FOCUS: Fused Observation of Channels for Unveiling Spectra
Pith reviewed 2026-05-19 03:48 UTC · model grok-4.3
The pith
FOCUS enables frozen vision transformers to generate reliable spatial-spectral saliency maps for hyperspectral images in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
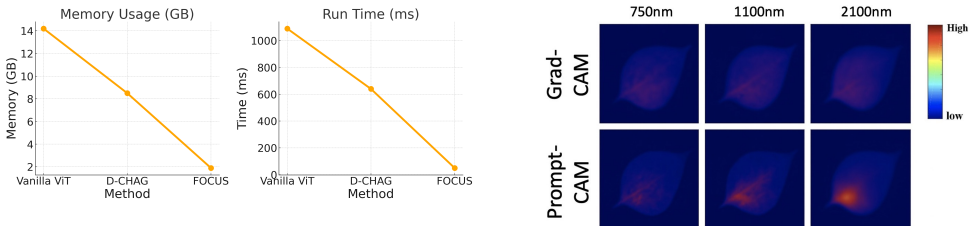
FOCUS is the first framework that enables reliable and efficient spatial-spectral interpretability for frozen ViTs. It introduces class-specific spectral prompts that guide attention toward semantically meaningful wavelength groups, and a learnable [SINK] token trained with an attraction loss to absorb noisy or redundant attention. Together these designs make it possible to generate stable and interpretable 3D saliency maps and spectral importance curves in a single forward pass, without any gradient backpropagation or backbone modification.
What carries the argument
Class-specific spectral prompts paired with a learnable [SINK] token under an attraction loss, which together direct and stabilize attention flow in a frozen vision transformer processing hyperspectral data.
Load-bearing premise
That class-specific spectral prompts and the attraction loss on the sink token will reliably guide attention to semantically meaningful wavelength groups in a single forward pass without any backbone modification or gradient computation.
What would settle it
A hyperspectral dataset where the saliency maps and spectral curves produced by FOCUS show no measurable overlap with expert-annotated important wavelengths for the same classes.
Figures





read the original abstract
Hyperspectral imaging (HSI) captures hundreds of narrow, contiguous wavelength bands, making it a powerful tool in biology, agriculture, and environmental monitoring. However, interpreting Vision Transformers (ViTs) in this setting remains largely unexplored due to two key challenges: (1) existing saliency methods struggle to capture meaningful spectral cues, often collapsing attention onto the class token, and (2) full-spectrum ViTs are computationally prohibitive for interpretability, given the high-dimensional nature of HSI data. We present FOCUS, the first framework that enables reliable and efficient spatial-spectral interpretability for frozen ViTs. FOCUS introduces two core components: class-specific spectral prompts that guide attention toward semantically meaningful wavelength groups, and a learnable [SINK] token trained with an attraction loss to absorb noisy or redundant attention. Together, these designs make it possible to generate stable and interpretable 3D saliency maps and spectral importance curves in a single forward pass, without any gradient backpropagation or backbone modification. FOCUS improves band-level IoU by 15 percent, reduces attention collapse by over 40 percent, and produces saliency results that align closely with expert annotations. With less than 1 percent parameter overhead, our method makes high-resolution ViT interpretability practical for real-world hyperspectral applications, bridging a long-standing gap between black-box modeling and trustworthy HSI decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FOCUS, a framework for spatial-spectral interpretability of frozen Vision Transformers on hyperspectral imaging data. It adds class-specific spectral prompts and a learnable [SINK] token with an attraction loss to produce 3D saliency maps and spectral importance curves in a single forward pass, without gradients or backbone modification. The work claims a 15% gain in band-level IoU, over 40% reduction in attention collapse, close alignment with expert annotations, and less than 1% parameter overhead.
Significance. If the faithfulness of the saliency maps to the unmodified frozen ViT holds and the quantitative gains are robustly supported, the approach could meaningfully advance practical interpretability for high-dimensional HSI applications in biology, agriculture, and environmental monitoring. The single-pass efficiency and minimal overhead would be a clear practical strength for real-world deployment.
major comments (1)
- [Abstract] Abstract: The central claim that FOCUS delivers 'reliable' interpretability of the frozen ViT is load-bearing for the contribution, yet the addition of class-specific spectral prompts and the [SINK] token modifies the input token sequence. This alteration can shift attention weights among the original patch and class tokens in a single forward pass, even without backbone changes or gradients. It is therefore unclear whether the reported 15% IoU improvement and 40% collapse reduction reflect intrinsic spectral cues of the original model or are driven by the auxiliary loss and prompts; a targeted faithfulness check (e.g., comparison of attention before/after insertion on the same frozen backbone) is required.
minor comments (1)
- [Abstract] Abstract: Quantitative claims are stated without reference to experimental setup, baselines, number of runs, statistical significance testing, or dataset details, which hinders immediate assessment of reproducibility and effect-size reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding the faithfulness of the interpretability claims below and are prepared to strengthen the paper with additional analysis.
read point-by-point responses
-
Referee: The central claim that FOCUS delivers 'reliable' interpretability of the frozen ViT is load-bearing for the contribution, yet the addition of class-specific spectral prompts and the [SINK] token modifies the input token sequence. This alteration can shift attention weights among the original patch and class tokens in a single forward pass, even without backbone changes or gradients. It is therefore unclear whether the reported 15% IoU improvement and 40% collapse reduction reflect intrinsic spectral cues of the original model or are driven by the auxiliary loss and prompts; a targeted faithfulness check (e.g., comparison of attention before/after insertion on the same frozen backbone) is required.
Authors: We agree that the insertion of class-specific spectral prompts and the learnable [SINK] token modifies the input token sequence, which can influence attention weight distributions even with a frozen backbone. This is a substantive point that merits explicit verification to confirm that the observed improvements in band-level IoU and attention collapse reduction primarily capture intrinsic spectral cues rather than being artifacts of the auxiliary components. In the revised manuscript we will add a targeted faithfulness experiment that directly compares attention maps (on the original patch and class tokens) produced by the identical frozen ViT with and without the prompts and [SINK] token. This analysis will quantify any shifts and provide quantitative evidence supporting the reliability of the reported gains. revision: yes
Circularity Check
No circularity: novel components introduced without reduction to inputs or self-citation chains
full rationale
The paper introduces FOCUS via two explicitly new design elements—class-specific spectral prompts and a learnable [SINK] token with attraction loss—presented as additions that enable single-forward-pass saliency on frozen ViTs. No equations, derivations, or fitted parameters are shown that reduce by construction to prior outputs or self-citations. The reported gains (15% IoU, 40% collapse reduction) are framed as empirical outcomes rather than forced by definition or imported uniqueness theorems. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FOCUS introduces two core components: class-specific spectral prompts that guide attention toward semantically meaningful wavelength groups, and a learnable [SINK] token trained with an attraction loss to absorb noisy or redundant attention.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lsink = −λ ∑ℓ 1/|Haux| ∑h∈Haux meani Aℓ,h[i,ksink]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
The first survey on Attention Sink in Transformers structures the literature around fundamental utilization, mechanistic interpretation, and strategic mitigation.
Reference graph
Works this paper leans on
-
[1]
Quantifying attention flow in transformers
Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 4190–4197, 2020. 2, 5
work page 2020
-
[2]
Learning to mask and permute visual tokens for vision transformer pre- training
Lorenzo Baraldi, Roberto Amoroso, Marcella Cornia, An- drea Pilzer, and Rita Cucchiara. Learning to mask and permute visual tokens for vision transformer pre- training. Computer Vision and Image Understanding, 2025. arXiv:2306.07346. 8
-
[3]
Grad-cam++: General- ized gradient-based visual explanations for deep convolu- tional networks
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-cam++: General- ized gradient-based visual explanations for deep convolu- tional networks. In 2018 IEEE winter conference on appli- cations of computer vision (WACV) , pages 839–847. IEEE,
work page 2018
-
[4]
Transformer inter- pretability beyond attention visualization
Hila Chefer, Shir Gur, and Lior Wolf. Transformer inter- pretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 782–791, 2021. 2, 5
work page 2021
-
[5]
Optimiz- ing relevance maps of vision transformers improves robust- ness
Hila Chefer, Idan Schwartz, and Lior Wolf. Optimiz- ing relevance maps of vision transformers improves robust- ness. In Advances in Neural Information Processing Systems (NeurIPS), 2022. 7, 8
work page 2022
-
[6]
Barnett, Jonathan Su, and Cynthia Rudin
Chaofan Chen, Oscar Li, Chaofan Tao, Alina J. Barnett, Jonathan Su, and Cynthia Rudin. This looks like that: Deep learning for interpretable image recognition. In Advances in Neural Information Processing Systems (NeurIPS), pages 8821–8832, 2019. 5
work page 2019
-
[7]
Sst: Spatial and semantic transformers for multi-label image recognition
Zhao-Min Chen, Quan Cui, Borui Zhao, Renjie Song, Xi- aoqin Zhang, and Osamu Yoshie. Sst: Spatial and semantic transformers for multi-label image recognition. IEEE Trans- actions on Image Processing, 31:2570–2583, 2022. 2
work page 2022
-
[8]
Prompt-cam: A simpler interpretable transformer for fine-grained analysis
Arpita Chowdhury, Dipanjyoti Paul, Zheda Mai, Jianyang Gu, Ziheng Zhang, Kazi Sajeed Mehrab, Elizabeth G Campolongo, Daniel Rubenstein, Charles V Stewart, Anuj Karpatne, et al. Prompt-cam: A simpler interpretable transformer for fine-grained analysis. arXiv preprint arXiv:2501.09333, 2025. 2, 3, 5, 6, 7
-
[9]
Vision Transformers Need Registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Pi- otr Bojanowski. Vision transformers need registers. arXiv preprint arXiv:2309.16588, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Vi- sion transformers need registers
Timoth ´ee Darcet, Amir Dezfouli, Maximilian Igl, Andr ´e Barreto, John Quan, Vedanuj Misra, Jared Kaplan, George Tucker, Tom Schaul, Xavier Puig, and Emilio Parisotto. Vi- sion transformers need registers. In Proceedings of the In- ternational Conference on Learning Representations (ICLR),
- [12]
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Sanet: Structure-aware net- work for visual tracking
Heng Fan and Haibin Ling. Sanet: Structure-aware net- work for visual tracking. In Proceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 42–49, 2017. 3, 5, 6, 7
work page 2017
-
[15]
Mohsen Fayyaz, Soroush A. Koohpayegani, Farnoush R. Ja- fari, Sunando Sengupta, Hamid R. Vaezi Joze, Eric Sommer- lade, Hamed Pirsiavash, and Juergen Gall. Adaptive token sampling for efficient vision transformers. arXiv preprint arXiv:2111.15667, 2021. 3
-
[16]
Wenfeng Feng and Guoying Sun. Edit: Enhanc- ing vision transformers by mitigating attention sink through an encoder–decoder architecture. arXiv preprint arXiv:2504.06738, 2025. 3
-
[17]
Axiom-based grad-cam: Towards accurate visualization and explanation of cnns
Ruigang Fu, Qingyong Hu, Xiaohu Dong, Yulan Guo, Yinghui Gao, and Biao Li. Axiom-based grad-cam: To- wards accurate visualization and explanation of cnns. arXiv preprint arXiv:2008.02312, 2020. 2, 5
-
[18]
Sptrack: Spectral similarity prompt learning for hyperspectral object tracking
Gaowei Guo, Zhaoxu Li, Wei An, Yingqian Wang, Xu He, Yihang Luo, Qiang Ling, Miao Li, and Zaiping Lin. Sptrack: Spectral similarity prompt learning for hyperspectral object tracking. Remote Sensing, 16(16):2975, 2024. 3
work page 2024
-
[19]
Hyperprompt: Prompt-based task-conditioning of transformers
Yun He, Steven Zheng, Yi Tay, Jai Gupta, Yu Du, Vamsi Aribandi, Zhe Zhao, YaGuang Li, Zhao Chen, Donald Met- zler, et al. Hyperprompt: Prompt-based task-conditioning of transformers. In International conference on machine learn- ing, pages 8678–8690. PMLR, 2022. 3, 5, 6, 7
work page 2022
-
[20]
Spectralformer: Re- thinking hyperspectral image classification with transform- ers
Danfeng Hong, Zhu Han, Jing Yao, Lianru Gao, Bing Zhang, Antonio Plaza, and Jocelyn Chanussot. Spectralformer: Re- thinking hyperspectral image classification with transform- ers. IEEE Transactions on Geoscience and Remote Sensing, 60:1–15, 2021. 2
work page 2021
-
[21]
Spectralformer: Re- thinking hyperspectral image classification with transform- ers
Danfeng Hong, Zhu Han, Jing Yao, Lianru Gao, Bing Zhang, Antonio Plaza, and Jocelyn Chanussot. Spectralformer: Re- thinking hyperspectral image classification with transform- ers. IEEE Transactions on Geoscience and Remote Sensing, 60:5518615, 2022. 3
work page 2022
-
[22]
Specformer: Guarding vision trans- former robustness via maximum singular value penalization
Xixu Hu, Runkai Zheng, Jindong Wang, Cheuk Hang Leung, Qi Wu, and Xing Xie. Specformer: Guarding vision trans- former robustness via maximum singular value penalization. arXiv preprint arXiv:2402.03317, 2024. 3 9
-
[23]
Layercam: Exploring hierarchical class activation maps for localization
Peng-Tao Jiang, Chang-Bin Zhang, Qibin Hou, Ming-Ming Cheng, and Yunchao Wei. Layercam: Exploring hierarchical class activation maps for localization. IEEE Transactions on Image Processing, 30:5875–5888, 2021. 2, 5
work page 2021
-
[24]
HyperLeaf2024 – a hyper- spectral imaging dataset for classification and regression of wheat leaves
William Michael Laprade, Pawel Pieta, Svetlana Kutuzova, Jesper Cairo Westergaard, Mads Nielsen, Svend Christensen, and Anders Bjorholm Dahl. HyperLeaf2024 – a hyper- spectral imaging dataset for classification and regression of wheat leaves. In Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Work- shops (FGVC 11), 2024. 5
work page 2024
-
[25]
Diffcam: Data-driven saliency maps by capturing feature differences
Xingjian Li, Qiming Zhao, Neelesh Bisht, Mostofa Rafid Uddin, Jin Yu Kim, Bryan Zhang, and Min Xu. Diffcam: Data-driven saliency maps by capturing feature differences. In Proceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 10327–10337, 2025. 2, 5, 6, 7
work page 2025
-
[26]
Spectral–spatial classification of hyperspectral imagery with 3d convolutional neural network
Ying Li, Haokui Zhang, and Qiang Shen. Spectral–spatial classification of hyperspectral imagery with 3d convolutional neural network. Remote Sensing, 9(1):67, 2017. 2
work page 2017
-
[27]
Hsi-cnn: A novel convolution neural network for hyperspectral image
Yanan Luo, Jie Zou, Chengfei Yao, Xiaosong Zhao, Tao Li, and Gang Bai. Hsi-cnn: A novel convolution neural network for hyperspectral image. In 2018 International Conference on Audio, Language and Image Processing (ICALIP), pages 464–469. IEEE, 2018. 2
work page 2018
-
[28]
Eigen-cam: Class activation map using principal compo- nents
Mohammed Bany Muhammad and Mohammed Yeasin. Eigen-cam: Class activation map using principal compo- nents. In 2020 international joint conference on neural net- works (IJCNN), pages 1–7. IEEE, 2020. 2, 5
work page 2020
-
[29]
Daniel Omeiza, Skyler Speakman, Celia Cintas, and Kom- minist Weldermariam. Smooth grad-cam++: An en- hanced inference level visualization technique for deep convolutional neural network models. In Proceedings of the Intelligent Systems Conference (IntelliSys) , 2019. arXiv:1908.01224. 2
-
[30]
Carlyn, Samuel Stevens, Kaiya L
Dipanjyoti Paul, Arpita Chowdhury, Xinqi Xiong, Feng-Ju Chang, David E. Carlyn, Samuel Stevens, Kaiya L. Provost, Anuj Karpatne, Bryan Carstens, Daniel Rubenstein, Charles Stewart, Tanya Berger-Wolf, Yu Su, and Wei-Lun Chao. A simple interpretable transformer for fine-grained image clas- sification and analysis. arXiv preprint arXiv:2311.04157 ,
-
[31]
Rise: Random- ized input sampling for explanation of black-box models
Vitali Petsiuk, Abir Das, and Kate Saenko. Rise: Random- ized input sampling for explanation of black-box models. In British Machine Vision Conference (BMVC), 2018. 5
work page 2018
-
[32]
Bishwas Praveen and Vineetha Menon. Hyper-vit: A novel light-weighted visual transformer-based supervised classifi- cation framework for hyperspectral remote sensing applica- tions. In 2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHIS- PERS), pages 1–5. IEEE, 2022. 2
work page 2022
-
[33]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE in- ternational conference on computer vision , pages 618–626,
-
[34]
Ssa: Semantic structure aware inference for weakly pixel-wise dense predictions without cost
Yanpeng Sun and Zechao Li. Ssa: Semantic structure aware inference for weakly pixel-wise dense predictions without cost. arXiv preprint arXiv:2111.03392, 2021. 3, 5
-
[36]
Going deeper with im- age transformers
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herv´e J´egou. Going deeper with im- age transformers. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 32–42,
-
[37]
Distributed cross-channel hierar- chical aggregation for foundation models
Aristeidis Tsaris, Isaac Lyngaas, John Lagregren, Mohamed Wahib, Larry York, Prasanna Balaprakash, Dan Lu, Feiyi Wang, and Xiao Wang. Distributed cross-channel hierar- chical aggregation for foundation models. arXiv preprint arXiv:2506.21411, 2025. 8
-
[38]
Score-cam: Score-weighted visual explanations for convolutional neural networks
Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages 24–25, 2020. 2, 5
work page 2020
-
[39]
Hongjie Wang, Bhishma Dedhia, and Niraj K. Jha. Zero- tprune: Zero-shot token pruning through leveraging of the attention graph in pre-trained transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2024. 3
work page 2024
-
[40]
High perfor- mance model based image reconstruction
Xiao Wang, Amit Sabne, Sherman Kisner, Anand Raghu- nathan, Charles Bouman, and Samuel Midkiff. High perfor- mance model based image reconstruction. In Proceedings of the 21st ACM SIGPLAN Symposium on Principles and Prac- tice of Parallel Programming, New York, NY , USA, 2016. Association for Computing Machinery. 3
work page 2016
-
[41]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Chunyuan Li, Lei Hou, Hao Ma, Ming Sun, Nan Du Wang, Qizhe Wu, Yue Zhang, Lichen Shou, Lei Zhou, Hongyu Zhang, Fei Wu, Haifeng Wang, and Jin- gren Zhou. Efficient streaming language models with atten- tion sinks. arXiv preprint arXiv:2309.17453, 2023. 2, 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Visual instance-aware prompt tuning, 2025
Xi Xiao, Yunbei Zhang, Xingjian Li, Tianyang Wang, Xiao Wang, Yuxiang Wei, Jihun Hamm, and Min Xu. Visual instance-aware prompt tuning, 2025. 2
work page 2025
-
[43]
Visual varia- tional autoencoder prompt tuning, 2025
Xi Xiao, Yunbei Zhang, Yanshuh Li, Xingjian Li, Tianyang Wang, Jihun Hamm, Xiao Wang, and Min Xu. Visual varia- tional autoencoder prompt tuning, 2025. 2
work page 2025
-
[44]
Hsvit: Horizontally scalable vision transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, and Douglas Creighton. Hsvit: Horizontally scalable vision transformer. arXiv preprint arXiv:2404.05196, 2024. 2
-
[45]
Mengqi Xue, Qihan Huang, Haofei Zhang, Lechao Cheng, Jie Song, Minghui Wu, and Mingli Song. Protopformer: Concentrating on prototypical parts in vision transform- ers for interpretable image recognition. arXiv preprint arXiv:2208.10431, 2022. 5
-
[46]
Semi-active convolutional neural networks for hyperspectral image clas- 10 sification
Jing Yao, Xiangyong Cao, Danfeng Hong, Xin Wu, Deyu Meng, Jocelyn Chanussot, and Zongben Xu. Semi-active convolutional neural networks for hyperspectral image clas- 10 sification. IEEE Transactions on Geoscience and Remote Sensing, 60:1–15, 2022. 3
work page 2022
-
[47]
Jianping Zhang, Yizhan Huang, Weibin Wu, and Michael R. Lyu. Transferable adversarial attacks on vision transform- ers with token gradient regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2, 5
work page 2023
-
[48]
Xuemei Zhang, Boris A. Vinatzer, and Song Li. Hyperspec- tral imaging analysis for early detection of tomato bacterial leaf spot disease. Scientific Reports, 14:27666, 2024. 5
work page 2024
-
[49]
Deepvit: Towards deeper vision transformer
Daquan Zhou, Bingyi Kang, Xiaojie Jin, Linjie Yang, Xi- aochen Lian, Zihang Jiang, Qibin Hou, and Jiashi Feng. Deepvit: Towards deeper vision transformer. arXiv preprint arXiv:2103.11886, 2021. 7 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.