ChatENV: An Interactive Vision-Language Model for Sensor-Guided Environmental Monitoring and Scenario Simulation
Pith reviewed 2026-05-18 23:10 UTC · model grok-4.3
The pith
ChatENV integrates satellite image pairs with real sensor readings such as temperature and pollution to support interactive what-if environmental reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
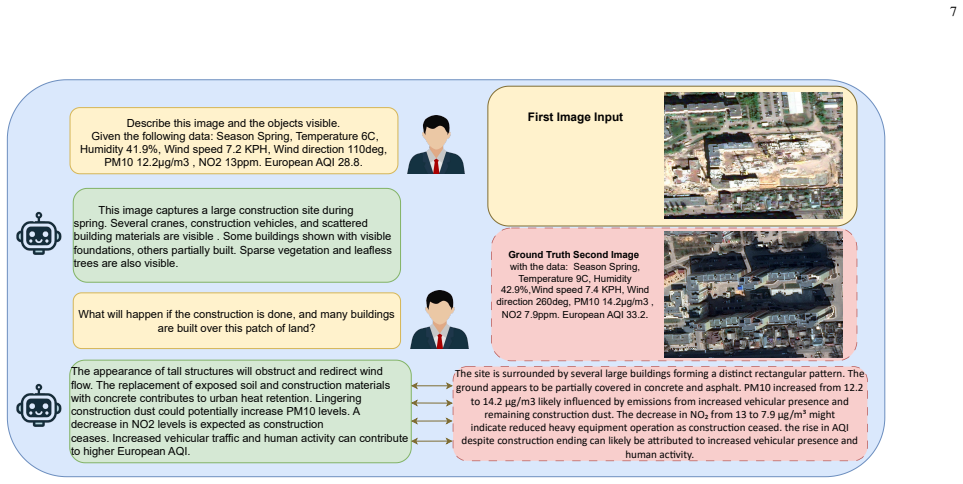
By creating a large collection of temporal satellite image pairs enriched with sensor metadata and fine-tuning Qwen-2.5-VL on diverse annotations, ChatENV enables accurate temporal reasoning and interactive what-if scenario analysis that rivals or exceeds existing temporal models.
What carries the argument
Joint reasoning over satellite image pairs and real-world sensor metadata (temperature, PM10, CO) inside a chat interface produced by LoRA fine-tuning on the annotated dataset.
If this is right
- Environmental monitoring systems can move beyond single-image captioning to causal, sensor-aware change detection.
- Users gain the ability to run interactive scenario simulations for climate resilience and urban planning.
- Performance on temporal reasoning reaches BERTF1 of 0.902 while supporting analysis across 197 countries.
- The same dataset and training recipe can be applied to new sensor streams or land-use classes.
Where Pith is reading between the lines
- The approach could be extended to real-time sensor feeds for live forecasting of environmental events.
- Similar sensor-grounded models might improve decision support in domains such as agriculture or disaster response.
- Interactive interfaces of this kind may reduce reliance on expert interpreters for routine monitoring tasks.
Load-bearing premise
Annotations produced by GPT-4o and Gemini 2.0 supply accurate, unbiased, and stylistically diverse labels that do not introduce systematic errors into the training data or evaluation.
What would settle it
A held-out set of temporal image pairs where model answers on what-if scenarios change dramatically when the accompanying sensor values are removed or altered.
Figures




read the original abstract
Understanding environmental changes from remote sensing imagery is vital for climate resilience, urban planning, and ecosystem monitoring. Yet, current vision language models (VLMs) overlook causal signals from environmental sensors, rely on single-source captions prone to stylistic bias, and lack interactive scenario-based reasoning. We present ChatENV, the first interactive VLM that jointly reasons over satellite image pairs and real-world sensor data. Our framework: (i) creates a 177k-image dataset forming 152k temporal pairs across 62 land-use classes in 197 countries with rich sensor metadata (e.g., temperature, PM10, CO); (ii) annotates data using GPT4o and Gemini 2.0 for stylistic and semantic diversity; and (iii) fine-tunes Qwen-2.5-VL using efficient Low-Rank Adaptation (LoRA) adapters for chat purposes. ChatENV achieves strong performance in temporal and "what-if" reasoning (e.g., BERTF1 0.902) and rivals or outperforms state-of-the-art temporal models, while supporting interactive scenario-based analysis. This positions ChatENV as a powerful tool for grounded, sensor-aware environmental monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChatENV, the first interactive vision-language model that jointly reasons over satellite image pairs and real-world sensor data (e.g., temperature, PM10, CO) for environmental monitoring and scenario simulation. It describes constructing a 177k-image dataset forming 152k temporal pairs across 62 land-use classes in 197 countries, annotating the pairs with GPT-4o and Gemini 2.0 for stylistic and semantic diversity, and fine-tuning Qwen-2.5-VL via LoRA adapters. The central claim is strong performance in temporal and 'what-if' reasoning (BERTF1 of 0.902) that rivals or outperforms state-of-the-art temporal models while enabling interactive analysis.
Significance. If the performance claims hold after proper validation, the integration of sensor metadata with VLMs for grounded temporal and counterfactual reasoning would represent a useful advance for applications in climate resilience, urban planning, and ecosystem monitoring. The efficient LoRA-based adaptation and emphasis on interactivity are practical strengths. However, the absence of evaluation details and annotation validation substantially weakens the current assessment of significance.
major comments (2)
- [Abstract] Abstract: The headline result (BERTF1 0.902, rivaling SOTA temporal models) is presented without any information on evaluation splits, baseline comparisons, error bars, or controls for data leakage across the 152k temporal pairs. This information is required to substantiate the central performance claim.
- [Dataset construction and annotation] Dataset construction and annotation: The 152k temporal pairs are annotated exclusively by GPT-4o and Gemini 2.0 'for stylistic and semantic diversity,' yet the manuscript reports no human validation, inter-annotator agreement, or error analysis on temporal/sensor labels. Because these LLM-generated labels serve as ground truth for both training and the reported BERTF1 metric, any systematic misalignment with actual land-use change or sensor correlations would render the performance numbers unreliable.
minor comments (2)
- Clarify the precise relationship between the stated 177k images and 152k temporal pairs (e.g., how many pairs are formed per image or whether some images are used only once).
- The abstract lists LoRA rank and scaling factor as free parameters; state the specific values used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our evaluation protocol and the reliability of our dataset annotations. We address each major comment below and have revised the manuscript to incorporate additional details and validation steps.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result (BERTF1 0.902, rivaling SOTA temporal models) is presented without any information on evaluation splits, baseline comparisons, error bars, or controls for data leakage across the 152k temporal pairs. This information is required to substantiate the central performance claim.
Authors: We agree that the abstract would benefit from more explicit context on the evaluation setup to support the reported performance. In the revised manuscript, we have updated the abstract to briefly reference the use of temporally separated train/validation/test splits designed to avoid leakage across pairs, direct comparisons against specific state-of-the-art temporal reasoning baselines, and the inclusion of error bars derived from multiple experimental runs. Full experimental details, including split statistics and baseline tables, appear in the Experiments section of the revision. revision: yes
-
Referee: [Dataset construction and annotation] Dataset construction and annotation: The 152k temporal pairs are annotated exclusively by GPT-4o and Gemini 2.0 'for stylistic and semantic diversity,' yet the manuscript reports no human validation, inter-annotator agreement, or error analysis on temporal/sensor labels. Because these LLM-generated labels serve as ground truth for both training and the reported BERTF1 metric, any systematic misalignment with actual land-use change or sensor correlations would render the performance numbers unreliable.
Authors: We acknowledge the importance of validating the LLM-generated annotations that serve as training and evaluation targets. In the revised manuscript, we have added a new subsection under Dataset Construction that reports inter-annotator agreement between GPT-4o and Gemini 2.0 outputs on a sampled subset, along with a human validation study conducted on 500 randomly selected pairs. This study measures expert agreement on the accuracy of described land-use changes and sensor correlations. We also discuss the rationale for multi-LLM annotation to promote diversity while noting remaining limitations of automated labeling. The annotation prompts have been moved to the appendix for transparency. revision: yes
Circularity Check
No significant circularity; evaluation uses external metric on held-out data
full rationale
The paper's central claims rest on fine-tuning Qwen-2.5-VL with LoRA on a dataset of 152k temporal pairs whose captions were produced by external models (GPT-4o and Gemini 2.0) and then measuring performance with the independent BERTF1 metric on a held-out set. No equations, derivations, or self-citations are shown that reduce the reported BERTF1 score or scenario-reasoning results to quantities defined by the authors' own fitted parameters or prior self-referential theorems. The annotation step introduces a potential validity concern but does not create a self-definitional or fitted-input loop within the derivation chain itself. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank and scaling factor
axioms (1)
- domain assumption GPT4o and Gemini 2.0 annotations produce stylistically and semantically diverse yet accurate captions for satellite images
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves strong performance in temporal and 'what-if' reasoning (e.g., BERTF1 0.902)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Landsat continuity: Issues and opportunities for land cover monitoring,
M. A. Wulder, J. G. Masek, W. B. Cohen, T. R. Loveland, and C. E. Woodcock, “Landsat continuity: Issues and opportunities for land cover monitoring,” Remote Sensing of Environment, vol. 122, pp. 84–91, 2012
work page 2012
-
[2]
C. Corradino, G. Ganci, A. Cappello, G. Bilotta, A. Hérault, and C. Del Negro, “Mapping recent lava flows at mount etna using mul- tispectral sentinel-2 images and machine learning techniques,” Remote Sensing, vol. 11, no. 16, p. 1916, 2019
work page 1916
-
[3]
Change-agent: Towards interactive comprehensive remote sensing change interpretation and analysis,
C. Liu, K. Chen, H. Zhang, Z. Qi, Z. Zou, and Z. Shi, “Change-agent: Towards interactive comprehensive remote sensing change interpretation and analysis,” IEEE Transactions on Geoscience and Remote Sensing , 2024
work page 2024
-
[4]
Z. Zhang, H. Shen, T. Zhao, B. Chen, Z. Guan, Y . Wang, X. Jia, Y . Cai, Y . Shang, and J. Yin, “Georsmllm: A multimodal large language model for vision-language tasks in geoscience and remote sensing,” 2025. [Online]. Available: https://arxiv.org/abs/2503.12490
-
[5]
Skyscript: A large and semantically diverse vision-language dataset for remote sens- ing,
Z. Wang, R. Prabha, T. Huang, J. Wu, and R. Rajagopal, “Skyscript: A large and semantically diverse vision-language dataset for remote sens- ing,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 38, no. 6, 2024, pp. 5805–5813
work page 2024
-
[7]
Rsgpt: A remote sensing vision language model and benchmark,
Y . Hu, J. Yuan, C. Wen, X. Lu, Y . Liu, and X. Li, “Rsgpt: A remote sensing vision language model and benchmark,” ISPRS Journal of Photogrammetry and Remote Sensing , vol. 224, pp. 272–286, 2025
work page 2025
-
[8]
Exploring models and data for remote sensing image caption generation,
X. Lu, B. Wang, X. Zheng, and X. Li, “Exploring models and data for remote sensing image caption generation,” IEEE Transactions on Geoscience and Remote Sensing , vol. 56, no. 4, pp. 2183–2195, 2017
work page 2017
-
[9]
Nwpu- captions dataset and mlca-net for remote sensing image captioning,
Q. Cheng, H. Huang, Y . Xu, Y . Zhou, H. Li, and Z. Wang, “Nwpu- captions dataset and mlca-net for remote sensing image captioning,” IEEE Transactions on Geoscience and Remote Sensing , vol. 60, pp. 1– 13, 2022
work page 2022
-
[10]
Rsvqa: Visual question answering for remote sensing data,
S. Lobry, D. Marcos, J. Murray, and D. Tuia, “Rsvqa: Visual question answering for remote sensing data,” IEEE Transactions on Geoscience and Remote Sensing , vol. 59, no. 12, pp. 10 129–10 141, 2021
work page 2021
-
[11]
Change detection meets visual question answering,
Z. Yuan, L. Mou, Z. Xiong, and X. X. Zhu, “Change detection meets visual question answering,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022
work page 2022
-
[12]
H. Chen and Z. Shi, “A spatial-temporal attention-based method and a new dataset for remote sensing image change detection,” Remote Sensing, vol. 12, no. 10, p. 1662, 2020
work page 2020
-
[13]
C. Liu, R. Zhao, H. Chen, Z. Zou, and Z. Shi, “Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–20, 2022
work page 2022
-
[14]
S. Dong, L. Wang, B. Du, and M. Meng, “Changeclip: Remote sensing change detection with multimodal vision-language representation learn- ing,” ISPRS Journal of Photogrammetry and Remote Sensing , vol. 208, pp. 53–69, 2024
work page 2024
-
[15]
The multi-temporal urban development spacenet dataset,
A. Van Etten, D. Hogan, J. M. Manso, J. Shermeyer, N. Weir, and R. Lewis, “The multi-temporal urban development spacenet dataset,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6398–6407
work page 2021
-
[16]
P. Agrawal, S. Antoniak, E. B. Hanna, B. Bout, D. Chaplot, J. Chudnovsky, D. Costa, B. D. Monicault, S. Garg, T. Gervet, S. Ghosh, A. Héliou, P. Jacob, A. Q. Jiang, K. Khandelwal, T. Lacroix, G. Lample, D. L. Casas, T. Lavril, T. L. Scao, A. Lo, W. Marshall, L. Martin, A. Mensch, P. Muddireddy, V . Nemychnikova, M. Pellat, P. V . Platen, N. Raghuraman, B....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Deepseek-vl: Towards real-world vision-language understanding,
H. Lu, W. Liu, B. Zhang, B. Wang, K. Dong, B. Liu, J. Sun, T. Ren, Z. Li, H. Yang, Y . Sun, C. Deng, H. Xu, Z. Xie, and C. Ruan, “Deepseek-vl: Towards real-world vision-language understanding,”
-
[18]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
[Online]. Available: https://arxiv.org/abs/2403.05525
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-pro: Unified multimodal understanding and generation with data and model scaling,” arXiv preprint arXiv:2501.17811 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chenet al., “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture- of-loras,” arXiv preprint arXiv:2503.01743 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al. , “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Y . Bazi, L. Bashmal, M. M. Al Rahhal, R. Ricci, and F. Melgani, “Rs- llava: A large vision-language model for joint captioning and question answering in remote sensing imagery,” Remote Sensing, vol. 16, no. 9, p. 1477, 2024
work page 2024
-
[23]
Y . Bazi, L. Bashmal, M. M. Al Rahhal, E. Ricci, and F. Melgani, “Rs- llava: A large vision-language model for joint captioning and question answering in remote sensing imagery,” Remote Sensing, vol. 16, no. 9, p. 1477, 2024
work page 2024
-
[24]
W. Zhang, M. Cai, T. Zhang, Y . Zhuang, and X. Mao, “Earthgpt: A universal multi-modal large language model for multi-sensor image comprehension in remote sensing,” IEEE Transactions on Geoscience and Remote Sensing , vol. 62, pp. 1–11, 2024
work page 2024
-
[25]
Remoteclip: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024. [Online]. Available: https: //doi.org/10.1109/TGRS.2024.3390838
-
[26]
Geochat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. S. Danish, M. Naseer, A. Das, S. Khan, and F. S. Khan, “Geochat: Grounded large vision-language model for remote sensing,” The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[28]
Available: https://arxiv.org/abs/2410.19552
[Online]. Available: https://arxiv.org/abs/2410.19552
-
[29]
Learning repre- sentations of satellite images from metadata supervision,
J. Bourcier, G. Dashyan, K. Alahari, and J. Chanussot, “Learning repre- sentations of satellite images from metadata supervision,” inProceedings of the European Conference on Computer Vision (ECCV) , 2024
work page 2024
-
[30]
S. Du, S. Tang, W. Wang, X. Li, and R. Guo, “Tree-gpt: Modular large language model expert system for forest remote sensing image un- derstanding and interactive analysis,” arXiv preprint arXiv:2310.04698 , 2023
-
[31]
Teochat: A large vision-language assistant for temporal earth observation data,
J. A. Irvin, E. R. Liu, J. C. Chen, I. Dormoy, J. Kim, S. Khanna, Z. Zheng, and S. Ermon, “Teochat: A large vision-language assistant for temporal earth observation data,” arXiv preprint arXiv:2410.06234 , 2024
-
[32]
G. Christie, N. Fendley, J. Wilson, and R. Mukherjee, “Functional map of the world,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 6172–6180
work page 2018
-
[33]
Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery,
Y . Cong, S. Khanna, C. Meng, P. Liu, E. Rozi, Y . He, M. Burke, D. Lo- bell, and S. Ermon, “Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery,” Advances in Neural Information Processing Systems, vol. 35, pp. 197–211, 2022
work page 2022
-
[34]
Visual Crossing, “Weather data documentation,” https://www. visualcrossing.com/documentation/, n.d., accessed: 2025-04-05
work page 2025
-
[35]
Air quality api documentation,
Open-Meteo, “Air quality api documentation,” https://open-meteo.com/ en/docs/air-quality-api, n.d., accessed: 2025-04-05
work page 2025
-
[36]
OpenAQ, “Openaq api documentation,” https://docs.openaq.org/docs, n.d., accessed: 2025-04-05
work page 2025
-
[37]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Llava- next: Next-generation large vision-language models with decoupled multimodal pre-training,
H. Liu, Z. Wu, C. Li, J. Yang, L. Li, Z. Huang, and J. Gao, “Llava- next: Next-generation large vision-language models with decoupled multimodal pre-training,” 2024
work page 2024
-
[39]
Video-LLaV A: Learning united visual representation by alignment before projection,
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-LLaV A: Learning united visual representation by alignment before projection,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association 9 for Computational Linguistics, No...
work page 2024
-
[40]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations , 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[41]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out , 2004, pp. 74–81
work page 2004
-
[42]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , 2019, pp. 3982– 3992
work page 2019
-
[43]
Bertscore: Evaluating text generation with bert,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,” in International Conference on Learning Representations, 2020
work page 2020
-
[44]
Comet: A neural framework for mt evaluation,
R. Rei, A. Farinha, A. Lavie, and A. F. T. Martins, “Comet: A neural framework for mt evaluation,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , 2020, pp. 2685– 2702. Hosam Elgendy is currently a Research Asso- ciate in the Machine Learning department at Mo- hamed bin Zayed University of Artificial Intelligence...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.