Beyond Classification Accuracy: Neural-MedBench and the Need for Deeper Reasoning Benchmarks
Pith reviewed 2026-05-18 13:22 UTC · model grok-4.3
pith:TIR5IYQ4 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{TIR5IYQ4}
Prints a linked pith:TIR5IYQ4 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Vision-language models show major reasoning shortfalls on a new compact neurology benchmark despite high scores on standard tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
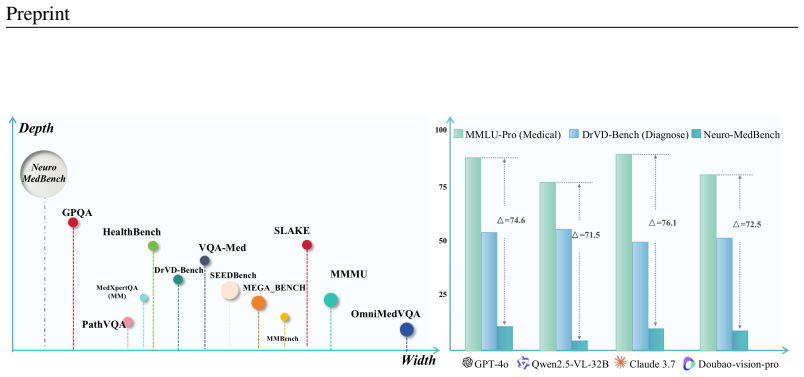
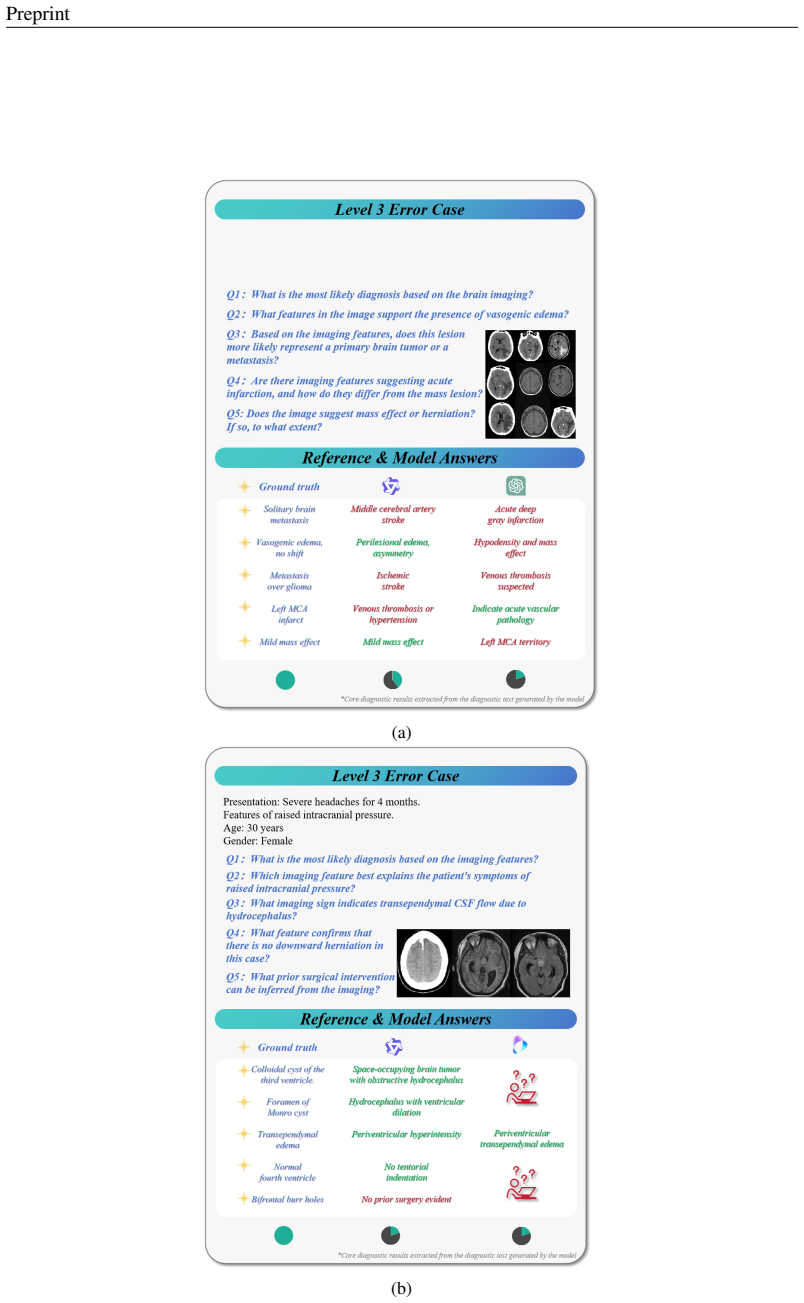
The central discovery is that reasoning failures dominate the shortcomings of current vision-language models in clinical settings, as revealed by the new Neural-MedBench benchmark which integrates multimodal neurology data and employs a hybrid scoring method to evaluate performance on differential diagnosis, lesion recognition, and rationale generation tasks. This performance drop compared to traditional datasets underscores the limitations of accuracy-centric evaluations and supports the adoption of a Two-Axis Evaluation Framework for balanced assessment of model capabilities.
What carries the argument
Neural-MedBench, a reasoning-intensive benchmark for neurology that integrates multi-sequence MRI scans, electronic health records, and clinical notes, evaluated via a hybrid scoring pipeline of LLM graders, clinician validation, and semantic similarity metrics.
If this is right
- Future medical AI benchmarks should incorporate depth-oriented reasoning tasks in addition to breadth-oriented accuracy metrics.
- Model developers should focus on improving reasoning capabilities rather than just perceptual accuracy to achieve clinical utility.
- The Two-Axis Evaluation Framework can guide the design of more effective and trustworthy diagnostic AI systems.
- Open release of such benchmarks enables community-driven improvements and cost-effective testing.
Where Pith is reading between the lines
- Applying similar depth-focused testing in other high-stakes domains like radiology or pathology could uncover comparable reasoning gaps.
- Training regimes that incorporate feedback from reasoning benchmarks like this may lead to faster progress toward clinically reliable models.
- Without such benchmarks, there is a risk that AI systems are deployed in medicine based on misleading performance signals.
Load-bearing premise
The hybrid scoring pipeline combining LLM-based graders, clinician validation, and semantic similarity metrics provides a reliable and unbiased measure of true clinical reasoning ability.
What would settle it
Re-running the evaluations using only expert clinician scorers without LLM or semantic components and finding no significant performance drop or a shift to perceptual errors as the main issue would challenge the central findings.
Figures










read the original abstract
Recent advances in vision-language models (VLMs) have achieved remarkable performance on standard medical benchmarks, yet their true clinical reasoning ability remains unclear. Existing datasets predominantly emphasize classification accuracy, creating an evaluation illusion in which models appear proficient while still failing at high-stakes diagnostic reasoning. We introduce Neural-MedBench, a compact yet reasoning-intensive benchmark specifically designed to probe the limits of multimodal clinical reasoning in neurology. Neural-MedBench integrates multi-sequence MRI scans, structured electronic health records, and clinical notes, and encompasses three core task families: differential diagnosis, lesion recognition, and rationale generation. To ensure reliable evaluation, we develop a hybrid scoring pipeline that combines LLM-based graders, clinician validation, and semantic similarity metrics. Through systematic evaluation of state-of-the-art VLMs, including GPT-4o, Claude-4, and MedGemma, we observe a sharp performance drop compared to conventional datasets. Error analysis shows that reasoning failures, rather than perceptual errors, dominate model shortcomings. Our findings highlight the necessity of a Two-Axis Evaluation Framework: breadth-oriented large datasets for statistical generalization, and depth-oriented, compact benchmarks such as Neural-MedBench for reasoning fidelity. We release Neural-MedBench at https://neuromedbench.github.io/ as an open and extensible diagnostic testbed, which guides the expansion of future benchmarks and enables rigorous yet cost-effective assessment of clinically trustworthy AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Neural-MedBench, a compact multimodal benchmark for neurology that integrates multi-sequence MRI, EHR data, and clinical notes across three task families: differential diagnosis, lesion recognition, and rationale generation. It evaluates state-of-the-art VLMs including GPT-4o, Claude-4, and MedGemma, reports sharp performance drops relative to conventional classification-focused datasets, and attributes the gaps primarily to reasoning failures via a hybrid scoring pipeline of LLM graders, clinician validation, and semantic similarity. The work proposes a Two-Axis Evaluation Framework (breadth-oriented large datasets plus depth-oriented compact benchmarks) and releases the benchmark publicly to support more rigorous assessment of clinical reasoning in VLMs.
Significance. If the core results hold, the paper makes a useful contribution by exposing the limitations of accuracy-centric medical benchmarks and advocating for reasoning-focused evaluation. The open release of Neural-MedBench and the emphasis on error analysis beyond perception provide a practical testbed that could help steer development toward clinically trustworthy multimodal models. The work is strengthened by its use of external models on newly constructed tasks rather than self-referential metrics.
major comments (1)
- [Hybrid Scoring Pipeline / Evaluation Methodology] The attribution of performance drops to reasoning failures (rather than perceptual errors) depends on the hybrid scoring pipeline producing reliable labels. The manuscript provides no reported inter-rater agreement statistics (e.g., Cohen’s kappa or percentage agreement) between multiple clinicians, nor quantitative validation of the LLM graders against independent expert judgments. This is load-bearing for the error analysis and the claim that Neural-MedBench isolates reasoning fidelity; without such evidence the observed gaps could partly reflect grader artifacts or inconsistencies in the Two-Axis Framework comparisons.
minor comments (2)
- [Abstract and Experiments] Clarify the exact version of the Claude model evaluated (listed as “Claude-4”); if this refers to a future or internal release, state the access date and any relevant caveats.
- [Benchmark Description] The benchmark release link is welcome, but the manuscript would benefit from a table or appendix listing the number of cases per task family, annotation protocol, and any exclusion criteria to support immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential contribution of Neural-MedBench in highlighting the limitations of accuracy-centric medical benchmarks. We appreciate the emphasis on the need for rigorous validation of our evaluation methodology. We address the major comment below and have prepared revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: The attribution of performance drops to reasoning failures (rather than perceptual errors) depends on the hybrid scoring pipeline producing reliable labels. The manuscript provides no reported inter-rater agreement statistics (e.g., Cohen’s kappa or percentage agreement) between multiple clinicians, nor quantitative validation of the LLM graders against independent expert judgments. This is load-bearing for the error analysis and the claim that Neural-MedBench isolates reasoning fidelity; without such evidence the observed gaps could partly reflect grader artifacts or inconsistencies in the Two-Axis Framework comparisons.
Authors: We agree that quantitative validation of the hybrid scoring pipeline is critical for supporting the attribution of errors to reasoning failures. The original manuscript described the pipeline components (LLM graders, clinician validation, and semantic similarity) but omitted explicit inter-rater agreement statistics and direct comparisons of LLM outputs to expert judgments. This was an oversight in the initial submission. In the revised manuscript, we will report Cohen’s kappa and percentage agreement between the clinicians who performed validation. We will also include a quantitative validation of the LLM grader against independent clinician judgments on a held-out subset of cases. These additions will provide the necessary evidence that the error analysis reflects model shortcomings rather than grader inconsistencies, thereby reinforcing the comparisons within the Two-Axis Evaluation Framework. revision: yes
Circularity Check
No significant circularity in empirical benchmark and evaluation
full rationale
The paper introduces Neural-MedBench as a new dataset and applies a hybrid scoring pipeline (LLM graders + clinician validation + semantic metrics) to evaluate external VLMs on novel tasks. No equations, fitted parameters, or predictions are defined in terms of the target results; performance drops and error attributions are direct observations on held-out data rather than reductions by construction. The Two-Axis Framework is presented as an organizing recommendation, not a derived necessity from self-referential inputs. Self-citations, if present, are not load-bearing for the central empirical claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hybrid scoring pipeline combining LLM-based graders, clinician validation, and semantic similarity metrics reliably captures clinical reasoning quality.
invented entities (1)
-
Two-Axis Evaluation Framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the Two-Axis Evaluation Framework... Breadth... Depth... Neural-MedBench... hybrid scoring pipeline that combines LLM-based graders, clinician validation, and semantic similarity metrics... Error analysis shows that reasoning failures, rather than perceptual errors, dominate model shortcomings.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Task Families... Differential Diagnosis, Lesion Recognition, Rationale Generation... stratified into three difficulty levels
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023. URL https://arxiv.org/abs/2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Christ, Eugene V orontsov, Gabriel Chlebus, Holger Chen, Qi Dou, et al
Patrick Bilic, Patrick F Christ, Eugene Vorontsov, Grzegorz Chlebus, Hao Chen, Qi Dou, Chi-Wing Fu, Xu Han, Pheng-Ann Heng, Jürgen Hesser, et al. The liver tumor segmentation benchmark (lits). arXiv preprint arXiv:1901.04056, 2019
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jadon Geathers, Yann Hicke, Colleen Chan, Niroop Rajashekar, Sarah Young, Justin Sewell, Susannah Cornes, Rene F Kizilcec, and Dennis Shung. Benchmarking generative ai for scoring medical student interviews in objective structured clinical examinations (osces). In International Conference on Artificial Intelligence in Education, pp.\ 231--245. Springer, 2025
work page 2025
-
[6]
Large language models lack essential metacognition for reliable medical reasoning
Maxime Griot, Coralie Hemptinne, Jean Vanderdonckt, and Demet Yuksel. Large language models lack essential metacognition for reliable medical reasoning. Nature communications, 16 0 (1): 0 642, 2025
work page 2025
-
[7]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Zexuan He, Yifan Peng, Le Lu, Xiaosong Wang, and Ronald M Summers. Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[8]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. arXiv preprint arXiv:2402.09181, 2024
-
[10]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. Proceedings of the AAAI Conference on Artificial Intelligence, 33 0 (01): 0 590--597, 2019
work page 2019
-
[11]
Heartcare Suite: Multi-dimensional Understanding ECG with Raw Multi- lead Signal Modeling
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven Q H Truong, Du Nguyen Duong, Tan Bui, Pierre Chambon, Yuhao Zhang, Matthew P Lungren, Andrew Y Ng, et al. Radgraph: Extracting clinical entities and relations from radiology reports. arXiv preprint arXiv:2106.14463, 2021
-
[12]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports
Alistair E W Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data, 6 0 (1): 0 317, 2019
work page 2019
-
[13]
Rad-bench: Evaluating large language models capabilities in retrieval augmented dialogues
Tzu-Lin Kuo, Feng-Ting Liao, Mu-Wei Hsieh, Fu-Chieh Chang, Po-Chun Hsu, and Da-Shan Shiu. Rad-bench: Evaluating large language models capabilities in retrieval augmented dialogues. arXiv preprint arXiv:2409.12558, 2024
-
[14]
A dataset of clinically generated visual questions and answers about radiology images
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images. Scientific data, 5 0 (1): 0 1--10, 2018
work page 2018
-
[15]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In NeurIPS 23 Datasets & Benchmarks Track (Spotlight), 2023. URL https://github.com/microsoft/LLaVA-Med
work page 2023
-
[16]
The multimodal brain tumor image segmentation benchmark (brats)
Bjoern H Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy-Cramer, Keyvan Farahani, Justin Kirby, Yuliya Burren, Nils Porz, Johannes Slotboom, Roland Wiest, et al. The multimodal brain tumor image segmentation benchmark (brats). IEEE Transactions on Medical Imaging, 34 0 (10): 0 1993--2024, 2015
work page 1993
-
[17]
Med-flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Cyril Zakka, Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, and Jure Leskovec. Med-flamingo: a multimodal medical few-shot learner. In Stefan Hegselmann, Antonio Parziale, Divya Shanmugam, Shengpu Tang, Mercy Nyamewaa Asiedu, Serina Chang, Tom Hartvigsen, and Harvineet Singh (eds.), Proceeding...
work page 2023
-
[18]
OpenAI. Gpt-4o system card, 2024. URL https://arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
u ckert, Louise Bloch, Raphael Br \
Johannes R \"u ckert, Louise Bloch, Raphael Br \"u ngel, Ahmad Idrissi-Yaghir, Henning Sch \"a fer, Cynthia S Schmidt, Sven Koitka, Obioma Pelka, Asma Ben Abacha, Alba G. Seco de Herrera, et al. Rocov2: Radiology objects in context version 2, an updated multimodal image dataset. Scientific Data, 11 0 (1): 0 688, 2024
work page 2024
-
[20]
Richard M Schwartzstein. Clinical reasoning and artificial intelligence: can ai really think? Transactions of the American Clinical and Climatological Association, 134: 0 133, 2024
work page 2024
-
[21]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C \' an Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Grad-cam: visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: visual explanations from deep networks via gradient-based localization. International journal of computer vision, 128: 0 336--359, 2020
work page 2020
-
[23]
Arnaud A A Setio, Andrea Traverso, Timo de Bel, Max S Berens, Chris van den Bogaard, Piergiorgio Cerello, Hoo-Chang Chen, Qi Dou, Maria E Fantacci, Pierre Geurts, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medical Image Analysis, 42: 0 1--13, 2017
work page 2017
-
[24]
Assessment of clinical reasoning during a high stakes medical student osce
Jeffrey Siegelman, Lisa Bernstein, Jennifer Goedken, Linda Lewin, Jason Schneider, Martha Ward, and Hugh Stoddard. Assessment of clinical reasoning during a high stakes medical student osce. Perspectives on Medical Education, 13 0 (1): 0 629, 2024
work page 2024
-
[25]
Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Y Ng, and Matthew P Lungren. Chexbert: combining automatic labelers and expert annotations for accurate radiology report labeling using bert. arXiv preprint arXiv:2004.09167, 2020
-
[26]
J. Smith et al. Expert-of-experts verification and alignment (eval): Clinician-augmented evaluation of large language models in gastrointestinal bleeding. NPJ Digital Medicine, 8 0 (1): 0 1589, 2025
work page 2025
-
[27]
Medagentsbench: Benchmarking thinking models and agent frameworks for complex medical reasoning
Xiangru Tang, Daniel Shao, Jiwoong Sohn, Jiapeng Chen, Jiayi Zhang, Jinyu Xiang, Fang Wu, Yilun Zhao, Chenglin Wu, Wenqi Shi, et al. Medagentsbench: Benchmarking thinking models and agent frameworks for complex medical reasoning. arXiv preprint arXiv:2503.07459, 2025
-
[28]
Doubao Team. The doubao visual language model officially released with general model capability fully comparable to gpt-4o, 2024. URL https://team.doubao.com/
work page 2024
-
[29]
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[30]
Stefan Winzeck, Ali Hakim, Richard McKinley, Joana Pinto, Victor Alves, Carlos Silva, Mauricio Reyes, Alessandro Crimi, Bjoern Menze, Daniel Rueckert, et al. Isles 2015—a public evaluation benchmark for ischemic stroke lesion segmentation from multispectral mri. Medical Image Analysis, 35: 0 250--269, 2017
work page 2015
-
[31]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data. arXiv preprint arXiv:2308.02463, 2023. URL https://arxiv.org/abs/2308.02463
-
[32]
Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data, 10 0 (1): 0 41, 2023
work page 2023
-
[33]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[34]
Y. Zhang et al. Llmeval-med: Benchmarking large language models for clinical evaluation with expert-designed scenarios. arXiv preprint arXiv:2506.04078, 2025
-
[35]
Yuxuan Zhang, Yifan Wang, Ya Zhang, Yanfeng Wang, and Liang He. Medfmc: A real-world dataset and benchmark for foundation model adaptation in medical image classification. Scientific Data, 10 0 (1): 0 1--11, 2023
work page 2023
-
[36]
Medgr ^ 2 : Breaking the data barrier for medical reasoning via generative reward learning
Weihai Zhi, Jiayan Guo, and Shangyang Li. Medgr ^ 2 : Breaking the data barrier for medical reasoning via generative reward learning. arXiv preprint arXiv:2508.20549, 2025
-
[37]
Multifaceteval: Multifaceted evaluation to probe llms in mastering medical knowledge
Yuxuan Zhou, Xien Liu, Chen Ning, and Ji Wu. Multifaceteval: Multifaceted evaluation to probe llms in mastering medical knowledge. arXiv preprint arXiv:2406.02919, 2024
-
[38]
Diagnosisarena: Benchmarking diagnostic reasoning for large language models
Yakun Zhu, Zhongzhen Huang, Linjie Mu, Yutong Huang, Wei Nie, Jiaji Liu, Shaoting Zhang, Pengfei Liu, and Xiaofan Zhang. Diagnosisarena: Benchmarking diagnostic reasoning for large language models. arXiv preprint arXiv:2505.14107, 2025
-
[39]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[40]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[41]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[42]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.