Autoguided Online Data Curation for Diffusion Model Training
Pith reviewed 2026-05-21 21:56 UTC · model grok-4.3
The pith
Autoguidance consistently improves sample quality and diversity in diffusion model training while online data selection adds overhead that often makes it less practical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
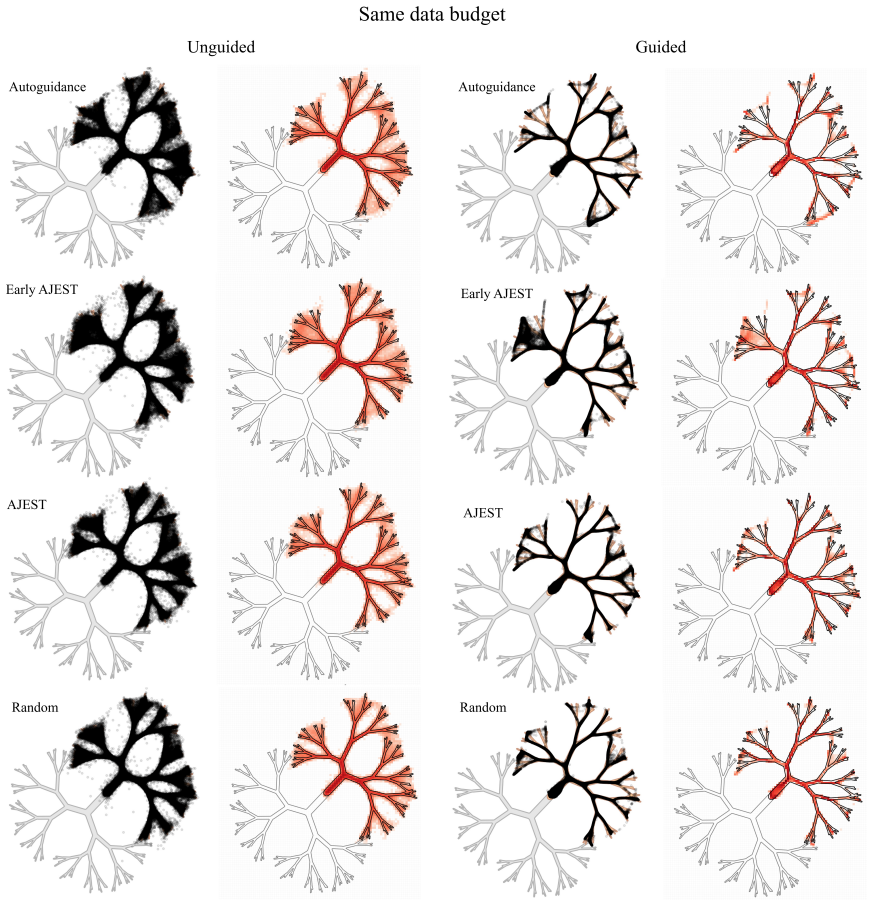
The paper establishes that autoguidance delivers consistent gains in sample quality and diversity for diffusion models. Early AJEST, which applies selection only at the start of training, can reach or slightly exceed the data efficiency of autoguidance alone on both the 2D and image tasks. Yet the added time overhead and complexity of selection mean autoguidance by itself or uniform random sampling tends to be preferable in equal-time comparisons. The findings point to autoguidance as the main driver of robust quality improvements, with targeted online selection offering efficiency mainly in early training stages.
What carries the argument
Autoguidance paired with early joint example selection (AJEST) for online batch curation, evaluated under equal wall-clock time and sample budgets that include selection costs.
If this is right
- Autoguidance raises sample quality and diversity without needing extra selection machinery.
- Early AJEST can match or modestly beat autoguidance on data efficiency for both synthetic and image tasks.
- Time and complexity costs of online selection make autoguidance or random sampling preferable in most equal-time settings.
- Robust quality gains trace primarily to autoguidance rather than the selection process itself.
- Targeted online selection may help only during the initial phase of training for efficiency.
Where Pith is reading between the lines
- The results suggest that simplifying selection pipelines or lowering their overhead could make AJEST competitive in more scenarios.
- Similar autoguidance methods might transfer to other generative architectures beyond diffusion models.
- Scaling the experiments to larger models and datasets would test whether the current preference for simplicity holds at higher compute levels.
Load-bearing premise
The assumption that controlled 2D synthetic data and 64 by 64 image generation, compared at equal wall-clock time while counting selection overhead, represent the benefits and costs of data curation in practical high-dimensional generative training.
What would settle it
Running the same equal-time comparisons on a higher-resolution dataset such as 256 by 256 images and checking whether AJEST overhead shrinks relative to its efficiency gains or whether quality diverges further from autoguidance alone.
Figures











read the original abstract
The costs of generative model compute rekindled promises and hopes for efficient data curation. In this work, we investigate whether recently developed autoguidance and online data selection methods can improve the time and sample efficiency of training generative diffusion models. We integrate joint example selection (JEST) and autoguidance into a unified code base for fast ablation and benchmarking. We evaluate combinations of data curation on a controlled 2-D synthetic data generation task as well as (3x64x64)-D image generation. Our comparisons are made at equal wall-clock time and equal number of samples, explicitly accounting for the overhead of selection. Across experiments, autoguidance consistently improves sample quality and diversity. Early AJEST (applying selection only at the beginning of training) can match or modestly exceed autoguidance alone in data efficiency on both tasks. However, its time overhead and added complexity make autoguidance or uniform random data selection preferable in most situations. These findings suggest that while targeted online selection can yield efficiency gains in early training, robust sample quality improvements are primarily driven by autoguidance. We discuss limitations and scope, and outline when data selection may be beneficial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoguidance improves sample quality and diversity in diffusion model training, while early AJEST offers data efficiency gains but is less practical due to overhead. This is shown through equal wall-clock time and equal-sample comparisons on 2D synthetic and 64x64 image tasks, accounting for selection costs, leading to the recommendation of autoguidance or random selection in most cases.
Significance. Should the findings generalize, this study offers practical insights into balancing autoguidance and data selection for efficient diffusion training. The unified implementation for ablations and the fair equal-time comparisons are positive aspects. It underscores that quality improvements are mainly from autoguidance, with selection benefits limited to early training, aiding researchers in choosing methods for compute-constrained settings.
major comments (2)
- §4 (Experimental Evaluation): The central preference ordering (autoguidance or random selection over early AJEST due to overhead) rests on measurements from the 2-D synthetic task and (3x64x64) image generation. The assumption that selection forward-pass overhead scales similarly relative to training compute may not hold at higher resolutions where diffusion steps dominate, which is load-bearing for the claim that AJEST's added complexity makes it less preferable in most situations.
- §4: The abstract and results describe clear outcomes for quality/diversity but provide insufficient detail on exact metrics, statistical tests, error bars, or full baseline implementations. This weakens the support for the 'consistently improves' claim and the cross-task conclusions.
minor comments (2)
- Abstract: The description of the two tasks could explicitly note the dimensions (2-D synthetic and 3x64x64) at the outset for quicker reader orientation.
- Methods: Acronyms such as AJEST should be expanded on first use to improve accessibility for readers new to the JEST/autoguidance literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating where revisions have been made to improve transparency and acknowledge limitations.
read point-by-point responses
-
Referee: §4 (Experimental Evaluation): The central preference ordering (autoguidance or random selection over early AJEST due to overhead) rests on measurements from the 2-D synthetic task and (3x64x64) image generation. The assumption that selection forward-pass overhead scales similarly relative to training compute may not hold at higher resolutions where diffusion steps dominate, which is load-bearing for the claim that AJEST's added complexity makes it less preferable in most situations.
Authors: We agree that the relative overhead of selection forward passes may decrease at higher resolutions where diffusion steps dominate the compute budget. Our equal wall-clock time comparisons explicitly measure and account for this overhead in the 2D and 64x64 regimes tested, supporting the observed preference ordering there. To address the scaling concern, we have added a dedicated paragraph in the revised discussion section acknowledging this as a limitation and noting that the recommendation applies primarily to the evaluated compute regimes, with future higher-resolution studies needed to confirm generalization. revision: partial
-
Referee: §4: The abstract and results describe clear outcomes for quality/diversity but provide insufficient detail on exact metrics, statistical tests, error bars, or full baseline implementations. This weakens the support for the 'consistently improves' claim and the cross-task conclusions.
Authors: We appreciate this observation and have revised Section 4 to include precise metric definitions (FID, precision/recall, and diversity measures for images; Wasserstein distance for 2D), error bars as standard deviations over 3-5 runs, and full baseline implementation details including how autoguidance and AJEST are unified in the codebase. We now also report results of paired t-tests to support statistical significance of the consistent improvements from autoguidance across tasks. revision: yes
Circularity Check
Empirical ablation study with no derivation chain or self-referential reductions
full rationale
The paper reports experimental comparisons of autoguidance and online selection (JEST/AJEST) on a 2-D synthetic task and 64x64 image generation, measuring quality/diversity at equal wall-clock time and equal sample counts while accounting for selection overhead. All central claims are direct outcomes of these controlled runs rather than any first-principles derivation, fitted parameter renamed as prediction, or self-citation that bears the load of the result. No equations or theoretical steps are presented that could reduce to their own inputs by construction; the work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 2-D synthetic task and 64x64 image generation task are representative proxies for evaluating data curation efficiency in diffusion models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across experiments, autoguidance consistently improves sample quality and diversity. Early AJEST ... can match or modestly exceed autoguidance alone in data efficiency ... its time overhead and added complexity make autoguidance or uniform random data selection preferable in most situations.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Contextual diversity for active learning
Sharat Agarwal, Himanshu Arora, Saket Anand, and Chetan Arora. Contextual diversity for active learning. InComputer Vision – ECCV 2020: 16th European Conference, Glas- gow, UK, August 23–28, 2020, Proceedings, Part XVI, page 137–153, Berlin, Heidelberg, 2020. Springer-Verlag. 1
work page 2020
-
[2]
Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal
Jordan T. Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learn- ing by diverse, uncertain gradient lower bounds. InInterna- tional Conference on Learning Representations, 2020. 1
work page 2020
-
[3]
M ¨uller, L´aszl´o N ´emeth, Luis Oala, Lennart Purucker, Sahithya Ravi, Jan N
Bernd Bischl, Giuseppe Casalicchio, Taniya Das, Matthias Feurer, Sebastian Fischer, Pieter Gijsbers, Subhaditya Mukherjee, Andreas C. M ¨uller, L´aszl´o N ´emeth, Luis Oala, Lennart Purucker, Sahithya Ravi, Jan N. van Rijn, Prabhant Singh, Joaquin Vanschoren, Jos van der Velde, and Marcel Wever. Openml: Insights from 10 years and more than a thousand pape...
work page 2025
-
[4]
Data pruning in generative diffusion models, 2025
Rania Briq, Jiangtao Wang, and Stefan Kesselheim. Data pruning in generative diffusion models, 2025. 1
work page 2025
-
[5]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2829, 2023. 1
work page 2023
-
[6]
Selection via proxy: Efficient data se- lection for deep learning
Cody Coleman, Christopher Yeh, Stephen Mussmann, Baha- ran Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via proxy: Efficient data se- lection for deep learning. InInternational Conference on Learning Representations, 2020. 1
work page 2020
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 11
work page 2009
-
[8]
Data curation via joint example selec- tion further accelerates multimodal learning
Talfan Evans, Nikhil Parthasarathy, Hamza Merzic, and Olivier J Henaff. Data curation via joint example selec- tion further accelerates multimodal learning. InThe Thirty- eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. 1, 2, 5
work page 2024
-
[9]
What neural networks memorize and why: Discovering the long tail via influence estimation
Vitaly Feldman and Chiyuan Zhang. What neural networks memorize and why: Discovering the long tail via influence estimation. InAdvances in Neural Information Processing Systems, pages 2881–2891. Curran Associates, Inc., 2020. 1
work page 2020
-
[10]
Lipton, Aditi Raghunathan, and J
Sachin Goyal, Pratyush Maini, Zachary C. Lipton, Aditi Raghunathan, and J. Zico Kolter. Scaling laws for data filtering– data curation cannot be compute agnostic. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22702–22711, 2024. 1
work page 2024
-
[11]
Co- teaching: Robust training of deep neural networks with ex- tremely noisy labels
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co- teaching: Robust training of deep neural networks with ex- tremely noisy labels. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2018. 1
work page 2018
-
[12]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InAdvances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2017. 3, 10
work page 2017
-
[13]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. 1, 2
work page 2022
-
[14]
Vision transformers in 2022: An update on tiny imagenet, 2022
Ethan Huynh. Vision transformers in 2022: An update on tiny imagenet, 2022. 3, 10, 11
work page 2022
-
[15]
MentorNet: Learning data-driven curriculum for very deep neural networks on corrupted labels
Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. MentorNet: Learning data-driven curriculum for very deep neural networks on corrupted labels. InProceed- ings of the 35th International Conference on Machine Learn- ing, pages 2304–2313. PMLR, 2018. 1
work page 2018
-
[16]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. 1
work page 2020
-
[17]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Samuli Laine, and Timo Aila. Elucidating the design space of diffusion-based generative models. InProceedings of the 36th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2022. Curran Associates Inc. 2, 1
work page 2022
-
[18]
Guiding a diffusion model with a bad version of itself
Tero Karras, Miika Aittala, Tuomas Kynk ¨a¨anniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. InAdvances in Neural In- formation Processing Systems, pages 52996–53021. Curran Associates, Inc., 2024. 1, 2, 3, 5, 10
work page 2024
-
[19]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24174–24184, 2024. 2, 3, 10
work page 2024
-
[20]
Ya Le and Xuan S. Yang. Tiny imagenet classification with convolutional neural networks. Course Project Report Win- ter Quarter 2015, Stanford University, CS231n: Convolu- tional Neural Networks for Visual Recognition, 2015. Un- published student project, available online. 3, 2, 11
work page 2015
-
[21]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 9992–10002, 2021. 10
work page 2021
-
[22]
Coresets for data-efficient training of machine learning mod- els
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning mod- els. InProceedings of the 37th International Conference on Machine Learning, pages 6950–6960. PMLR, 2020. 1
work page 2020
-
[23]
Tiny imagenet (mn- moustafa version) on kaggle.https://kaggle.com/ competitions/tiny- imagenet, 2017
mnmoustafa and Mohammed Ali. Tiny imagenet (mn- moustafa version) on kaggle.https://kaggle.com/ competitions/tiny- imagenet, 2017. Accessed: 2025-08-24. 11
work page 2017
-
[24]
Luis Oala, Manil Maskey, Lilith Bat-Leah, Alicia Par- rish, Nezihe Merve G ¨urel, Tzu-Sheng Kuo, Yang Liu, 5 Rotem Dror, Danilo Brajovic, Xiaozhe Yao, Max Bartolo, William A Gaviria Rojas, Ryan Hileman, Rainier Aliment, Michael W. Mahoney, Meg Risdal, Matthew Lease, Woj- ciech Samek, Debojyoti Dutta, Curtis G Northcutt, Cody Coleman, Braden Hancock, Berna...
work page 2024
-
[25]
Repeated random sampling for minimizing the time-to-accuracy of learning
Patrik Okanovic, Roger Waleffe, Vasilis Mageirakos, Kon- stantinos Nikolakakis, Amin Karbasi, Dionysios Kalogerias, Nezihe Merve G ¨urel, and Theodoros Rekatsinas. Repeated random sampling for minimizing the time-to-accuracy of learning. InThe Twelfth International Conference on Learn- ing Representations, 2024. 1, 3
work page 2024
-
[26]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patr...
work page 2024
-
[27]
Deep learning on a data diet: Finding important ex- amples early in training
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziu- gaite. Deep learning on a data diet: Finding important ex- amples early in training. InAdvances in Neural Information Processing Systems, pages 20596–20607. Curran Associates, Inc., 2021. 1
work page 2021
-
[28]
Adaptive second order coresets for data-efficient machine learning
Omead Pooladzandi, David Davini, and Baharan Mirza- soleiman. Adaptive second order coresets for data-efficient machine learning. InProceedings of the 39th Interna- tional Conference on Machine Learning, pages 17848– 17869. PMLR, 2022. 1
work page 2022
-
[29]
Active learning for convolu- tional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolu- tional neural networks: A core-set approach. InInternational Conference on Learning Representations, 2018. 1
work page 2018
-
[30]
Loss-curvature matching for dataset selection and condensation
Seungjae Shin, Heesun Bae, Donghyeok Shin, Weonyoung Joo, and Il-Chul Moon. Loss-curvature matching for dataset selection and condensation. InProceedings of The 26th In- ternational Conference on Artificial Intelligence and Statis- tics, pages 8606–8628. PMLR, 2023. 1
work page 2023
-
[31]
Beyond neural scaling laws: beat- ing power law scaling via data pruning
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beat- ing power law scaling via data pruning. InAdvances in Neu- ral Information Processing Systems, pages 19523–19536. Curran Associates, Inc., 2022. 1
work page 2022
-
[32]
George Stein, Jesse Cresswell, Rasa Hosseinzadeh, Yi Sui, Brendan Ross, Valentin Villecroze, Zhaoyan Liu, Anthony L Caterini, Eric Taylor, and Gabriel Loaiza-Ganem. Exposing flaws of generative model evaluation metrics and their un- fair treatment of diffusion models. InAdvances in Neural Information Processing Systems, pages 3732–3784. Curran Associates,...
work page 2023
-
[33]
Rethinking the inception ar- chitecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception ar- chitecture for computer vision. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826, 2016. 10
work page 2016
-
[34]
Data pruning via moving-one- sample-out
Haoru Tan, Sitong Wu, Fei Du, Yukang Chen, Zhibin Wang, Fan Wang, and Xiaojuan Qi. Data pruning via moving-one- sample-out. InProceedings of the 37th International Confer- ence on Neural Information Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 1
work page 2023
-
[35]
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J. Gordon. An empirical study of example forgetting during deep neural network learning. InInternational Conference on Learning Representations, 2019. 1
work page 2019
-
[36]
Vishaal Udandarao, Nikhil Parthasarathy, Muhammad Fer- jad Naeem, Talfan Evans, Samuel Albanie, Federico Tombari, Yongqin Xian, Alessio Tonioni, and Olivier J. H´enaff. Active data curation effectively distills large-scale multimodal models, 2025. Accepted for the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition 2025 to be hosted in June 2...
work page 2025
-
[37]
Moderate coreset: A universal method of data selection for real-world data-efficient deep learning
Xiaobo Xia, Jiale Liu, Jun Yu, Xu Shen, Bo Han, and Tongliang Liu. Moderate coreset: A universal method of data selection for real-world data-efficient deep learning. In The Eleventh International Conference on Learning Repre- sentations, 2023. 1
work page 2023
-
[38]
Tiny imagenet (zh-plus version) on hugging face
zh plus. Tiny imagenet (zh-plus version) on hugging face. https://huggingface.co/datasets/zh-plus/ tiny-imagenet, 2025. Accessed: 2025-08-19. 3, 2, 11 6 Autoguided Online Data Curation for Diffusion Model Training Supplementary Material A. Implementation details A.1. JEST data selection Joint example selection (JEST) samples training examples based on a l...
work page 2025
-
[39]
The(s 11, ..., sBB )diagonal scores that feed the same datapoint to both the learner and the reference models
-
[40]
The sums of scores( P k∈K sk1, ...,P k∈K skB )that re- sult from only considering the selected datapoints fed into the learner model
-
[41]
The sums of scores( P k∈K s1k, ...,P k∈K sBk )that re- sult from only considering the selected datapoints fed into the reference model
-
[42]
A penalizing term whose elements are−10 8 for all se- lected datapoints inKand 0 for unselected datapoints. Figure 5. Iterative sampling process for JEST data selection. Our code implementation follows quite closely the one published by Evans et al [8]. However, we observed that a softmax distribution applied directly to thesezlogits is highly unstable. F...
-
[43]
We trained on a single NVIDIA A5000 GPU
We then independently trained a larger main model with hidden dimension 64 for 4096 iterations. We trained on a single NVIDIA A5000 GPU. In this setup, a no-selection baseline could be trained for 4096 iterations in approxi- mately 23 minutes; Full AJEST increased this to≈36min- utes, while Early AJEST added only≈38seconds over baseline. We store models e...
-
[44]
and DINOv2 [26] to extract image features. We com- pare these features to those obtained with the same models applied to all images from Tiny ImageNet’s training dataset. Classification-based evaluation.To avoid any biases im- posed by the use of a single family of metrics, we apply a pretrained classifier to the same 2000 generated images and calculate t...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.