SciGA: A Comprehensive Dataset for Designing Graphical Abstracts in Academic Papers
Pith reviewed 2026-05-19 05:55 UTC · model grok-4.3
The pith
A dataset of 145,000 papers and 1.14 million figures supports AI tasks for selecting and recommending graphical abstracts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By releasing the SciGA-145k dataset and defining intra-GA and inter-GA recommendation tasks along with the Confidence Adjusted top-1 ground truth Ratio metric, the work demonstrates the viability of using machine learning for graphical abstract design support in academic papers.
What carries the argument
SciGA-145k dataset of 145k papers and 1.14M figures, which enables training and evaluation of models for intra-paper and inter-paper graphical abstract recommendation.
Load-bearing premise
That the figures chosen as graphical abstracts in the source papers, plus other figures from those papers, serve as reliable examples of good graphical abstracts.
What would settle it
Conducting a controlled experiment where domain experts rate the quality of AI-recommended figures versus non-recommended ones for use as graphical abstracts would test the practical usefulness of the tasks and metric.
Figures














read the original abstract
Graphical Abstracts (GAs) play a crucial role in visually conveying the key findings of scientific papers. Although recent research increasingly incorporates visual materials such as Figure 1 as de facto GAs, their potential to enhance scientific communication remains largely unexplored. Designing effective GAs requires advanced visualization skills, hindering their widespread adoption. To tackle these challenges, we introduce SciGA-145k, a large-scale dataset comprising approximately 145,000 scientific papers and 1.14 million figures, specifically designed to support GA selection and recommendation, and to facilitate research in automated GA generation. As a preliminary step toward GA design support, we define two tasks: 1) Intra-GA Recommendation, identifying figures within a given paper well-suited as GAs, and 2) Inter-GA Recommendation, retrieving GAs from other papers to inspire new GA designs. Furthermore, we propose Confidence Adjusted top-1 ground truth Ratio (CAR), a novel recommendation metric for fine-grained analysis of model behavior. CAR addresses limitations of traditional rank-based metrics by considering that not only an explicitly labeled GA but also other in-paper figures may plausibly serve as GAs. Benchmark results demonstrate the viability of our tasks and the effectiveness of CAR. Collectively, these establish a foundation for advancing scientific communication within AI for Science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciGA-145k, a dataset of approximately 145,000 scientific papers and 1.14 million figures, to support research on graphical abstract (GA) design. It defines two tasks (Intra-GA Recommendation within a paper and Inter-GA Recommendation across papers), proposes the Confidence Adjusted top-1 ground truth Ratio (CAR) metric to account for plausible alternative GAs, and reports benchmark results claiming to demonstrate task viability and CAR effectiveness for advancing AI-assisted scientific communication.
Significance. If the results hold, the work supplies a large-scale public resource that could accelerate development of automated tools for visual scientific summarization. The scale of the dataset and the introduction of CAR—which adjusts standard ranking metrics to credit other in-paper figures as potentially suitable GAs—are concrete strengths that address practical evaluation challenges in recommendation settings.
major comments (1)
- [§3] §3 (Dataset Construction): Positive labels for effective GAs are defined solely via figures explicitly presented as GAs in the collected papers together with other in-paper figures. No independent expert validation, ratings on design criteria (clarity, information density, visual hierarchy), or inter-annotator agreement is reported. This assumption is load-bearing for the central claim in §5 that benchmarks demonstrate task viability and CAR effectiveness; without measurable superiority of the labeled GAs, the reported numbers risk reflecting dataset artifacts rather than genuine progress on identifying well-suited GAs.
minor comments (2)
- [Abstract] The abstract states benchmark results demonstrate viability but does not include even a single key performance figure (e.g., CAR score or top-1 accuracy), which would help readers quickly gauge the strength of the empirical support.
- [§4] Notation for the CAR adjustment formula would be clearer if presented as an explicit equation in the main text rather than referenced only descriptively.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential value of the SciGA-145k dataset and the CAR metric. We address the single major comment below and describe the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): Positive labels for effective GAs are defined solely via figures explicitly presented as GAs in the collected papers together with other in-paper figures. No independent expert validation, ratings on design criteria (clarity, information density, visual hierarchy), or inter-annotator agreement is reported. This assumption is load-bearing for the central claim in §5 that benchmarks demonstrate task viability and CAR effectiveness; without measurable superiority of the labeled GAs, the reported numbers risk reflecting dataset artifacts rather than genuine progress on identifying well-suited GAs.
Authors: We agree that the labeling relies on figures already designated as GAs by the original paper authors, together with the remaining in-paper figures. This choice was deliberate: it leverages existing publishing conventions at scale (145k papers) rather than introducing new subjective annotations that would be costly and difficult to scale. The Intra-GA task is explicitly formulated to treat multiple in-paper figures as potentially suitable, which is why CAR was developed to credit plausible alternatives instead of penalizing them. The reported benchmarks therefore demonstrate that models can be trained to recover the author-chosen GA and to surface other viable candidates, providing an initial proof of concept for the tasks. Nevertheless, we recognize that the absence of independent expert ratings on criteria such as clarity or visual hierarchy constitutes a genuine limitation for stronger claims about label quality. In the revised manuscript we will (i) add an explicit limitations paragraph in §3 detailing this assumption and its implications, (ii) include a forward-looking statement on planned expert validation studies, and (iii) temper the language in §5 to emphasize that the results establish task viability under the current labeling rather than absolute superiority of the labeled GAs. These changes will make the evidential basis clearer without altering the dataset or core experiments. revision: partial
Circularity Check
No significant circularity; dataset, tasks, and CAR metric are explicitly defined without reduction to inputs by construction.
full rationale
The paper centers on releasing SciGA-145k and defining Intra-GA and Inter-GA recommendation tasks plus the CAR metric. No equations, derivations, or predictions are presented that reduce by construction to fitted parameters, self-referential quantities, or self-citation chains. Ground truth is explicitly constructed from paper-provided GAs and in-paper figures, and benchmarks are empirical evaluations on this dataset; the contribution remains self-contained with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Some figures within scientific papers are suitable to function as graphical abstracts
invented entities (1)
-
CAR metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce SciGA-145k... define two tasks: 1) Intra-GA Recommendation... 2) Inter-GA Recommendation... propose CAR@k... benchmark results demonstrate the viability of our tasks
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
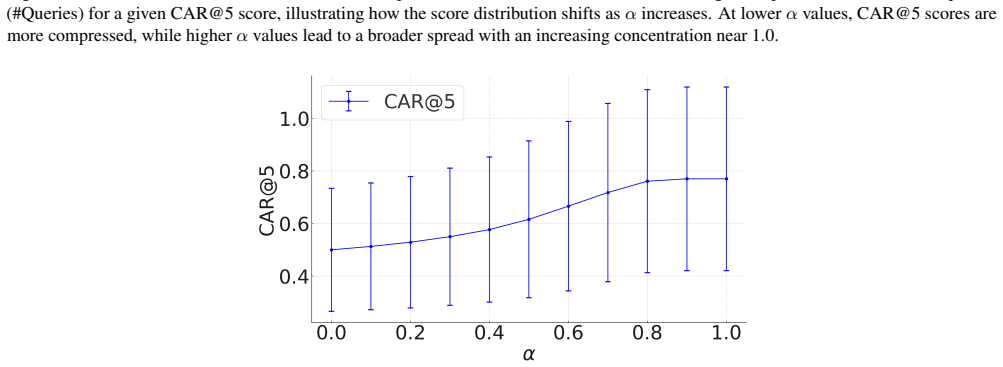
CAR@k = pGT / ptop-1 * C(P,k) where C uses entropy H(P) of top-k relevance scores
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models, 2024. https://doi.org/10.48550/arXiv.2404.07738. 1
-
[2]
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In ACL, 2005. 5, 7, 8
work page 2005
-
[3]
Hunter Bennett and Flynn Slattery. Graphical abstracts are associated with greater Altmetric attention scores, but not citations, in sport science. Scientometrics, 128:3793–3804,
-
[4]
Bruce G. Buchanan and Edward A. Feigenbaum. Dendral and meta-dendral: Their applications dimension. Artificial Intelligence, 11(1):5–12, 1978. 1
work page 1978
-
[5]
Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender
Christopher J.C. Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. Learning to rank using gradient descent. In ICML, 2005. 4
work page 2005
-
[6]
S. J. Chapman, R. C. Grossman, M. E. B. FitzPatrick, and R. R. W. Brady. Randomized controlled trial of plain English and visual abstracts for disseminating surgical research via social media. British Journal of Surgery, 106(12):1611–1616,
-
[7]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. In CVPR,
-
[8]
Franz Josef Och Chin-Yew Lin. Automatic Evaluation of Machine Translation Quality Using Longest Common Sub- sequence and Skip-Bigram Statistics. In ACL, 2004. 5, 7, 8
work page 2004
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR, 2021. 2, 5, 7, 4
work page 2021
-
[10]
DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents
Tsu-Jui Fu, William Yang Wang, Daniel McDuff, and Yale Song. DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents. In AAAI, 2022. 1, 3
work page 2022
-
[11]
ar5iv:04.2024 dataset, an HTML5 conversion of arXiv.org, 2024
Deyan Ginev. ar5iv:04.2024 dataset, an HTML5 conversion of arXiv.org, 2024. SIGMathLing – Special Interest Group on Math Linguistics. 4
work page 2024
-
[12]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A Reference-free Evaluation Metric for Image Captioning. In EMNLP, 2021. 5
work page 2021
-
[13]
Hoffberg, Joe Huggins, Audrey Cobb, Jeri E
Adam S. Hoffberg, Joe Huggins, Audrey Cobb, Jeri E. Forster, and Nazanin H. Bahraini. Beyond Journals—Visual Abstracts Promote Wider Suicide Prevention Research Dissemination and Engagement: A Randomized Crossover Trial. Frontiers in Research Metrics and Analytics, 5, 2020. 2, 3
work page 2020
-
[14]
Simon Huang, Lynsey J. Martin, Calvin H. Yeh, Alvin Chin, Heather Murray, William B. Sanderson, Rohit Mohindra, Teresa M. Chan, and Brent Thoma. The effect of an info- graphic promotion on research dissemination and readership: A randomized controlled trial. Canadian Journal of Emer- gency Medicine, 20(6):826—-833, 2018. 1
work page 2018
-
[15]
Andrew M. Ibrahim, Keith D. Lillemoe, Mary E. Klingen- smith, and Justin B. Dimick. Visual Abstracts to Dissemi- nate Research on Social Media A Prospective, Case-control Crossover Study. Annals of Surgery, 266(6):46–48, 2017. 2, 3
work page 2017
-
[16]
Attract readers with a graphical abstract – The latest clickbait
Madhan Jeyaraman and Raju Vaishya. Attract readers with a graphical abstract – The latest clickbait. Journal of Or- thopaedics. Journal of Orthopaedics , 38(1):30–31, 2023. 2, 3
work page 2023
-
[17]
Madhan Jeyaraman, Harish V . K. Ratna, Naveen Jeyara- man, Nicola Maffulli, Filippo Migliorini, Arulkumar Nal- lakumarasamy, and Sankalp Yadav. Graphical Abstract in Scientific Research. Cureus, 15(9), 2023. 2, 3, 4
work page 2023
-
[18]
Yohan Kim, Ji-Eun Lee, Jeong-Ju Yoo, Eun-Ae Jung, Sang Gyune Kim, and Young Seok Kim. Seeing Is Believing: The Effect of Graphical Abstracts on Citations and Social Media Exposure in Gastroenterology & Hepatology Journals. Journal of Korean Medical Science, 37, 2022. 3
work page 2022
-
[19]
Rebecca A. Krukowski and Carly M. Goldstein. The potential for graphical abstracts to enhance science communication. Transl Behav Med, 13(12):891–895, 2023. 3
work page 2023
-
[20]
Kunze, Amar Vadhera, Ritika Purbeyc, Harsh Singh, Gregory S
Kyle N. Kunze, Amar Vadhera, Ritika Purbeyc, Harsh Singh, Gregory S. Kazarian, and Jorge Chahla. Infographics are more effective at increasing social media attention in comparison with original research articles: An altmetrics-based analysis. Canadian Journal of Emergency Medicine, 37(8):2591–2597,
-
[21]
The current state of graphical abstracts and how to create good graphical abstracts
Jieun Lee and Jeong-Ju Yoo. The current state of graphical abstracts and how to create good graphical abstracts. Science Editing, 10(1):19–26, 2023. 2, 3
work page 2023
-
[22]
Douglas B. Lenat. Automated Theory Formation in Mathe- matics. In IJCAI, 1977. 1
work page 1977
-
[23]
Douglas B. Lenat and John Seely Brown. Why am and eurisko appear to work. In AAAI, 1983. 1
work page 1983
-
[24]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP- 2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. In ICML, 2023. 6, 7, 8, 4
work page 2023
-
[25]
Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision- Language Models
Lei Li, Yuqi Wang, Runxin Xu, Peiyi Wang, Xiachong Feng, Lingpeng Kong, and Qi Liu. Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision- Language Models. In ACL, 2024. 3
work page 2024
-
[26]
Wilson, Woosang Lim, and William Yang Wang
Zekun Li, Xianjun Yang, Kyuri Choi, Wanrong Zhu, Ryan Hsieh, HyeonJung Kim, Jin Hyuk Lim, Sungy- oung Ji, Byungju Lee, Xifeng Yan, Linda Ruth Petzold, Stephen D. Wilson, Woosang Lim, and William Yang Wang. MMSci: A Dataset for Graduate-Level Multi- Discipline Multimodal Scientific Understanding, 2024. https://doi.org/10.48550/arXiv.2407.04903. 3
-
[27]
Swin Transformer V2: Scaling Up Capacity and Resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. Swin Transformer V2: Scaling Up Capacity and Resolution. In CVPR, 2022. 2, 5, 7, 4
work page 2022
-
[28]
S2ORC: The Semantic Scholar Open Re- search Corpus
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. S2ORC: The Semantic Scholar Open Re- search Corpus. In ACL, 2020. 3
work page 2020
-
[29]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Lange, Jakob Foerste, Jeff Clune, and David Ha. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, 2024. https://doi.org/10.48550/arXiv.2408.06292. 1
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.06292 2024
-
[30]
UMAP: Uniform Manifold Approximation and Projection
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Grossberger. UMAP: Uniform Manifold Approximation and Projection. The Journal of Open Source Software, 3(29):861,
-
[31]
Lennart Meincke, Karan Girotra, Gideon Nave, Christian Terwiesch, and Karl T. Ulrich. Using Large Language Models for Idea Generation in Innovation. SSRN Electronic Journal,
-
[32]
Schoenholz, Mu- ratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk
Amil Merchant, Simon Batzner, Samuel S. Schoenholz, Mu- ratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk. Scal- ing deep learning for materials discovery. Nature, 624:80–85,
-
[33]
The Role of Visual Abstracts in the Dissemination of Medical Research
Beverley C Millar and Michelle Lim. The Role of Visual Abstracts in the Dissemination of Medical Research. Ulster Medical Journal, 91(2):67–78, 2022. 3, 4
work page 2022
-
[34]
Edward O. Pyzer-Knapp, Jed W. Pitera, Peter W. J. Staar, Seiji Takeda, Teodoro Laino, Daniel P. Sanders, James Sex- ton, John R. Smith, and Alessandro Curioni. Accelerating materials discovery using artificial intelligence, high perfor- mance computing and robotics. npj Computational Materials, 8(84), 2022. 1
work page 2022
-
[35]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2022. 2, 4, 7, 8
work page 2022
-
[36]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In EMNLP,
-
[37]
Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford
Stephen E. Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford. Okapi at trec-3. In TREC-3, 1994. 5, 7, 8
work page 1994
-
[38]
Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau Rodriguez
Juan A. Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau Rodriguez. FigGen: Text to Scientific Figure Generation. In ICLR, 2023. 1, 3
work page 2023
-
[39]
Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau Rodriguez
Juan A. Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau Rodriguez. OCR-VQGAN: Taming Text- within-Image Generation. In WACV, 2023. 3
work page 2023
-
[40]
Tarek Saier, Johan Krause, and Michael F ¨arber. unarXive 2022: All arXiv Publications Pre-Processed for NLP, Includ- ing Structured Full-Text and Citation Network. In JCDL,
work page 2022
-
[41]
Szymanski, Bernardus Rendy, Yuxing Fei, Rishi E
Nathan J. Szymanski, Bernardus Rendy, Yuxing Fei, Rishi E. Kumar, Tanjin He, David Milsted, Matthew J. McDermott, Max Gallant, Ekin Dogus Cubuk, Amil Merchant, Haegyeom Kim, Anubhav Jain, Christopher J. Bartel, Kristin Persson, Yan Zeng, and Gerbrand Ceder. An autonomous laboratory for the accelerated synthesis of novel materials. Nature, 624: 86–91, 2023. 1
work page 2023
-
[42]
Mingxing Tan and Quoc V . Le. Efficientnetv2: Smaller Mod- els and Faster Training. In ICML, 2021. 5, 7, 4
work page 2021
-
[43]
SciPost- Layout: A Dataset for Layout Analysis and Layout Genera- tion of Scientific Posters
Shohei Tanaka, Hao Wang, and Yoshitaka Ushiku. SciPost- Layout: A Dataset for Layout Analysis and Layout Genera- tion of Scientific Posters. In BMVC, 2024. 1, 3
work page 2024
-
[44]
Learning to Generate Posters of Scientific Papers by Probabilistic Graphical Models
Yu ting Qiang, Yanwei Fu, Xiao Yu, Yanwen Guo, Zhi-Hua Zhou, and Leonid Sigal. Learning to Generate Posters of Scientific Papers by Probabilistic Graphical Models. Journal of Computer Science and Technology, 34:155–169, 2019. 3
work page 2019
-
[45]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding, 2018. https://doi.org/10.48550/arXiv.1807.03748. 6
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.03748 2018
-
[46]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalu- ation. In CVPR, 2015. 5, 7, 8
work page 2015
-
[47]
OverleafCopilot: Empowering Aca- demic Writing in Overleaf with Large Language Models,
Haomin Wen, Zhenjie Wei, Yan Lin, Jiyuan Wang, Yuxuan Liang, and Huaiyu Wan. OverleafCopilot: Empowering Aca- demic Writing in Overleaf with Large Language Models,
-
[48]
https://doi.org/10.48550/arXiv.2403.09733. 1
-
[49]
Con- vNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Con- vNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. In CVPR, 2023. 2, 5, 7, 4
work page 2023
-
[50]
Automatic Paper Summary Generation from Visual and Textual Information
Shintaro Yamamoto, Yoshihiro Fukuhara, Ryota Suzuki, Shi- geo Morishima, and Hirokatsu Kataoka. Automatic Paper Summary Generation from Visual and Textual Information. In ICMV, 2018. 3, 5
work page 2018
-
[51]
Ma Yuanyuan and Jiang Kevin. Verbal and visual resources in graphical abstracts: Analyzing patterns of knowledge pre- sentation in digital genres. Ib´erica, 46:129–154, 2023. 4
work page 2023
-
[52]
Yan Zeng, Xinsong Zhang, Hang Li, Jiawei Wang, Jipeng Zhang, and Wangchunshu Zhou. X2-VLM: All-in-One Pre- Trained Model for Vision-Language Tasks.IEEE transactions on pattern analysis and machine intelligence , 46(5):3156– 3168, 2023. 6, 7, 8, 4
work page 2023
-
[53]
Long-CLIP: Unlocking the Long-Text Capability of CLIP
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-CLIP: Unlocking the Long-Text Capability of CLIP. In ECCV, 2024. 2, 6, 7, 8, 4
work page 2024
-
[54]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Wein- berger, and Yoav Artzi. BERTScore: Evaluating Text Genera- tion with BERT. In ICLR, 2020. 5, 7, 8, 4
work page 2020
-
[55]
Hao Zheng, Xinyan Guan, Hao Kong, Jia Zheng, Weix- iang Zhou, Hongyu Lin, Yaojie Lu, Ben He, Xian- pei Han, and Le Sun. PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides, 2025. https://doi.org/10.48550/arXiv.2501.03936. 3 A. Dataset Structure The textual data and associated metadata of SciGA-145k are provided in JSON format, as illus...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.