Enhancing Hallucination Detection via Future Context
Pith reviewed 2026-05-19 03:16 UTC · model grok-4.3
The pith
Sampling future contexts from LLMs reveals persistent hallucinations to improve detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that hallucinations tend to persist in model-generated text, so sampling future contexts supplies useful clues for detection; these clues integrate with various sampling-based methods and yield performance improvements on black-box generators.
What carries the argument
Sampling future contexts from the generator, which supplies persistent hallucination signals that serve as detection clues.
If this is right
- Existing sampling-based hallucination detection methods achieve higher accuracy when combined with future-context sampling.
- The approach applies directly to black-box models where internal states or probabilities are unavailable.
- Detection can occur by examining continuation samples rather than only the initial output segment.
Where Pith is reading between the lines
- The persistence of hallucinations suggests that checking early in a generation could limit error spread in longer outputs.
- The sampling idea might extend to detecting other forms of factual inconsistency beyond the paper's tested cases.
Load-bearing premise
Hallucinations tend to persist in future contexts generated by the model and supply reliable detection clues without the sampling process itself introducing substantial new errors or noise.
What would settle it
An experiment in which adding sampled future contexts produces no gain in detection accuracy over the original methods, or direct measurement showing that hallucinations frequently fail to persist in subsequent generations.
Figures








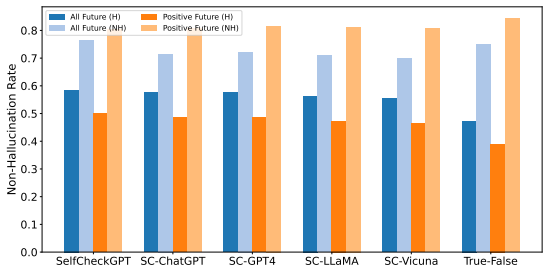




read the original abstract
Large Language Models (LLMs) are widely used to generate plausible text on online platforms, without revealing the generation process. As users increasingly encounter such black-box outputs, detecting hallucinations has become a critical challenge. To address this challenge, we focus on developing a hallucination detection framework for black-box generators. Motivated by the observation that hallucinations, once introduced, tend to persist, we sample future contexts. The sampled future contexts provide valuable clues for hallucination detection and can be effectively integrated with various sampling-based methods. We extensively demonstrate performance improvements across multiple methods using our proposed sampling approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hallucination detection framework for black-box LLMs. Motivated by the observation that hallucinations tend to persist once introduced, it samples future contexts from the generator and integrates these as additional signals into existing sampling-based detection methods. The central claim is that this future-context sampling yields consistent performance gains across multiple base detectors, demonstrated through extensive experiments.
Significance. If the persistence premise holds and the sampled continuations reliably surface detectable inconsistencies without introducing excessive noise, the method offers a lightweight, black-box-compatible enhancement to sampling-based hallucination detectors. This is practically relevant for deployed LLMs where internal states are inaccessible. The approach is empirical rather than axiomatic and does not claim parameter-free derivations or machine-checked proofs.
major comments (2)
- [Motivation and Section 3 (Approach)] The central premise that future contexts supply reliable detection clues because hallucinations 'tend to persist' is load-bearing for the entire contribution. However, the manuscript does not quantify the fraction of cases in which sampled continuations expose contradictions versus maintaining internal consistency around the erroneous fact. This is especially critical for purely black-box sampling, where the only signal is the model's own output distribution; a detector could then reinforce rather than flag the hallucination. A concrete breakdown (e.g., by hallucination type or model) is needed to substantiate the claim.
- [Abstract] Abstract and experimental sections: the claim of 'extensively demonstrate performance improvements across multiple methods' is asserted without reference to specific quantitative metrics, baselines, datasets, or statistical significance tests in the provided abstract. While the full manuscript presumably contains results, the absence of even summary numbers (e.g., F1 deltas, number of runs) in the high-level claim makes it difficult to evaluate effect size or robustness.
minor comments (1)
- [Section 3] Notation for the future-context sampling procedure could be clarified; it is not immediately obvious how the sampled tokens are aggregated into the detection score versus simply concatenated as additional input.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: [Motivation and Section 3 (Approach)] The central premise that future contexts supply reliable detection clues because hallucinations 'tend to persist' is load-bearing for the entire contribution. However, the manuscript does not quantify the fraction of cases in which sampled continuations expose contradictions versus maintaining internal consistency around the erroneous fact. This is especially critical for purely black-box sampling, where the only signal is the model's own output distribution; a detector could then reinforce rather than flag the hallucination. A concrete breakdown (e.g., by hallucination type or model) is needed to substantiate the claim.
Authors: We agree that quantifying the rate at which future contexts surface contradictions versus preserving erroneous consistency would strengthen the motivation section. In the revised manuscript we will add an analysis (new subsection in Section 3 or appendix) that manually inspects a representative sample of generations, broken down by hallucination type and model, reporting the observed fractions. Regarding the black-box reinforcement concern, our main experimental results already show that integrating the sampled future contexts consistently improves detection F1 across all tested base methods and datasets; this empirical outcome indicates that the additional context supplies net-positive signals rather than simply amplifying the original hallucination. revision: yes
-
Referee: [Abstract] Abstract and experimental sections: the claim of 'extensively demonstrate performance improvements across multiple methods' is asserted without reference to specific quantitative metrics, baselines, datasets, or statistical significance tests in the provided abstract. While the full manuscript presumably contains results, the absence of even summary numbers (e.g., F1 deltas, number of runs) in the high-level claim makes it difficult to evaluate effect size or robustness.
Authors: We accept that the abstract would be clearer with concise quantitative anchors. In the revised abstract we will insert a short summary sentence reporting the average F1 improvement range across the evaluated detectors, the number of base methods and datasets, and a note on statistical significance testing performed in the experiments. revision: yes
Circularity Check
No circularity: empirical sampling proposal is self-contained
full rationale
The paper proposes sampling future contexts to aid hallucination detection, motivated by the external observation that hallucinations tend to persist. No equations, fitted parameters, or derivations are presented that reduce the central claim to its own inputs by construction. The approach is integrated with existing sampling-based methods and validated through experiments, with no load-bearing self-citations, ansatzes, or uniqueness theorems invoked. The derivation chain remains independent of any self-referential loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Find- ings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore
The internal state of an LLM knows when it‘s lying. In Find- ings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore. Associa- tion for Computational Linguistics. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand...
work page 2023
-
[2]
In Ad- vances in Neural Information Processing Systems , volume 33, pages 1877–1901
Language models are few-shot learners. In Ad- vances in Neural Information Processing Systems , volume 33, pages 1877–1901. Curran Associates, Inc. Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sut- ton, Xuezhi Wang, and Denny Zhou
work page 1901
-
[3]
In ICML 2024 Workshop on In-Context Learning
Universal self-consistency for large language models. In ICML 2024 Workshop on In-Context Learning. Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing
work page 2024
-
[4]
Fact-checking the output of large language models via token-level uncertainty quantification. In Findings of the Association for Computational Linguistics: ACL 2024 , pages 9367– 9385, Bangkok, Thailand. Association for Computa- tional Linguistics. Aaron Grattafiori et al
work page 2024
-
[5]
The llama 3 herd of mod- els. Preprint, arXiv:2407.21783. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know. Preprint, arXiv:2207.05221. Aishwarya Kamath et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gemma 3 technical report. Preprint, arXiv:2503.19786. Potsawee Manakul, Adian Liusie, and Mark Gales
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
SelfCheckGPT: Zero-resource black-box hallucina- tion detection for generative large language models. In Proceedings of the 2023 Conference on Empiri- cal Methods in Natural Language Processing , pages 9004–9017, Singapore. Association for Computa- tional Linguistics. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, L...
work page 2023
-
[9]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, Singa- pore. Association for Computational Linguistics. Niels Mündler, Jingxuan He, Slobodan Jenko, and Mar- tin Vechev
work page 2023
-
[10]
Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. Preprint, arXiv:2305.15852. OpenAI
-
[11]
Introducing chatgpt. Accessed: 2025- 04-08. OpenAI, Josh Achiam, et al
work page 2025
-
[12]
Gpt-4 technical report. Preprint, arXiv:2303.08774. Pranab Sahoo, Prabhash Meharia, Akash Ghosh, Sri- parna Saha, Vinija Jain, and Aman Chadha
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A comprehensive survey of hallucination in large lan- guage, image, video and audio foundation models. In Findings of the Association for Computational Linguistics: EMNLP 2024 , pages 11709–11724, Mi- ami, Florida, USA. Association for Computational Linguistics. Yixiao Song, Yekyung Kim, and Mohit Iyyer
work page 2024
-
[14]
VeriScore: Evaluating the factuality of verifiable claims in long-form text generation. In Findings of the Association for Computational Linguistics: EMNLP 2024 , pages 9447–9474, Miami, Florida, USA. Association for Computational Linguistics. Hugo Touvron et al
work page 2024
-
[15]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foun- dation and fine-tuned chat models. Preprint, arXiv:2307.09288. Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jian- shu Chen, and Dong Yu
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation. Preprint, arXiv:2307.03987. Xinglin Wang, Yiwei Li, Shaoxiong Feng, Peiwen Yuan, Boyuan Pan, Heda Wang, Yao Hu, and Kan Li
-
[17]
Qwen2.5 technical report. Preprint, arXiv:2412.15115. Yakir Yehuda, Itzik Malkiel, Oren Barkan, Jonathan Weill, Royi Ronen, and Noam Koenigstein
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Association for Computational Linguistics
Do large language models know what they don‘t know? In Findings of the Association for Computational Lin- guistics: ACL 2023 , pages 8653–8665, Toronto, Canada. Association for Computational Linguistics. Jiaxin Zhang, Zhuohang Li, Kamalika Das, Bradley Ma- lin, and Sricharan Kumar. 2023a. SAC 3: Reliable hallucination detection in black-box language model...
work page 2023
-
[19]
How language model hallucinations can snowball. In Proceedings of the 41st International Conference on Machine Learning , volume 235 of Proceedings of Machine Learning Research, pages 59670–59684. PMLR. Tianhang Zhang, Lin Qiu, Qipeng Guo, Cheng Deng, Yue Zhang, Zheng Zhang, Chenghu Zhou, Xinbing Wang, and Luoyi Fu. 2023b. Enhancing uncertainty- based hal...
work page 2023
-
[20]
Future context is optional and may be selectively used depending on the experiment. The goal of this prompt is to intuitively provide the model with clues, enabling it to determine whether the target sentence is hallucinatory based on its in- ternal knowledge. This prompt forms the core of our DIRECT baseline. We next describe the prompt design used in SE...
work page 1990
-
[21]
IS (Insufficient Samples): Percentage of cases sampling fewer than half the number of requested sentences. HR (High Redundancy): Percentage of cases where more than 50% of sampled sentences are duplicates. Dataset V ERISCORE VERISCORE+f True-False 88.6 91.7 Table 9: Hallucination detection performance (AUROC) of VERI SCORE on True-False. lects the final a...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.