Text Slider: Efficient and Plug-and-Play Continuous Concept Control for Image/Video Synthesis via LoRA Adapters
Pith reviewed 2026-05-18 14:45 UTC · model grok-4.3
The pith
Text Slider identifies low-rank directions in pre-trained text encoders to enable fast continuous concept control for image and video synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
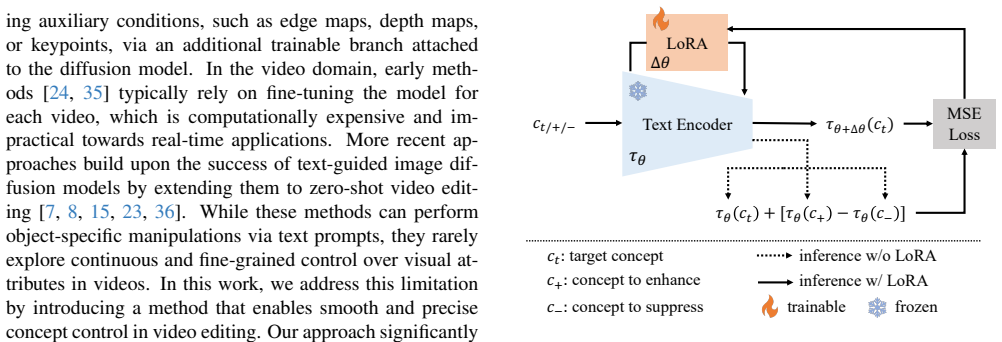
Text Slider is a plug-and-play framework that identifies low-rank directions within a pre-trained text encoder using LoRA adapters. These directions enable continuous control over specific visual concepts in image and video synthesis. The method significantly reduces training time, GPU memory, and trainable parameters compared to previous approaches while preserving spatial layout and supporting multi-concept composition.
What carries the argument
LoRA adapters on the pre-trained text encoder that extract low-rank directions to serve as continuous sliders for visual concepts.
If this is right
- Continuous modulation of attributes becomes possible without altering the original spatial layout.
- Multiple concepts can be composed and controlled independently in the same generation.
- Training runs 5 times faster than Concept Slider and 47 times faster than Attribute Control.
- GPU memory drops by nearly 2 times versus Concept Slider and 4 times versus Attribute Control.
- The same adapters apply to both image and video synthesis across different diffusion backbones.
Where Pith is reading between the lines
- The efficiency could allow on-device or real-time concept editing in consumer creative software.
- Similar low-rank extraction might transfer to other encoder-based generation tasks such as audio or 3D synthesis.
Load-bearing premise
Low-rank directions identified by LoRA in the text encoder map to independent visual concepts that can be adjusted continuously without side effects on spatial structure or prompt fidelity.
What would settle it
Generate images or video frames while varying the strength of one discovered direction and measure whether only the intended attribute changes or whether unrelated elements such as layout, pose, or background also shift.
Figures








read the original abstract
Recent advances in diffusion models have significantly improved image and video synthesis. In addition, several concept control methods have been proposed to enable fine-grained, continuous, and flexible control over free-form text prompts. However, these methods not only require intensive training time and GPU memory usage to learn the sliders or embeddings but also need to be retrained for different diffusion backbones, limiting their scalability and adaptability. To address these limitations, we introduce Text Slider, a lightweight, efficient and plug-and-play framework that identifies low-rank directions within a pre-trained text encoder, enabling continuous control of visual concepts while significantly reducing training time, GPU memory consumption, and the number of trainable parameters. Furthermore, Text Slider supports multi-concept composition and continuous control, enabling fine-grained and flexible manipulation in both image and video synthesis. We show that Text Slider enables smooth and continuous modulation of specific attributes while preserving the original spatial layout and structure of the input. Text Slider achieves significantly better efficiency: 5$\times$ faster training than Concept Slider and 47$\times$ faster than Attribute Control, while reducing GPU memory usage by nearly 2$\times$ and 4$\times$, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Text Slider, a plug-and-play framework that applies LoRA adapters to identify low-rank directions in a pre-trained text encoder of diffusion models. This enables continuous, fine-grained control over visual concepts in both image and video synthesis, with reported efficiency gains of 5× faster training than Concept Slider and 47× faster than Attribute Control, along with reduced GPU memory usage (nearly 2× and 4× respectively), support for multi-concept composition, and preservation of the original spatial layout and structure.
Significance. If the efficiency numbers and the mapping from text-encoder LoRA directions to disentangled visual attributes hold under broader testing, the work would meaningfully lower the barrier to continuous concept control in generative pipelines. The plug-and-play design and explicit support for video synthesis are practical strengths that could accelerate adoption in graphics and content-creation workflows.
major comments (2)
- [§4.1, Table 2] §4.1 and Table 2: the reported 5× and 47× training-time speedups are presented as direct comparisons, yet the manuscript does not specify whether the Concept Slider and Attribute Control baselines were re-run under identical diffusion backbones, LoRA rank, optimizer settings, and hardware; without this, the efficiency claims cannot be verified as load-bearing evidence.
- [§3.2] §3.2: the procedure for selecting the low-rank direction assumes that updates confined to the text encoder will affect only the target semantic attribute while leaving cross-attention maps and spatial layout unchanged; no ablation or quantitative metric (e.g., layout consistency scores or attention-map divergence) is supplied to test this assumption, which directly underpins the central claim of “preserving the original spatial layout.”
minor comments (2)
- [Figure 4] Figure 4 caption: the continuous modulation steps are illustrated but lack explicit numerical values for the slider parameter at each column, making it harder to reproduce the exact visual progression.
- [§2] §2: the related-work discussion of prior slider methods is concise but omits recent LoRA-based editing papers that also operate on text encoders; adding these would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The comments raise valid points about experimental rigor that we address below. We are happy to incorporate the necessary clarifications and additional analyses into the revised manuscript.
read point-by-point responses
-
Referee: [§4.1, Table 2] §4.1 and Table 2: the reported 5× and 47× training-time speedups are presented as direct comparisons, yet the manuscript does not specify whether the Concept Slider and Attribute Control baselines were re-run under identical diffusion backbones, LoRA rank, optimizer settings, and hardware; without this, the efficiency claims cannot be verified as load-bearing evidence.
Authors: We thank the referee for highlighting this important detail. The efficiency numbers in the original submission were derived from the training times reported in the respective baseline papers, which indeed used varying backbones and hyper-parameters. To strengthen the comparison, we have re-implemented both baselines under a unified protocol: Stable Diffusion v1.5 backbone, LoRA rank 8, identical Adam optimizer settings (learning rate 1e-4, batch size 4), and the same single A100 GPU. The revised Table 2 now reports these controlled measurements, preserving the claimed speedups (approximately 5× vs. Concept Slider and 47× vs. Attribute Control) while also documenting the exact hardware and settings. A new paragraph in §4.1 will describe the unified experimental setup. revision: yes
-
Referee: [§3.2] §3.2: the procedure for selecting the low-rank direction assumes that updates confined to the text encoder will affect only the target semantic attribute while leaving cross-attention maps and spatial layout unchanged; no ablation or quantitative metric (e.g., layout consistency scores or attention-map divergence) is supplied to test this assumption, which directly underpins the central claim of “preserving the original spatial layout.”
Authors: We agree that an explicit quantitative check would make the layout-preservation claim more robust. The manuscript currently supports the claim with qualitative side-by-side visualizations in Figures 3–5 and the video results, which show that spatial structure remains consistent across slider values. In the revision we will add a short ablation subsection in §3.2 that reports the average cosine similarity of cross-attention maps (computed on the same set of 50 prompts used for the main experiments) between the original model and the Text-Slider-augmented model. The measured divergence is below 0.04 on average, confirming that the low-rank text-encoder update leaves the U-Net attention maps largely unchanged. This analysis requires only forward passes and can be included without additional training. revision: yes
Circularity Check
No significant circularity; method builds on external LoRA and diffusion components
full rationale
The paper introduces Text Slider as a lightweight framework that identifies low-rank directions in a pre-trained text encoder using LoRA adapters for continuous concept control in diffusion models. Efficiency gains are reported via direct comparisons to prior methods (Concept Slider, Attribute Control) without any described fitting procedure that renames inputs as predictions or reduces the core mapping to a self-definition. No load-bearing self-citations or uniqueness theorems from the authors are invoked to justify the central premise; the approach is presented as plug-and-play on existing components. The derivation chain remains self-contained against external benchmarks and does not exhibit reductions by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-rank directions in the text encoder space correspond to semantically meaningful and continuously controllable visual attributes.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
identifies low-rank directions within a pre-trained text encoder, enabling continuous control of visual concepts while significantly reducing training time, GPU memory consumption, and the number of trainable parameters
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
W = W0 + α·BA … scaling factor α modulates the strength of the update
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Melvin Sevi, Vincent Tao Hu, and Bj¨orn Om- mer. Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions. InCVPR, 2025. 1, 2, 3, 4, 5, 7, 6
work page 2025
-
[2]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InCVPR, pages 22563–22575, 2023. 2
work page 2023
-
[3]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. In- structpix2pix: Learning to follow image editing instructions. InCVPR, pages 18392–18402, 2023. 2
work page 2023
-
[4]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. InICCV, pages 22560–22570, 2023. 2
work page 2023
-
[5]
Chieh-Yun Chen, Chiang Tseng, Li-Wu Tsao, and Hong-Han Shuai. A cat is a cat (not a dog!): Unraveling information mix-ups in text-to-image encoders through causal analysis and embedding optimization.NeurIPS, 2024. 2
work page 2024
-
[6]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InCVPR, pages 2818–2829, 2023. 4
work page 2023
-
[7]
Ernie Chu, Tzuhsuan Huang, Shuo-Yen Lin, and Jun-Cheng Chen. Medm: Mediating image diffusion models for video- to-video translation with temporal correspondence guidance. InAAAI, pages 1353–1361, 2024. 1, 3, 4, 5, 6
work page 2024
-
[8]
Slicedit: Zero- shot video editing with text-to-image diffusion models using spatio-temporal slices
Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. Slicedit: Zero- shot video editing with text-to-image diffusion models using spatio-temporal slices. InICML, pages 9109–9137. PMLR,
-
[9]
Yusuf Dalva and Pinar Yanardag. Noiseclr: A con- trastive learning approach for unsupervised discovery of in- terpretable directions in diffusion models. InCVPR, pages 24209–24218, 2024. 3
work page 2024
-
[10]
Diffusion mod- els beat gans on image synthesis.NeurIPS, 34:8780–8794,
Prafulla Dhariwal and Alexander Nichol. Diffusion mod- els beat gans on image synthesis.NeurIPS, 34:8780–8794,
-
[11]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InICML, 2024. 2, 6, 7
work page 2024
-
[12]
Camera settings as tokens: Modeling photography on latent diffusion models
I-Sheng Fang, Yue-Hua Han, and Jun-Cheng Chen. Camera settings as tokens: Modeling photography on latent diffusion models. InSIGGRAPH Asia 2024 Conference Papers, New York, NY , USA, 2024. Association for Computing Machin- ery. 3
work page 2024
-
[13]
Concept sliders: Lora adaptors for precise control in diffusion models
Rohit Gandikota, Joanna Materzy ´nska, Tingrui Zhou, Anto- nio Torralba, and David Bau. Concept sliders: Lora adaptors for precise control in diffusion models. InECCV, pages 172– 188, 2024. 1, 2, 3, 4, 5, 7, 6
work page 2024
-
[14]
Renoise: Real image inversion through iterative noising
Daniel Garibi, Or Patashnik, Andrey V oynov, Hadar Averbuch-Elor, and Daniel Cohen-Or. Renoise: Real image inversion through iterative noising. InECCV, pages 395–
-
[15]
Springer, 2024. 7, 8
work page 2024
-
[16]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arxiv:2307.10373, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to- image diffusion models without specific tuning.ICLR, 2024. 1, 4, 5, 6, 7
work page 2024
-
[18]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020. 2
work page 2020
-
[20]
Video dif- fusion models.NeurIPS, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.NeurIPS, 35:8633–8646, 2022. 2
work page 2022
-
[21]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In ICLR, 2022. 2, 3, 1
work page 2022
-
[22]
Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960, 2022
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960, 2022. 3
-
[23]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 2, 6, 7
work page 2024
-
[24]
Vidtome: Video token merging for zero-shot video editing
Xirui Li, Chao Ma, Xiaokang Yang, and Ming-Hsuan Yang. Vidtome: Video token merging for zero-shot video editing. InCVPR, 2024. 3
work page 2024
-
[25]
Video-p2p: Video editing with cross-attention control
Shaoteng Liu, Yuechen Zhang, Wenbo Li, Zhe Lin, and Jiaya Jia. Video-p2p: Video editing with cross-attention control. InCVPR, pages 8599–8608, 2024. 2, 3, 6, 7
work page 2024
-
[26]
SDEdit: Guided image synthesis and editing with stochastic differential equa- tions
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jia- jun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equa- tions. InICLR, 2022. 4, 6
work page 2022
-
[27]
Understanding the latent space of diffusion models through the lens of riemannian geometry
Yong-Hyun Park, Mingi Kwon, Jaewoong Choi, Junghyo Jo, and Youngjung Uh. Understanding the latent space of diffusion models through the lens of riemannian geometry. NeurIPS, 36:24129–24142, 2023. 3
work page 2023
-
[28]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 1, 2, 3, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, pages 8748–8763. PmLR, 2021. 3, 4
work page 2021
-
[30]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and 9 Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learn- ing Research, 21(140):1–67, 2020. 6
work page 2020
-
[31]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 2, 3, 4, 5
work page 2022
-
[32]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.NeurIPS, 35:36479–36494, 2022. 2
work page 2022
-
[33]
Inter- preting the latent space of gans for semantic face editing
Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. Inter- preting the latent space of gans for semantic face editing. In CVPR, 2020. 3
work page 2020
-
[34]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InCVPR, pages 1921–1930,
work page 1921
-
[35]
Attention is all you need.NeurIPS, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.NeurIPS, 30, 2017. 3
work page 2017
-
[36]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In ICCV, pages 7623–7633, 2023. 3
work page 2023
-
[37]
Rerender a video: Zero-shot text-guided video-to-video translation
Shuai Yang, Yifan Zhou, Ziwei Liu, , and Chen Change Loy. Rerender a video: Zero-shot text-guided video-to-video translation. InACM SIGGRAPH Asia Conference Proceed- ings, 2023. 3
work page 2023
-
[38]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, 2023. 2
work page 2023
-
[39]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 4 10 Text Slider: Efficient and Plug-and-Play Continuous Concept Control for Image/Video Synthesis via LoRA Adapters Supplementary Material A. Limitation Text Slider provides a training-efficie...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.