No Data? No Problem: Synthesizing Security Graphs for Better Intrusion Detection
Pith reviewed 2026-05-19 10:34 UTC · model grok-4.3
The pith
PROVSYN synthesizes high-fidelity provenance graphs to improve intrusion detection accuracy by up to 38 percent
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
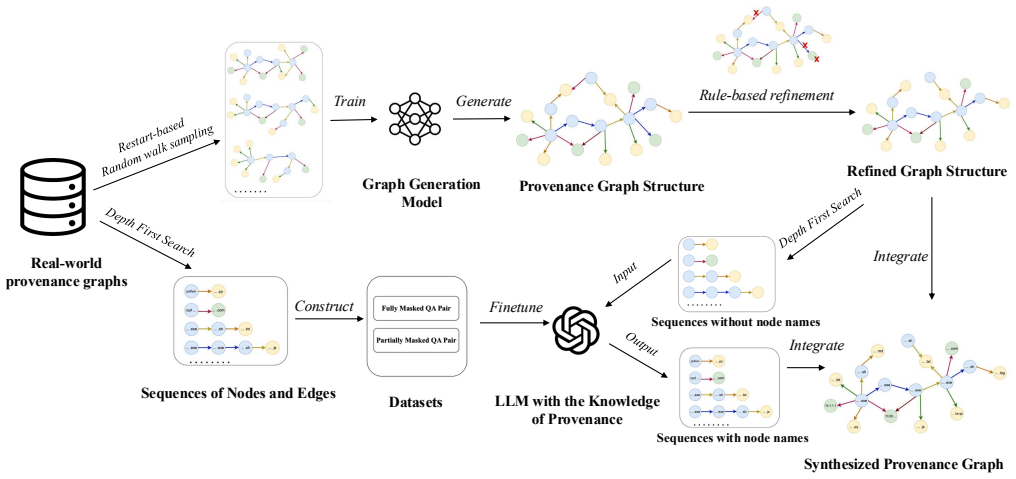
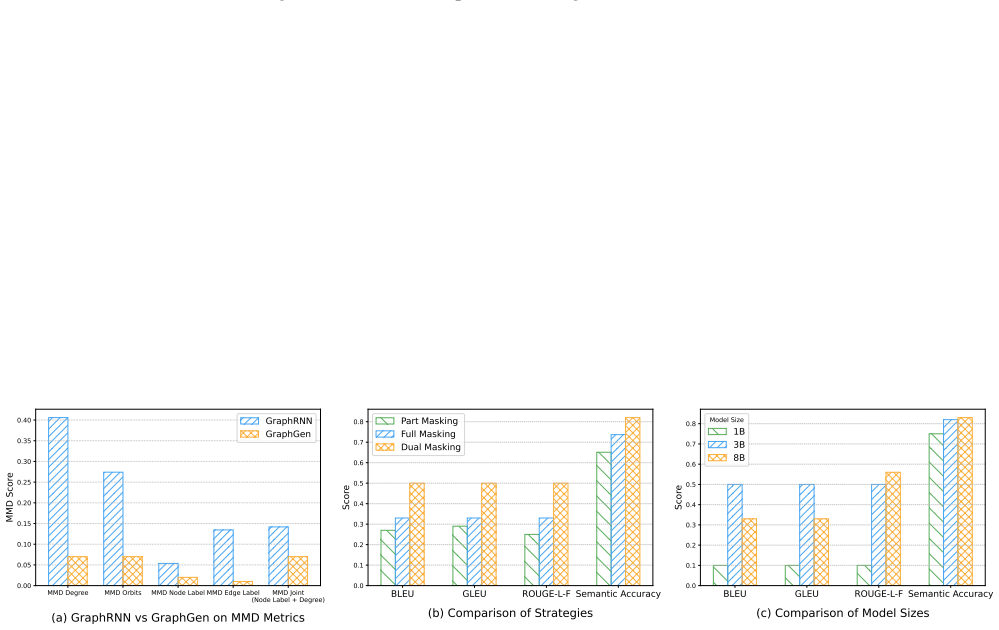
PROVSYN is a hybrid provenance graph synthesis framework comprising graph structure synthesis via heterogeneous graph generation models, textual attribute synthesis via fine-tuned large language models, and five-dimensional fidelity evaluation. On six benchmark datasets the method produces higher-fidelity graphs than four strong baselines; when the resulting graphs augment training sets they improve normalized entropy by up to 35 percent and raise downstream APT detection accuracy by up to 38 percent.
What carries the argument
PROVSYN, the three-part hybrid framework that pairs heterogeneous graph generation models for structure, fine-tuned LLMs for textual attributes, and a five-dimensional fidelity evaluation to verify quality before use in augmentation.
If this is right
- Augmented training sets allow graph neural networks combined with NLP to learn rare APT patterns that were previously under-represented.
- Higher-fidelity synthetic graphs reduce the chance that models learn spurious features introduced by poor synthesis.
- Improved normalized entropy directly supports more balanced class distributions across multiple existing benchmark collections.
- Downstream models become more generalizable, performing better on attack variants not seen during original data collection.
Where Pith is reading between the lines
- The same structure-plus-attribute synthesis approach could be tested on other scarce security graphs such as those used for malware or fraud detection.
- Embedding the synthesis step inside an online monitoring system might let detectors adapt continuously as new threat patterns emerge.
- Measuring how each of the five fidelity dimensions correlates with specific detection-error reductions could guide more targeted synthesis improvements.
Load-bearing premise
That gains measured on benchmark datasets and five fidelity metrics will carry over to real-world networks without introducing misleading artifacts or harmful distribution shifts.
What would settle it
Train detection models on original data versus original-plus-synthetic data, then measure accuracy and false-positive rates on a fresh, previously unseen real-world network trace containing actual APT activity.
Figures




read the original abstract
Provenance graph analysis plays a vital role in intrusion detection, particularly against Advanced Persistent Threats (APTs), by exposing complex attack patterns. While recent systems combine graph neural networks (GNNs) with natural language processing (NLP) to capture structural and semantic features, their effectiveness is limited by class imbalance in real-world data. To address this, we introduce PROVSYN, a novel hybrid provenance graph synthesis framework, which comprises three components: (1) graph structure synthesis via heterogeneous graph generation models, (2) textual attribute synthesis via fine-tuned Large Language Models (LLMs), and (3) five-dimensional fidelity evaluation. Experiments on six benchmark datasets demonstrate that PROVSYN consistently produces higher-fidelity graphs across the five evaluation dimensions compared to four strong baselines. To further demonstrate the practical utility of PROVSYN, we utilize the synthesized graphs to augment training datasets for downstream APT detection models. The results show that PROVSYN effectively mitigates data imbalance, improving normalized entropy by up to 35%, and enhances the generalizability of downstream detection models, achieving an accuracy improvement of up to 38%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PROVSYN, a hybrid provenance graph synthesis framework with three components: heterogeneous graph generation for structure, fine-tuned LLMs for textual attribute synthesis, and five-dimensional fidelity evaluation. Experiments on six benchmark datasets claim that PROVSYN produces higher-fidelity graphs than four baselines across the five dimensions; augmenting training data with the synthesized graphs is reported to mitigate imbalance (normalized entropy gains up to 35%) and improve downstream APT detection accuracy by up to 38%.
Significance. If the empirical claims hold under rigorous controls, the work could help address data scarcity and imbalance in provenance-based intrusion detection, a practical bottleneck for GNN+NLP models targeting APTs. The hybrid graph-plus-LLM synthesis approach is a reasonable direction, though its value depends on whether fidelity metrics translate to real-world robustness.
major comments (2)
- [§4 and §5] §4 (Experiments) and §5 (Results): the abstract and results sections report quantitative gains on six datasets and four baselines but supply no details on experimental controls, statistical testing, exact definitions or formulas for the five fidelity dimensions, or how baselines were re-implemented. This absence prevents verification that the reported fidelity and accuracy improvements (up to 38%) are not artifacts of uncontrolled variables.
- [§5.3] §5.3 (Downstream evaluation): the claim that synthesized graphs enhance generalizability rests on accuracy lifts measured within the same benchmark distributions used for synthesis. No cross-distribution or out-of-distribution test on live enterprise APT traces is presented, leaving the transfer assumption—that high five-dimensional fidelity preserves causal/temporal invariants and avoids harmful distribution shifts—untested and load-bearing for the practical-utility conclusion.
minor comments (2)
- [Abstract] Abstract: the five evaluation dimensions are referenced but never enumerated; a single sentence listing them would improve readability.
- [Figures/Tables] Figure and table captions throughout: ensure each explicitly states the five fidelity metrics, the four baselines, and the exact datasets so that results can be interpreted without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive comments on our paper. We address each major comment below, providing clarifications and indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experiments) and §5 (Results): the abstract and results sections report quantitative gains on six datasets and four baselines but supply no details on experimental controls, statistical testing, exact definitions or formulas for the five fidelity dimensions, or how baselines were re-implemented. This absence prevents verification that the reported fidelity and accuracy improvements (up to 38%) are not artifacts of uncontrolled variables.
Authors: We agree that additional details are necessary for reproducibility and verification. In the revised manuscript, we will expand Sections 4 and 5 to include comprehensive descriptions of experimental controls (e.g., random seeds, data splits, and environment specifications), statistical significance testing with p-values and confidence intervals for all reported metrics, precise mathematical definitions and formulas for the five fidelity dimensions, and detailed re-implementation procedures for the four baselines, including any modifications or hyperparameters used. This will enable independent verification of the results. revision: yes
-
Referee: [§5.3] §5.3 (Downstream evaluation): the claim that synthesized graphs enhance generalizability rests on accuracy lifts measured within the same benchmark distributions used for synthesis. No cross-distribution or out-of-distribution test on live enterprise APT traces is presented, leaving the transfer assumption—that high five-dimensional fidelity preserves causal/temporal invariants and avoids harmful distribution shifts—untested and load-bearing for the practical-utility conclusion.
Authors: The six benchmark datasets are widely used in the field and cover a range of scenarios, allowing us to demonstrate consistent improvements. The five-dimensional fidelity evaluation is intended to ensure that key invariants are preserved. However, we acknowledge the value of OOD testing. Due to the sensitive nature of real enterprise APT traces, such data is not publicly available, which limited our ability to perform cross-distribution tests in this work. We will add a discussion of this limitation and the assumptions made in the revised version. Future extensions could involve synthetic OOD scenarios or collaborations for real traces. revision: partial
- Access to live enterprise APT traces for out-of-distribution testing is restricted due to privacy and security concerns, preventing direct empirical validation of transfer to real-world distributions in the current study.
Circularity Check
Empirical results on external benchmarks with no derivation chain
full rationale
The paper introduces PROVSYN as a three-component synthesis framework and reports measured improvements in fidelity metrics and downstream accuracy on six independent benchmark datasets. No equations, parameter-fitting steps, or self-citation chains are described that would reduce any claimed result to a tautology or to the authors' own inputs by construction. All reported gains (entropy, accuracy) are presented as experimental outcomes rather than predictions derived from fitted parameters within the same work. The evaluation therefore remains self-contained against external data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PROVSYN is a three-phase synthesis framework comprising structural synthesis, topological refinement, and textual attribution... heterogeneous graph generation network... LSTM... DFS sequences... five-dimensional fidelity evaluation (structural MMD, textual BLEU/GLEU/ROUGE, temporal LCS/DTW, embedding DeepWalk/Doc2Vec, semantic correctness via GAT+MLP contrastive learning)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt GraphGen... minimum DFS codes... rule-based post-processing... fine-tune Llama3.2-3B... contrastive learning with Subject-Object Inversion, Predicate Replacement, Entity Substitution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
URL https://github.com/darpa-i2o/Transparent-Computing
Darpa transparent computing program engagement 3 data release. URL https://github.com/darpa-i2o/Transparent-Computing. (2025, May 27)
work page 2025
- [3]
-
[4]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
T. J. Anande and M. S. Leeson. Generative adversarial networks (gans): a survey of network traffic generation. International Journal of Machine Learning and Computing , 12(6):333–343, 2022
work page 2022
-
[6]
M. M. Anjum, S. Iqbal, and B. Hamelin. Analyzing the usefulness of the darpa optc dataset in cyber threat detection research. In Proceedings of the 26th ACM symposium on access control models and technologies, pages 27–32, 2021
work page 2021
-
[7]
L. Bergroth, H. Hakonen, and T. Raita. A survey of longest com- mon subsequence algorithms. In Proceedings Seventh International Symposium on String Processing and Information Retrieval. SPIRE 2000, pages 39–48. IEEE, 2000
work page 2000
-
[8]
M. Buda, A. Maki, and M. A. Mazurowski. A systematic study of the class imbalance problem in convolutional neural networks. Neural networks, 106:249–259, 2018
work page 2018
-
[9]
N. V . Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of arti- ficial intelligence research, 16:321–357, 2002
work page 2002
- [10]
-
[11]
A. Cheng. Pac-gan: Packet generation of network traffic using generative adversarial networks. In 2019 IEEE 10th Annual Informa- tion Technology, Electronics and Mobile Communication Conference (IEMCON), pages 0728–0734. IEEE, 2019
work page 2019
-
[12]
N. De Cao and T. Kipf. Molgan: An implicit generative model for small molecular graphs. arXiv preprint arXiv:1805.11973 , 2018
-
[13]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019. URL https://arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[14]
N. Ding, Y . Chen, B. Xu, Y . Qin, Z. Zheng, S. Hu, Z. Liu, M. Sun, and B. Zhou. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, H. Wang, and H. Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 , 2:1, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
F. Gilardi, M. Alizadeh, and M. Kubli. Chatgpt outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences , 120(30):e2305016120, 2023
work page 2023
- [17]
-
[18]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
A. Gretton, K. Borgwardt, M. Rasch, B. Sch ¨olkopf, and A. Smola. A kernel method for the two-sample-problem. Advances in neural information processing systems , 19, 2006
work page 2006
-
[20]
S. Gunasekar, Y . Zhang, J. Aneja, C. C. T. Mendes, A. Del Giorno, S. Gopi, M. Javaheripi, P. Kauffmann, G. de Rosa, O. Saarikivi, et al. Textbooks are all you need. arXiv preprint arXiv:2306.11644 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
-
[22]
X. Han, X. Yu, T. Pasquier, D. Li, J. Rhee, J. Mickens, M. Seltzer, and H. Chen. {SIGL}: Securing software installations through deep graph learning. In 30th USENIX Security Symposium (USENIX Security 21), pages 2345–2362, 2021
work page 2021
-
[23]
W. U. Hassan, S. Guo, D. Li, Z. Chen, K. Jee, Z. Li, and A. Bates. Nodoze: Combatting threat alert fatigue with automated provenance triage. In network and distributed systems security symposium , 2019
work page 2019
-
[24]
W. U. Hassan, A. Bates, and D. Marino. Tactical provenance analysis for endpoint detection and response systems. In 2020 IEEE sympo- sium on security and privacy (SP) , pages 1172–1189. IEEE, 2020
work page 2020
- [25]
- [26]
-
[27]
O. Honovich, T. Scialom, O. Levy, and T. Schick. Unnatural instruc- tions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689, 2022
-
[28]
M. N. Hossain, S. Sheikhi, and R. Sekar. Combating dependence explosion in forensic analysis using alternative tag propagation se- mantics. In 2020 IEEE symposium on security and privacy (SP) , pages 1139–1155. IEEE, 2020
work page 2020
-
[29]
M. A. Inam, Y . Chen, A. Goyal, J. Liu, J. Mink, N. Michael, S. Gaur, A. Bates, and W. U. Hassan. Sok: History is a vast early warning system: Auditing the provenance of system intrusions. In 2023 IEEE Symposium on Security and Privacy (SP) , pages 2620–2638. IEEE, 2023
work page 2023
-
[30]
S. Ji, S. Pan, E. Cambria, P. Marttinen, and P. S. Yu. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE transactions on neural networks and learning systems , 33(2): 494–514, 2021
work page 2021
-
[31]
Z. Jia, Y . Xiong, Y . Nan, Y . Zhang, J. Zhao, and M. Wen.{MAGIC}: Detecting advanced persistent threats via masked graph representation learning. In 33rd USENIX Security Symposium (USENIX Security 24), pages 5197–5214, 2024
work page 2024
- [32]
-
[33]
B. Jin, G. Liu, C. Han, M. Jiang, H. Ji, and J. Han. Large language models on graphs: A comprehensive survey. IEEE Transactions on Knowledge and Data Engineering , 2024
work page 2024
-
[34]
J. M. Johnson and T. M. Khoshgoftaar. Survey on deep learning with class imbalance. Journal of big data , 6(1):1–54, 2019
work page 2019
-
[35]
J. H. Lau and T. Baldwin. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv preprint arXiv:1607.05368, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
N. Lee, W. Ping, P. Xu, M. Patwary, P. N. Fung, M. Shoeybi, and B. Catanzaro. Factuality enhanced language models for open-ended 14 text generation. Advances in Neural Information Processing Systems , 35:34586–34599, 2022
work page 2022
- [37]
-
[38]
Y . Li, S. Bubeck, R. Eldan, A. Del Giorno, S. Gunasekar, and Y . T. Lee. Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Z. Li, X. Cheng, L. Sun, J. Zhang, and B. Chen. A hierarchical approach for advanced persistent threat detection with attention-based graph neural networks. Security and Communication Networks , 2021 (1):9961342, 2021
work page 2021
-
[40]
C.-Y . Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out , pages 74–81, 2004
work page 2004
-
[41]
F. Liu, Y . Wen, D. Zhang, X. Jiang, X. Xing, and D. Meng. Log2vec: A heterogeneous graph embedding based approach for detecting cyber threats within enterprise. In Proceedings of the 2019 ACM SIGSAC conference on computer and communications security , pages 1777– 1794, 2019
work page 2019
-
[42]
L. Liu, P. Wang, J. Lin, and L. Liu. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE access, 9:7550–7563, 2020
work page 2020
- [43]
-
[44]
X.-Y . Liu, J. Wu, and Z.-H. Zhou. Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) , 39(2):539–550, 2008
work page 2008
-
[45]
Y . Liu, M. Zhang, D. Li, K. Jee, Z. Li, Z. Wu, J. Rhee, and P. Mittal. Towards a timely causality analysis for enterprise security. In NDSS, 2018
work page 2018
-
[46]
S. M. Milajerdi, R. Gjomemo, B. Eshete, R. Sekar, and V . Venkatakr- ishnan. Holmes: real-time apt detection through correlation of suspi- cious information flows. In 2019 IEEE symposium on security and privacy (SP), pages 1137–1152. IEEE, 2019
work page 2019
-
[47]
R. Mohammed, J. Rawashdeh, and M. Abdullah. Machine learning with oversampling and undersampling techniques: overview study and experimental results. In 2020 11th international conference on information and communication systems (ICICS) , pages 243–248. IEEE, 2020
work page 2020
- [48]
- [49]
-
[50]
S. Pan, L. Luo, Y . Wang, C. Chen, J. Wang, and X. Wu. Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering, 36(7):3580–3599, 2024
work page 2024
-
[51]
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
work page 2002
-
[52]
B. Perozzi, R. Al-Rfou, and S. Skiena. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 701–710, 2014
work page 2014
-
[53]
M. U. Rehman, H. Ahmadi, and W. U. Hassan. Flash: A com- prehensive approach to intrusion detection via provenance graph representation learning. In 2024 IEEE Symposium on Security and Privacy (SP), pages 3552–3570. IEEE, 2024
work page 2024
-
[54]
M. Rigaki and S. Garcia. Bringing a gan to a knife-fight: Adapting malware communication to avoid detection. In 2018 IEEE Security and Privacy Workshops (SPW) , pages 70–75. IEEE, 2018
work page 2018
-
[55]
M. Ring, D. Schl ¨or, D. Landes, and A. Hotho. Flow-based network traffic generation using generative adversarial networks. Computers & Security, 82:156–172, 2019
work page 2019
-
[56]
B. Samanta, A. De, G. Jana, V . G ´omez, P. Chattaraj, N. Ganguly, and M. Gomez-Rodriguez. Nevae: A deep generative model for molecular graphs. Journal of machine learning research , 21(114):1–33, 2020
work page 2020
-
[57]
S. Sudalairaj, A. Bhandwaldar, A. Pareja, K. Xu, D. D. Cox, and A. Srivastava. Lab: Large-scale alignment for chatbots. arXiv preprint arXiv:2403.01081, 2024
-
[58]
Z. Sun, Y . Shen, Q. Zhou, H. Zhang, Z. Chen, D. Cox, Y . Yang, and C. Gan. Principle-driven self-alignment of language models from scratch with minimal human supervision. Advances in Neural Information Processing Systems , 36:2511–2565, 2023
work page 2023
-
[59]
R. Thompson, B. Knyazev, E. Ghalebi, J. Kim, and G. W. Taylor. On evaluation metrics for graph generative models. arXiv preprint arXiv:2201.09871, 2022
-
[60]
P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y . Ben- gio, et al. Graph attention networks. stat, 1050(20):10–48550, 2017
work page 2017
-
[61]
Q. Wang, W. U. Hassan, D. Li, K. Jee, X. Yu, K. Zou, J. Rhee, Z. Chen, W. Cheng, C. A. Gunter, et al. You are what you do: Hunting stealthy malware via data provenance analysis. In NDSS, 2020
work page 2020
-
[62]
S. Wang, Z. Wang, T. Zhou, H. Sun, X. Yin, D. Han, H. Zhang, X. Shi, and J. Yang. Threatrace: Detecting and tracing host-based threats in node level through provenance graph learning. IEEE Transactions on Information Forensics and Security , 17:3972–3987, 2022
work page 2022
-
[63]
Y . Wang, Y . Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi. Self-instruct: Aligning language models with self- generated instructions. arXiv preprint arXiv:2212.10560 , 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[65]
C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, and D. Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, and Z. Qi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
J. Yang, K. Zhou, Y . Li, and Z. Liu. Generalized out-of-distribution detection: A survey. International Journal of Computer Vision , 132 (12):5635–5662, 2024
work page 2024
- [68]
- [69]
- [70]
-
[71]
J. You, B. Liu, Z. Ying, V . Pande, and J. Leskovec. Graph convolu- tional policy network for goal-directed molecular graph generation. Advances in neural information processing systems , 31, 2018
work page 2018
-
[72]
J. You, R. Ying, X. Ren, W. Hamilton, and J. Leskovec. Graphrnn: Generating realistic graphs with deep auto-regressive models. In International conference on machine learning , pages 5708–5717. PMLR, 2018
work page 2018
-
[73]
Y . Yu, Y . Zhuang, J. Zhang, Y . Meng, A. J. Ratner, R. Krishna, J. Shen, and C. Zhang. Large language model as attributed training data generator: A tale of diversity and bias. Advances in Neural Information Processing Systems , 36:55734–55784, 2023
work page 2023
- [74]
- [75]
-
[76]
T. Zhao, X. Zhang, and S. Wang. Graphsmote: Imbalanced node classification on graphs with graph neural networks. In Proceedings of the 14th ACM international conference on web search and data mining, pages 833–841, 2021
work page 2021
-
[77]
Y . Zhou, M. Kantarcioglu, and C. Clifton. On improving fairness of ai models with synthetic minority oversampling techniques. In Proceedings of the 2023 SIAM international conference on data mining (SDM), pages 874–882. SIAM, 2023. Appendix A. Entity and Event Distribution in Our Datasets We present the distributions of entity type and event type across ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.