GrACE: A Generative Approach to Better Confidence Elicitation and Efficient Test-Time Scaling in Large Language Models
Pith reviewed 2026-05-18 17:50 UTC · model grok-4.3
The pith
GrACE trains LLMs to express confidence through similarity of their last hidden state to a special token's embedding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GrACE achieves reliable confidence elicitation by fine-tuning the LLM so that the similarity between its last hidden state and the embedding of an appended special token directly indicates the accuracy of the generated output. This generative approach yields superior discriminative capacity and calibration on open-ended tasks compared to prior methods, all without extra sampling or an auxiliary model, and enables confidence-guided strategies that boost final accuracy while reducing required samples.
What carries the argument
The similarity between the last hidden state and the embedding of a special token appended to the vocabulary, calibrated via fine-tuning on accuracy targets.
If this is right
- LLMs can provide on-the-fly confidence estimates during generation without additional compute.
- Test-time scaling becomes more efficient by using confidence to limit the number of samples needed.
- Open-ended generation tasks gain better calibrated uncertainty measures for decision making.
- Deployment in high-stakes domains improves because confidence no longer relies on costly post-processing.
Where Pith is reading between the lines
- If the special token embedding learns to represent uncertainty patterns, it could be used to debug or interpret model errors.
- This mechanism might extend to other sequence models beyond transformers if the hidden state carries similar information.
- Combining GrACE with existing sampling methods could create hybrid systems with even lower overhead.
Load-bearing premise
Fine-tuning with accuracy-associated targets makes the hidden-state similarity to the special token a reliable and generalizable indicator of true model confidence.
What would settle it
A test showing that after fine-tuning, the similarity scores do not correlate with actual output accuracy on held-out open-ended generation tasks or perform worse than baseline methods on standard calibration metrics like expected calibration error.
Figures










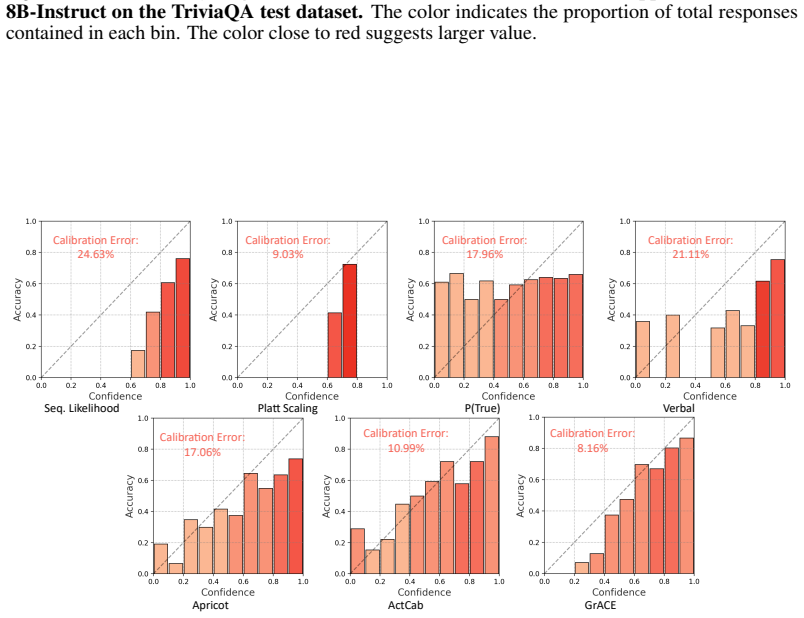
read the original abstract
Assessing the reliability of Large Language Models (LLMs) by confidence elicitation is a prominent approach to AI safety in high-stakes applications, such as healthcare and finance. Existing methods either require expensive computational overhead or suffer from poor calibration, making them impractical and unreliable for real-world deployment. In this work, we propose GrACE, a Generative Approach to Confidence Elicitation that enables scalable and reliable confidence elicitation for LLMs. GrACE adopts a novel mechanism in which the model expresses confidence by the similarity between the last hidden state and the embedding of a special token appended to the vocabulary, in real-time. We fine-tune the model for calibrating the confidence with targets associated with accuracy. Extensive experiments show that the confidence produced by GrACE achieves the best discriminative capacity and calibration on open-ended generation tasks without resorting to additional sampling or an auxiliary model. Moreover, we propose two confidence-based strategies for test-time scaling with GrACE, which not only improve the accuracy of the final decision but also significantly reduce the number of required samples, highlighting its potential as a practical solution for deploying LLMs with reliable, on-the-fly confidence estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GrACE, a generative approach to confidence elicitation for LLMs. A special token is appended to the vocabulary, and confidence is expressed via the similarity between the last hidden state and the special token's embedding. The model is fine-tuned using targets associated with accuracy to calibrate this signal. The central claims are that GrACE achieves the best discriminative capacity and calibration on open-ended generation tasks without additional sampling or an auxiliary model, and that two proposed confidence-based strategies enable improved accuracy with fewer samples during test-time scaling.
Significance. If the empirical claims hold under rigorous validation, the work could offer a low-overhead, real-time confidence mechanism that addresses practical limitations of sampling-based or auxiliary-model approaches in high-stakes LLM deployment. The test-time scaling component adds value by linking confidence directly to efficiency gains. The approach sits outside standard logit or ensemble methods, so confirmation that the learned similarity generalizes beyond training artifacts would strengthen its contribution to uncertainty quantification.
major comments (2)
- [Abstract and §3 (method)] Abstract and fine-tuning description: The claim that fine-tuning on accuracy-associated targets causes the similarity between the last hidden state and the special-token embedding to become a reliable, generalizable confidence proxy is load-bearing. The manuscript does not specify whether the objective is an explicit calibration or ranking loss on the similarity metric itself or merely next-token prediction on accuracy-labeled sequences. Without the former, the similarity risks latching onto dataset-specific patterns rather than epistemic uncertainty, especially on open-ended tasks where accuracy labels are noisy or model-dependent.
- [§4 (experiments)] Experimental evaluation: The abstract asserts 'best discriminative capacity and calibration' on open-ended tasks, yet the provided high-level summary lacks concrete metrics (e.g., AUC, ECE, Brier score), baseline implementations, dataset statistics, or error bars. These details are required to substantiate superiority and to rule out that gains arise from the fine-tuning distribution rather than the proposed similarity mechanism.
minor comments (2)
- [Method] The precise similarity function (cosine or otherwise) and the exact placement of the special token during generation should be formalized with an equation for reproducibility.
- [Method] Clarify whether the special token embedding is learned from scratch or initialized from an existing token; this affects the number of free parameters and the interpretation of the 'parameter-free' aspect of inference-time use.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and have revised the manuscript accordingly to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract and §3 (method)] Abstract and fine-tuning description: The claim that fine-tuning on accuracy-associated targets causes the similarity between the last hidden state and the special-token embedding to become a reliable, generalizable confidence proxy is load-bearing. The manuscript does not specify whether the objective is an explicit calibration or ranking loss on the similarity metric itself or merely next-token prediction on accuracy-labeled sequences. Without the former, the similarity risks latching onto dataset-specific patterns rather than epistemic uncertainty, especially on open-ended tasks where accuracy labels are noisy or model-dependent.
Authors: We appreciate this observation and agree that the precise training objective requires explicit description to support the claim of a generalizable confidence proxy. The GrACE fine-tuning uses next-token prediction on accuracy-labeled sequences where the special token is appended and its generation probability is tied to correctness; however, we acknowledge that this alone may not guarantee the similarity acts as an explicit calibration signal. In the revision we have expanded §3 to detail the full objective (including any auxiliary term on the similarity) and added a new ablation showing that the learned similarity generalizes to held-out tasks beyond the fine-tuning distribution. revision: yes
-
Referee: [§4 (experiments)] Experimental evaluation: The abstract asserts 'best discriminative capacity and calibration' on open-ended tasks, yet the provided high-level summary lacks concrete metrics (e.g., AUC, ECE, Brier score), baseline implementations, dataset statistics, or error bars. These details are required to substantiate superiority and to rule out that gains arise from the fine-tuning distribution rather than the proposed similarity mechanism.
Authors: We agree that concrete metrics, baselines, and statistical details are essential for rigorous validation. The full experimental section already reports AUC, ECE, and Brier scores with comparisons to logit-based, sampling-based, and auxiliary-model baselines, along with dataset sizes and error bars from multiple seeds. To address the concern, we have moved key quantitative results into the abstract, added a table summarizing all metrics with standard deviations, and included an additional ablation that isolates the contribution of the similarity mechanism from the fine-tuning data distribution. revision: yes
Circularity Check
No significant circularity: confidence defined via similarity and calibrated via standard fine-tuning on accuracy targets
full rationale
The derivation introduces a special token whose embedding similarity to the final hidden state serves as the confidence signal, then applies fine-tuning with accuracy-associated targets to align that signal. This constitutes a conventional supervised calibration step rather than a self-definitional loop or a fitted input relabeled as a prediction. No equations or claims reduce the reported discriminative capacity or calibration metrics to quantities that are identical to the training targets by construction. The paper presents empirical results on open-ended generation tasks as external validation, with no load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The method is therefore self-contained against its stated benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- special token embedding
axioms (1)
- domain assumption Fine-tuning on accuracy-associated targets will make similarity to the special-token embedding a reliable proxy for true model confidence.
invented entities (1)
-
special confidence token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Claude 3: A conversational ai model
Anthropic. Claude 3: A conversational ai model. 2024
work page 2024
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
work page 2023
-
[6]
Hallucination-free? assessing the reliability of leading ai legal research tools
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D Manning, and Daniel E Ho. Hallucination-free? assessing the reliability of leading ai legal research tools. arXiv preprint arXiv:2405.20362, 2024
-
[7]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al. Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems, 37:95716–95743, 2024
work page 2024
-
[8]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR, 2017
work page 2017
-
[10]
Calibration of pre-trained transformers
Shrey Desai and Greg Durrett. Calibration of pre-trained transformers. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 295–302, 2020
work page 2020
-
[11]
Large language models are miscalibrated in-context learners
Chengzu Li, Han Zhou, Goran Glavaš, Anna Korhonen, and Ivan Vuli ´c. Large language models are miscalibrated in-context learners. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11575–11596, 2025
work page 2025
-
[12]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Atomic calibration of llms in long-form generations.arXiv preprint arXiv:2410.13246, 2024
Caiqi Zhang, Ruihan Yang, Zhisong Zhang, Xinting Huang, Sen Yang, Dong Yu, and Nigel Collier. Atomic calibration of llms in long-form generations.arXiv preprint arXiv:2410.13246, 2024
-
[14]
Cali- brating large language models using their generations only
Dennis Thomas Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Joon Oh. Cali- brating large language models using their generations only. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 15440–15459. Association for Computational Linguistics, 2024
work page 2024
-
[15]
Large language models must be taught to know what they don’t know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine M Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew Gordon Wilson. Large language models must be taught to know what they don’t know. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. 10
-
[16]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
work page 2023
-
[17]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InThe Twelfth International Conference on Learning Representations
-
[18]
Linguistic calibration of long- form generations
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long- form generations. InProceedings of the 41st International Conference on Machine Learning, pages 2732–2778, 2024
work page 2024
-
[19]
Logu: Long-form generation with uncertainty expressions.arXiv preprint arXiv:2410.14309, 2024
Ruihan Yang, Caiqi Zhang, Zhisong Zhang, Xinting Huang, Sen Yang, Nigel Collier, Dong Yu, and Deqing Yang. Logu: Long-form generation with uncertainty expressions.arXiv preprint arXiv:2410.14309, 2024
-
[20]
Uncle: Uncertainty expressions in long-form generation.arXiv preprint arXiv:2505.16922, 2025
Ruihan Yang, Caiqi Zhang, Zhisong Zhang, Xinting Huang, Dong Yu, Nigel Collier, and Deqing Yang. Uncle: Uncertainty expressions in long-form generation.arXiv preprint arXiv:2505.16922, 2025
-
[21]
Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, Pascale Fung, and Nicola Cancedda. Calibrating verbal uncertainty as a linear feature to reduce hallucinations.arXiv preprint arXiv:2503.14477, 2025
-
[22]
Lora: Low-rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations
-
[23]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations
-
[24]
Get confused cautiously: Textual sequence memorization erasure with selective entropy maximization
Zhaohan Zhang, Ziquan Liu, and Ioannis Patras. Get confused cautiously: Textual sequence memorization erasure with selective entropy maximization. InProceedings of the 31st Interna- tional Conference on Computational Linguistics, pages 10924–10939, 2025
work page 2025
-
[25]
Benjamin Plaut, Khanh Nguyen, and Tu Trinh. Softmax probabilities (mostly) predict large language model correctness on multiple-choice q&a.arXiv e-prints, pages arXiv–2402, 2024
work page 2024
-
[26]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InThe 2023 Conference on Empirical Methods in Natural Language Processing
work page 2023
-
[27]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Enhancing language model factuality via activation- based confidence calibration and guided decoding
Xin Liu, Farima Fatahi Bayat, and Lu Wang. Enhancing language model factuality via activation- based confidence calibration and guided decoding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10436–10448, 2024
work page 2024
-
[29]
Sophia Hager, David Mueller, Kevin Duh, and Nicholas Andrews. Uncertainty distillation: Teaching language models to express semantic confidence.arXiv preprint arXiv:2503.14749, 2025
-
[30]
Roi Cohen, Konstantin Dobler, Eden Biran, and Gerard de Melo. I don’t know: Explicit modeling of uncertainty with an [idk] token.Advances in Neural Information Processing Systems, 37:10935–10958, 2024
work page 2024
-
[31]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations
-
[33]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning
Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Xinglin Wang, Bin Sun, Heda Wang, and Kan Li. Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning. In The Twelfth International Conference on Learning Representations
-
[36]
Let’s sample step by step: Adaptive- consistency for efficient reasoning and coding with llms
Pranjal Aggarwal, Aman Madaan, Yiming Yang, et al. Let’s sample step by step: Adaptive- consistency for efficient reasoning and coding with llms. InThe 2023 Conference on Empirical Methods in Natural Language Processing
work page 2023
-
[37]
Seungone Kim, Ian Wu, Jinu Lee, Xiang Yue, Seongyun Lee, Mingyeong Moon, Kiril Gash- teovski, Carolin Lawrence, Julia Hockenmaier, Graham Neubig, et al. Scaling evaluation-time compute with reasoning models as process evaluators.arXiv preprint arXiv:2503.19877, 2025
-
[38]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023
work page 2023
-
[39]
Confidence improves self-consistency in llms.arXiv preprint arXiv:2502.06233, 2025
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence improves self-consistency in llms.arXiv preprint arXiv:2502.06233, 2025
-
[40]
Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025
Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, and Jiaxin Huang. Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025
-
[41]
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence.arXiv preprint arXiv:2508.15260, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. In The Twelfth International Conference on Learning Representations
-
[43]
Guiding language model reasoning with planning tokens
Xinyi Wang, Lucas Caccia, Oleksiy Ostapenko, Xingdi Yuan, William Yang Wang, and Alessan- dro Sordoni. Guiding language model reasoning with planning tokens. InFirst Conference on Language Modeling
-
[44]
Calibrated structured prediction.Advances in Neural Information Processing Systems, 28, 2015
V olodymyr Kuleshov and Percy S Liang. Calibrated structured prediction.Advances in Neural Information Processing Systems, 28, 2015
work page 2015
-
[45]
Uncertainty estimation in autoregressive structured prediction
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. InInternational Conference on Learning Representations
-
[46]
John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers, 10(3):61–74, 1999
work page 1999
-
[47]
Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling. InThe 2025 Annual Conference of the Nations of the Americas Chapter of the ACL, 2025
work page 2025
-
[48]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017. 12
work page 2017
-
[49]
Crowdsourcing multiple choice science questions
Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. InProceedings of the 3rd Workshop on Noisy User-generated Text, pages 94–106, 2017
work page 2017
-
[50]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
work page 2004
-
[51]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InProceedings of the AAAI conference on artificial intelligence, volume 29, 2015
work page 2015
-
[55]
Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3, 1950
Glenn W Brier. Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3, 1950
work page 1950
-
[56]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Mathqa: Towards interpretable math word problem solving with operation-based formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and ...
work page 2019
-
[58]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[59]
Hexiang Tan, Fei Sun, Sha Liu, Du Su, Qi Cao, Xin Chen, Jingang Wang, Xunliang Cai, Yuanzhuo Wang, Huawei Shen, et al. Too consistent to detect: A study of self-consistent errors in llms.arXiv preprint arXiv:2505.17656, 2025. 13 A Implementation Details A.1 Prompt Template We elaborate on the prompt templates used for open-ended generation and test-time s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.