StableMTL: Repurposing Latent Diffusion Models for Multi-Task Learning from Partially Annotated Synthetic Datasets
Pith reviewed 2026-05-19 10:07 UTC · model grok-4.3
The pith
Repurposing latent diffusion models enables multi-task learning from synthetic datasets labeled for only subsets of tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StableMTL repurposes image generators for latent regression by adapting a denoising framework with task encoding, per-task conditioning and a tailored training scheme. Instead of per-task losses, a unified latent loss is used. A multi-stream model with task-attention converts N-to-N task interactions into efficient 1-to-N attention to promote cross-task synergy. The resulting model is trained on multiple synthetic datasets each supplying labels for only a subset of tasks and outperforms baselines on seven tasks across eight benchmarks.
What carries the argument
The multi-stream model with task-attention that turns expensive N-to-N cross-task interactions into efficient 1-to-N attention for inter-task synergy.
If this is right
- Adding more tasks requires no extra loss-balancing effort because a single unified latent loss is used.
- Multiple synthetic datasets can be combined even when no dataset labels all tasks at once.
- Task-attention lets each task benefit from features learned for the others without explicit pairing.
- The zero-shot partial-label setup removes the need for any single dataset to carry complete annotations.
Where Pith is reading between the lines
- Similar conditioning and attention changes might let other generative models handle partial-label multi-task training.
- Evaluating the trained model directly on real images with partial labels would test transfer beyond synthetic data.
- The 1-to-N attention pattern could be reused in other multi-task settings that involve many output heads.
Load-bearing premise
The generalization power of pre-trained latent diffusion models is sufficient to support zero-shot extension of partial-label training when each synthetic dataset supplies labels for only a subset of tasks.
What would settle it
Train an identical architecture from random weights rather than from pre-trained diffusion weights and check whether performance on the eight benchmarks still exceeds the reported baselines.
Figures










read the original abstract
Multi-task learning for dense prediction is limited by the need for extensive annotation for every task, though recent works have explored training with partial task labels. Leveraging the generalization power of diffusion models, we extend the partial learning setup to a zero-shot setting, training a multi-task model on multiple synthetic datasets, each labeled for only a subset of tasks. Our method, StableMTL, repurposes image generators for latent regression. Adapting a denoising framework with task encoding, per-task conditioning and a tailored training scheme. Instead of per-task losses requiring careful balancing, a unified latent loss is adopted, enabling seamless scaling to more tasks. To encourage inter-task synergy, we introduce a multi-stream model with a task-attention mechanism that converts N-to-N task interactions into efficient 1-to-N attention, promoting effective cross-task sharing. StableMTL outperforms baselines on 7 tasks across 8 benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StableMTL, a method that repurposes pre-trained latent diffusion models for multi-task dense prediction by training on multiple synthetic datasets, each providing labels for only a subset of tasks. It adapts the denoising framework via task encoding and per-task conditioning, replaces per-task losses with a unified latent loss, and employs a multi-stream architecture with a task-attention mechanism that converts N-to-N interactions into efficient 1-to-N attention to promote cross-task synergy. The approach is evaluated on 7 tasks across 8 benchmarks and reported to outperform baselines.
Significance. If the results hold, the work is significant because it shows how the generalization properties of pre-trained latent diffusion models can be leveraged for zero-shot partial-label multi-task regression on synthetic data, removing the need for explicit per-task loss balancing and enabling more scalable task addition. Credit is given for the extensive empirical evaluation across 8 benchmarks, which provides concrete, falsifiable support for the claimed outperformance and for the design choices in the unified loss and task-attention components.
major comments (2)
- [§3.3] §3.3 (Unified Latent Loss): the claim that the single latent loss removes the need for per-task balancing is central, yet the formulation appears to retain task-specific conditioning weights; an explicit derivation or ablation showing invariance to task weighting would be required to substantiate the scaling advantage.
- [§4.2] §4.2 (Ablation on partial labels): the zero-shot partial-label premise is load-bearing for the entire setup, but the reported gains on missing-task subsets are not isolated from the contribution of the pre-trained LDM features; a controlled ablation that freezes the latent encoder while varying the fraction of missing labels per dataset would directly test whether cross-task attention recovers the signals or whether performance relies on already-encoded features.
minor comments (2)
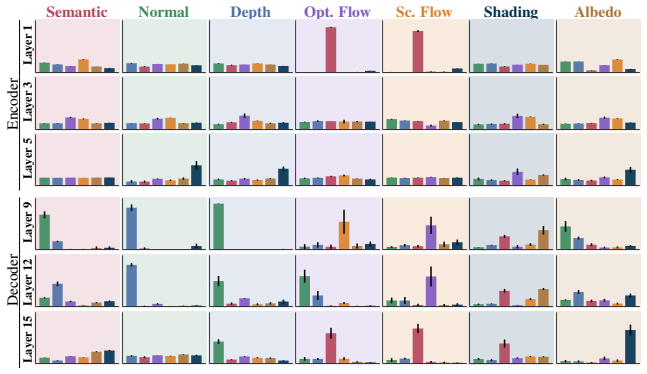
- [Figure 3] Figure 3: the task-attention diagram would benefit from explicit notation for the 1-to-N reduction (e.g., query/key/value dimensions) to clarify computational savings relative to standard multi-head attention.
- [Table 1] Table 1: baseline descriptions should include the exact loss-balancing strategy used for each competing method so that the advantage of the unified latent loss can be directly compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we address each major comment point by point and describe the revisions we will make.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Unified Latent Loss): the claim that the single latent loss removes the need for per-task balancing is central, yet the formulation appears to retain task-specific conditioning weights; an explicit derivation or ablation showing invariance to task weighting would be required to substantiate the scaling advantage.
Authors: We appreciate the referee's observation. Task-specific conditioning weights are used solely to inject task identity into the diffusion conditioning mechanism. The training objective itself remains a single unified loss computed directly in latent space and does not involve any per-task loss terms or explicit weighting coefficients that would require balancing. We will add a short derivation of the gradient of this unified loss with respect to the network parameters to show that no task-specific loss weights appear. We will also include an ablation that varies the magnitude of the conditioning weights while keeping the loss formulation fixed, demonstrating that performance is largely invariant and thereby supporting the claimed scaling advantage. revision: yes
-
Referee: [§4.2] §4.2 (Ablation on partial labels): the zero-shot partial-label premise is load-bearing for the entire setup, but the reported gains on missing-task subsets are not isolated from the contribution of the pre-trained LDM features; a controlled ablation that freezes the latent encoder while varying the fraction of missing labels per dataset would directly test whether cross-task attention recovers the signals or whether performance relies on already-encoded features.
Authors: We agree that isolating the contribution of the cross-task attention from the pre-trained latent features is important for validating the zero-shot partial-label premise. We will add a controlled ablation in which the latent encoder is frozen and the fraction of missing labels per dataset is systematically varied. The results of this experiment will be reported to clarify whether the task-attention mechanism enables recovery of signals for missing tasks beyond what is already present in the frozen pre-trained representations. revision: yes
Circularity Check
No significant circularity; derivation relies on external pre-trained model generalization
full rationale
The paper's method description in the abstract and skeptic summary introduces task encoding, per-task conditioning, unified latent loss, and task-attention as adaptations of a denoising framework for partial-label multi-task regression. No equations, fitting procedures, or self-citations are exhibited that reduce any claimed prediction or result to an input defined by the same claim. The load-bearing premise is the generalization power of pre-trained latent diffusion models, treated as an external property rather than derived internally. This qualifies as a self-contained engineering contribution without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leveraging the generalization power of diffusion models allows extension of partial learning to zero-shot setting with synthetic datasets each labeled for only a subset of tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified latent loss ... single and simple latent Mean Squared Error (MSE) loss
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
task-attention mechanism that converts N-to-N task interactions into efficient 1-to-N attention
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aich, A., Schulter, S., Roy-Chowdhury, A.K., Chandraker, M., Suh, Y .: Efficient controllable multi-task architectures. In: ICCV (2023)
work page 2023
-
[2]
Aleotti, F., Poggi, M., Mattoccia, S.: Learning optical flow from still images. In: CVPR (2021)
work page 2021
-
[3]
Argaw, D.M., Kim, J., Rameau, F., Cho, J.W., Kweon, I.S.: Optical flow estimation from a single motion-blurred image. In: AAAI (2021)
work page 2021
-
[4]
Bae, G., Davison, A.J.: Rethinking inductive biases for surface normal estimation. In: CVPR (2024)
work page 2024
-
[5]
Baker, S., Roth, S., Scharstein, D., Black, M.J., Lewis, J., Szeliski, R.: A database and evaluation methodology for optical flow. In: ICCV (2007)
work page 2007
-
[6]
Borse, S., Das, D., Park, H., Cai, H., Garrepalli, R., Porikli, F.: Dejavu: Conditional regenerative learning to enhance dense prediction. In: CVPR (2023)
work page 2023
-
[7]
Brüggemann, D., Kanakis, M., Obukhov, A., Georgoulis, S., Van Gool, L.: Exploring relational context for multi-task dense prediction. In: ICCV (2021)
work page 2021
-
[8]
Cabon, Y ., Murray, N., Humenberger, M.: Virtual kitti 2. In: arXiv (2020)
work page 2020
-
[9]
Careaga, C., Aksoy, Y .: Intrinsic image decomposition via ordinal shading. ACM TOG (2023)
work page 2023
-
[10]
Careaga, C., Aksoy, Y .: Colorful diffuse intrinsic image decomposition in the wild. ACM TOG (2024)
work page 2024
-
[11]
Chen, T., Chen, X., Du, X., Rashwan, A., Yang, F., Chen, H., Wang, Z., Li, Y .: AdaMV-MoE: Adaptive multi-task vision mixture-of-experts. In: ICCV (2023)
work page 2023
-
[12]
Chen, Z., Badrinarayanan, V ., Lee, C.Y ., Rabinovich, A.: Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In: ICML (2018)
work page 2018
-
[13]
Chen, Z., Ngiam, J., Huang, Y ., Luong, T., Kretzschmar, H., Chai, Y ., Anguelov, D.: Just pick a sign: Optimizing deep multitask models with gradient sign dropout. In: NeurIPS (2020)
work page 2020
-
[14]
Choi, W., Im, S.: Dynamic neural network for multi-task learning searching across diverse network topologies. In: CVPR (2023)
work page 2023
-
[15]
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR (2016)
work page 2016
-
[16]
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: NeurIPS (2014)
work page 2014
-
[17]
Fan, Z., Sarkar, R., Jiang, Z., Chen, T., Zou, K., Cheng, Y ., Hao, C., Wang, Z., et al.: M3VIT: Mixture-of-experts vision transformer for efficient multi-task learning with model-accelerator co-design. In: NeurIPS (2022)
work page 2022
-
[18]
Proceedings of the IEEE (2024)
Fontana, M., Spratling, M., Shi, M.: When multitask learning meets partial supervision: A computer vision review. Proceedings of the IEEE (2024)
work page 2024
-
[19]
Fu, X., Yin, W., Hu, M., Wang, K., Ma, Y ., Tan, P., Shen, S., Lin, D., Long, X.: Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. In: ECCV (2024)
work page 2024
-
[20]
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: CVPR (2012)
work page 2012
-
[21]
Ghiasi, G., Zoph, B., Cubuk, E.D., Le, Q.V ., Lin, T.Y .: Multi-task self-training for learning general representations. In: ICCV (2021) 10
work page 2021
-
[22]
Gui, M., Schusterbauer, J., Prestel, U., Ma, P., Kotovenko, D., Grebenkova, O., Baumann, S.A., Hu, V .T., Ommer, B.: DepthFM: Fast monocular depth estimation with flow matching. In: AAAI (2025)
work page 2025
-
[23]
Guizilini, V ., Ambrus, R., Pillai, S., Raventos, A., Gaidon, A.: 3d packing for self-supervised monocular depth estimation. In: CVPR (2020)
work page 2020
-
[24]
Guo, P., Lee, C.Y ., Ulbricht, D.: Learning to branch for multi-task learning. In: ICML (2020)
work page 2020
-
[25]
He, J., Li, H., Yin, W., Liang, Y ., Li, L., Zhou, K., Liu, H., Liu, B., Chen, Y .C.: Lotus: Diffusion-based visual foundation model for high-quality dense prediction. In: ICLR (2025)
work page 2025
-
[26]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
work page 2016
-
[27]
Ke, B., Obukhov, A., Huang, S., Metzger, N., Daudt, R.C., Schindler, K.: Repurposing diffusion- based image generators for monocular depth estimation. In: CVPR (2024)
work page 2024
-
[28]
Ke, B., Qu, K., Wang, T., Metzger, N., Huang, S., Li, B., Obukhov, A., Schindler, K.: Marigold: Affordable adaptation of diffusion-based image generators for image analysis. T-PAMI (2025)
work page 2025
-
[29]
Kendall, A., Gal, Y ., Cipolla, R.: Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In: CVPR (2018)
work page 2018
-
[30]
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: ICLR (2015)
work page 2015
-
[31]
Le, D.H., Pham, T., Lee, S., Clark, C., Kembhavi, A., Mandt, S., Krishna, R., Lu, J.: One diffusion to generate them all. In: CVPR (2025)
work page 2025
-
[32]
Li, W.H., Liu, X., Bilen, H.: Learning multiple dense prediction tasks from partially annotated data. In: CVPR (2022)
work page 2022
-
[33]
Liang, X., Wu, Y ., Han, J., Xu, H., Xu, C., Liang, X.: Effective adaptation in multi-task co-training for unified autonomous driving. In: NeurIPS (2022)
work page 2022
-
[34]
Lin, X., Zhen, H.L., Li, Z., Zhang, Q.F., Kwong, S.: Pareto multi-task learning. In: NeurIPS (2019)
work page 2019
-
[35]
Liu, Q., Liao, X., Carin, L.: Semi-supervised multitask learning. In: NeurIPS (2007)
work page 2007
-
[36]
Liu, Y .C., Ma, C.Y ., Tian, J., He, Z., Kira, Z.: Polyhistor: Parameter-efficient multi-task adaptation for dense vision tasks. In: NeurIPS (2022)
work page 2022
-
[37]
Lopes, I., Vu, T.H., de Charette, R.: DenseMTL: Cross-task attention mechanism for dense multi-task learning. In: W ACV (2023)
work page 2023
-
[38]
Lu, Y ., Pirk, S., Dlabal, J., Brohan, A., Pasad, A., Chen, Z., Casser, V ., Angelova, A., Gordon, A.: Taskology: Utilizing task relations at scale. In: CVPR (2021)
work page 2021
-
[39]
Lu, Y ., Kumar, A., Zhai, S., Cheng, Y ., Javidi, T., Feris, R.: Fully-adaptive feature sharing in multi-task networks with applications in person attribute classification. In: CVPR (2017)
work page 2017
-
[40]
Martin Garcia, G., Abou Zeid, K., Schmidt, C., de Geus, D., Hermans, A., Leibe, B.: Fine-tuning image-conditional diffusion models is easier than you think. In: W ACV (2025)
work page 2025
-
[41]
Mayer, N., Ilg, E., Häusser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: CVPR (2016)
work page 2016
-
[42]
Menze, M., Geiger, A.: Object scene flow for autonomous vehicles. In: CVPR (2015)
work page 2015
-
[43]
Misra, I., Shrivastava, A., Gupta, A., Hebert, M.: Cross-stitch networks for multi-task learning. In: CVPR (2016)
work page 2016
-
[44]
Momma, M., Dong, C., Liu, J.: A multi-objective/multi-task learning framework induced by pareto stationarity. In: ICML (2022) 11
work page 2022
-
[45]
Murmann, L., Gharbi, M., Aittala, M., Durand, F.: A multi-illumination dataset of indoor object appearance. In: ICCV (2019)
work page 2019
-
[46]
Nishi, K., Kim, J., Li, W., Pfister, H.: Joint-task regularization for partially labeled multi-task learning. In: CVPR (2024)
work page 2024
-
[47]
Ouali, Y ., Hudelot, C., Tami, M.: Semi-supervised semantic segmentation with cross-consistency training. In: CVPR (2020)
work page 2020
-
[48]
Perazzi, F., Pont-Tuset, J., McWilliams, B., Gool, L.V ., Gross, M., Sorkine-Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. In: CVPR (2016)
work page 2016
-
[49]
Roberts, M., Ramapuram, J., Ranjan, A., Kumar, A., Bautista, M.A., Paczan, N., Webb, R., Susskind, J.M.: Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In: ICCV (2021)
work page 2021
-
[50]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
work page 2022
-
[51]
Ruder, S., Bingel, J., Augenstein, I., Søgaard, A.: Latent multi-task architecture learning. In: AAAI (2019)
work page 2019
-
[52]
Saha, S., Obukhov, A., Paudel, D.P., Kanakis, M., Chen, Y ., Georgoulis, S., Van Gool, L.: Learning to relate depth and semantics for unsupervised domain adaptation. In: CVPR (2021)
work page 2021
-
[53]
Senushkin, D., Patakin, N., Kuznetsov, A., Konushin, A.: Independent component alignment for multi-task learning. In: CVPR (2023)
work page 2023
-
[54]
Standley, T., Zamir, A.R., Chen, D., Guibas, L., Malik, J., Savarese, S.: Which tasks should be learned together in multi-task learning? In: ICML (2020)
work page 2020
-
[55]
Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: CVPR (2019)
work page 2019
-
[56]
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V ., Tsui, P., Guo, J., Zhou, Y ., Chai, Y ., Caine, B., Vasudevan, V ., Han, W., Ngiam, J., Zhao, H., Timofeev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y ., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset. In: CVPR (2020)
work page 2020
-
[57]
Vandenhende, S., Georgoulis, S., Van Gansbeke, W., Proesmans, M., Dai, D., Van Gool, L.: Multi-task learning for dense prediction tasks: A survey. T-PAMI (2022)
work page 2022
-
[58]
Vasiljevic, I., Kolkin, N., Zhang, S., Luo, R., Wang, H., Dai, F.Z., Daniele, A.F., Mostajabi, M., Basart, S., Walter, M.R., Shakhnarovich, G.: DIODE: A Dense Indoor and Outdoor DEpth Dataset. CoRR (2019)
work page 2019
-
[59]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: NeurIPS (2017)
work page 2017
-
[60]
Wang, F., Wang, X., Li, T.: Semi-supervised multi-task learning with task regularizations. In: ICDM (2009)
work page 2009
-
[61]
Wang, Y ., Tsai, Y .H., Hung, W.C., Ding, W., Liu, S., Yang, M.H.: Semi-supervised multi-task learning for semantics and depth. In: W ACV (2022)
work page 2022
-
[62]
Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Image quality assessment: from error visibility to structural similarity. TIP (2004)
work page 2004
-
[63]
Wang, Z., Li, H., Sui, L., Zhou, T., Jiang, H., Nie, L., Liu, S.: StableMotion: Repurposing diffusion-based image priors for motion estimation. In: arXiv (2025)
work page 2025
-
[64]
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., Ramanan, D., Carr, P., Hays, J.: Argoverse 2: Next generation datasets for self-driving perception and forecasting. In: NeurIPS (2021) 12
work page 2021
-
[65]
Xiao, P., Shao, Z., Hao, S., Zhang, Z., Chai, X., Jiao, J., Li, Z., Wu, J., Sun, K., Jiang, K., Wang, Y ., Yang, D.: PandaSet: Advanced sensor suite dataset for autonomous driving. In: ITSC (2021)
work page 2021
-
[66]
Xu, G., Ge, Y ., Liu, M., Fan, C., Xie, K., Zhao, Z., Chen, H., Shen, C.: What matters when repurposing diffusion models for general dense perception tasks? In: ICLR (2025)
work page 2025
-
[67]
Xu, N., Yang, L., Fan, Y ., Yang, J., Yue, D., Liang, Y ., Price, B., Cohen, S., Huang, T.: Youtube-vos: Sequence-to-sequence video object segmentation. In: ECCV (2018)
work page 2018
-
[68]
Xu, X., Zhao, H., Vineet, V ., Lim, S.N., Torralba, A.: Mtformer: Multi-task learning via transformer and cross-task reasoning. In: ECCV (2022)
work page 2022
-
[69]
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y ., Dong, Z., Bo, L., Xiu, Y ., Han, X.: StableNormal: Reducing diffusion variance for stable and sharp normal. ACM TOG (2024)
work page 2024
-
[70]
Ye, H., Xu, D.: Inverted pyramid multi-task transformer for dense scene understanding. In: ECCV (2022)
work page 2022
-
[71]
Ye, H., Xu, D.: DiffusionMTL: Learning multi-task denoising diffusion model from partially annotated data. In: CVPR (2024)
work page 2024
-
[72]
Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., Finn, C.: Gradient surgery for multi-task learning. In: NeurIPS (2020)
work page 2020
-
[73]
Zamir, A.R., Sax, A., Cheerla, N., Suri, R., Cao, Z., Malik, J., Guibas, L.J.: Robust learning through cross-task consistency. In: CVPR (2020)
work page 2020
-
[74]
Zamir, A.R., Sax, A., Shen, W.B., Guibas, L., Malik, J., Savarese, S.: Taskonomy: Disentangling task transfer learning. In: CVPR (2018)
work page 2018
-
[75]
Zeng, Z., Deschaintre, V ., Georgiev, I., Hold-Geoffroy, Y ., Hu, Y ., Luan, F., Yan, L.Q., Hašan, M.: RGB↔X: Image decomposition and synthesis using material- and lighting-aware diffusion models. In: SIGGRAPH (2024)
work page 2024
-
[76]
In: Buntine, W., Grobelnik, M., Mladeni´c, D., Shawe-Taylor, J
Zhang, Y ., Yeung, D.Y .: Semi-supervised multi-task regression. In: Buntine, W., Grobelnik, M., Mladeni´c, D., Shawe-Taylor, J. (eds.) ECML PKDD (2009)
work page 2009
-
[77]
Zhang, Z., Cui, Z., Xu, C., Jie, Z., Li, X., Yang, J.: Joint task-recursive learning for semantic segmentation and depth estimation. In: ECCV (2018)
work page 2018
-
[78]
Zhao, C., Liu, M., Zheng, H., Zhu, M., Zhao, Z., Chen, H., He, T., Shen, C.: DICEPTION: A generalist diffusion model for visual perceptual tasks. In: arXiv (2025) 13 Acknowledgments. This work was funded by the French Agence Nationale de la Recherche (ANR) with project SIGHT (ANR-20-CE23-0016) and performed with HPC resources from GENCI-IDRIS (Grants AD01...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.