ML Code Smells: From Specification to Detection
Pith reviewed 2026-05-18 13:34 UTC · model grok-4.3
The pith
SpecDetect4ML detects ML code smells using declarative DSL specifications and code property graph analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that ML code smells can be expressed as executable specifications in a declarative DSL and detected effectively through CPG-based project-level reasoning, which handles non-local and flow-dependent patterns that AST-only tools miss, yielding 95.82 percent precision and 88.14 percent recall on a unified ground truth while providing an extensible foundation for additional smells.
What carries the argument
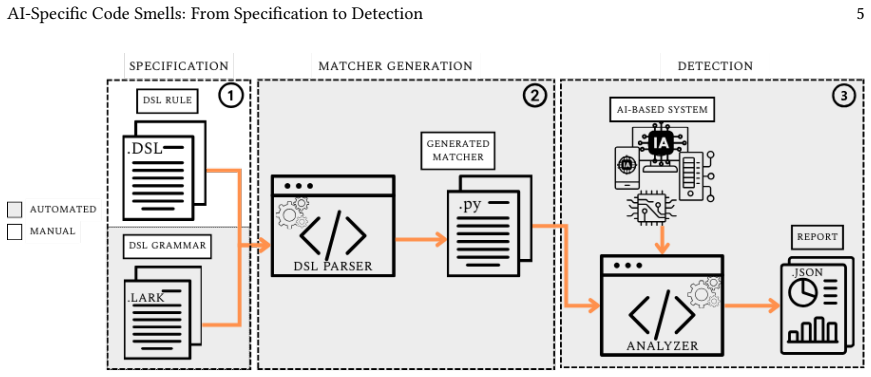
SpecDetect4ML, the specification-driven detection tool that pairs a declarative DSL for reusable smell predicates with a scalable CPG analysis engine for syntactic, control-flow, and data-flow relations.
If this is right
- ML developers gain a practical way to scan pipelines for issues like data leakage before they compromise results.
- The DSL approach allows new smells to be added by writing predicates rather than hand-coding rules.
- Project-level CPG analysis extends detection to control and data flows that local pattern matchers overlook.
- Higher coverage than existing tools reduces the chance of silent failures in reproducibility and maintainability.
Where Pith is reading between the lines
- The same DSL-plus-CPG pattern could apply to code smells in other domains such as scientific computing or web services.
- Embedding the detector in continuous integration could prevent smells from entering codebases during development.
- Automatic repair suggestions based on the detected smells would be a natural next step not explored here.
Load-bearing premise
The 22 specified ML code smells represent real-world problems and the unified ground truth used for evaluation on 890 systems is accurate and unbiased.
What would settle it
Re-running the evaluation on a fresh set of ML systems outside the original 890 would produce precision or recall below 80 percent or miss known flow-dependent smells that the tool claims to cover.
Figures


read the original abstract
The rapid adoption of Artificial Intelligence (AI) is increasingly realised through Machine Learning (ML) pipelines that integrate data preprocessing, model training, evaluation scripts, and configuration-heavy experimentation code. In these ML-based systems, small and often overlooked implementation choices can silently compromise experimental reproducibility, robustness to data and environment changes, and maintainability. We study ML code smells, recurring implementation patterns that can undermine reproducibility, robustness, and maintainability, for example by inducing silent failures or data leakage. We present SpecDetect4ML, a specification-driven detection tool that combines a declarative Domain-Specific Language (DSL) with a scalable analysis engine backed with Code Property Graphs (CPGs). Unlike the state-of-the-art (SOTA) analysers that rely on hand-coded, per-rule local pattern checks, our DSL expresses smells as executable specifications via reusable predicates, while the CPG analysis enables project-level reasoning over syntactic, control-flow, and data-flow relations. This CPG reasoning outperforms Abstract Syntax Tree (AST)-only analysers while remaining scalable and practical in analysis time. We specified 22 ML code smells and evaluated SpecDetect4ML on 890 ML-based systems. SpecDetect4ML achieves 95.82% precision and 88.14% recall on a unified ground truth, outperforming SOTA analysers in both effectiveness and coverage, providing an extensible foundation for detecting non-local, flow-dependent ML code smells.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpecDetect4ML, a specification-driven tool that uses a declarative DSL to express ML code smells as reusable predicates and a CPG-based analysis engine to perform project-level syntactic, control-flow, and data-flow reasoning. The authors specify 22 ML code smells and evaluate the approach on 890 ML-based systems, claiming 95.82% precision and 88.14% recall on a unified ground truth while outperforming SOTA analysers in effectiveness and coverage for non-local, flow-dependent smells.
Significance. If the evaluation methodology proves robust, the work would be significant as it moves beyond local AST pattern matching to scalable, non-local detection of ML-specific smells that affect reproducibility and maintainability. The extensible DSL and CPG foundation could serve as a reusable platform for future smell specifications.
major comments (1)
- [Evaluation] Evaluation section: The central claims of 95.82% precision and 88.14% recall (and superiority over SOTA) rest on an unspecified 'unified ground truth' for the 890 systems. No details are provided on the labeling protocol, number of annotators, inter-rater reliability, sampling strategy, conflict resolution for non-local or cross-file smells, or operationalization criteria for the 22 smells. This absence directly undermines verification of the reported metrics and the claim that the tool accurately captures both local and flow-dependent issues.
minor comments (1)
- [Abstract] Abstract: The phrase 'unified ground truth' appears without a forward reference to the evaluation methodology or a brief characterization of how it was assembled; adding one sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps strengthen the presentation of our evaluation. We address the major comment below and will revise the manuscript to provide the requested details on ground truth construction.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central claims of 95.82% precision and 88.14% recall (and superiority over SOTA) rest on an unspecified 'unified ground truth' for the 890 systems. No details are provided on the labeling protocol, number of annotators, inter-rater reliability, sampling strategy, conflict resolution for non-local or cross-file smells, or operationalization criteria for the 22 smells. This absence directly undermines verification of the reported metrics and the claim that the tool accurately captures both local and flow-dependent issues.
Authors: We agree that the manuscript currently provides insufficient detail on the unified ground truth, which limits independent verification of the metrics. In the revised version we will insert a dedicated subsection 'Ground Truth Construction' immediately preceding the results. This subsection will cover: the labeling protocol, which operationalizes each of the 22 smells using the exact DSL predicate definitions to distinguish local syntactic patterns from non-local control- and data-flow conditions; the number of annotators and their qualifications; the inter-rater reliability measure employed; the sampling strategy for selecting the 890 systems and the annotated instances; and the conflict-resolution procedure, which explicitly addresses disagreements on cross-file smells through consensus discussion anchored to the smell specifications. These additions will directly support the claims regarding both local and flow-dependent detection and the comparison with prior tools. revision: yes
Circularity Check
No significant circularity: empirical evaluation on external corpus
full rationale
The paper specifies 22 ML code smells in a DSL, implements detection via CPG-based analysis, and reports precision/recall on a unified ground truth across 890 external ML systems. No equations, fitted parameters, or first-principles derivations are present that could reduce to self-definition or input renaming. Performance figures are measured outcomes against an external benchmark rather than quantities constructed from the paper's own fitted values or prior self-citations. The evaluation protocol, while potentially underspecified in the abstract, does not create a circular reduction because the ground truth is treated as an independent reference set. This is a standard empirical software-engineering result with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption ML pipelines contain recurring implementation patterns that silently compromise reproducibility and robustness
- standard math Code Property Graphs enable scalable project-level reasoning over data and control flow
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a declarative DSL... 52 reusable semantic predicates... evaluated on 826 AI-based systems... 95.82% precision and 88.14% recall on a unified ground truth
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SpecDetect4AI... combines a high-level declarative Domain-Specific Language (DSL) for rule specification with an extensible static analysis tool
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Meta AI. 2024. LLaMA 3: Open Foundation and Instruction-Tuned Language Models by Meta. https://github.com/meta-llama/llama3. Accessed: 2025-03-10
work page 2024
- [2]
-
[3]
Anonymous. 2025. SpecDetect4AI Replication Package. https://anonymous.4open.science/r/SpecDetect4AI-B903. Study artefacts
work page 2025
-
[4]
Sebastian Baltes and Paul Ralph. 2022. Sampling in Software Engineering Research: A Critical Review and Guidelines.Empirical Software Engineering 27, 3 (2022), 1–38. doi:10.1007/s10664-021-10072-8 AI-Specific Code Smells: From Specification to Detection 19
-
[5]
Polarization Control of VCSELs,
Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. 2009.Pearson correlation coefficient. Springer. 1–4 pages. doi:10.1007/978-3-642- 00296-0_1
-
[6]
John Brooke. 1996. SUS: a “quick and dirty” usability scale.Usability evaluation in industry189, 194 (1996), 4–7
work page 1996
-
[7]
William G. Cochran. 1977.Sampling Techniques(3 ed.). John Wiley & Sons, New York
work page 1977
-
[8]
Databricks. 2024. mlflow: An Open Source Platform for the Machine Learning Lifecycle. https://github.com/mlflow/mlflow. Accessed: 2025-04-01
work page 2024
-
[9]
DeepSeek-AI. 2024. DeepSeek-R1: A Strong Open LLM Series with 7B/67B Models. https://github.com/deepseek-ai/DeepSeek-R1. Accessed: 2025-03-21
work page 2024
-
[10]
DeepSeek-AI et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948 (2025). https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Malinda Dilhara, Danny Dig, and Ameya Ketkar. 2023. PyEvolve: Automating Frequent Code Changes in Python ML Systems. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 995–1007. doi:10.1109/ICSE48619.2023.00091
-
[12]
Julian Dolby, Avraham Shinnar, Allison Allain, and Jenna Reinen. 2018. Ariadne: analysis for machine learning programs. InProceedings of the 2nd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages(Philadelphia, PA, USA)(MAPL 2018). Association for Computing Machinery, New York, NY, USA, 1–10. doi:10.1145/3211346.3211349
-
[13]
Aryaz Eghbali and Michael Pradel. 2022. DynaPyt: A Dynamic Analysis Framework for Python. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’22). 760–771. doi:10.1145/3540250.3549126
-
[14]
John Field, Manu Sridharan, and Gaurav S. Kc. 2005. WALA: A Scalable Infrastructure for Program Analysis. InWorkshop on Middleware for Software Development Environments (at ACM/IFIP/USENIX Middleware). https://wala.github.io/ IBM T.J. Watson Research Center
work page 2005
-
[15]
Martin Fowler. 2002. Refactoring: Improving the Design of Existing Code. InExtreme Programming and Agile Methods — XP/Agile Universe 2002, Don Wells and Laurie Williams (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 256–256
work page 2002
-
[16]
Corrado Gini. 1921. Measurement of inequality of incomes.The economic journal31, 121 (1921), 124–125
work page 1921
-
[17]
GitHub Security Lab. 2024. CodeQL: Semantic Code Analysis Engine. https://codeql.github.com. Accessed May 2025
work page 2024
-
[18]
Rebecca A Grier, Aaron Bangor, Philip Kortum, and S Camille Peres. 2013. The system usability scale: Beyond standard usability testing. In Proceedings of the human factors and ergonomics society annual meeting, Vol. 57. SAGE Publications Sage CA: Los Angeles, CA, 187–191
work page 2013
-
[19]
2023.MLpylint: Automating the Identification of Machine Learning-Specific Code Smells
Pär Hamfelt. 2023.MLpylint: Automating the Identification of Machine Learning-Specific Code Smells. Dissertation. Blekinge Institute of Technology. https://urn.kb.se/resolve?urn=urn:nbn:se:bth-25490
work page 2023
-
[20]
Weigang He, Peng Di, Mengli Ming, Chengyu Zhang, Ting Su, Shijie Li, and Yulei Sui. 2024. Finding and Understanding Defects in Static Analyzers by Constructing Automated Oracles.Proc. ACM Softw. Eng.1, FSE, Article 74 (July 2024), 23 pages. doi:10.1145/3660781
-
[21]
Heli Järvenpää, Patricia Lago, Justus Bogner, Grace Lewis, Henry Muccini, and Ipek Ozkaya. 2024. A Synthesis of Green Architectural Tactics for ML-Enabled Systems. InProceedings of the 46th International Conference on Software Engineering: Software Engineering in Society(Lisbon, Portugal) (ICSE-SEIS’24). Association for Computing Machinery, New York, NY, ...
-
[22]
2013.Content Analysis: An Introduction to Its Methodology(3rd ed.)
Klaus Krippendorff. 2013.Content Analysis: An Introduction to Its Methodology(3rd ed.). SAGE Publications
work page 2013
-
[23]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention.arXiv preprint arXiv:2309.06180(2023). arXiv:2309.06180 [cs.LG] doi:10.48550/arXiv.2309.06180
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180 2023
-
[24]
Nelson Amaral, Bor-Yuh Evan Chang, Samuel Z
Benjamin Livshits, Manu Sridharan, Yannis Smaragdakis, Ondřej Lhoták, J. Nelson Amaral, Bor-Yuh Evan Chang, Samuel Z. Guyer, Uday P. Khedker, Anders Møller, and Dimitrios Vardoulakis. 2015. In defense of soundiness: a manifesto.Commun. ACM58, 2 (Jan. 2015), 44–46. doi:10.1145/2644805
-
[25]
Marjan Mernik, Jan Heering, and Anthony M. Sloane. 2005. When and how to develop domain-specific languages.ACM Comput. Surv.37, 4 (Dec. 2005), 316–344. doi:10.1145/1118890.1118892
-
[26]
Nadia Nahar, Haoran Zhang, Grace Lewis, Shurui Zhou, and Christian Kästner. 2023. A meta-summary of challenges in building products with ml components–collecting experiences from 4758+ practitioners. In2023 IEEE/ACM 2nd International Conference on AI Engineering–Software Engineering for AI (CAIN). IEEE, 171–183
work page 2023
- [27]
- [28]
-
[29]
OpenAI. 2025. GPT-4.1 mini (Model documentation). https://platform.openai.com/docs/models/gpt-4.1-mini Accessed: 2025-09-01
work page 2025
-
[30]
Samir Passi and Steven J. Jackson. 2018. Trust in Data Science: Collaboration, Translation, and Accountability in Corporate Data Science Projects. Proc. ACM Hum.-Comput. Interact.2, CSCW, Article 136 (Nov. 2018), 28 pages. doi:10.1145/3274405
-
[31]
Eduard Pinconschi, Sofia Reis, Chi Zhang, Rui Abreu, Hakan Erdogmus, Corina S. Păsăreanu, and Limin Jia. 2023. Tenet: A Flexible Framework for Machine-Learning-based Vulnerability Detection. InProceedings of the 2023 IEEE/ACM 2nd International Conference on AI Engineering – Software Engineering for AI (CAIN). IEEE. doi:10.1109/CAIN58948.2023.00026 Paper p...
-
[32]
PyCQA_flake8. 2024. flake8. https://pypi.org/project/flake8/. Accessed May 2025
work page 2024
-
[33]
PyCQA_pylint. 2024. Pylint. https://pypi.org/project/pylint/. Accessed May 2025
work page 2024
-
[34]
r2c, Inc. 2024. Semgrep: Lightweight Static Analysis for Many Languages. https://semgrep.dev. Accessed May 2025. 20 Mahmoudi et al
work page 2024
-
[35]
Gilberto Recupito, Giammaria Giordano, Filomena Ferrucci, Dario Di Nucci, and Fabio Palomba. 2025. When code smells meet ML: on the lifecycle of ML-specific code smells in ML-enabled systems.Empirical Software Engineering30, Article 139 (2025). doi:10.1007/s10664-025-10676-4
-
[36]
Eduardo Royuela and Yania Crespo. 2025. Comparing Different Techniques for Automatic Detection and Correction of React Code Smells.SSRN Electronic Journal(2025). doi:10.2139/ssrn.5251648
-
[37]
Shreya Shankar, Reyna Garcia, Joseph M. Hellerstein, and Aditya G. Parameswaran. 2022. Operationalizing Machine Learning: An Interview Study. (2022). arXiv:2209.09125 [cs.SE] arXiv preprint
-
[38]
Mary Shaw and Liming Zhu. 2022. Can Software Engineering Harness the Benefits of Advanced AI?IEEE Softw.39, 6 (Nov. 2022), 99–104. doi:10.1109/MS.2022.3203200
-
[39]
Erez Shinan. 2017. Lark: A Modern Parsing Library for Python. https://github.com/lark-parser/lark. Used for DSL grammar parsing in this work. Accessed April 7, 2025
work page 2017
-
[40]
Xiaoxi Wang et al. 2023. Code Llama: Open Foundation Models for Code. InArXiv Preprint. https://arxiv.org/abs/2308.12950
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Zhijie Wang, Zijie Zhou, Da Song, Yuheng Huang, Shengmai Chen, Lei Ma, and Tianyi Zhang. 2025. Towards Understanding the Characteristics of Code Generation Errors Made by Large Language Models. InProceedings of the 2025 International Conference on Software Engineering (Track ICSE Research Track)(São Francisco, CA)
work page 2025
-
[42]
Moshi Wei, Nima Shiri Harzevili, Yuekai Huang, Jinqiu Yang, Junjie Wang, and Song Wang. 2024. Demystifying and Detecting Misuses of Deep Learning APIs. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 201, 12 pages. doi:10.1145/3...
-
[43]
Moshi Wei, Yuchao Huang, Junjie Wang, Jiho Shin, Nima Shiri Harzevili, and Song Wang. 2022. API recommendation for machine learning libraries: how far are we?. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Singapore, Singapore)(ESEC/FSE 2022). Association for Computing...
-
[44]
Frank Wilcoxon. 1945. Individual comparisons by ranking methods.Biometrics Bulletin1, 6 (1945), 80–83. doi:10.2307/3001968
-
[45]
Niklaus Wirth. 1977. What Can We Do About the Unnecessary Diversity of Notation for Syntactic Definitions?Commun. ACM20, 11 (1977), 822–823. doi:10.1145/359863.359909
-
[46]
Di Wu, Fangwen Mu, Lin Shi, Zhaoqiang Guo, Kui Liu, Weiguang Zhuang, Yuqi Zhong, and Li Zhang. 2024. iSMELL: Assembling LLMs with Expert Toolsets for Code Smell Detection and Refactoring. In2024 39th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1345–1357
work page 2024
-
[47]
Yao Yao, Lei Zhang, and Abhimanyu Chaudhuri. 2008. Early Stopping and Its Applications to Boosting.Journal of Machine Learning Research9 (2008), 947–970
work page 2008
-
[48]
Haiyin Zhang, Luís Cruz, and Arie van Deursen. 2022. Code smells for machine learning applications. InProceedings of the 1st International Conference on AI Engineering: Software Engineering for AI(Pittsburgh, Pennsylvania)(CAIN ’22). Association for Computing Machinery, New York, NY, USA, 217–228. doi:10.1145/3522664.3528620
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.