PLD: A Choice-Theoretic List-Wise Knowledge Distillation
Pith reviewed 2026-05-19 09:20 UTC · model grok-4.3
The pith
Plackett-Luce Distillation optimizes a single teacher-optimal ranking by treating logits as worth scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
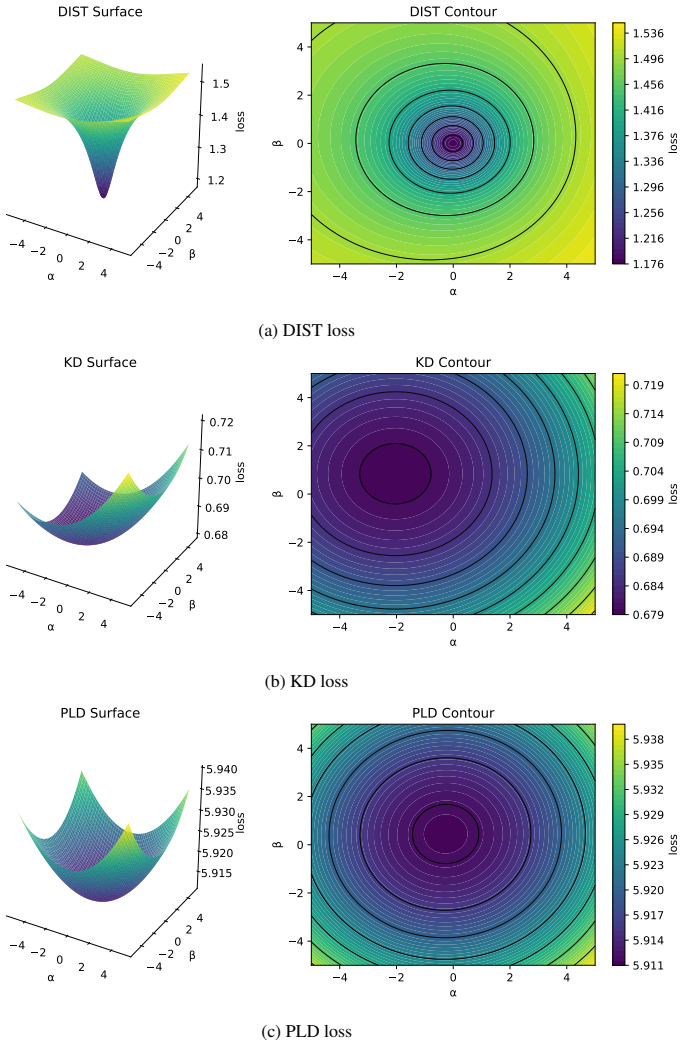
The central claim is that knowledge distillation improves by directly optimizing a teacher-optimal ranking under the Plackett-Luce model rather than adding separate divergence or correlation terms. Teacher logits are interpreted as worth scores, and the student is trained to match the ranking where the ground-truth class comes first followed by the other classes in order of decreasing teacher confidence. The resulting weighted list-wise loss is convex, invariant under logit translation, and subsumes weighted cross-entropy without introducing new tunable parameters beyond those already present in existing methods.
What carries the argument
Plackett-Luce Distillation (PLD) as a weighted list-wise ranking loss that interprets teacher logits as worth scores to enforce a single teacher-optimal ordering.
If this is right
- PLD integrates directly with divergence-based, correlation-based, and feature-based distillation objectives.
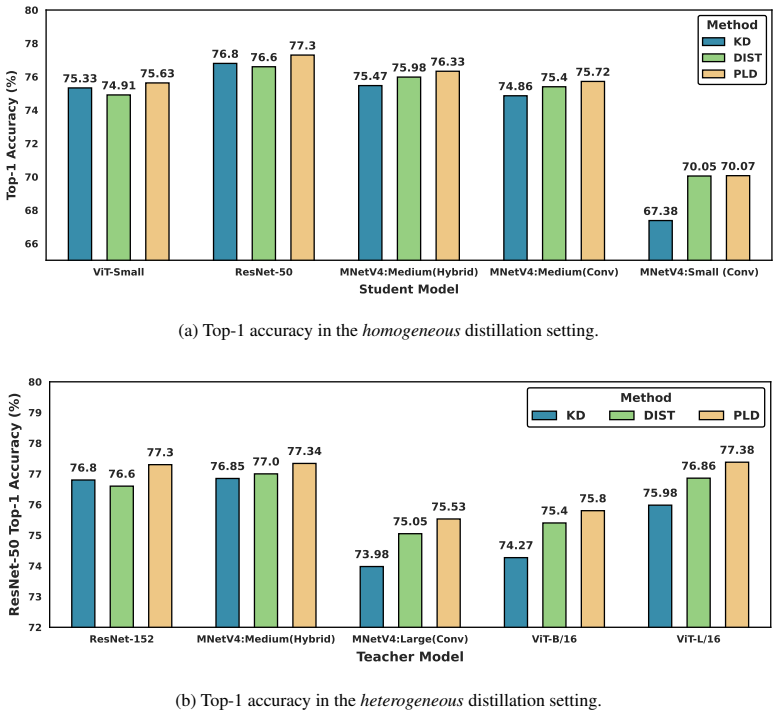
- Consistent accuracy gains appear across CIFAR-100, ImageNet-1K, and MS-COCO for both homogeneous and heterogeneous teacher-student pairs.
- The loss remains convex and translation-invariant while subsuming weighted cross-entropy.
- No extra tunable weights beyond those already used in baseline methods are introduced.
Where Pith is reading between the lines
- The choice-theoretic framing could be tested on sequential prediction tasks where order among outputs matters.
- Fewer tunable hyperparameters might simplify distillation pipelines in large-scale training.
- The same ranking construction could be examined for distillation between models of different modalities.
Load-bearing premise
That recasting teacher logits as worth scores under the Plackett-Luce model and optimizing the resulting list-wise ranking loss transfers knowledge more effectively than divergence-based or correlation-based terms without requiring additional tunable weights.
What would settle it
A controlled experiment on ImageNet-1K showing no accuracy improvement from adding PLD to a fixed teacher-student pair compared with standard KL-divergence distillation when all other hyperparameters remain unchanged.
Figures


read the original abstract
Knowledge distillation is a model compression technique in which a compact "student" network is trained to replicate the predictive behavior of a larger "teacher" network. In logit-based knowledge distillation, it has become the de facto approach to augment cross-entropy with a distillation term. Typically, this term is either a KL divergence that matches marginal probabilities or a correlation-based loss that captures intra- and inter-class relationships. In every case, it acts as an additional term to cross-entropy. This term has its own weight, which must be carefully tuned. In this paper, we adopt a choice-theoretic perspective and recast knowledge distillation under the Plackett-Luce model by interpreting teacher logits as "worth" scores. We introduce "Plackett-Luce Distillation (PLD)", a weighted list-wise ranking loss. In PLD, the teacher model transfers knowledge of its full ranking of classes, weighting each ranked choice by its own confidence. PLD directly optimizes a single "teacher-optimal" ranking. The true label is placed first, followed by the remaining classes in descending teacher confidence. This process yields a convex and translation-invariant surrogate that subsumes weighted cross-entropy. Empirically, across CIFAR-100, ImageNet-1K, and MS-COCO, PLD achieves consistent gains across diverse architectures and distillation objectives, including divergence-based, correlation-based, and feature-based methods, in both homogeneous and heterogeneous teacher-student pairs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Plackett-Luce Distillation (PLD), a list-wise knowledge distillation approach that recasts teacher logits as worth scores under the Plackett-Luce model. It defines a target ranking with the ground-truth label fixed at rank 1 followed by remaining classes sorted by descending teacher logits, then optimizes a weighted list-wise ranking loss claimed to be convex and translation-invariant while subsuming weighted cross-entropy. The method is positioned as transferring the teacher's full class ranking and is reported to yield consistent empirical gains over divergence-, correlation-, and feature-based distillation baselines on CIFAR-100, ImageNet-1K, and MS-COCO across homogeneous and heterogeneous teacher-student pairs.
Significance. If the reported gains are reproducible and the loss indeed provides a parameter-light alternative that meaningfully incorporates ranking information, PLD could serve as a useful addition to the logit-based distillation toolkit. The choice-theoretic framing offers a distinct perspective from standard KL or correlation terms, though its practical advantage hinges on whether the ground-truth augmentation in the target ranking is the primary driver of performance rather than pure teacher ranking transfer.
major comments (2)
- [§3] §3 (target ranking construction): The 'teacher-optimal' ranking places the true label first irrespective of the teacher's logit value on that class. When the teacher assigns a higher logit to an incorrect class (common on hard examples or early in training), the optimized ranking deviates from the teacher's observed ranking. This modification should be analyzed for its effect on the claim that PLD transfers 'knowledge of its full ranking of classes,' as the choice-theoretic justification appears to rely on a ground-truth-augmented target rather than the raw teacher ranking.
- [§3] §3 (loss definition and subsumption claim): The paper states that PLD yields a convex, translation-invariant surrogate that subsumes weighted cross-entropy. The explicit reduction to weighted CE (or the conditions under which this holds) should be derived step-by-step, including any assumptions on the Plackett-Luce weights, to confirm the subsumption is not merely by construction.
minor comments (2)
- [Abstract, §4] Abstract and §4: Quantitative results, standard deviations, and ablation details on the weighting scheme are referenced but not summarized with specific numbers or tables in the provided front matter; ensure the main text includes clear reporting of effect sizes relative to baselines.
- [§3] Notation: Define the Plackett-Luce probability and the exact form of the weighted list-wise loss (including how teacher confidence enters the weights) with consistent symbols before the empirical section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to include the requested clarifications and analysis.
read point-by-point responses
-
Referee: [§3] §3 (target ranking construction): The 'teacher-optimal' ranking places the true label first irrespective of the teacher's logit value on that class. When the teacher assigns a higher logit to an incorrect class (common on hard examples or early in training), the optimized ranking deviates from the teacher's observed ranking. This modification should be analyzed for its effect on the claim that PLD transfers 'knowledge of its full ranking of classes,' as the choice-theoretic justification appears to rely on a ground-truth-augmented target rather than the raw teacher ranking.
Authors: We appreciate the referee pointing out this distinction. The target ranking is constructed with the ground-truth label fixed at position 1 followed by the remaining classes ordered by descending teacher logits precisely to ensure the student learns both correct classification and the teacher's relative ordering among non-ground-truth classes. This augmentation is intentional: pure transfer of the teacher's raw ranking could reinforce errors on hard examples where the teacher assigns higher logit to an incorrect class. The choice-theoretic framing still holds because the Plackett-Luce model is applied to the full target ranking, with teacher logits serving as worth scores for the ordering of the tail. We will add a new paragraph in §3 that explicitly discusses this design choice, its implications for the 'full ranking' claim, and a brief analysis of behavior on examples where the teacher misranks the ground-truth class. revision: yes
-
Referee: [§3] §3 (loss definition and subsumption claim): The paper states that PLD yields a convex, translation-invariant surrogate that subsumes weighted cross-entropy. The explicit reduction to weighted CE (or the conditions under which this holds) should be derived step-by-step, including any assumptions on the Plackett-Luce weights, to confirm the subsumption is not merely by construction.
Authors: We agree that an explicit derivation is necessary to substantiate the subsumption claim. In the revised manuscript we will insert a step-by-step derivation immediately after the loss definition in §3. Briefly, the PLD objective is the negative log-likelihood of the target ranking under the Plackett-Luce model with student logits as worth scores. When the ranking list is considered only up to the first position (i.e., the probability of selecting the ground-truth label first), and the Plackett-Luce weights are set to the teacher-derived confidence for that position while the remaining terms vanish, the expression reduces to a weighted softmax cross-entropy loss whose weights are the teacher's normalized logit on the ground-truth class. Convexity follows directly from the convexity of the Plackett-Luce log-partition function, and translation invariance holds because adding any constant to all logits leaves the ranking probabilities unchanged. We will state the precise assumptions on the weights and provide the algebraic steps. revision: yes
Circularity Check
PLD derivation is self-contained with no circular reductions
full rationale
The paper defines PLD by interpreting teacher logits as worth scores under the Plackett-Luce model and constructing a target ranking with the true label first followed by classes sorted by descending teacher confidence. This directly defines the list-wise ranking loss optimized by the method. No equations reduce a claimed prediction to a fitted parameter or self-citation by construction. The approach is a proposed surrogate loss that subsumes weighted cross-entropy, and the derivation chain does not exhibit self-definitional or fitted-input patterns. The method is self-contained against external benchmarks as a new distillation objective.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher logits can be interpreted as worth scores in the Plackett-Luce model to define a teacher-optimal ranking of classes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PLD directly optimizes a single 'teacher-optimal' ranking—true label first, followed by the remaining classes in descending teacher confidence—yielding a convex, and translation-invariant surrogate that subsumes weighted cross-entropy.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We interpret logits as 'worth' scores in the classical Plackett-Luce permutation model... PPL(π | s) = ∏ exp(s_πk) / ∑_{l≥k} exp(s_πl)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Z. Cao, T. Qin, T.-Y . Liu, M.-F. Tsai, and H. Li. Learning to rank: from pairwise approach to listwise approach. In Proceedings of the 24th international conference on Machine learning, pages 129–136, 2007
work page 2007
-
[2]
J. H. Cho and B. Hariharan. On the efficacy of knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4794–4802, 2019
work page 2019
-
[3]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition , pages 248–255. Ieee, 2009
work page 2009
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
W.-S. Fan, S. Lu, X.-C. Li, D.-C. Zhan, and L. Gan. Revisit the essence of distilling knowledge through calibration. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[6]
A. Frydenlund, G. Singh, and F. Rudzicz. Language modelling via learning to rank. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 10636–10644, 2022
work page 2022
-
[7]
L. Gao, Z. Dai, and J. Callan. Understanding bert rankers under distillation. In Proceedings of the 2020 ACM SIGIR on International Conference on Theory of Information Retrieval, pages 149–152, 2020
work page 2020
-
[8]
J. Gou, B. Yu, S. J. Maybank, and D. Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129(6):1789–1819, 2021
work page 2021
-
[9]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
R. Herbrich, T. Graepel, and K. Obermayer. Support vector learning for ordinal regression. In 1999 Ninth International Conference on Artificial Neural Networks ICANN 99.(Conf. Publ. No. 470), volume 1, pages 97–102. IET, 1999
work page 1999
-
[11]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [12]
- [13]
-
[14]
Y . Lan, Y . Zhu, J. Guo, S. Niu, and X. Cheng. Position-aware listmle: A sequential learning process for ranking. In UAI, volume 14, pages 449–458, 2014
work page 2014
-
[15]
J.-w. Lee, M. Choi, J. Lee, and H. Shim. Collaborative distillation for top-n recommendation. In 2019 IEEE International Conference on Data Mining (ICDM), pages 369–378. IEEE, 2019
work page 2019
- [16]
-
[17]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
R. D. Luce. Individual choice behavior, volume 4. Wiley New York, 1959
work page 1959
-
[19]
T. Luo, D. Wang, R. Liu, and Y . Pan. Stochastic top-k listnet. arXiv preprint arXiv:1511.00271, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
S. I. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh. Improved knowl- edge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5191–5198, 2020
work page 2020
- [21]
-
[22]
W. Park, D. Kim, Y . Lu, and M. Cho. Relational knowledge distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3967–3976, 2019. 10
work page 2019
-
[23]
R. L. Plackett. The analysis of permutations. Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
work page 1975
-
[24]
D. Qin, C. Leichner, M. Delakis, M. Fornoni, S. Luo, F. Yang, W. Wang, C. Banbury, C. Ye, B. Akin, et al. Mobilenetv4: universal models for the mobile ecosystem. In European Conference on Computer Vision, pages 78–96. Springer, 2024
work page 2024
-
[25]
J. Rao, X. Meng, L. Ding, S. Qi, X. Liu, M. Zhang, and D. Tao. Parameter-efficient and student-friendly knowledge distillation. IEEE Transactions on Multimedia, 2023
work page 2023
- [26]
-
[27]
W. Son, J. Na, J. Choi, and W. Hwang. Densely guided knowledge distillation using multiple teacher assistants. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9395– 9404, 2021
work page 2021
-
[28]
J. Song, Y . Chen, J. Ye, and M. Song. Spot-adaptive knowledge distillation.IEEE Transactions on Image Processing, 31:3359–3370, 2022
work page 2022
-
[29]
S. Sun, W. Ren, J. Li, R. Wang, and X. Cao. Logit standardization in knowledge distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15731–15740, 2024
work page 2024
-
[30]
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
work page 2016
-
[31]
J. Tang and K. Wang. Ranking distillation: Learning compact ranking models with high performance for recommender system. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2289–2298, 2018
work page 2018
-
[32]
C. Wang, Q. Yang, R. Huang, S. Song, and G. Huang. Efficient knowledge distillation from model checkpoints. Advances in Neural Information Processing Systems, 35:607–619, 2022
work page 2022
- [33]
-
[34]
Y . Wang, C. Yang, S. Lan, W. Fei, L. Wang, G. Q. Huang, and L. Zhu. Towards industrial foundation models: Framework, key issues and potential applications. In 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), pages 1–6. IEEE, 2024
work page 2024
-
[35]
Y . Wang, C. Yang, S. Lan, L. Zhu, and Y . Zhang. End-edge-cloud collaborative computing for deep learning: A comprehensive survey. IEEE Communications Surveys & Tutorials, 2024
work page 2024
- [36]
-
[37]
R. Wightman, H. Touvron, and H. Jegou. Resnet strikes back: An improved training procedure in timm. In NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future
work page 2021
- [38]
-
[39]
X. Xie, P. Zhou, H. Li, Z. Lin, and S. Yan. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[40]
C. Yang, Y . Wang, S. Lan, L. Wang, W. Shen, and G. Q. Huang. Cloud-edge-device collaboration mechanisms of deep learning models for smart robots in mass personalization. Robotics and Computer- Integrated Manufacturing, 77:102351, 2022
work page 2022
-
[41]
S. Yin, Z. Xiao, M. Song, and J. Long. Adversarial distillation based on slack matching and attribution re- gion alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24605–24614, 2024
work page 2024
- [42]
-
[43]
M. Yuan, B. Lang, and F. Quan. Student-friendly knowledge distillation. Knowledge-Based Systems, 296:111915, 2024
work page 2024
-
[44]
Z.-H. Zhou. Learnware: on the future of machine learning. Frontiers Comput. Sci., 10(4):589–590, 2016
work page 2016
-
[45]
Y . Zhu, N. Liu, Z. Xu, X. Liu, W. Meng, L. Wang, Z. Ou, and J. Tang. Teach less, learn more: On the undistillable classes in knowledge distillation. Advances in Neural Information Processing Systems, 35:32011–32024, 2022
work page 2022
- [46]
-
[47]
J. Zhuang, T. Tang, Y . Ding, S. C. Tatikonda, N. Dvornek, X. Papademetris, and J. Duncan. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Advances in neural information processing systems, 33:18795–18806, 2020. 12 A Gradient Derivation for PLD Loss A.1 Definitions Let s = (s1, . . . , sC) ∈ RC be the student’s logits. Letπ∗ =...
work page 2020
-
[48]
∂ ∂si −αksπ∗ k = −αk ∂sπ∗ k ∂si
Derivative of the affine term: The first term is −αksπ∗ k. ∂ ∂si −αksπ∗ k = −αk ∂sπ∗ k ∂si . Since sπ∗ k is the component of s at index π∗ k, its derivative with respect to si is 1 if i = π∗ k and 0 otherwise. This can be written using the indicator function 1{i = π∗ k}. ∂ ∂si −αksπ∗ k = −αk1{i = π∗ k}
-
[49]
Derivative of the log-sum-exp term: The second term is αkϕk(s), where ϕk(s) = logPC ℓ=k exp(sπ∗ ℓ ). ∂ ∂si (αkϕk(s)) = αk ∂ϕk ∂si . To compute ∂ϕk ∂si , let Xk(s) = PC ℓ=k exp(sπ∗ ℓ ). Then ϕk(s) = log Xk(s). Using the chain rule, ∂ϕk ∂si = 1 Xk(s) ∂Xk(s) ∂si . Now, we compute ∂Xk(s) ∂si : ∂Xk(s) ∂si = ∂ ∂si CX ℓ=k exp(sπ∗ ℓ ) ! = CX ℓ=k ∂ ∂si (exp(sπ∗ ℓ ...
-
[50]
Must␣remove␣exactly␣one␣true␣label␣per␣row
Combining derivatives for Lk(s). Now, we combine the derivatives of the two parts ofLk(s): ∂Lk ∂si = ∂ ∂si −αksπ∗ k + ∂ ∂si (αkϕk(s)) = −αk1{i = π∗ k} + αkσk(i) = αk [σk(i) − 1{i = π∗ k}] . A.3 Final Gradient ∇sL(s): The i-th component of the gradient of the total loss L(s) is: ∂L ∂si = CX k=1 ∂Lk ∂si = CX k=1 αk [σk(i) − 1{i = π∗ k}] . We can separate th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.