BoHA: Blockwise Hadamard Product Adaptation for Parameter-Efficient Fine-Tuning
Pith reviewed 2026-05-18 13:41 UTC · model grok-4.3
The pith
BoHA partitions frozen weights into blocks and applies local low-rank Hadamard factors to retain prior-task accuracy during sequential fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
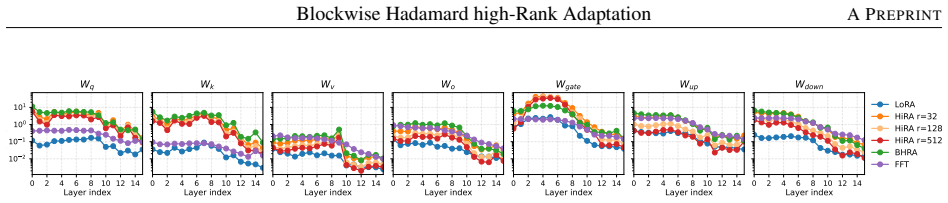
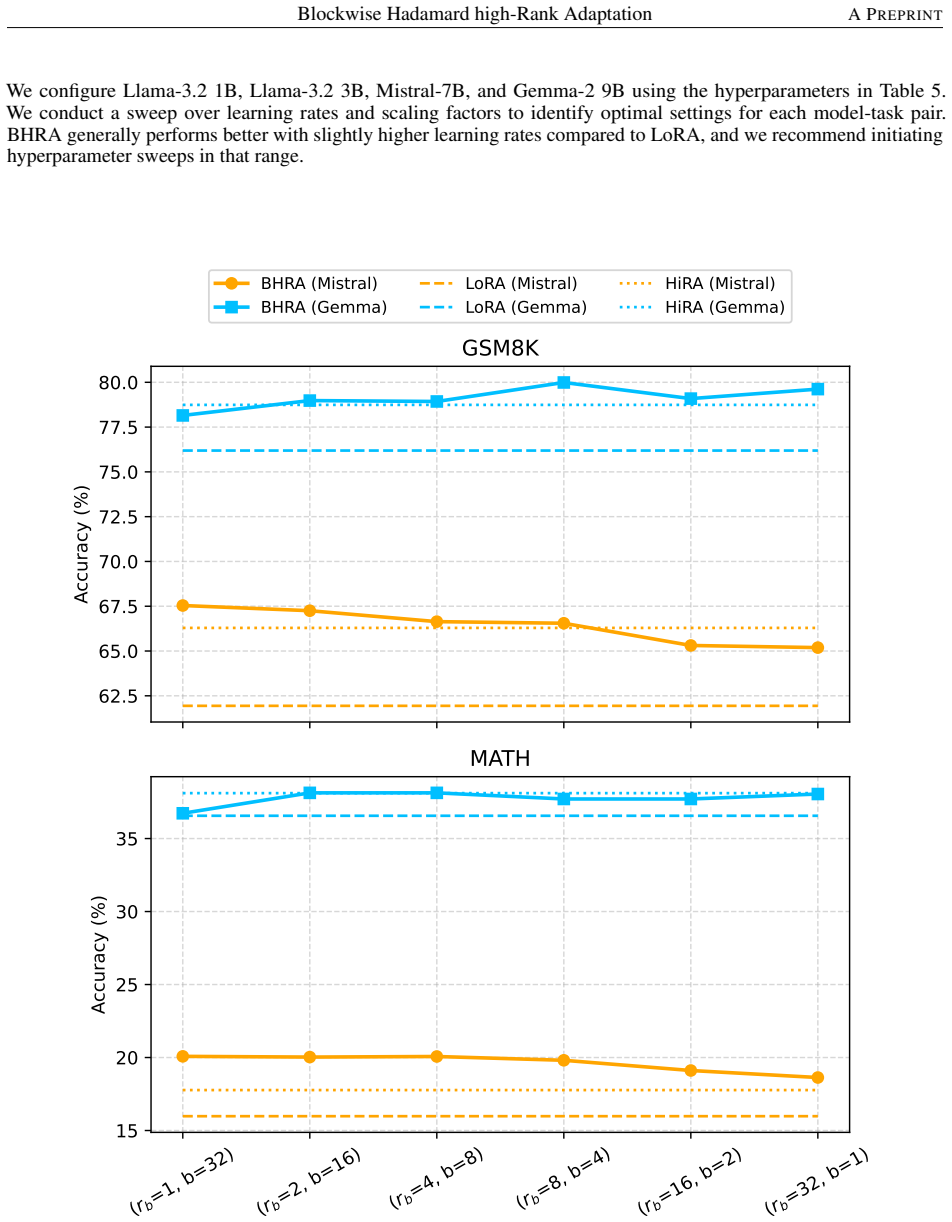
BoHA partitions the frozen weight W0 into a b×b grid and learns an independent low-rank Hadamard product factor in each block, preserving a matched LoRA-equivalent total rank with adapter-free merged inference. On a synthetic target, BoHA at per-block rank rb=1 exactly reconstructs an update that requires rank b² under the global W0-coupled Hadamard parameterization. Across Llama-3.2-1B/3B, Mistral-7B, and Gemma-2-9B on commonsense and arithmetic reasoning tasks, BoHA outperforms LoRA across all matched-budget single-task averages and remains competitive with the strongest Hadamard baseline. On a Llama-3.2-3B commonsense to arithmetic continual-learning diagnostic, BoHA retains 57.66 percent
What carries the argument
Blockwise W0-coupled Hadamard product adapter: the frozen weight is split into a b by b grid and each block receives its own low-rank Hadamard factor, keeping total rank matched to LoRA while allowing merged inference.
If this is right
- BoHA achieves higher single-task accuracy than LoRA at the same parameter budget on commonsense and arithmetic reasoning.
- In sequential adaptation the method retains substantially more first-stage performance than additive W0-free controls.
- The blockwise construction still permits exact reconstruction of higher-rank updates using only rank-1 factors per block.
- Adapter-free merged inference remains possible, matching the deployment convenience of LoRA.
- The approach scales across model sizes from 1B to 9B parameters without changing the core design.
Where Pith is reading between the lines
- Spatial partitioning may reduce destructive interference between successive tasks more effectively than global low-rank updates.
- The same blockwise idea could be tested on vision or multimodal models where weight matrices have clear spatial structure.
- Choosing block size b as a hyperparameter might trade off between local flexibility and total parameter count in longer task sequences.
Load-bearing premise
Partitioning W0 into blocks and learning independent low-rank Hadamard factors per block preserves the effective rank of the adaptation and enables adapter-free merged inference.
What would settle it
If, on the reported Llama-3.2-3B commonsense-to-arithmetic diagnostic, BoHA fails to exceed the W0-free additive-control mean first-stage accuracy while matching second-stage plasticity, the retention advantage claim is falsified.
Figures







read the original abstract
Parameter-efficient fine-tuning (PEFT) of large language models trains a small task-specific parameter set while keeping the pretrained model frozen. The dominant Low-Rank Adaptation (LoRA) family makes this trade-off practical; however, evaluations under the same parameter budget assess single-task accuracy. In sequential adaptation settings, such evaluations should also measure how well performance on the first-stage task is retained after subsequent fine-tuning. To address this gap, we introduce BoHA, a blockwise $W_0$-coupled Hadamard product adapter that treats spatial support as an explicit design axis. BoHA partitions the frozen weight $W_0$ into a $b{\times}b$ grid and learns an independent low-rank Hadamard product factor in each block, preserving a matched LoRA-equivalent total rank with adapter-free merged inference. On a synthetic target, BoHA at per-block rank $r_b{=}1$ exactly reconstructs an update that requires rank $b^2$ under the global $W_0$-coupled Hadamard parameterization. Across Llama-3.2-1B/3B, Mistral-7B, and Gemma-2-9B on commonsense and arithmetic reasoning tasks, BoHA outperforms LoRA across all matched-budget single-task averages and remains competitive with the strongest Hadamard baseline. On a Llama-3.2-3B commonsense $\to$ arithmetic continual-learning diagnostic, BoHA retains $57.66\%$ first-stage accuracy and exceeds the $W_0$-free additive-control mean by $15.23\%$ under matched second-stage plasticity. These results demonstrate that blockwise $W_0$-coupled Hadamard adaptation is a competitive PEFT design choice when retention under sequential adaptation is part of the objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BoHA, a blockwise Hadamard product adaptation method for parameter-efficient fine-tuning of LLMs. It partitions each frozen weight matrix W0 into a b×b grid and learns an independent low-rank Hadamard product factor per block. The central claims are that this design preserves a matched LoRA-equivalent total parameter budget, enables adapter-free merged inference, outperforms LoRA on single-task averages across Llama-3.2-1B/3B, Mistral-7B and Gemma-2-9B on commonsense and arithmetic tasks, and improves retention in a Llama-3.2-3B commonsense-to-arithmetic continual-learning diagnostic (57.66% first-stage retention and +15.23% over the W0-free additive control under matched second-stage plasticity). A synthetic reconstruction experiment is presented to show that per-block rank r_b=1 suffices for an update that would require global rank b² under a non-blockwise W0-coupled Hadamard parameterization.
Significance. If the empirical claims and the rank-preservation argument hold, the work supplies a new explicit design axis (spatial partitioning) for PEFT adapters that may be useful when retention after sequential adaptation is an objective. The synthetic reconstruction result is a clear, falsifiable verification of one claimed advantage of the blockwise structure. The continual-learning diagnostic addresses a relevant evaluation gap beyond single-task accuracy that is rarely reported in the LoRA literature.
major comments (2)
- [§3] §3 (Method): The claim that the b×b blockwise low-rank Hadamard factors preserve a LoRA-equivalent total rank (same parameter budget) while producing the reported retention gains is load-bearing for the central contribution. Because the update is multiplicative (ΔW = W0 ⊙ (UV) per block), the realized update magnitude is scaled by the local |W0| values in each block. Pretrained LLM weights are heterogeneous across blocks, so this introduces spatially varying effective plasticity with no counterpart in additive LoRA. The synthetic target only verifies exact reconstruction for a contrived low-rank case and does not test whether the scaling distorts gradient flow or retention on the Llama-3.2-3B commonsense→arithmetic diagnostic. A quantitative comparison of effective per-block update norms or an ablation that normalizes by block magnitude would be required to attribute the 57.66% retention
- [§4] §4 (Experiments, continual-learning diagnostic): The reported 57.66% first-stage retention and 15.23% improvement over the W0-free additive-control mean are presented without error bars, number of random seeds, or explicit confirmation that data splits, learning rates, and second-stage training steps are identical across all compared methods. These details are necessary to establish that the gains are attributable to the blockwise Hadamard structure rather than uncontrolled differences in plasticity or optimization.
minor comments (2)
- [Abstract] Abstract: The phrase 'W0-free additive-control mean' is used without a parenthetical definition or forward reference; a one-sentence clarification would improve standalone readability.
- [§3] Notation: The relation between per-block rank r_b and the global LoRA rank r should be stated explicitly (e.g., total parameters = b² · r_b · (d_in + d_out) versus LoRA's 2r · (d_in + d_out)) in a small comparison table or equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: [§3] §3 (Method): The claim that the b×b blockwise low-rank Hadamard factors preserve a LoRA-equivalent total rank (same parameter budget) while producing the reported retention gains is load-bearing for the central contribution. Because the update is multiplicative (ΔW = W0 ⊙ (UV) per block), the realized update magnitude is scaled by the local |W0| values in each block. Pretrained LLM weights are heterogeneous across blocks, so this introduces spatially varying effective plasticity with no counterpart in additive LoRA. The synthetic target only verifies exact reconstruction for a contrived low-rank case and does not test whether the scaling distorts gradient flow or retention on the Llama-3.2-3B commonsense→arithmetic diagnostic. A quantitative comparison of effective per-block update norms or an ablation that normalizes by block magnitude would be required to attribute the 57.66% ret
Authors: We agree that the multiplicative coupling introduces spatially varying scaling by local |W0| magnitudes, which differs from additive LoRA and is an intentional aspect of the W0-coupled design. This coupling is meant to leverage the pretrained weight structure for potentially better feature preservation during sequential adaptation. The synthetic experiment separately validates the rank-efficiency benefit of the blockwise parameterization. To address attribution of the retention results, we will add to the revised manuscript a quantitative comparison of effective per-block update norms across the Llama-3.2-3B diagnostic and an ablation that normalizes the Hadamard factors by block magnitude to isolate the contribution of the spatial partitioning. revision: yes
-
Referee: [§4] §4 (Experiments, continual-learning diagnostic): The reported 57.66% first-stage retention and 15.23% improvement over the W0-free additive-control mean are presented without error bars, number of random seeds, or explicit confirmation that data splits, learning rates, and second-stage training steps are identical across all compared methods. These details are necessary to establish that the gains are attributable to the blockwise Hadamard structure rather than uncontrolled differences in plasticity or optimization.
Authors: We acknowledge that the current reporting lacks these statistical and methodological details. In the revised version we will report error bars over multiple random seeds, state the number of seeds used, and explicitly confirm that data splits, learning rates, and second-stage training steps were held identical across all methods to support fair attribution of the observed retention differences. revision: yes
Circularity Check
No significant circularity; empirical method with independent validation
full rationale
The paper introduces BoHA as a blockwise Hadamard adapter design and supports its claims through direct empirical comparisons on single-task and continual-learning benchmarks against LoRA and Hadamard baselines. The abstract states the partitioning and rank-matching property as a design feature that enables adapter-free inference, without deriving performance metrics from fitted parameters or self-referential equations. The synthetic reconstruction result is presented as a verification of the blockwise structure's expressivity rather than a prediction forced by the method's own inputs. No load-bearing step reduces a claimed outcome to a self-definition, fitted input renamed as prediction, or self-citation chain; the reported retention and plasticity gains are measured outcomes on held-out task sequences.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-block rank r_b
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BHRA partitions W0 into a b×b grid and applies HiRA-style modulation independently within each block: ΔWij = W0,ij ⊙ (Bij Aij)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rank(ΔWBHRA) ≤ b r0 r while preserving the trainable parameter count r(m+n)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Large language models in medicine.Nature medicine, 29(8):1930–1940,
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature medicine, 29(8):1930–1940,
work page 1930
-
[2]
BloombergGPT: A Large Language Model for Finance
9 Blockwise Hadamard high-Rank AdaptationA PREPRINT Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Randlora: Full-rank parameter-efficient fine-tuning of large models.arXiv preprint arXiv:2502.00987,
Paul Albert, Frederic Z Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, and Ehsan Abbasnejad. Randlora: Full-rank parameter-efficient fine-tuning of large models.arXiv preprint arXiv:2502.00987,
-
[4]
Raghav Singhal, Kaustubh Ponkshe, Rohit Vartak, and Praneeth Vepakomma
URLhttps://openreview.net/forum?id=TwJrTz9cRS. Raghav Singhal, Kaustubh Ponkshe, Rohit Vartak, and Praneeth Vepakomma. Abba: Highly expressive hadamard product adaptation for large language models.arXiv preprint arXiv:2505.14238,
-
[5]
Yeonjoon Jung, Daehyun Ahn, Hyungjun Kim, Taesu Kim, and Eunhyeok Park
URLhttps://openreview.net/forum?id=lq62uWRJjiY. Yeonjoon Jung, Daehyun Ahn, Hyungjun Kim, Taesu Kim, and Eunhyeok Park. Gralora: Granular low-rank adaptation for parameter-efficient fine-tuning.arXiv preprint arXiv:2505.20355,
-
[6]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Ka-Wei Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models.arXiv preprint arXiv:2304.01933,
-
[9]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[10]
SocialIQA: Commonsense Reasoning about Social Interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions.arXiv preprint arXiv:1904.09728,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[11]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[12]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
10 Blockwise Hadamard high-Rank AdaptationA PREPRINT Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering.arXiv preprint arXiv:1809.02789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie- Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.ArXiv, abs/2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Gemma 2: Improving Open Language Models at a Practical Size
URLhttps://api.semanticscholar.org/CorpusID:263830494. Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Let- man, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45,
work page 2020
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Relation to GraLoRA and inference cost.Setting W0,ij =1 recovers GraLoRA with k=b , where the Hadamard stage disappears and the expression above reduces to the classic (2n−k)rT+ (2m−k)mT+ (k−1)mT form. In BHRA we precompute the masks Hij and fold them into W0,ij before deployment, so inference evaluates only the two low-rank GEMMs per block: FLOPs(adapter...
work page 2019
-
[23]
on arithmetic tasks. While we adopt most settings from prior work [Hu et al., 2023], we run targeted learning-rate sweeps to tune performance. For baselines we replicate the experimental protocols from LoRA [Hu et al., 2022], DoRA [Liu et al., 14 Blockwise Hadamard high-Rank AdaptationA PREPRINT 2024], HiRA [Huang et al., 2025], and ABBA [Singhal et al., ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.