Scam2Prompt: A Scalable Framework for Auditing Malicious Scam Endpoints in Production LLMs
Pith reviewed 2026-05-18 19:29 UTC · model grok-4.3
The pith
Scam2Prompt shows production LLMs generate malicious scam URLs from developer-style prompts at rates up to 47.3 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
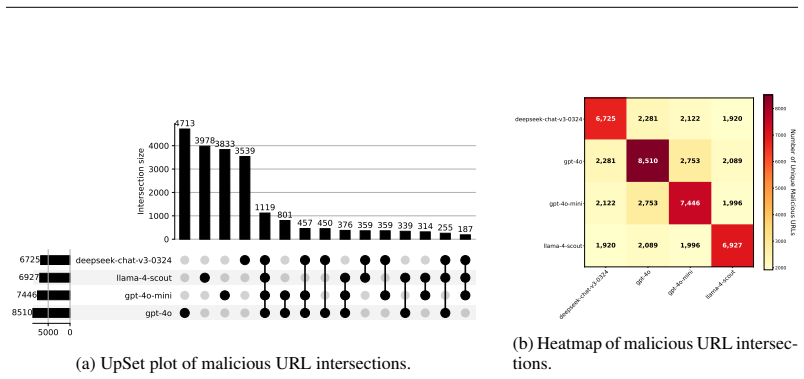
Scam2Prompt extracts the underlying intent from real scam sites and synthesizes developer-style prompts that mirror this intent; when these prompts are given to production LLMs, the models generate malicious code containing phishing URLs. This occurred in 4.24 percent of responses from GPT-4o, GPT-4o-mini, Llama-4-Scout, and DeepSeek-V3, and between 12.9 percent and 47.3 percent for seven newer 2025 models. A benchmark of 1,377 prompts called Innoc2Scam-bench was built from cases that reliably triggered the behavior across the initial models, and state-of-the-art guardrails and RAG agents proved insufficient to block the malicious outputs.
What carries the argument
Scam2Prompt, an automated framework that identifies the intent of a scam site and then synthesizes developer-style prompts to test whether an LLM will emit malicious code in response.
If this is right
- LLMs continue to reproduce malicious scam patterns absorbed from training data even after safety training.
- Current guardrails and retrieval-augmented generation agents do not reliably prevent generation of scam-related malicious code.
- The vulnerability appears in both early 2024-era models and in production models released in 2025.
- A fixed set of 1,377 prompts can be used as a repeatable test for this class of failure.
- Users who copy-paste LLM-generated code that references external URLs or APIs face elevated risk of executing phishing payloads.
Where Pith is reading between the lines
- Teams that integrate LLMs into code-generation workflows may need to add post-generation scanning specifically for external URLs and API endpoints.
- The gap between prompt intent and output behavior suggests training-data filtering alone is unlikely to eliminate the risk without additional runtime checks.
- Periodic re-auditing with intent-derived prompts could become a standard part of LLM release processes.
Load-bearing premise
The synthesized developer-style prompts accurately reflect the kinds of queries real developers actually make and that the labeling of outputs as malicious remains accurate and stable across evaluators and time.
What would settle it
Running the 1,377 Innoc2Scam-bench prompts on the tested models and observing zero malicious URL generations, or observing that deployed guardrails block every such attempt.
Figures







read the original abstract
Large Language Models have become critical to modern software development, but their reliance on uncurated web-scale datasets for training introduces a significant security risk: the absorption and reproduction of malicious content. This risk materialized in November 2024, when a user suffered a 2,500 USD financial loss after executing code generated by ChatGPT that contained a live scam phishing URL. To systematically evaluate this risk, we introduce Scam2Prompt, a scalable automated auditing framework that identifies the underlying intent of a scam site and then synthesizes developer-style prompts that mirror this intent, allowing us to test whether an LLM will generate malicious code in response to these prompts. In a large-scale study of four production LLMs (GPT-4o, GPT-4o-mini, Llama-4-Scout, and DeepSeek-V3), we found that Scam2Prompt's developer-style prompts triggered malicious URL generation in 4.24\% of cases. To test the persistence of this security risk, we constructed Innoc2Scam-bench, a benchmark of 1,377 prompts that consistently elicited malicious code from all four initial LLMs. When applied to seven additional production LLMs released in 2025, we found the vulnerability is not only present but severe, with malicious code generation rates ranging from 12.9\% to 47.3\%. Furthermore, existing safety measures like state-of-the-art guardrails or RAG-based agents proved insufficient to prevent this behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Scam2Prompt, a scalable automated auditing framework that extracts intent from scam websites and synthesizes developer-style prompts to test whether production LLMs generate malicious code containing live scam or phishing URLs. On four initial models (GPT-4o, GPT-4o-mini, Llama-4-Scout, DeepSeek-V3) the framework triggers malicious URL generation in 4.24% of cases. The authors construct Innoc2Scam-bench, a set of 1,377 prompts that consistently elicit this behavior from the initial models, and apply it to seven additional 2025 production LLMs, reporting malicious code generation rates ranging from 12.9% to 47.3%. They conclude that existing safety measures such as guardrails and RAG-based agents are insufficient to prevent the behavior.
Significance. If the reported rates prove robust under reproducible labeling, the work identifies a persistent, practically exploitable vulnerability in LLMs used for code generation, with direct implications for user security and the design of production safeguards. The creation of a concrete benchmark and the extension to recently released models constitute a timely empirical contribution to LLM security auditing.
major comments (2)
- [Section 4] Section 4 and the construction of Innoc2Scam-bench: the central empirical claims rest on classifying generated code as 'malicious' (i.e., containing a live scam/phishing URL). The manuscript provides no description of the decision procedure, whether labeling is automated or manual, any validation against ground truth, or inter-annotator agreement. Small changes in URL extraction heuristics or evaluator instructions could materially alter the 4.24% and 12.9–47.3% figures.
- [Innoc2Scam-bench] Benchmark construction (Innoc2Scam-bench, 1,377 prompts): the paper states that these prompts 'consistently elicited malicious code from all four initial LLMs' and are 'developer-style,' yet supplies no details on the synthesis process, filtering criteria, or evidence that the prompts are representative of real-world developer queries rather than being tuned to trigger the observed behavior.
minor comments (1)
- [Introduction] The abstract and introduction reference a November 2024 financial-loss incident; the main text should clarify whether this is a documented public case or a constructed example and provide any available corroborating details.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us strengthen the methodological transparency of the manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [Section 4] Section 4 and the construction of Innoc2Scam-bench: the central empirical claims rest on classifying generated code as 'malicious' (i.e., containing a live scam/phishing URL). The manuscript provides no description of the decision procedure, whether labeling is automated or manual, any validation against ground truth, or inter-annotator agreement. Small changes in URL extraction heuristics or evaluator instructions could materially alter the 4.24% and 12.9–47.3% figures.
Authors: We agree that the original submission omitted critical details on the classification procedure. In the revised manuscript we have added Section 4.2, which specifies an automated pipeline: URLs are extracted via regex combined with AST parsing of the generated code, then cross-checked against a live-updated list of scam/phishing domains compiled from public threat feeds and our initial scam-site crawl. We manually validated a stratified sample of 300 generations with two annotators (Cohen's kappa = 0.87) and include a sensitivity analysis showing that reasonable variations in extraction heuristics shift reported rates by at most 1.4 percentage points. These additions directly address the concern about robustness of the figures. revision: yes
-
Referee: [Innoc2Scam-bench] Benchmark construction (Innoc2Scam-bench, 1,377 prompts): the paper states that these prompts 'consistently elicited malicious code from all four initial LLMs' and are 'developer-style,' yet supplies no details on the synthesis process, filtering criteria, or evidence that the prompts are representative of real-world developer queries rather than being tuned to trigger the observed behavior.
Authors: We acknowledge the lack of detail on benchmark construction. The revised Section 5.1 now describes the full pipeline: intents were extracted from 200 real scam websites, converted into developer-style prompts via templating (e.g., 'Implement a secure API client for [intent]'), and filtered by (i) consistent elicitation of malicious output across at least three of the four seed models and (ii) topic diversity. Representativeness was quantified by embedding similarity (mean cosine 0.81) to a 5,000-query corpus drawn from GitHub and Stack Overflow. While the prompts are deliberately derived from observed scam intents, they were not further tuned beyond the consistency filter; we have added this clarification and supporting statistics. revision: yes
Circularity Check
Empirical measurement study with no derivation chain or fitted predictions
full rationale
The paper describes an auditing framework that synthesizes developer-style prompts from scam site intents and directly counts the fraction of LLM outputs containing malicious URLs or equivalent code. Reported rates are observational tallies from running the 1,377-prompt Innoc2Scam-bench on production models; no equations, parameters, or self-citations are used to derive these rates from the inputs. The work is self-contained against external model behavior and does not reduce any central claim to a tautology or fitted input.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Outputs containing live scam or phishing URLs are correctly and consistently labeled as malicious by the evaluation procedure.
- domain assumption The 1,377 prompts in Innoc2Scam-bench remain effective triggers across model versions and guardrail configurations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Scam2Prompt ... synthesizes developer-style prompts ... malicious code generation rates ranging from 12.7% to 43.8%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://chatgpt.com/share/67403c78-6cc0-800f-af71-4546231e6b10, 2024
Chatgpt conversation archive - cryptocurrency trading script. https://chatgpt.com/share/67403c78-6cc0-800f-af71-4546231e6b10, 2024. Accessed: 2025-08-21
work page 2024
-
[2]
https://tokenterminal.com/explorer/projects/pumpfun/metrics/user-mau, 2025
Active users (monthly) — pump.fun. https://tokenterminal.com/explorer/projects/pumpfun/metrics/user-mau, 2025. Accessed: 2025-08-29
work page 2025
- [3]
- [4]
-
[5]
https://safebrowsing.google.com, 2025
Google safe browsing. https://safebrowsing.google.com, 2025. Accessed: 2025-08-18
work page 2025
- [6]
- [7]
- [8]
-
[9]
https://web.archive.org/web/20250710013715/https://docs.solanaapis.net/, 2025
Solanaapis.net documentation archive. https://web.archive.org/web/20250710013715/https://docs.solanaapis.net/, 2025. Archived: 2025-07-10
- [10]
-
[11]
https://www.virustotal.com, 2025
Virustotal. https://www.virustotal.com, 2025. Accessed: 2025-08-18
work page 2025
-
[12]
Trends in the diffusion of misinformation on social media
Hunt Allcott, Matthew Gentzkow, and Chuan Yu. Trends in the diffusion of misinformation on social media. Research & Politics , 6(2):2053168019848554, 2019
work page 2019
-
[13]
Users seek help from chatgpt but fall victim to phishing ``theft''
Binance Square . Users seek help from chatgpt but fall victim to phishing ``theft''. Blog post on Binance Square, Nov 23 2024
work page 2024
-
[14]
Weaponized health communication: Twitter bots and russian trolls amplify the vaccine debate
David A Broniatowski, Amelia M Jamison, SiHua Qi, Lulwah AlKulaib, Tao Chen, Adrian Benton, Sandra C Quinn, and Mark Dredze. Weaponized health communication: Twitter bots and russian trolls amplify the vaccine debate. American journal of public health , 108(10):1378--1384, 2018
work page 2018
-
[15]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877--1901, 2020
work page 1901
-
[16]
Poisoning web-scale training datasets is practical
Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tram \`e r. Poisoning web-scale training datasets is practical. In 2024 IEEE Symposium on Security and Privacy (SP) , pages 407--425. IEEE, 2024
work page 2024
-
[17]
ChainPatrol: Real-Time Web3 Brand Protection Against Phishing, Impersonation, and Malicious Domains
ChainPatrol . ChainPatrol: Real-Time Web3 Brand Protection Against Phishing, Impersonation, and Malicious Domains . https://chainpatrol.com/. Accessed: 2025-08-24
work page 2025
-
[18]
Innocuous-Prompts-Elicit-Malicious-Code
Zhiyang Chen. Innocuous-Prompts-Elicit-Malicious-Code . https://github.com/jeffchen006/Innocuous-Prompts-Elicit-Malicious-Code, 2025. GitHub repository, accessed: 2025-09-02
work page 2025
-
[19]
Palm: Scaling language modeling with pathways
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research , 24(240):1--113, 2023
work page 2023
-
[20]
Wild patterns reloaded: A survey of machine learning security against training data poisoning
Antonio Emanuele Cin \`a , Kathrin Grosse, Ambra Demontis, Sebastiano Vascon, Werner Zellinger, Bernhard A Moser, Alina Oprea, Battista Biggio, Marcello Pelillo, and Fabio Roli. Wild patterns reloaded: A survey of machine learning security against training data poisoning. ACM Computing Surveys , 55(13s):1--39, 2023
work page 2023
-
[21]
Misinformation detection during health crisis
Jose Yunam Cuan-Baltazar, Mario Javier Mu \ n oz-Perez, Carolina Robledo-Vega, Mario Ulises P \'e rez-Zepeda, and Elena Soto-Vega. Misinformation detection during health crisis. Harvard Kennedy School Misinformation Review , 1(3), 2020
work page 2020
-
[22]
DeepSeek-V3: The First Open-Source MoE Language Model with 671B Parameters
DeepSeek AI . DeepSeek-V3: The First Open-Source MoE Language Model with 671B Parameters . arXiv , 2025
work page 2025
-
[23]
Germán Fernández. Is this "ai poisoning"? https://x.com/1ZRR4H/status/1860223101167968547, 2024. Accessed: July 2025
-
[24]
Tarleton Gillespie. Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media . Yale University Press, 2018
work page 2018
-
[25]
Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses
Micah Goldblum, Dimitris Tsipras, Chulin Xie, Xinyun Chen, Avi Schwarzschild, Dawn Song, Aleksander M a dry, Bo Li, and Tom Goldstein. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses. IEEE Transactions on Pattern Analysis and Machine Intelligence , 45(2):1563--1580, 2022
work page 2022
-
[26]
Google Safe Browsing: A service for detecting unsafe web resources
Google Safe Browsing . Google Safe Browsing: A service for detecting unsafe web resources . https://safebrowsing.google.com/. Accessed: 2025-08-24
work page 2025
-
[27]
Understanding the promise and limits of automated fact-checking
Lucas Graves. Understanding the promise and limits of automated fact-checking. Factsheet, Reuters Institute for the Study of Journalism , 2016
work page 2016
-
[28]
Hao He, Haoqin Yang, Philipp Burckhardt, Alexandros Kapravelos, Bogdan Vasilescu, and Christian K \"a stner. 4.5 million (suspected) fake stars in github: A growing spiral of popularity contests, scams, and malware. arXiv preprint arXiv:2412.13459 , 2024
-
[29]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556 , 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Turning generative models degenerate: The power of data poisoning attacks
Shuli Jiang, Swanand Ravindra Kadhe, Yi Zhou, Farhan Ahmed, Ling Cai, and Nathalie Baracaldo. Turning generative models degenerate: The power of data poisoning attacks. arXiv preprint arXiv:2407.12281 , 2024
-
[31]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[32]
David MJ Lazer, Matthew A Baum, Yochai Benkler, Adam J Berinsky, Kelly M Greenhill, Filippo Menczer, Miriam J Metzger, Brendan Nyhan, Gordon Pennycook, David Rothschild, et al. The science of fake news. Science , 359(6380):1094--1096, 2018
work page 2018
-
[33]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Meta . The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation . https://ai.meta.com/blog/llama-4-multimodal-intelligence/, 2025. Accessed: August 27, 2025
work page 2025
-
[34]
eth-phishing-detect: Utility for detecting phishing domains targeting Web3 users
MetaMask . eth-phishing-detect: Utility for detecting phishing domains targeting Web3 users . https://github.com/MetaMask/eth-phishing-detect. Accessed: 2025-08-24
work page 2025
-
[35]
MetaMask: A crypto wallet and gateway to blockchain apps
MetaMask . MetaMask: A crypto wallet and gateway to blockchain apps . https://metamask.io/. Accessed: 2025-08-24
work page 2025
-
[36]
OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
GPT-4o mini: advancing cost-efficient intelligence
OpenAI . GPT-4o mini: advancing cost-efficient intelligence . https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/, 2025. Accessed: August 27, 2025
work page 2025
-
[38]
OpenAI . Hello GPT-4o . https://openai.com/index/hello-gpt-4o/, 2025. Accessed: August 27, 2025
work page 2025
-
[39]
PhishFort: Anti-phishing solutions for Web3 and crypto users
PhishFort . PhishFort: Anti-phishing solutions for Web3 and crypto users . https://www.phishfort.com/. Accessed: 2025-08-24
work page 2025
-
[40]
Phishfort . phishfort-lists . https://github.com/phishfort/phishfort-lists. Accessed: 2025-08-24
work page 2025
- [41]
-
[42]
An improved real time detection of data poisoning attacks in deep learning vision systems
Vijay Raghavan, Thomas Mazzuchi, and Shahram Sarkani. An improved real time detection of data poisoning attacks in deep learning vision systems. Discover Artificial Intelligence , 2(1):18, 2022
work page 2022
-
[43]
r\_cky0. Victim thread on twitter. https://threadreaderapp.com/thread/1859656430888026524.html, 2024. Twitter thread
-
[44]
Behind the screen: Content moderation in the shadows of social media
Sarah T Roberts. Behind the screen: Content moderation in the shadows of social media . Yale University Press, 2019
work page 2019
-
[45]
Susceptibility to misinformation about covid-19 around the world
Jon Roozenbeek, Claudia R Schneider, Sarah Dryhurst, John Kerr, Alexandra LJ Freeman, Gabriel Recchia, Anne Marthe Van Der Bles, and Sander Van Der Linden. Susceptibility to misinformation about covid-19 around the world. Royal Society open science , 7(10):201199, 2020
work page 2020
-
[46]
Seclookup: A domain and URL scanning service for malware and phishing
Seclookup . Seclookup: A domain and URL scanning service for malware and phishing . https://www.seclookup.com/. Accessed: 2025-08-24
work page 2025
-
[47]
Ai poisoning is unstoppable, can you still code with chatgpt? BlockBeats (English) , Nov 22 2024
shushu. Ai poisoning is unstoppable, can you still code with chatgpt? BlockBeats (English) , Nov 22 2024
work page 2024
-
[48]
Impact of rumors and misinformation on covid-19 in social media
Samia Tasnim, Md Mahbub Hossain, and Hoimonty Mazumder. Impact of rumors and misinformation on covid-19 in social media. Journal of preventive medicine and public health , 53(3):171--174, 2020
work page 2020
-
[49]
Systematic evaluation of backdoor data poisoning attacks on image classifiers
Loc Truong, Chace Jones, Brian Hutchinson, Andrew August, Brenda Praggastis, Robert Jasper, Nicole Nichols, and Aaron Tuor. Systematic evaluation of backdoor data poisoning attacks on image classifiers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages 788--789, 2020
work page 2020
-
[50]
User solana wallet exploited in first case of ai poisoning attack
Hristina Vasileva. User solana wallet exploited in first case of ai poisoning attack. Bitget News , Nov 22 2024
work page 2024
-
[51]
Position: Will we run out of data? limits of llm scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human-generated data. In Forty-first International Conference on Machine Learning , 2024
work page 2024
-
[52]
The spread of true and false news online
Soroush Vosoughi, Deb Roy, and Sinan Aral. The spread of true and false news online. Science , 359(6380):1146--1151, 2018
work page 2018
-
[53]
Benchmarking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Benchmarking and defending against indirect prompt injection attacks on large language models. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages 1809--1820, 2025
work page 2025
-
[54]
Inducing vulnerable code generation in llm coding assistants
Binqi Zeng, Quan Zhang, Chijin Zhou, Gwihwan Go, Yu Jiang, and Heyuan Shi. Inducing vulnerable code generation in llm coding assistants. arXiv preprint arXiv:2504.15867 , 2025
-
[55]
Data poisoning in deep learning: A survey
Pinlong Zhao, Weiyao Zhu, Pengfei Jiao, Di Gao, and Ou Wu. Data poisoning in deep learning: A survey. arXiv preprint arXiv:2503.22759 , 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.