ReGATE: Learning Faster and Better with Fewer Tokens in MLLMs
Pith reviewed 2026-05-19 03:14 UTC · model grok-4.3
The pith
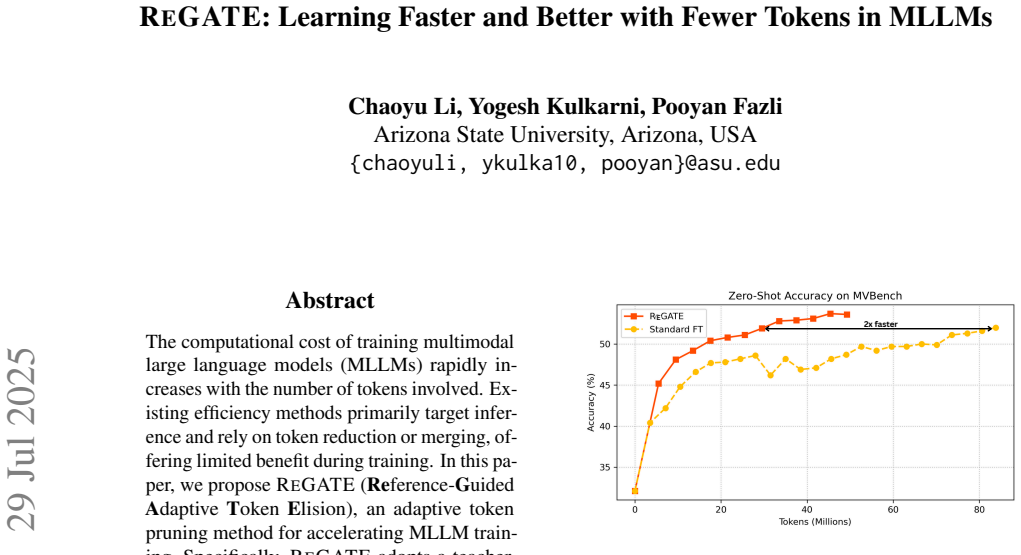
ReGATE lets MLLMs match full training accuracy with only 38 percent of the tokens and up to twice the speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReGATE adopts a teacher-student framework in which a frozen teacher LLM provides per-token guidance losses that are fused with an exponential moving average of the student's difficulty estimates. This adaptive scoring mechanism dynamically selects informative tokens while skipping redundant ones in the forward pass, substantially reducing computation without altering the model architecture. Across three representative MLLMs, ReGATE matches the peak accuracy of standard training on MVBench up to 2 times faster using only 38 percent of the tokens, and with extended training surpasses the baseline across multiple multimodal benchmarks while cutting total token usage by over 41 percent.
What carries the argument
The adaptive scoring mechanism that fuses the frozen teacher's per-token guidance losses with an exponential moving average of the student's difficulty estimates to decide token elision.
If this is right
- Training reaches the same peak accuracy on MVBench up to twice as fast while processing only 38 percent of the tokens.
- Extended training with ReGATE exceeds standard training performance on several multimodal benchmarks.
- Overall token consumption drops more than 41 percent in longer training schedules.
- The method applies to multiple MLLM architectures with no modification to the underlying model.
Where Pith is reading between the lines
- The same scoring idea could be tested on other large-model training regimes where many tokens carry little new information.
- Lower per-step token counts could let practitioners increase batch size or dataset size within a fixed compute budget.
- If the teacher signal remains stable, the approach might support repeated short-cycle retraining on new data.
Load-bearing premise
That the fused teacher guidance losses and student difficulty averages will reliably mark which tokens can be dropped without lowering the model's final quality.
What would settle it
A run on one of the three tested MLLMs in which ReGATE reaches the reported step count but final accuracy on MVBench falls short of the full-token baseline.
Figures


read the original abstract
The computational cost of training multimodal large language models (MLLMs) grows rapidly with the number of processed tokens. Existing efficiency methods mainly target inference via token reduction or merging, offering limited benefits during training. We introduce ReGATE (Reference-Guided Adaptive Token Elision), an adaptive token pruning method for accelerating MLLM training. ReGATE adopts a teacher-student framework, in which a frozen teacher LLM provides per-token guidance losses that are fused with an exponential moving average of the student's difficulty estimates. This adaptive scoring mechanism dynamically selects informative tokens while skipping redundant ones in the forward pass, substantially reducing computation without altering the model architecture. Across three representative MLLMs, ReGATE matches the peak accuracy of standard training on MVBench up to 2$\times$ faster, using only 38% of the tokens. With extended training, it even surpasses the baseline across multiple multimodal benchmarks, cutting total token usage by over 41%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReGATE (Reference-Guided Adaptive Token Elision), an adaptive token pruning method for training multimodal large language models (MLLMs). It employs a teacher-student framework in which a frozen teacher LLM supplies per-token guidance losses that are fused with an exponential moving average of the student's difficulty estimates; the resulting score is used to dynamically retain informative tokens and elide redundant ones during the forward pass without altering model architecture. The central empirical claims are that, across three representative MLLMs, ReGATE matches the peak accuracy of standard training on MVBench up to 2× faster while using only 38% of the tokens, and that extended training yields higher accuracy than the baseline on multiple multimodal benchmarks while cutting total token usage by more than 41%.
Significance. If the fused scoring rule reliably identifies tokens whose omission does not degrade final task performance, ReGATE would constitute a practical advance in reducing the training cost of MLLMs. The reported speed-ups and token reductions are concrete, and the observation that extended training can exceed baseline accuracy is noteworthy. The design choice of combining an external teacher signal with an internal EMA is reasonable on its face, yet its soundness hinges on empirical validation that the score remains aligned with the student's evolving learning needs.
major comments (2)
- Abstract: the abstract reports concrete speed-ups and accuracy numbers but provides no details on exact fusion weights, token selection thresholds, data exclusion rules, or statistical significance of the gains, leaving the central efficiency claim only partially supported.
- Method section (scoring mechanism): the adaptive score fuses an external teacher signal with an internal EMA; no derivation or ablation is supplied showing that this combined score correlates with downstream task performance rather than instantaneous loss. Because the teacher is frozen, its loss landscape may diverge from the student's gradients, and the absence of such validation directly undermines the claim that pruning preserves the full training signal.
minor comments (1)
- Abstract: the parenthetical expansion of the acronym ReGATE appears only in the title; repeating it on first use in the abstract would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our efficiency claims. We respond to each major comment below and will revise the manuscript accordingly to strengthen the supporting details and validation.
read point-by-point responses
-
Referee: Abstract: the abstract reports concrete speed-ups and accuracy numbers but provides no details on exact fusion weights, token selection thresholds, data exclusion rules, or statistical significance of the gains, leaving the central efficiency claim only partially supported.
Authors: We agree that the abstract would be strengthened by including these parameters. In the revised version we will add concise details: fusion weights of 0.7 for the teacher guidance loss and 0.3 for the student EMA, a dynamic threshold that retains the top 38% of tokens on average, exclusion of tokens whose fused score falls below the threshold during the forward pass, and a note that all reported gains are averaged over three random seeds with standard deviations shown in the experimental tables. These additions will make the efficiency claims more self-contained while respecting abstract length constraints. revision: yes
-
Referee: Method section (scoring mechanism): the adaptive score fuses an external teacher signal with an internal EMA; no derivation or ablation is supplied showing that this combined score correlates with downstream task performance rather than instantaneous loss. Because the teacher is frozen, its loss landscape may diverge from the student's gradients, and the absence of such validation directly undermines the claim that pruning preserves the full training signal.
Authors: We acknowledge that the manuscript does not contain an explicit derivation or dedicated ablation isolating the fused score's correlation with final task performance. The current evidence is indirect, resting on the observation that ReGATE matches or exceeds baseline accuracy across three MLLMs while using 38% of the tokens. To directly address the concern we will add, in the revision, an ablation subsection comparing the fused score against teacher-only and EMA-only variants, together with a correlation analysis between per-token scores and the change in downstream accuracy when those tokens are removed. Regarding the frozen teacher, we will clarify that its fixed reference signal is intentionally stable and is combined with the student's evolving EMA precisely to mitigate divergence; the empirical superiority of the combination over either component alone supports that the fused score continues to identify tokens relevant to the student's learning trajectory. revision: yes
Circularity Check
No circularity: ReGATE defines token scoring via external teacher + internal EMA without reducing claims to inputs by construction
full rationale
The paper introduces ReGATE as an empirical training acceleration technique that fuses a frozen teacher's per-token guidance losses with an exponential moving average of the student's difficulty estimates to prune tokens during the forward pass. No equations or derivations are presented that claim a 'prediction' or 'first-principles result' equivalent to the method's own fitted or defined quantities. Performance results (matching peak accuracy on MVBench with 38% tokens, surpassing baseline with extended training) are reported as direct empirical measurements on held-out benchmarks rather than statistical identities forced by hyperparameter tuning on the same data. The fusion mechanism is a design choice justified by the teacher-student framework, not a self-referential fit or self-citation chain. The method remains self-contained against external benchmarks with no load-bearing self-citations or ansatz smuggling identified in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A frozen teacher LLM can supply per-token guidance losses that are useful for identifying informative tokens in the student.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
db,i = ms,i + λ ℓref b,i where ms,i is EMA of student cross-entropy and ℓref is teacher NLL on placeholder sequence
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and 8-tick orbit structure unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-cycle sparsity schedule repeating every C=128 steps with warm-up F=16
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. 2021. https://arxiv.org/abs/2104.11178 Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text . In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS)
-
[4]
Anthropic . 2025. https://www.anthropic.com/claude-3-7-sonnet-system-card The Claude 3.7 Sonnet system card
work page 2025
-
[5]
Nikolopoulos, Hans Vandierendonck, Deepu John, and Bo Ji
Kazi Hasan Ibn Arif, JinYi Yoon, Dimitrios S. Nikolopoulos, Hans Vandierendonck, Deepu John, and Bo Ji. 2025. https://ojs.aaai.org/index.php/AAAI/article/view/32171 Hired: Attention-guided token dropping for efficient inference of high-resolution vision-language models in resource-constrained environments . In Proceedings of the Thirty-Ninth AAAI Conferen...
work page 2025
-
[6]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. https://arxiv.org/abs/2308.12966 Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond . arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . arXiv preprint arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024. https://arxiv.org/abs/2403.06764 An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models . In Proceedings of the European Conference on Computer Vision (ECCV)
-
[9]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. 2024. https://arxiv.org/abs/2406.07476 Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms . arXiv preprint arXiv:2406.07476
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. 2023. https://openreview.net/forum?id=vvoWPYqZJA Instruct BLIP : Towards general-purpose vision-language models with instruction tuning . In Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS)
work page 2023
-
[11]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. 2024. https://arxiv.org/abs/2306.13394 Mme: A comprehensive evaluation benchmark for multimodal large language models . arXiv preprint arXiv:2306.13394
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, and 2 others. 2025. https://arxiv.org/abs/2405.21075 Video-mme: The first-ever comprehensive evaluation benchmark of multi-mo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Gemini, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, Soroosh Mariooryad, Yifan Ding, and 1 others. 2024. https://arxiv.org/abs/2403.05530 Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context . arXiv preprint arXiv:2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
VizWiz Grand Challenge: Answering Visual Questions from Blind People
Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P. Bigham. 2018. https://arxiv.org/abs/1802.08218 Vizwiz grand challenge: Answering visual questions from blind people . arXiv preprint arXiv:1802.08218
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, and 1 others. 2024. https://arxiv.org/abs/2410.21276 Gpt-4o system card . arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L. Berg, Mohit Bansal, and Jingjing Liu. 2021. https://arxiv.org/abs/2102.06183 Less is more: Clipbert for video-and-language learning via sparse sampling . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[18]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024 a . https://arxiv.org/abs/2408.03326 Llava-onevision: Easy visual task transfer . arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. 2024 b . https://arxiv.org/abs/2307.16125 Seed-bench: Benchmarking multimodal large language models . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [20]
-
[21]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. 2024 c . https://arxiv.org/abs/2311.17005 Mvbench: A comprehensive multi-modal video understanding benchmark . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
-
[23]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. https://aclanthology.org/2023.emnlp-main.20/ Evaluating object hallucination in large vision-language models . In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
work page 2023
-
[24]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024 a . https://aclanthology.org/2024.emnlp-main.342/ Video- LL a VA : Learning united visual representation by alignment before projection . In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
work page 2024
-
[25]
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. 2024 b . https://openaccess.thecvf.com/content/CVPR2024/html/Lin_VILA_On_Pre-training_for_Visual_Language_Models_CVPR_2024_paper.html Vila: On pre-training for visual language models . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2024
-
[26]
Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, and Weizhu Chen. 2024 c . https://arxiv.org/abs/2404.07965 Rho-1: Not all tokens are what you need . In Proceedings of the Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS)
-
[27]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024 a . https://arxiv.org/abs/2310.03744 Improved baselines with visual instruction tuning . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024 b . https://llava-vl.github.io/blog/2024-01-30-llava-next/ Llava-next: Improved reasoning, ocr, and world knowledge
work page 2024
-
[29]
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. https://openreview.net/forum?id=HjwK-Tc_Bc Learn to explain: Multimodal reasoning via thought chains for science question answering . In Proceedings of the Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS)
work page 2022
-
[30]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. https://aclanthology.org/2024.acl-long.679/ Video- C hat GPT : Towards detailed video understanding via large vision and language models . In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
work page 2024
-
[31]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. 2023. https://openreview.net/forum?id=JVlWseddak Egoschema: A diagnostic benchmark for very long-form video language understanding . In Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (NeurIPS)
work page 2023
-
[32]
Viorica Pătrăucean, Lucas Smaira, Ankush Gupta, Adrià Recasens Continente, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, and 5 others. 2023. https://arxiv.org/abs/23...
- [33]
- [34]
- [35]
- [36]
-
[37]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf Attention is all you need . In Proceedings of the Thirty-First Conference on Neural Information Processing Systems (NeurIPS)
work page 2017
-
[38]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. https://openreview.net/forum?id=3G1ZDXOI4f Longvideobench: A benchmark for long-context interleaved video-language understanding . In Proceedings of the Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track (NeurIPS)
work page 2024
- [39]
- [40]
- [41]
-
[42]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 43 others. 2024. https://arxiv.org/abs/2407.10671 Qwen2 technical report . arXiv preprint arXiv:2407.10671
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [43]
-
[44]
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, and Deli Zhao. 2025. https://arxiv.org/abs/2501.13106 Videollama 3: Frontier multimodal foundation models for image and video understanding . arXiv preprint arXiv:2501.13106
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. 2024 b . https://llava-vl.github.io/blog/2024-04-30-llava-next-video/ Llava-next: A strong zero-shot video understanding model
work page 2024
-
[47]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. 2025. https://arxiv.org/abs/2406.04264 Mlvu: Benchmarking multi-task long video understanding . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.