The Less You Depend, The More You Learn: Synthesizing Novel Views from Sparse, Unposed Images with Minimal 3D Knowledge
Pith reviewed 2026-05-19 09:28 UTC · model grok-4.3
The pith
Novel view synthesis methods relying on less explicit 3D knowledge improve faster with more data and eventually outperform pose-dependent approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
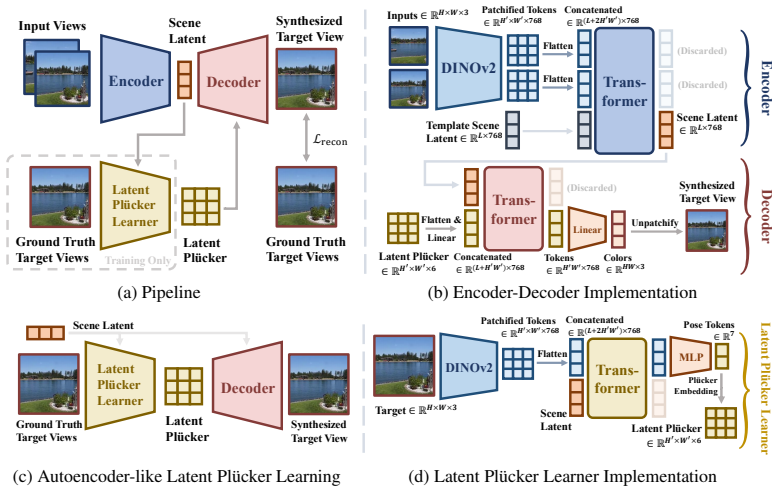
The authors discover that the performance of novel view synthesis methods requiring less 3D knowledge accelerates more as training data increases, eventually outperforming 3D knowledge-driven counterparts. They term this 'the less you depend, the more you learn.' Building on this, they design a feed-forward framework that eliminates dependence on explicit scene structure and pose annotations, learning implicit 3D awareness directly from vast quantities of 2D images without any pose information for training or inference.
What carries the argument
A feed-forward novel view synthesis network designed to learn implicit 3D structure from unposed 2D images without explicit scene representations or camera poses.
If this is right
- The new framework achieves state-of-the-art performance on novel view synthesis tasks.
- It works even when outperforming methods that rely on posed training data.
- Performance gains accelerate with larger training sets for low-dependence methods.
- This validates shifting design focus toward data-centric paradigms in 3D vision.
Where Pith is reading between the lines
- Similar scaling advantages might appear in other vision tasks like depth estimation or 3D reconstruction if explicit priors are minimized.
- The approach could enable training on much larger, noisier internet image collections without pose estimation.
- One testable extension is applying the method to dynamic scenes or video data where poses are hard to obtain.
Load-bearing premise
The observed advantage of low-3D-knowledge methods will continue when the new architecture is scaled to much larger data volumes without introducing unmeasured errors from missing explicit structure.
What would settle it
Training the proposed model on increasingly large datasets and checking whether its novel view synthesis accuracy continues to exceed that of pose-based methods or degrades on scenes requiring precise geometric constraints.
Figures









read the original abstract
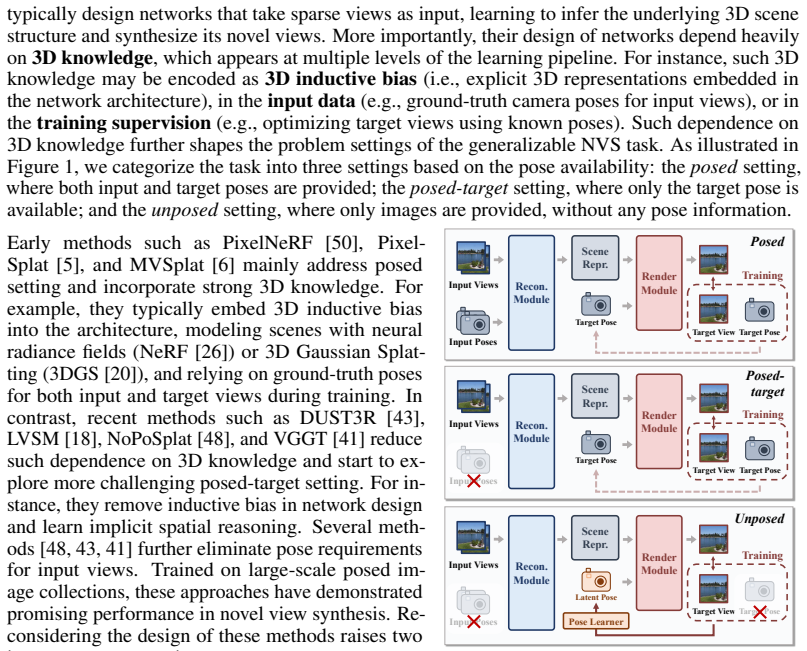
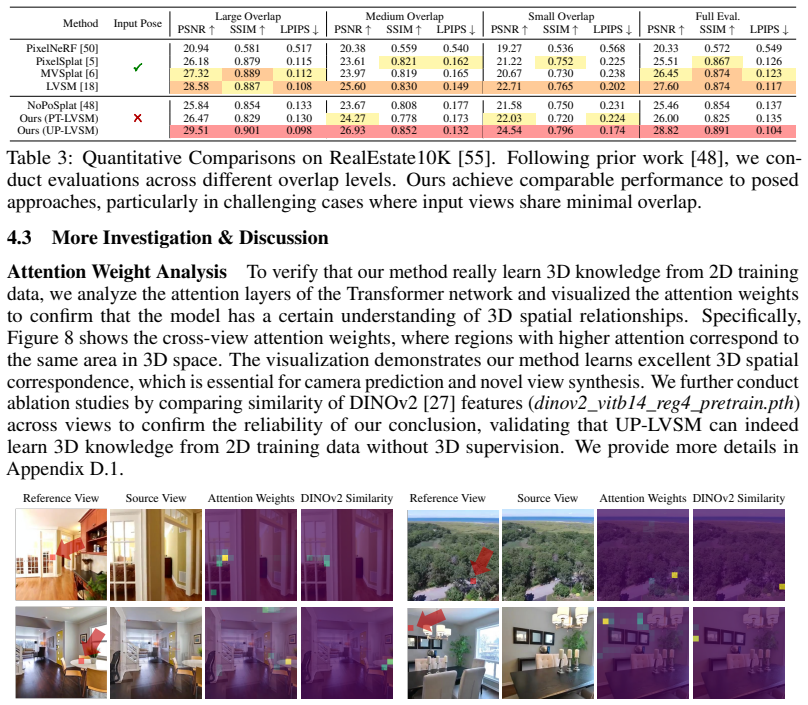
Recent advances in feed-forward Novel View Synthesis (NVS) have led to a divergence between two design philosophies: bias-driven methods, which rely on explicit 3D knowledge, such as handcrafted 3D representations (e.g., NeRF and 3DGS) and camera poses annotated by Structure-from-Motion algorithms, and data-centric methods, which learn to understand 3D structure implicitly from large-scale imagery data. This raises a fundamental question: which paradigm is more scalable in an era of ever-increasing data availability? In this work, we conduct a comprehensive analysis of existing methods and uncover a critical trend that the performance of methods requiring less 3D knowledge accelerates more as training data increases, eventually outperforming their 3D knowledge-driven counterparts, which we term "the less you depend, the more you learn." Guided by this finding, we design a feed-forward NVS framework that removes both explicit scene structure and pose annotation reliance. By eliminating these dependencies, our method leverages great scalability, learning implicit 3D awareness directly from vast quantities of 2D images, without any pose information for training or inference. Extensive experiments demonstrate that our model achieves state-of-the-art NVS performance, even outperforming methods relying on posed training data. The results validate not only the effectiveness of our data-centric paradigm but also the power of our scalability finding as a guiding principle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes existing novel view synthesis (NVS) methods and identifies a scaling trend: approaches relying on less explicit 3D knowledge (no poses, no handcrafted representations) improve faster with more training data and eventually surpass bias-driven methods that use SfM poses or explicit 3D structures such as NeRF/3DGS. Guided by this observation, the authors introduce a feed-forward NVS architecture trained and tested without any pose or scene-structure supervision, claiming state-of-the-art performance on standard benchmarks even when compared to pose-supervised baselines.
Significance. If the reported scaling advantage is robust and the new pose-free model continues to improve at larger scales, the work would provide both an empirical principle and a practical architecture that reduces dependence on costly 3D annotations, potentially enabling NVS on massive unposed image collections. The explicit credit for reproducible code or parameter-free derivations is not present in the manuscript; the strength lies in the empirical trend analysis and the architectural simplification.
major comments (2)
- The central scaling claim (performance acceleration driven by reduced 3D dependence) rests on a comparison of prior methods whose groups differ systematically in backbone (CNN vs. transformer), parameter count, optimization schedule, and data curation. Without a controlled ablation that holds architecture and capacity fixed while varying only the amount of explicit 3D input, it remains possible that the steeper curves reflect recent architectural progress rather than the 'less you depend' principle. This directly affects the justification for designing the new pose-free model.
- The manuscript states that the new model is trained without pose supervision and still outperforms posed baselines, yet no quantitative breakdown is given for how much of the gain comes from the architecture versus the larger effective training set enabled by dropping pose requirements. A direct comparison on identical data with and without pose inputs would isolate the contribution.
minor comments (2)
- Figure captions and axis labels in the scaling plots should explicitly state the exact metric (e.g., PSNR, SSIM) and the precise definition of 'training data volume' used for each curve.
- The abstract claims 'state-of-the-art NVS performance' without specifying the evaluation protocol (number of input views, scene categories, or whether test poses are known at inference). Adding these details would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions to strengthen the manuscript where appropriate.
read point-by-point responses
-
Referee: The central scaling claim (performance acceleration driven by reduced 3D dependence) rests on a comparison of prior methods whose groups differ systematically in backbone (CNN vs. transformer), parameter count, optimization schedule, and data curation. Without a controlled ablation that holds architecture and capacity fixed while varying only the amount of explicit 3D input, it remains possible that the steeper curves reflect recent architectural progress rather than the 'less you depend' principle. This directly affects the justification for designing the new pose-free model.
Authors: We acknowledge that the literature methods aggregated in our scaling analysis differ in backbone, capacity, and training details, which could introduce confounding factors. The trend we report is nevertheless consistent across multiple independent works, providing empirical motivation for the data-centric direction. In the revision we will add explicit discussion of these potential confounders and their possible influence on the observed curves. The design of the new pose-free model is justified primarily by its own empirical results on standard benchmarks without pose supervision; we will clarify that the literature analysis serves as guiding observation rather than conclusive causal proof. revision: partial
-
Referee: The manuscript states that the new model is trained without pose supervision and still outperforms posed baselines, yet no quantitative breakdown is given for how much of the gain comes from the architecture versus the larger effective training set enabled by dropping pose requirements. A direct comparison on identical data with and without pose inputs would isolate the contribution.
Authors: We agree that isolating the contribution of architecture versus expanded data scale would be valuable. Because our architecture is specifically engineered for unposed inputs, constructing an otherwise identical posed variant is non-trivial; however, we will add scaling experiments on matched data subsets in the revision to quantify the benefit of the larger effective training set made possible by removing pose requirements. We will also discuss the practical trade-offs involved in such a comparison. revision: yes
Circularity Check
Empirical scaling analysis of prior methods and independent new-model validation contain no circular reductions
full rationale
The paper derives its guiding principle from a comparative performance analysis of existing NVS methods (NeRF/3DGS/pose-based vs. implicit feed-forward) as data volume grows; this is an external empirical observation on published results rather than any self-referential fit, definition, or self-citation chain. The subsequent architecture is explicitly constructed to remove pose and structure inputs and is evaluated as a fresh test of the observed trend. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or described derivation; the chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022
work page 2022
-
[2]
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, Áron Monszpart, Daniyar Turmukham- betov, and Victor Adrian Prisacariu. Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer. In European Conference on Computer Vision , pages 421–440. Springer, 2024
work page 2024
-
[3]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In CVPR, 2024
work page 2024
-
[6]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. arXiv preprint arXiv:2403.14627, 2024
-
[7]
Abo: Dataset and benchmarks for real-world 3d object understanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achleshwar Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object understanding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21126–21136, 2022
work page 2022
-
[8]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 5828–5839, 2017
work page 2017
-
[9]
Objaverse-xl: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems , 36:35799–35813, 2023
work page 2023
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Google scanned objects: A high-quality dataset of 3d scanned household items
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Reymann, Thomas B McHugh, and Vincent Vanhoucke. Google scanned objects: A high-quality dataset of 3d scanned household items. In 2022 International Conference on Robotics and Automation (ICRA) , pages 2553–2560. IEEE, 2022
work page 2022
-
[12]
Learning to render novel views from wide-baseline stereo pairs
Yilun Du, Cameron Smith, Ayush Tewari, and Vincent Sitzmann. Learning to render novel views from wide-baseline stereo pairs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[13]
Learning to render novel views from wide-baseline stereo pairs
Yilun Du, Cameron Smith, Ayush Tewari, and Vincent Sitzmann. Learning to render novel views from wide-baseline stereo pairs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4970–4980, 2023
work page 2023
-
[14]
Pose-free generalizable rendering transformer
Zhiwen Fan, Panwang Pan, Peihao Wang, Yifan Jiang, Hanwen Jiang, Dejia Xu, Zehao Zhu, Dilin Wang, and Zhangyang Wang. Pose-free generalizable rendering transformer. arXiv preprint arXiv:2310.03704, 2023
-
[15]
Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 seconds
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, et al. Instantsplat: Unbounded sparse-view pose-free gaussian splatting in 40 seconds. arXiv preprint arXiv:2403.20309, 2(3):4, 2024
-
[16]
Query-key normalization for transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normalization for transformers. arXiv preprint arXiv:2010.04245, 2020
-
[17]
Rayzer: A self-supervised large view synthesis model, 2025
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, and Georgios Pavlakos. Rayzer: A self-supervised large view synthesis model, 2025
work page 2025
-
[18]
Lvsm: A large view synthesis model with minimal 3d inductive bias
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. Lvsm: A large view synthesis model with minimal 3d inductive bias. In The Thirteenth International Conference on Learning Representations , 2025
work page 2025
-
[19]
Perceptual losses for real-time style transfer and super- resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super- resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14 , pages 694–711. Springer, 2016
work page 2016
-
[20]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), 2023
work page 2023
-
[21]
Megadepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 2041–2050, 2018
work page 2041
-
[22]
Openrooms: An open framework for photorealistic indoor scene datasets
Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu-Ying Yeh, Rui Zhu, Nitesh Gundavarapu, Jia Shi, et al. Openrooms: An open framework for photorealistic indoor scene datasets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 7190–7199, 2021
work page 2021
-
[23]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 22160–22169, 2024
work page 2024
-
[24]
Infinite nature: Perpetual view generation of natural scenes from a single image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. Infinite nature: Perpetual view generation of natural scenes from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 14458–14467, 2021
work page 2021
-
[25]
Matrix3d: Large photogrammetry model all-in-one
Yuanxun Lu†, Jingyang Zhang, Tian Fang, Jean–Daniel Nahmias, Yanghai Tsin, Long Quan‡, Xun Cao†, Yao Yao†, and Shiwei Li. Matrix3d: Large photogrammetry model all-in-one. In CVPR, 2025
work page 2025
-
[26]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In The European Conference on Computer Vision (ECCV), 2020
work page 2020
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Julius Plucker. Xvii. on a new geometry of space. Philosophical Transactions of the Royal Society of London, 155:725–791, 1865. 11
-
[29]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In Proceedings of the IEEE/CVF international conference on computer vision , pages 10901–10911, 2021
work page 2021
-
[30]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In Proceedings of the IEEE/CVF international conference on computer vision , pages 10912–10922, 2021
work page 2021
-
[31]
Geometry-free view synthesis: Transformers and no 3d priors
Robin Rombach, Patrick Esser, and Björn Ommer. Geometry-free view synthesis: Transformers and no 3d priors. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 14356–14366, 2021
work page 2021
-
[32]
Mehdi S. M. Sajjadi, Henning Meyer, Etienne Pot, Urs Bergmann, Klaus Greff, Noha Radwan, Suhani V ora, Mario Lucic, Daniel Duckworth, Alexey Dosovitskiy, Jakob Uszkoreit, Thomas Funkhouser, and Andrea Tagliasacchi. Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations. CVPR, 2022
work page 2022
-
[33]
Mehdi S. M. Sajjadi, Aravindh Mahendran, Thomas Kipf, Etienne Pot, Daniel Duckworth, Mario Luˇci´c, and Klaus Greff. RUST: Latent Neural Scene Representations from Unposed Imagery. CVPR, 2023
work page 2023
-
[34]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 4104–4113, 2016
work page 2016
-
[35]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs. arXiv preprint arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Generalizable patch-based neural rendering
Mohammed Suhail, Carlos Esteves, Leonid Sigal, and Ameesh Makadia. Generalizable patch-based neural rendering. In European Conference on Computer Vision, pages 156–174. Springer, 2022
work page 2022
-
[37]
Megascenes: Scene-level view synthesis at scale
Joseph Tung, Gene Chou, Ruojin Cai, Guandao Yang, Kai Zhang, Gordon Wetzstein, Bharath Hariharan, and Noah Snavely. Megascenes: Scene-level view synthesis at scale. In ECCV, 2024
work page 2024
-
[38]
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008
work page 2008
-
[39]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017
work page 2017
-
[40]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21686–21697, 2024
work page 2024
-
[41]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[42]
Ibrnet: Learning multi-view image-based rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 4690–4699, 2021
work page 2021
-
[43]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. In CVPR, 2024
work page 2024
-
[44]
NeRF−−: Neural radiance fields without known camera parameters
Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, and Victor Adrian Prisacariu. NeRF−−: Neural radiance fields without known camera parameters. arXiv preprint arXiv:2102.07064, 2021
-
[45]
latentsplat: Autoencoding variational gaussians for fast generalizable 3d reconstruction
Christopher Wewer, Kevin Raj, Eddy Ilg, Bernt Schiele, and Jan Eric Lenssen. latentsplat: Autoencoding variational gaussians for fast generalizable 3d reconstruction. In European Conference on Computer Vision, pages 456–473. Springer, 2024
work page 2024
-
[46]
Murf: multi-baseline radiance fields
Haofei Xu, Anpei Chen, Yuedong Chen, Christos Sakaridis, Yulun Zhang, Marc Pollefeys, Andreas Geiger, and Fisher Yu. Murf: multi-baseline radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20041–20050, 2024
work page 2024
-
[47]
Blendedmvs: A large-scale dataset for generalized multi-view stereo networks
Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 1790–1799, 2020. 12
work page 2020
-
[48]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. In The Thirteenth International Conference on Learning Representations , 2025
work page 2025
-
[49]
Scannet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
work page 2023
-
[50]
pixelNeRF: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelNeRF: Neural radiance fields from one or few images. In CVPR, 2021
work page 2021
-
[51]
Mvimgnet: A large-scale dataset of multi-view images
Xianggang Yu, Mutian Xu, Yidan Zhang, Haolin Liu, Chongjie Ye, Yushuang Wu, Zizheng Yan, Chenming Zhu, Zhangyang Xiong, Tianyou Liang, et al. Mvimgnet: A large-scale dataset of multi-view images. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 9150–9161, 2023
work page 2023
-
[52]
Mip-splatting: Alias-free 3d gaussian splatting
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splatting. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19447–19456, 2024
work page 2024
-
[53]
Gs-lrm: Large reconstruction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting. European Conference on Computer Vision, 2024
work page 2024
-
[54]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. arXiv preprint arXiv:2502.12138, 2025
-
[55]
Stereo magnification: learning view synthesis using multiplane images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images. ACM Trans. Graph., 37(4), 2018. 13 A Problem Setting Details In this section, we provide additional details regarding the problem settings described in Section 3 of the main paper, where we present our analysis t...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.