Heavy-Tailed Class-Conditional Priors for Long-Tailed Generative Modeling
Pith reviewed 2026-05-18 19:07 UTC · model grok-4.3
The pith
Per-class heavy-tailed priors in VAEs give tail classes equal latent mass and lower FID under severe imbalance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
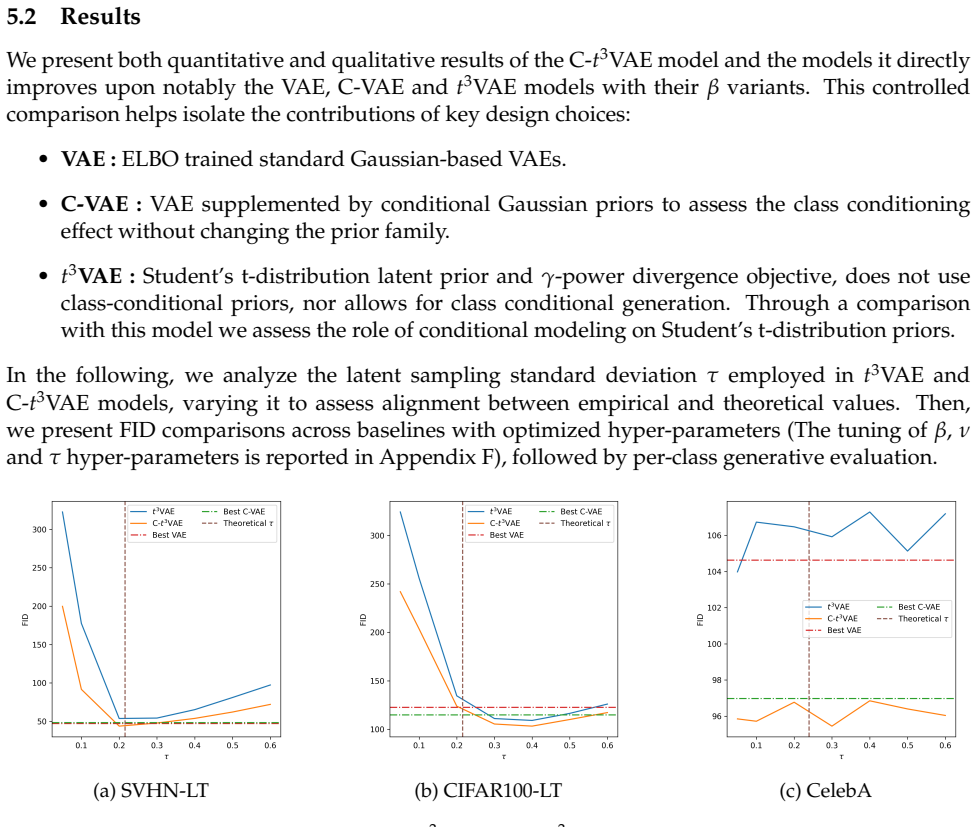
C-t³VAE assigns a per-class Student's t joint prior over latent and output variables. This design promotes uniform prior mass across class-conditioned components. The model is optimized with a closed-form objective derived from the γ-power divergence, and generation uses an equal-weight latent mixture for class-balanced output. On long-tailed datasets, it attains lower FID scores than t³VAE and Gaussian VAEs under severe imbalance while remaining competitive in balanced or mildly imbalanced settings and improving per-class F1 scores.
What carries the argument
The per-class Student's t joint prior over latent and output variables, which replaces the single global prior so that prior mass no longer scales with class frequency.
If this is right
- Tail-class samples exhibit higher fidelity and better mode coverage than those from global-prior models.
- The method improves per-class F1 scores over conditional Gaussian VAEs in highly imbalanced regimes.
- Gaussian priors suffice only when the imbalance ratio stays below the identified threshold of five.
- Class-balanced generation follows directly from sampling the equal-weight latent mixture.
Where Pith is reading between the lines
- The same per-class heavy-tailed structure could be inserted into other latent-variable generators such as diffusion models to test whether tail coverage improves without task-specific retraining.
- One could measure whether the resulting latent codes also reduce bias when the same encoder is later used for downstream classification on the identical long-tailed labels.
- Varying the degrees of freedom separately per class might let the model adapt tail weight to the observed frequency of each class rather than using one global value.
Load-bearing premise
The per-class Student's t prior actually spreads prior mass uniformly across the class-conditioned components rather than still favoring classes with more data.
What would settle it
Finding that FID scores on SVHN-LT or CIFAR100-LT remain equal to or higher than those of the global t³VAE baseline when the imbalance ratio reaches or exceeds five.
Figures








read the original abstract
Variational Autoencoders (VAEs) with global priors trained under an imbalanced empirical class distribution can lead to underrepresentation of tail classes in the latent space. While $t^3$VAE improves robustness via heavy-tailed Student's $t$-distribution priors, its single global prior still allocates mass proportionally to class frequency. We address this latent geometric bias by introducing C-$t^3$VAE, which assigns a per-class Student's $t$ joint prior over latent and output variables. This design promotes uniform prior mass across class-conditioned components. To optimize our model we derive a closed-form objective from the $\gamma$-power divergence, and we introduce an equal-weight latent mixture for class-balanced generation. On SVHN-LT, CIFAR100-LT, and CelebA datasets, C-$t^3$VAE consistently attains lower FID scores than $t^3$VAE and Gaussian-based VAE baselines under severe class imbalance while remaining competitive in balanced or mildly imbalanced settings. In per-class F1 evaluations, our model outperforms the conditional Gaussian VAE across highly imbalanced settings. Moreover, we identify the mild imbalance threshold $\rho < 5$, for which Gaussian-based models remain competitive. However, for $\rho \geq 5$ our approach yields improved class-balanced generation and mode coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce C-t³VAE, a VAE variant with per-class Student's t joint priors over latent and output variables to address underrepresentation of tail classes in long-tailed data. By promoting uniform prior mass, it aims to remove latent geometric bias. The model uses a closed-form objective derived from γ-power divergence and an equal-weight mixture for generation. It reports lower FID scores than t³VAE and Gaussian VAEs on SVHN-LT, CIFAR100-LT, and CelebA under severe imbalance, better per-class F1, and competitiveness in balanced settings, with a threshold ρ < 5 for Gaussian models.
Significance. Should the per-class t-priors indeed achieve the claimed uniform mass allocation and the objective derivation be sound, this could offer a valuable advancement in generative modeling for imbalanced datasets, enhancing mode coverage and class-balanced generation. The empirical results and the identified imbalance threshold provide actionable insights. Credit for the closed-form objective and the consistent performance gains in severe imbalance cases.
major comments (3)
- [Abstract] The central claim that the per-class Student's t joint prior promotes uniform prior mass and removes latent geometric bias is not supported by any direct verification such as marginal prior mass computation or latent occupancy analysis.
- [Method (objective derivation)] No verification is given that the closed-form objective from the γ-power divergence matches the per-class prior over latent and output variables.
- [Experiments] Reported FID improvements lack error bars, and there is no ablation study on the γ-power divergence choice, both of which are important for assessing the robustness of the results.
minor comments (2)
- [Abstract] Clarify the definition of the imbalance ratio ρ upon its first mention.
- [Throughout] Check for consistency in the use of 'C-t³VAE' and related notations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and detailed review of our manuscript. We address each major comment below and outline the specific revisions we will make to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract] The central claim that the per-class Student's t joint prior promotes uniform prior mass and removes latent geometric bias is not supported by any direct verification such as marginal prior mass computation or latent occupancy analysis.
Authors: We agree that explicit verification would strengthen the presentation of this central claim. The equal-weight mixture of per-class t-priors is designed to allocate uniform mass by construction, but we will add direct supporting evidence in the revision. Specifically, we will include marginal prior mass computations for each class-conditional component and latent occupancy analysis (e.g., per-class density histograms or occupancy statistics in the latent space) to empirically demonstrate the removal of geometric bias. revision: yes
-
Referee: [Method (objective derivation)] No verification is given that the closed-form objective from the γ-power divergence matches the per-class prior over latent and output variables.
Authors: The full derivation establishing that the closed-form objective corresponds to the γ-power divergence under the joint per-class prior (over both latent and output variables) appears in Appendix B. To improve accessibility, we will add a concise verification outline in the main text of the Methods section, highlighting the key algebraic steps that confirm the objective correctly incorporates the class-conditional joint priors. revision: yes
-
Referee: [Experiments] Reported FID improvements lack error bars, and there is no ablation study on the γ-power divergence choice, both of which are important for assessing the robustness of the results.
Authors: We concur that error bars and targeted ablations are valuable for assessing result robustness. In the revised manuscript, we will recompute and report all FID scores as means with standard deviations across multiple independent training runs (at least three seeds per setting). We will also add an ablation study examining the effect of different γ values in the power divergence objective on generation quality and class balance. revision: yes
Circularity Check
No significant circularity; derivation remains independent of fitted inputs or self-referential definitions
full rationale
The paper states that the per-class Student's t joint prior 'promotes uniform prior mass across class-conditioned components' as a design motivation and derives a closed-form objective from the γ-power divergence. This derivation is presented as a mathematical step independent of the target FID metric. The equal-weight mixture is introduced explicitly at generation time rather than being fitted to training data and then renamed as a prediction. No equations reduce the reported performance gains to a hyperparameter fit by construction, and no load-bearing uniqueness theorem or ansatz is smuggled via self-citation in the given text. Empirical claims rest on external dataset evaluations (SVHN-LT, CIFAR100-LT, CelebA) rather than tautological re-expression of inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- degrees of freedom for each class-conditional t
axioms (1)
- domain assumption The gamma-power divergence admits a closed-form expression when the prior is a per-class Student's t.
invented entities (1)
-
per-class Student's t joint prior over latent and output variables
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Conditional-t3VAE, which defines a per-class Student’s t joint prior over latent and output variables... optimized using a closed-form objective derived from the γ-power divergence.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p⋆_ν(z) = ∑_{y=1}^K α_y · t_m(μ_y, τ²I, ν+n) with α_y=1/K
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ldfacenet: Latent diffusion-based network for high-fidelity deepfake generation,
D. Mehta, A. Mehta, and P . Narang, “Ldfacenet: Latent diffusion-based network for high-fidelity deepfake generation,” in International Conference on Pattern Recognition , pp. 386–400, Springer, 2024
work page 2024
-
[2]
Brain imaging generation with latent diffusion models,
W. H. Pinaya, P .-D. Tudosiu, J. Dafflon, P . F. Da Costa, V . Fernandez, P . Nachev, S. Ourselin, and M. J. Cardoso, “Brain imaging generation with latent diffusion models,” inMICCAI Workshop on Deep Generative Models, pp. 117–126, Springer, 2022
work page 2022
-
[3]
Social biases through the text-to-image generation lens,
R. Naik and B. Nushi, “Social biases through the text-to-image generation lens,” in Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, p. 786–808, 2023
work page 2023
-
[4]
Auto-encoding variational bayes,
D. P . Kingma and M. Welling, “Auto-encoding variational bayes,” 2013
work page 2013
-
[5]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, 2022
work page 2022
-
[6]
On the statistical capacity of deep generative models,
E. Tam and D. B. Dunson, “On the statistical capacity of deep generative models,” arXiv preprint arXiv:2501.07763, 2025. 10
-
[7]
Student-t variational autoen- coder for robust density estimation,
H. Takahashi, T. Iwata, Y. Yamanaka, M. Yamada, and S. Yagi, “Student-t variational autoen- coder for robust density estimation,” in Proceedings of the Twenty-Seventh International Joint Con- ference on Artificial Intelligence, IJCAI-18, pp. 2696–2702, International Joint Conferences on Arti- ficial Intelligence Organization, 7 2018
work page 2018
-
[8]
Variational auto-encoders with student’s t-prior,
N. Abiri and M. Ohlsson, “Variational auto-encoders with student’s t-prior,” arXiv preprint arXiv:2004.02581, 2020
-
[9]
Pythagoras theorem in information geometry and applications to generalized linear models,
S. Eguchi, “Pythagoras theorem in information geometry and applications to generalized linear models,” in Information Geometry (A. Plastino, A. S. Srinivasa Rao, and C. Rao, eds.), vol. 45 of Handbook of Statistics, pp. 15–42, Elsevier, 2021
work page 2021
-
[10]
t3-variational autoencoder: Learning heavy- tailed data with student’s t and power divergence,
J. Kim, J. Kwon, M. Cho, H. Lee, and J.-H. Won, “ t3-variational autoencoder: Learning heavy- tailed data with student’s t and power divergence,” in The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[11]
Reading digits in natural im- ages with unsupervised feature learning,
Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural im- ages with unsupervised feature learning,” in NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, 2011
work page 2011
-
[12]
Learning imbalanced datasets with label- distribution-aware margin loss,
K. Cao, C. Wei, A. Gaidon, N. Arechiga, and T. Ma, “Learning imbalanced datasets with label- distribution-aware margin loss,” in Advances in Neural Information Processing Systems, 2019
work page 2019
-
[13]
Deep learning face attributes in the wild,
Z. Liu, P . Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[14]
Shape your space: A gaussian mixture regularization approach to deterministic autoencoders,
A. Saseendran, K. Skubch, S. Falkner, and M. Keuper, “Shape your space: A gaussian mixture regularization approach to deterministic autoencoders,” in Advances in Neural Information Pro- cessing Systems (M. Ranzato, A. Beygelzimer, Y. Dauphin, P . Liang, and J. W. Vaughan, eds.), vol. 34, pp. 7319–7332, Curran Associates, Inc., 2021
work page 2021
-
[15]
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders
N. Dilokthanakul, P . A. Mediano, M. Garnelo, M. C. Lee, H. Salimbeni, K. Arulkumaran, and M. Shanahan, “Deep unsupervised clustering with gaussian mixture variational autoencoders,” arXiv preprint arXiv:1611.02648, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Hyperspherical variational auto-encoders,
T. R. Davidson, L. Falorsi, N. De Cao, T. Kipf, and J. M. Tomczak, “Hyperspherical variational auto-encoders,” 34th Conference on Uncertainty in Artificial Intelligence (UAI-18), 2018
work page 2018
-
[17]
Tails of lipschitz triangular flows,
P . Jaini, I. Kobyzev, Y. Yu, and M. Brubaker, “Tails of lipschitz triangular flows,” inInternational Conference on Machine Learning, pp. 4673–4681, PMLR, 2020
work page 2020
-
[18]
C. Chadebec, E. Thibeau-Sutre, N. Burgos, and S. Allassonni `ere, “Data augmentation in high dimensional low sample size setting using a geometry-based variational autoencoder,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 2879–2896, 2023
work page 2023
-
[19]
Variational autoencoder with implicit optimal priors,
H. Takahashi, T. Iwata, Y. Yamanaka, M. Yamada, and S. Yagi, “Variational autoencoder with implicit optimal priors,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 33, pp. 5066–5073, 2019
work page 2019
-
[20]
Class-balancing diffusion models,
Y. Qin, H. Zheng, J. Yao, M. Zhou, and Y. Zhang, “Class-balancing diffusion models,” in Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 18434–18443, 2023
work page 2023
-
[21]
Heavy-tailed diffusion models,
K. Pandey, J. Pathak, Y. Xu, S. Mandt, M. Pritchard, A. Vahdat, and M. Mardani, “Heavy-tailed diffusion models,” in The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[22]
beta-VAE: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerch- ner, “beta-VAE: Learning basic visual concepts with a constrained variational framework,” in International Conference on Learning Representations, 2017. 11
work page 2017
-
[23]
Semi-supervised learning with deep generative models,
D. P . Kingma, S. Mohamed, D. Jimenez Rezende, and M. Welling, “Semi-supervised learning with deep generative models,” Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[24]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” tech. rep., 2009
work page 2009
-
[25]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information pro- cessing systems, vol. 30, 2017
work page 2017
-
[26]
Improved precision and recall metric for assessing generative models,
T. Kynk ¨a¨anniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila, “Improved precision and recall metric for assessing generative models,”Advances in neural information processing systems, vol. 32, 2019. 12 Appendix for ”Conditional-t3V AE: Equitable Latent Space Allocation for Fair Generation” A γ-power divergence corrected derivation In this section, we...
work page 2019
-
[27]
• SVHN-LT : This dataset is comprised of colored images of digits from 0 to 9 of size 32× 32 × 3
each chosen to highlight different challenges related to generative modeling under class imbal- ance and varying visual complexity. • SVHN-LT : This dataset is comprised of colored images of digits from 0 to 9 of size 32× 32 × 3. It serves as our controlled experimental setting. While simple enough for all models to con- verge, it is rich enough to reflec...
work page 1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.