WebMall -- A Multi-Shop Benchmark for Evaluating Web Agents
Pith reviewed 2026-05-18 22:26 UTC · model grok-4.3
The pith
WebMall introduces the first offline benchmark simulating multiple shops to test web agents on complex comparison shopping tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
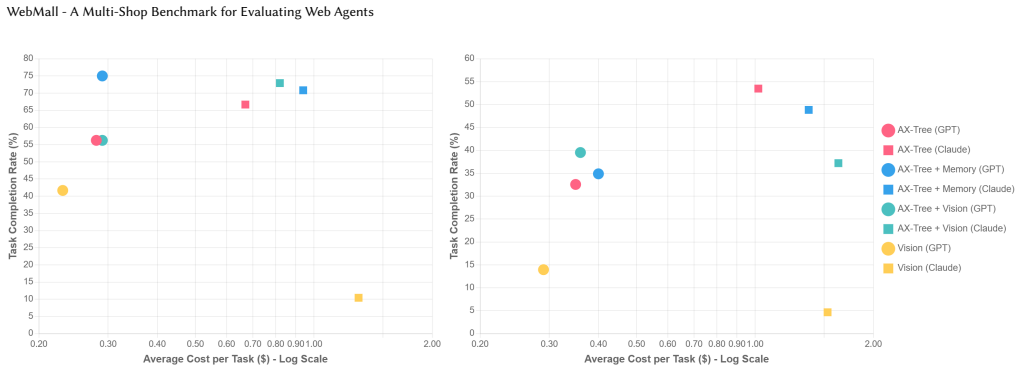
WebMall consists of four simulated shops populated with product data extracted from the web. The tasks range from specific product searches and price comparisons to advanced searches for complementary or substitute products, as well as checkout processes. When validated using eight agents that differ in observation space, availability of short-term memory, and the employed language model, the best-performing agents achieve task completion rates below 65 percent in the cheapest product search and vague product search categories.
What carries the argument
The WebMall benchmark, a set of four simulated shops and a suite of comparison-shopping tasks that force agents to retrieve and compare information across heterogeneous sources.
If this is right
- Agents must develop better strategies for switching between shops and comparing results rather than treating each shop in isolation.
- Reproducible offline environments become feasible for testing long sequences that include search, comparison, and checkout.
- Low completion rates in the hardest categories point to specific weaknesses in current observation and memory mechanisms.
- The benchmark supplies a fixed testbed that can be used to measure incremental gains as new agent designs are introduced.
Where Pith is reading between the lines
- Success on WebMall could serve as a stepping stone toward agents that handle everyday consumer decisions across competing retailers without human oversight.
- The same simulation approach could be extended to other domains that require cross-site comparison, such as booking travel or gathering service quotes.
- If agents improve on these tasks, the next question becomes whether the same improvements transfer when the underlying product data and site layouts change over time.
Load-bearing premise
The product data and navigation structure in the four simulated shops are representative of the variety and retrieval challenges that appear when agents interact with multiple real online stores.
What would settle it
Running the same eight agents on live versions of several actual e-commerce sites and observing whether their task completion rates rise substantially above the levels reported on WebMall would indicate that the simulation understates or overstates real-world difficulty.
Figures

read the original abstract
LLM-based web agents have the potential to automate long-running web tasks, such as searching for products in multiple e-shops and subsequently ordering the cheapest products that meet the users needs. Benchmarks for evaluating web agents either require agents to perform tasks online using the live Web or offline using simulated environments, the latter allowing for the exact reproduction of the experimental setup. While DeepShop and ShoppingComp provide online benchmarks that require agents to perform challenging shopping tasks, existing offline benchmarks such as WebShop, WebArena, and Mind2Web cover only comparatively simple e-commerce tasks performed against a single shop containing product data from a single source. What is missing is an e-commerce benchmark that simulates multiple shops containing heterogeneous product data and requires agents to perform complex retrieval tasks. We fill this gap by introducing WebMall, the first offline multi-shop benchmark for evaluating web agents on challenging comparison shopping tasks. WebMall consists of four simulated shops populated with product data extracted from the Common Crawl. The WebMall tasks range from specific product searches and price comparisons to advanced searches for complementary or substitute products, as well as checkout processes. We validate WebMall using eight agents that differ in observation space, availability of short-term memory, and the employed LLM. The validation highlights the difficulty of the benchmark, with the best-performing agents achieving task completion rates below 65% in the task categories cheapest product search and vague product search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebMall as the first offline multi-shop benchmark for web agents, consisting of four simulated shops populated with product data from Common Crawl. It defines tasks ranging from specific product searches and price comparisons to searches for complementary or substitute products and checkout processes. Validation experiments with eight agents (varying in observation space, short-term memory, and LLM) report task completion rates below 65% for the best agents on cheapest-product-search and vague-product-search categories, positioning WebMall as more challenging than prior single-shop offline benchmarks such as WebShop, WebArena, and Mind2Web.
Significance. If the four shops exhibit genuine heterogeneity in product overlap, pricing, and textual descriptions, WebMall would address a clear gap by enabling reproducible evaluation of cross-shop retrieval and comparison tasks. The offline simulation design is a strength for exact reproducibility. The reported low success rates on key categories provide preliminary evidence of difficulty, but the overall significance remains conditional on quantitative validation that the observed failures arise from intended multi-shop complexity rather than data artifacts.
major comments (2)
- The central claim that WebMall is meaningfully harder than single-shop benchmarks rests on the four shops containing overlapping but non-identical items with varied pricing and distinct descriptions. However, the manuscript provides no quantitative characterization (e.g., inter-shop overlap percentages, price dispersion statistics, attribute completeness rates, or lexical diversity metrics) of the Common Crawl-derived data. Without these, the <65% success rates on cheapest-product and vague-product tasks cannot be confidently attributed to multi-shop retrieval challenges rather than simulation artifacts such as uniform schemas or low textual variation.
- The validation section and abstract supply limited detail on exact task definitions, success criteria (e.g., precise matching rules for 'cheapest' or 'vague' queries), number of tasks per category, and statistical analysis (e.g., confidence intervals or variance across runs). This weakens the evidential support for the headline difficulty result and makes it hard to interpret the performance differences across the eight agents.
minor comments (3)
- Clarify the precise observation spaces (e.g., HTML vs. DOM vs. screenshot) and memory mechanisms used by each of the eight agents, ideally in a dedicated table.
- Add example task instances and ground-truth success conditions for each category to improve reproducibility.
- Ensure consistent terminology between 'vague product search' in the abstract and any corresponding section heading or definition in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that additional quantitative characterization of the product data and expanded details on tasks and evaluation will strengthen the manuscript, and we will incorporate these in the revision.
read point-by-point responses
-
Referee: The central claim that WebMall is meaningfully harder than single-shop benchmarks rests on the four shops containing overlapping but non-identical items with varied pricing and distinct descriptions. However, the manuscript provides no quantitative characterization (e.g., inter-shop overlap percentages, price dispersion statistics, attribute completeness rates, or lexical diversity metrics) of the Common Crawl-derived data. Without these, the <65% success rates on cheapest-product and vague-product tasks cannot be confidently attributed to multi-shop retrieval challenges rather than simulation artifacts such as uniform schemas or low textual variation.
Authors: We agree that quantitative metrics would help substantiate that the observed difficulties arise from multi-shop heterogeneity rather than data artifacts. In the revised manuscript we will add a dedicated subsection (likely in Section 3 or 4) reporting inter-shop product overlap percentages, price dispersion for matched items, attribute completeness rates, and lexical diversity metrics (e.g., type-token ratio or embedding variance) computed on the Common Crawl-derived catalogs. These statistics will directly support the claim that WebMall introduces genuine cross-shop comparison challenges. revision: yes
-
Referee: The validation section and abstract supply limited detail on exact task definitions, success criteria (e.g., precise matching rules for 'cheapest' or 'vague' queries), number of tasks per category, and statistical analysis (e.g., confidence intervals or variance across runs). This weakens the evidential support for the headline difficulty result and makes it hard to interpret the performance differences across the eight agents.
Authors: We acknowledge that greater precision is needed. The revision will expand the task definitions in Section 4 and the experimental setup in Section 5 to include: (i) verbatim task templates and query examples for each category, (ii) explicit success criteria with matching rules (e.g., exact product ID match for cheapest-product tasks and semantic similarity thresholds for vague-product tasks), (iii) the exact number of tasks per category, and (iv) statistical analysis including standard deviations and 95% confidence intervals computed over multiple runs. This will improve reproducibility and allow clearer comparison across agents. revision: yes
Circularity Check
No circularity: empirical benchmark construction without derivations or self-referential predictions
full rationale
This is a benchmark construction paper that describes the creation of WebMall from Common Crawl product data across four simulated shops and reports empirical task completion rates for eight agents. No equations, fitted parameters, uniqueness theorems, or predictions are present that could reduce to inputs by construction. The central claims rest on the explicit construction process and observed performance numbers rather than any self-definitional loop, self-citation load-bearing argument, or renamed known result. The absence of a derivation chain makes circularity analysis inapplicable; the paper is self-contained against its stated empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Product data extracted from Common Crawl is sufficiently representative of real e-commerce heterogeneity across multiple shops.
Forward citations
Cited by 1 Pith paper
-
MCP vs RAG vs NLWeb vs HTML: A Comparison of the Effectiveness and Efficiency of Different Agent Interfaces to the Web (Technical Report)
RAG, MCP, and NLWeb interfaces let LLM web agents achieve higher F1 scores (0.75-0.77 vs 0.67) and much lower token usage and runtime than HTML in controlled e-commerce tasks.
Reference graph
Works this paper leans on
-
[1]
Alexander Brinkmann, Anna Primpeli, and Christian Bizer. 2023. The web data commons schema. org data set series. In Companion Proceedings of the ACM Web Conference 2023. 136–139
work page 2023
- [2]
-
[3]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, et al . 2023. Mind2Web: Towards a Generalist Agent for the Web.Advances in Neural Infor- mation Processing Systems 36 (2023), 28091–28114
work page 2023
-
[4]
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao
-
[5]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv:2506.11763 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. 2025. From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review. arXiv:2504.19678 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, et al
-
[9]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. In Proceedings of the International Conference on Learning Representations 2024: Workshop on Large Language Model (LLM) Agents
work page 2024
-
[10]
Woźniak, Paul Lukowicz, and Jakob Karo- lus
Lars Krupp, Daniel Geißler, Paweł W. Woźniak, Paul Lukowicz, and Jakob Karo- lus. 2025. Quantifying Web Agents-A Survey on Web Agent Performance and Efficiency. OSF (2025)
work page 2025
-
[11]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, et al. 2023. AgentBench: Evaluating LLMs as Agents. InProceedings of the Twelfth International Conference on Learning Representations
work page 2023
- [12]
- [13]
-
[14]
A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions
Pascal J. Sager, Benjamin Meyer, Peng Yan, Rebekka von Wartburg-Kottler, Layan Etaiwi, et al. 2025. A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions. arXiv:2501.16150 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. Advances in Neural Information Processing Systems 36 (Dec. 2023), 8634–8652
work page 2023
-
[16]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, et al
-
[17]
Transactions on Machine Learning Research (Nov
Voyager: An Open-Ended Embodied Agent with Large Language Models. Transactions on Machine Learning Research (Nov. 2023)
work page 2023
-
[18]
Haoxin Wang, Xianhan Peng, Xucheng Huang, Yizhe Huang, Ming Gong, et al
- [19]
- [20]
-
[21]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science 18, 6 (March 2024). doi:10.1007/s11704- 024-40231-1
-
[22]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, et al
-
[23]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents. arXiv:2504.12516 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao
-
[25]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V. arXiv:2310.11441 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. Advances in Neural Information Processing Systems 35 (Dec. 2022), 20744–20757
work page 2022
-
[27]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, et al. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of the Eleventh International Conference on Learning Representations
work page 2023
-
[28]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, et al
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, et al. 2023. We- bArena: A Realistic Web Environment for Building Autonomous Agents. In Proceedings of the Twelfth International Conference on Learning Representations
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.