Self-CriTeach: LLM Self-Teaching and Self-Critiquing for Improving Robotic Planning via Automated Domain Generation
Pith reviewed 2026-05-18 13:26 UTC · model grok-4.3
The pith
An LLM can bootstrap stronger robotic planning by generating its own symbolic domains for training data and rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
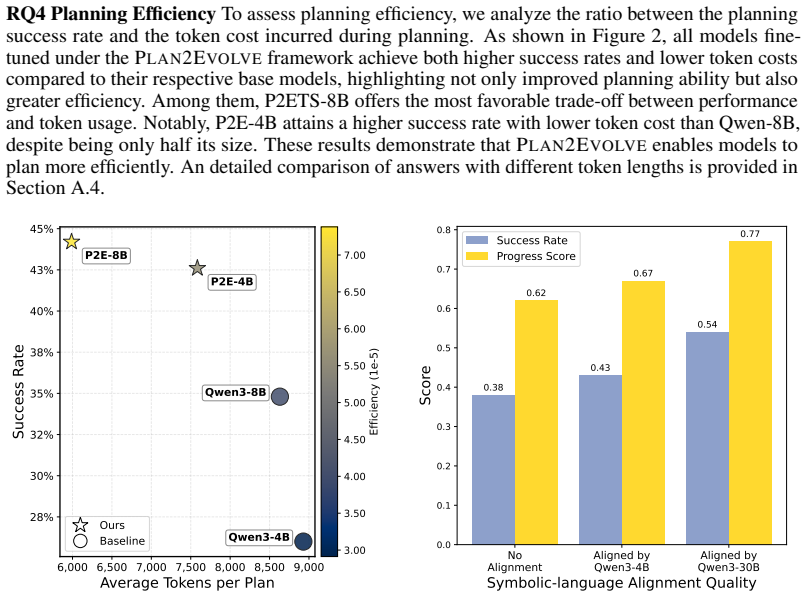
The central claim is that LLM-generated symbolic planning domains can play a dual role: they supply the data for producing extended CoT trajectories that fine-tune the model on planning, and they supply dense, structured reward signals that train the model via reinforcement learning. This unified pipeline produces a planning-enhanced LLM that achieves higher success rates, stronger cross-task generalization, reduced inference cost, and improved resistance to imperfect logical states.
What carries the argument
The Self-CriTeach pipeline, where autonomously generated symbolic planning domains are reused both to derive extended CoT supervision for fine-tuning and to define structured reward functions for reinforcement learning.
If this is right
- Planning success rates rise on standard robotic tasks.
- Cross-task generalization strengthens without task-specific human data.
- Inference cost drops because the model plans more efficiently.
- Performance holds up better when logical states are incomplete or noisy.
Where Pith is reading between the lines
- The method could support repeated self-improvement cycles in which each round of generated domains refines the model further.
- The same dual-use pattern might apply to planning problems outside robotics, such as logistics or scheduling.
- By removing manual reward engineering, the approach could make reinforcement learning more practical for complex real-world robot tasks.
Load-bearing premise
The symbolic planning domains generated by the LLM must be accurate enough to produce reliable training trajectories and effective reward signals.
What would settle it
A controlled test measuring whether the resulting LLM still outperforms baselines on robotic tasks when the input states contain simulated logical errors or perception noise.
Figures





read the original abstract
Large Language Models (LLMs) have shown strong promise for robotic task planning, particularly through the automatic generation of symbolic planning domains. However, prior work mainly treats generated domains as planning utilities. Such pipelines remain brittle under imperfect logical states and perception noise, while overlooking the potential of generated domains as scalable sources of reasoning supervision and structured reward signals. At the same time, reasoning LLMs depend on chain-of-thought (CoT) supervision, which is expensive to collect for robotic tasks, and reinforcement learning (RL) faces challenges in reward engineering. We propose Self-CriTeach, an LLM self-teaching and self-critiquing framework in which an LLM autonomously generates symbolic planning domains that serve a dual role: (1) In the self-teaching stage, generated domains are used to produce large-scale robotic planning problem--plan pairs, which are automatically converted into extended CoT trajectories for supervised fine-tuning. (2) In the self-critiquing stage, the same domains are reused as structured reward functions, providing dense feedback for reinforcement learning without manual reward engineering. This unified training pipeline yields a planning-enhanced LLM with higher planning success rates, stronger cross-task generalization, reduced inference cost, and improved resistance to imperfect logical states. GitHub Page: https://markli1hoshipu.github.io/Plan_LLM/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-CriTeach, a unified LLM self-teaching and self-critiquing framework for robotic planning. An LLM autonomously generates symbolic planning domains that are used (1) to synthesize large-scale problem-plan pairs converted into extended CoT trajectories for supervised fine-tuning and (2) as structured reward functions (goal predicates, action preconditions/effects) for reinforcement learning. The authors claim the resulting planning-enhanced LLM achieves higher success rates, stronger cross-task generalization, reduced inference cost, and improved robustness to imperfect logical states.
Significance. If the generated domains prove sufficiently accurate and the empirical gains hold, the approach would offer a scalable alternative to manual domain engineering and reward design, addressing data scarcity for CoT supervision and reward engineering in LLM-based robotic planners.
major comments (2)
- [Abstract and §3] Abstract and §3 (framework description): the central claim that LLM-generated domains are of sufficient quality to serve as reliable sources for both extended CoT trajectories and dense RL reward signals rests on an unverified assumption. No error analysis, predicate accuracy metrics, or expert validation of the generated domains (e.g., correctness of action schemas or state transitions) is reported, yet any systematic errors would directly corrupt both the SFT data and the RL rewards.
- [§4] §4 (experiments): the manuscript asserts higher planning success rates, stronger cross-task generalization, and robustness to imperfect states, but provides no quantitative results, baselines, ablations against hand-crafted domains, or fidelity checks on the generated domains. Without these, the causal improvements cannot be assessed.
minor comments (1)
- [Abstract] The GitHub link is given but the paper lacks an explicit reproducibility statement or details on how the generated domains and trajectories can be inspected.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of domain validation and experimental rigor that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (framework description): the central claim that LLM-generated domains are of sufficient quality to serve as reliable sources for both extended CoT trajectories and dense RL reward signals rests on an unverified assumption. No error analysis, predicate accuracy metrics, or expert validation of the generated domains (e.g., correctness of action schemas or state transitions) is reported, yet any systematic errors would directly corrupt both the SFT data and the RL rewards.
Authors: We agree that explicit validation metrics would strengthen the central claim. The self-critiquing stage is intended to detect and correct domain errors through iterative LLM feedback, but we acknowledge that the current version lacks quantitative error analysis or expert validation of predicate accuracy and state transitions. In the revised manuscript we will add a dedicated analysis subsection reporting domain fidelity metrics (e.g., percentage of valid action schemas and state transitions) and the success rate of the self-critiquing loop in producing usable domains. revision: yes
-
Referee: [§4] §4 (experiments): the manuscript asserts higher planning success rates, stronger cross-task generalization, and robustness to imperfect states, but provides no quantitative results, baselines, ablations against hand-crafted domains, or fidelity checks on the generated domains. Without these, the causal improvements cannot be assessed.
Authors: We accept that the current experimental section would benefit from more comprehensive quantitative support. While §4 presents initial success-rate and generalization results, we did not include full ablations against hand-crafted domains or explicit fidelity checks. In the revision we will expand the experiments with (i) tabulated success rates and inference-cost comparisons, (ii) ablations contrasting LLM-generated versus hand-crafted domains, and (iii) fidelity metrics linking domain quality to downstream planning performance, thereby clarifying the causal contribution of the proposed pipeline. revision: yes
Circularity Check
No significant circularity; framework evaluated on external benchmarks
full rationale
The paper proposes a pipeline in which LLM-generated symbolic domains supply CoT data for SFT and structured rewards for RL. Claimed outcomes (higher planning success rates, cross-task generalization, reduced inference cost, robustness to imperfect states) are measured against external task performance rather than quantities defined by the method's own fitted parameters or self-referential equations. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation remains self-contained against independent success metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can autonomously generate high-quality symbolic planning domains suitable for robotic tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PLAN2EVOLVE... treats LLM-generated PDDL domains as evolving knowledge sources... symbolic–language alignment... plan explanation, state transition check, alternative exploration, failure backtracking
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
generated domains... provide dense feedback for reinforcement learning without manual reward engineering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Predicate invention from pixels via pretrained vision-language models
From Pixels to Predicates: Learning Symbolic World Models via Pretrained Vision-Language Models. arXiv preprint arXiv:2501.00296 (2024). Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mo...
-
[2]
Yongchao Chen, Jacob Arkin, Yilun Hao, Yang Zhang, Nicholas Roy, and Chuchu Fan
CLIMB: Language-guided continual learning for task planning with iterative model building.arXiv [cs.RO] (2024). Yongchao Chen, Jacob Arkin, Yilun Hao, Yang Zhang, Nicholas Roy, and Chuchu Fan
work page 2024
-
[3]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems. In arXiv preprint arXiv:2110.14168. Murtaza Dalal, Ajay Mandlekar, Caelan Reed Garrett, Ankur Handa, Ruslan Salakhutdinov, and Di- eter Fox
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2021)
Automated Generation of Robotic Planning Domains from Observations. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2021). Danny Driess, F Xia, Mehdi S M Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Q Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, P Sermanet, Daniel Duckworth,...
work page 2021
-
[5]
PDDLStream: Integrat- ing symbolic planners and blackbox samplers via optimistic adaptive planning. Proc. Int. Conf. Autom. Plan. Sched. (2020). Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. 2023a. Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning. In Proc. Adv. Neu...
-
[6]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (March 2015). Joerg Hoffmann
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
FF: The Fast-Forward Planning System. AIMag 22, 3 (2001), 57–57. Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal
work page 2001
-
[8]
InProceedings of the 2024 Conference on Language Modeling
V-STaR: Training verifiers for self-taught reasoners. InProceedings of the 2024 Conference on Language Modeling. Mengkang Hu, Yao Mu, Xinmiao Yu, Mingyu Ding, Shiguang Wu, Wenqi Shao, Qiguang Chen, Bin Wang, Yu Qiao, and Ping Luo
work page 2024
-
[9]
arXiv preprint arXiv:2310.08582 , year=
Tree-Planner: Efficient close-loop task planning with Large Language Models. arXiv preprint arXiv:2310.08582 (2023). Jinbang Huang, Allen Tao, Rozilyn Marco, Miroslav Bogdanovic, Jonathan Kelly, and Florian Shkurti. 2025a. Automated Planning Domain Inference for Task and Motion Planning. In 2025 IEEE International Conference on Robotics and Automation (IC...
-
[10]
IEEE Robotics and Automation Letters (2023)
Learning to Search in Task and Motion Planning With Streams. IEEE Robotics and Automation Letters (2023). Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa
work page 2023
-
[11]
Self-training meets consistency: Im- proving LLMs’ reasoning with consistency-driven rationale evaluation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume1: Long Papers). Boyi Li, Philipp Wu, Pieter Abbeel, and Jitendra Malik
work page 2025
-
[12]
arXiv preprint arXiv:2410.23156 (2024)
VisualPredicator: Learning abstract world models with Neuro- Symbolic Predicates for robot planning. arXiv preprint arXiv:2410.23156 (2024). Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. 2023a. LLM+P: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477 (2023). ...
-
[13]
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. OpenAI
work page 2023
-
[14]
GPT-4 Technical Report. arXiv preprint arXiv:2303.08774 (2023). James Oswald, Kavitha Srinivas, Harsha Kokel, Junkyu Lee, Michael Katz, and Shirin Sohrabi
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Training Language Models to Follow Instructions with Human Feedback. In Proc. Adv. Neural Inf. Proc. Systems. Jiayi Pan, Glen Chou, and Dmitry Berenson. 2023b. Data-Efficient Learning of Natural Language to Linear Temporal Logic Translators for Robot Task Specification. InProceedings of the 2023 IEEE International Conference on Robotics and Automation (IC...
work page 2023
-
[16]
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Multi-LogiEval: Towards Evaluating Multi-Step Logical Reasoning Ability of Large Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J. Jos...
work page 2024
-
[17]
RoboVQA: Multimodal Long-Horizon Reasoning for Robotics. Proc. IEEE Int. Conf. on Robotics and Automation (2023). Tom Silver, Rohan Chitnis, Nishanth Kumar, Willie McClinton, Tomás Lozano-Pérez, Leslie Kael- bling, and Joshua B Tenenbaum
work page 2023
-
[18]
Gemma Team. 2025a. Gemma 3 Technical Report. arXiv preprint arXiv:2503.19786 (2025). Qwen Team. 2025b. Qwen3 Technical Report. arXiv preprint arXiv:2505.09388 (2025). Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
LLM3: Large Language Model-based Task and Motion Planning with Motion Failure Reasoning. In Proc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023b. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In Intern...
-
[20]
Learning adaptive planning representations with natural language guidance. arXiv [cs.AI] (2023). Jundong Xu, Hao Fei, Liangming Pan, Qian Liu, Mong Li Lee, and Wynne Hsu
work page 2023
-
[21]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models. arXiv preprint arXiv:2308.01825 (2023). Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Language Models can infer action semantics for symbolic planners from environment feedback. arXiv [cs.AI] (2024). 14 A Appendix A.1 LLM-based Domain Generation A.1.1 Initial Domain Skeleton Construction The first stage of PLAN2EVOLVEis the automatic construction of symbolic planning domains. We leverage the generative capacity of the base model M0 to prop...
work page 2024
-
[23]
From each model output, we extract the final predicted action sequence enclosed within <REASON> tags
0 10 10 20 20 30 30+ Optimal Plan Length (steps) 0.0 0.1 0.2 0.3 0.4 0.5 0.6Proportion of T asks Normal fit T ask counts Figure 6: Evaluation data distribution for Blocks World Classic A.3.2 Training Implementation Details The pipeline for generating CoT follows a structure similar to the evaluation pipeline, with minor modifications to the prompts and a ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.