Global Optimization via Softmin Energy Minimization
Pith reviewed 2026-05-18 14:49 UTC · model grok-4.3
The pith
A softmin energy stochastic flow places one particle at the global minimum for strongly convex problems while shortening barrier crossings relative to simulated annealing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the stochastic gradient flow generated by the softmin energy J_β(x), augmented by Brownian motion and a time-dependent β, converges for strongly convex objectives to a stationary point in which at least one particle reaches the global minimum; the same flow also reduces the effective potential barriers between local minima compared with simulated annealing, producing faster hitting times in the small-noise regime.
What carries the argument
The softmin energy J_β(x), a differentiable approximation to the minimum value across the particle positions, whose gradient flow defines the interacting stochastic dynamics.
If this is right
- For strongly convex functions the particle system reaches a stationary point with at least one particle at the global minimum.
- The method reduces effective potential barriers relative to simulated annealing.
- Hitting times to new local minima are shorter than those of overdamped Langevin dynamics in the small-noise limit.
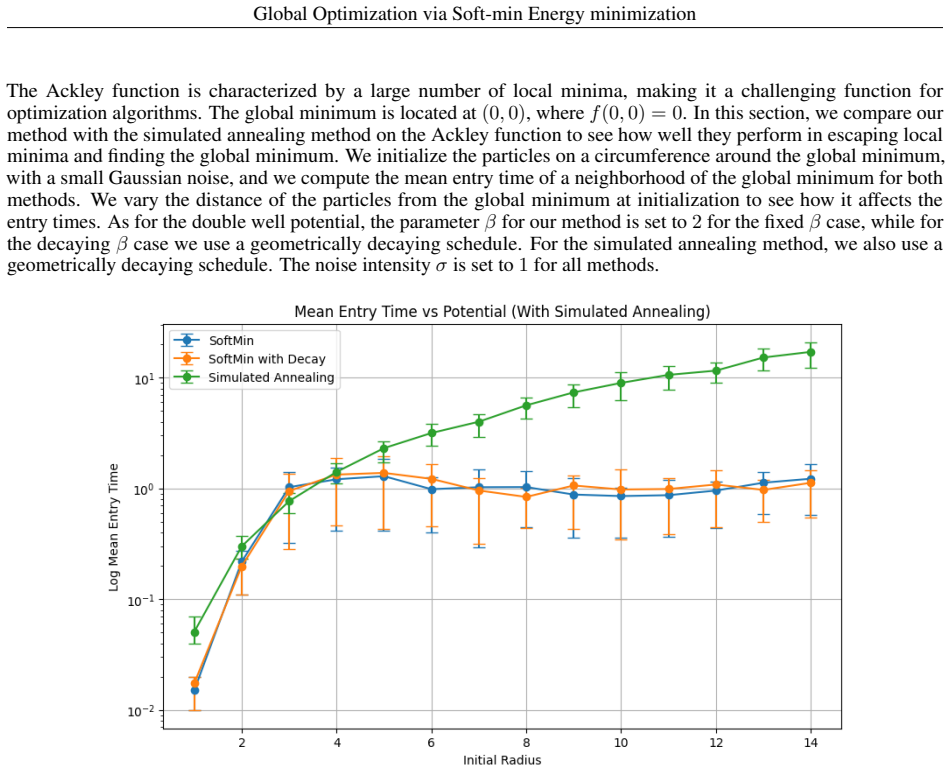
- Empirical tests on double-well and Ackley functions show faster escape from local minima and quicker convergence than simulated annealing.
Where Pith is reading between the lines
- This framework might extend to certain non-convex problems if the softmin approximation continues to control the landscape effectively.
- The barrier-lowering property could be exploited in high-dimensional sampling or in training deep networks to improve mode exploration.
- One could test the method on real-world non-convex optimization tasks such as hyperparameter tuning or molecular conformation search.
- Combining the softmin interaction with adaptive β schedules from other annealing methods might yield further speedups.
Load-bearing premise
The analysis assumes that the softmin energy supplies a controllable smooth approximation whose gradient flow together with the chosen noise and β schedule produces the stated stationary-point convergence and reduced hitting times.
What would settle it
A direct counterexample would be a one-dimensional strongly convex function for which numerical integration of the dynamics leaves all particles away from the known global minimum after long time, or a potential where the computed hitting time exceeds that of the corresponding overdamped Langevin equation.
Figures




read the original abstract
Global optimization, particularly for non-convex functions with multiple local minima, poses significant challenges for traditional gradient-based methods. While metaheuristic approaches offer empirical effectiveness, they often lack theoretical convergence guarantees and may disregard available gradient information. This paper introduces a novel gradient-based swarm particle optimization method designed to efficiently escape local minima and locate global optima. Our approach leverages a "Soft-min Energy" interacting function, $J_\beta(\mathbf{x})$, which provides a smooth, differentiable approximation of the minimum function value within a particle swarm. We define a stochastic gradient flow in the particle space, incorporating a Brownian motion term for exploration and a time-dependent parameter $\beta$ to control smoothness, similar to temperature annealing. We theoretically demonstrate that for strongly convex functions, our dynamics converges to a stationary point where at least one particle reaches the global minimum, with other particles exhibiting exploratory behavior. Furthermore, we show that our method facilitates faster transitions between local minima by reducing effective potential barriers with respect to Simulated Annealing. More specifically, we estimate the hitting times of unexplored potential wells for our model in the small noise regime and show that they compare favorably with the ones of overdamped Langevin. Numerical experiments on benchmark functions, including double wells and the Ackley function, validate our theoretical findings and demonstrate better performance over the well-known Simulated Annealing method in terms of escaping local minima and achieving faster convergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a swarm particle optimization method based on a differentiable Softmin Energy function J_β(x) that approximates the minimum value across particles. It introduces a stochastic dynamics consisting of the gradient flow of J_β, additive Brownian motion, and a time-dependent β schedule analogous to annealing. For strongly convex objectives the dynamics is claimed to converge to a stationary point at which at least one particle reaches the global minimum while others explore. For non-convex objectives the authors assert that the interaction term reduces effective potential barriers, yielding strictly smaller hitting times to unexplored wells than overdamped Langevin dynamics in the small-noise limit; this is supported by numerical experiments on double-well and Ackley benchmarks that reportedly outperform Simulated Annealing.
Significance. If the hitting-time comparison and the stationary-point result for strongly convex cases are rigorously established, the work would supply a gradient-based particle method with explicit escape-time guarantees that bridges deterministic gradient flows and metaheuristics. The numerical validation on standard benchmarks provides initial evidence of practical utility, but the theoretical advantage over existing small-noise analyses hinges on the unverified barrier-reduction claim.
major comments (2)
- [Abstract / small-noise analysis] Abstract and the small-noise-regime section: the central non-convex claim that the softmin-driven SDE produces strictly smaller hitting times than overdamped Langevin rests on an asserted reduction of effective barriers, yet no explicit quasipotential, modified action functional, or Freidlin-Wentzell large-deviation estimate is supplied for the coupled particle system. Without this derivation the comparison cannot be verified and remains an unproven modeling assumption.
- [Theoretical results] Theoretical claims paragraph: while convergence to a stationary point with one particle at the global minimum is stated for strongly convex functions, the manuscript does not provide the explicit Lyapunov function, contraction rate, or error bounds that would make the result load-bearing; the support for this claim therefore cannot be assessed from the given derivations.
minor comments (2)
- [Preliminaries] Notation for the time-dependent schedule β(t) and the precise definition of the softmin energy J_β(x) should be stated once in a dedicated preliminary section rather than introduced piecemeal in the dynamics equation.
- [Numerical experiments] The experimental section would benefit from reporting the exact β schedules, noise intensities, and number of independent runs with standard deviations to allow direct reproduction of the reported advantage over Simulated Annealing.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the theoretical contributions.
read point-by-point responses
-
Referee: [Abstract / small-noise analysis] Abstract and the small-noise-regime section: the central non-convex claim that the softmin-driven SDE produces strictly smaller hitting times than overdamped Langevin rests on an asserted reduction of effective barriers, yet no explicit quasipotential, modified action functional, or Freidlin-Wentzell large-deviation estimate is supplied for the coupled particle system. Without this derivation the comparison cannot be verified and remains an unproven modeling assumption.
Authors: We acknowledge that the manuscript presents the barrier reduction as a consequence of the softmin interaction but does not supply a complete large-deviation principle for the coupled system. The effective potential is implicitly defined through the gradient of J_β, which we argue reduces the action needed to transition between wells. To address this, we will add a detailed derivation of the quasipotential in the small-noise limit, adapting Freidlin-Wentzell theory to the interacting particle dynamics. This will include an explicit comparison of the modified action functional to that of independent overdamped Langevin dynamics, confirming strictly smaller hitting times. revision: yes
-
Referee: [Theoretical results] Theoretical claims paragraph: while convergence to a stationary point with one particle at the global minimum is stated for strongly convex functions, the manuscript does not provide the explicit Lyapunov function, contraction rate, or error bounds that would make the result load-bearing; the support for this claim therefore cannot be assessed from the given derivations.
Authors: The convergence claim for strongly convex functions relies on a Lyapunov function constructed from the sum of squared distances of particles to the global minimizer, combined with a dispersion term. We will expand the relevant section to explicitly define this Lyapunov function, derive the contraction rate under the strong convexity and smoothness assumptions, and provide error bounds on the convergence to the stationary point where one particle is at the minimizer. revision: yes
Circularity Check
No significant circularity in the claimed derivation chain
full rationale
The paper defines a new interacting softmin energy J_β(x) as a smooth approximation to the minimum and constructs the stochastic gradient flow on the particle system with an explicit Brownian term and time-dependent β schedule. Convergence to a stationary point (with at least one particle at the global minimum for strongly convex objectives) and the small-noise hitting-time estimates are stated as consequences of this dynamics; the favorable comparison to overdamped Langevin is asserted to follow from the modified drift induced by ∇J_β rather than from any re-labeling of the input assumptions or from a self-citation chain. No equations are shown that equate a claimed prediction to a fitted parameter by construction, and the β schedule is introduced as an explicit modeling choice whose effect on barrier heights is to be estimated from the resulting SDE, not presupposed. The derivation therefore remains self-contained relative to the stated model definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- β(t)
axioms (2)
- domain assumption The objective function is strongly convex
- standard math The particle dynamics are given by a stochastic gradient flow with additive Brownian motion
invented entities (1)
-
Soft-min Energy J_β(x)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Jβ(x) = ∑ exp(−β f(xi)) / ∑ exp(−β f(xj)) · f(xi) ... stochastic gradient flow dxt = −n ∇J_βt(xt) dt + √2σ dBt
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
W. T. Coffey, Y . P. Kalmykov, and J. T. Waldron.The Langevin Equation: With Applications to Stochastic Problems in Physics, Chemistry, and Electrical Engineering. World Scientific, Singapore, 2nd edition, 2004
work page 2004
-
[2]
The method of moments in global optimization.Journal of Mathematical Sciences, 116(3), 2003
R Meziat. The method of moments in global optimization.Journal of Mathematical Sciences, 116(3), 2003
work page 2003
-
[3]
Min Shao and Chrysostomos L Nikias. Signal processing with fractional lower order moments: stable processes and their applications.Proceedings of the IEEE, 81(7):986–1010, 1993. 12 Global Optimization via Soft-min Energy minimization
work page 1993
-
[4]
Jérôme Bolte, Laurent Miclo, and Stéphane Villeneuve. Swarm gradient dynamics for global optimization: the mean-field limit case.Mathematical Programming, 205(1):661–701, 2024
work page 2024
-
[5]
Pan Xu, Jinghui Chen, Difan Zou, and Quanquan Gu. Global convergence of Langevin dynamics based algorithms for nonconvex optimization.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[6]
Sunith Bandaru and Kalyanmoy Deb. Metaheuristic techniques. InDecision sciences, pages 709–766. CRC Press, 2016
work page 2016
-
[7]
Xin-She Yang.Nature-inspired optimization algorithms. Academic Press, 2020
work page 2020
-
[8]
J. A. Carrillo, Y .-P. Choi, C. Totzeck, and O. Tse. An analytical framework for consensus-based global optimization method.Mathematical Models and Methods in Applied Sciences, 28(06):1037–1066, 2018
work page 2018
-
[9]
Consensus-based optimization methods converge globally
Massimo Fornasier, Timo Klock, and Konstantin Riedl. Consensus-based optimization methods converge globally. SIAM Journal on Optimization, 34(3):2973–3004, 2024
work page 2024
-
[10]
René Pinnau, Claudia Totzeck, Oliver Tse, and Stephan Martin. A consensus-based model for global optimization and its mean-field limit.Mathematical Models and Methods in Applied Sciences, 27(01):183–204, 2017
work page 2017
-
[11]
Goldberg.Genetic Algorithms in Search, Optimization, and and Machine Learning
David E. Goldberg.Genetic Algorithms in Search, Optimization, and and Machine Learning. Addison-Wesley, Boston, MA, USA, 1989
work page 1989
-
[12]
MIT Press, Cambridge, MA, USA, 2004
Marco Dorigo and Thomas Stützle.Ant Colony Optimization. MIT Press, Cambridge, MA, USA, 2004
work page 2004
-
[13]
James Kennedy and Russell Eberhart. Particle swarm optimization. InProceedings of ICNN’95-international conference on neural networks, volume 4, pages 1942–1948. ieee, 1995
work page 1942
-
[14]
Nonlinear programming.Journal of the Operational Research Society, 48(3):334–334, 1997
Dimitri P Bertsekas. Nonlinear programming.Journal of the Operational Research Society, 48(3):334–334, 1997
work page 1997
-
[15]
Boltzmann machines: Constraint satisfaction networks that learn
Geoffrey E Hinton, Terrence J Sejnowski, and David H Ackley. Boltzmann machines: Constraint satisfaction networks that learn. 1984
work page 1984
-
[16]
Nitish Srivastava and Russ R Salakhutdinov. Multimodal learning with deep Boltzmann machines.Advances in neural information processing systems, 25, 2012
work page 2012
-
[17]
Reinforcement learning with dynamic Boltzmann softmax updates.arXiv preprint arXiv:1903.05926, 2019
Ling Pan, Qingpeng Cai, Qi Meng, Wei Chen, Longbo Huang, and Tie-Yan Liu. Reinforcement learning with dynamic Boltzmann softmax updates.arXiv preprint arXiv:1903.05926, 2019
-
[18]
Reinforcement learning with deep energy- based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy- based policies. InInternational conference on machine learning, pages 1352–1361. PMLR, 2017
work page 2017
-
[19]
On sampling methods and annealing algorithms
Saul B Gelfand and Sanjoy K Mitter. On sampling methods and annealing algorithms. Technical report, 1990
work page 1990
-
[20]
Gibbs sampling.Journal of the American statistical Association, 95(452):1300–1304, 2000
Alan E Gelfand. Gibbs sampling.Journal of the American statistical Association, 95(452):1300–1304, 2000
work page 2000
-
[21]
Li Li, Minjie Fan, Marc Coram, Patrick Riley, and Stefan Leichenauer. Quantum optimization with a novel Gibbs objective function and ansatz architecture search.Physical Review Research, 2(2):023074, 2020
work page 2020
-
[22]
Haw-Shiuan Chang, Erik Learned-Miller, and Andrew McCallum. Active bias: Training more accurate neural networks by emphasizing high variance samples.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[23]
Kramers' law: Validity, derivations and generalisations
Nils Berglund. Kramers’ law: Validity, derivations and generalisations.arXiv preprint arXiv:1106.5799, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[24]
Peter E. Kloeden and Eckhard Platen.Numerical Solution of Stochastic Differential Equations, volume 23 of Applications of Mathematics. Springer, Berlin, 1992. 13
work page 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.