhang, Haoran Liu, Zikang Shan, Hao Shen, Ruicheng Wang, Haoran Geng, Yijia Weng, Jiayi Chen, et al. Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. arXiv preprint arXiv:2303.00938, 2023
-
[54]
Spatial temporal graph convolutional networks for skeleton-based action recognition
Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[55]
Learning skeletal graph neural networks for hard 3d pose estimation
Ailing Zeng, Xiao Sun, Lei Yang, Nanxuan Zhao, Minhao Liu, and Qiang Xu. Learning skeletal graph neural networks for hard 3d pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11436–11445, 2021. 13
work page 2021
-
[56]
Jialiang Zhang, Haoran Liu, Danshi Li, Xinqiang Yu, Haoran Geng, Yufei Ding, Jiayi Chen, and He Wang. Dexgraspnet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes, 2024. URL https://arxiv.org/abs/2410.23004
-
[57]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Learning to estimate 3d hand pose from single rgb images
Christian Zimmermann and Thomas Brox. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE international conference on computer vision, pages 4903–4911, 2017
work page 2017
-
[59]
Freihand: A dataset for markerless capture of hand pose and shape from single rgb images
Christian Zimmermann, Duygu Ceylan, Jimei Yang, Bryan Russell, Max Argus, and Thomas Brox. Freihand: A dataset for markerless capture of hand pose and shape from single rgb images. In Proceedings of the IEEE/CVF international conference on computer vision, pages 813–822, 2019. 14 Supplementary Material This supplementary material provides additional detai...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.