Transformers Can Learn Connectivity in Some Graphs but Not Others
Pith reviewed 2026-05-18 12:43 UTC · model grok-4.3
The pith
Transformers learn to infer connectivity in low-dimensional grid graphs from training data but fail when graphs have many disconnected components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Transformers trained on the connectivity task succeed on directed grid graphs that admit low-dimensional embeddings from which paths are readily recoverable, with higher grid dimensions making the task harder; the same models fail to learn the task on non-grid graphs that contain a large number of disconnected components.
What carries the argument
Synthetic directed graphs built as grids of varying dimensionality, with training and test queries that ask whether one node reaches another.
If this is right
- Larger models show steadily better generalization to unseen grid graphs.
- Grid dimensionality is a reliable predictor of task difficulty, with low dimensions learned more readily than high ones.
- Absence of grid structure combined with many disconnected components prevents learning the connectivity rule.
- Connectivity becomes learnable precisely when it can be read off from low-dimensional node embeddings.
Where Pith is reading between the lines
- If causal chains in language data can be approximated by low-dimensional grids, scaling and structured pretraining may suffice for transitive reasoning in LLMs.
- The same training regime could be applied to other relational properties such as shortest paths or cycles inside similarly structured graphs.
- Persistent failure on disconnected graphs indicates that transformers may default to treating separate components independently unless the data supplies explicit global structure.
Load-bearing premise
That results on these hand-constructed grid and component graphs reveal how transformers will handle transitive relations in natural language or real causal data.
What would settle it
A large transformer trained on low-dimensional grid connectivity queries that then fails to predict paths correctly on new low-dimensional grids of comparable size while succeeding on graphs with many components.
Figures








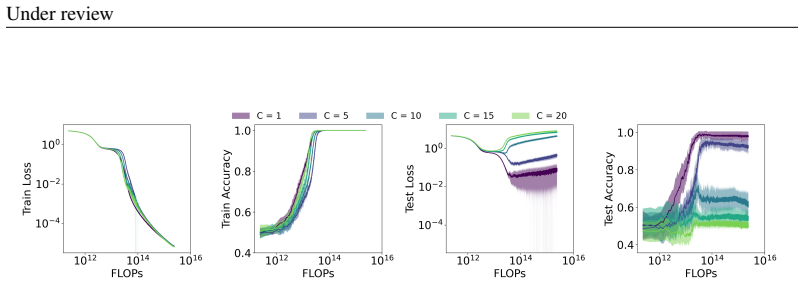

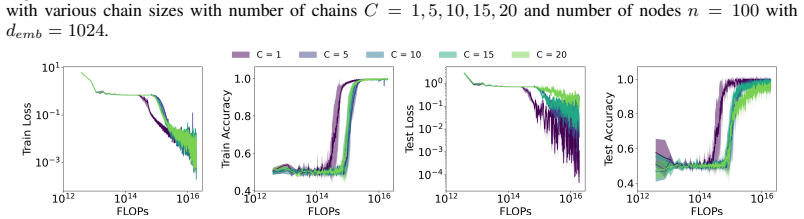

read the original abstract
Reasoning capability is essential to ensure the factual correctness of the responses of transformer-based Large Language Models (LLMs), and robust reasoning about transitive relations is instrumental in many settings, such as causal inference. Hence, it is essential to investigate the capability of transformers in the task of inferring transitive relations (e.g., knowing A causes B and B causes C, then A causes C). The task of inferring transitive relations is equivalent to the task of connectivity in directed graphs (e.g., knowing there is a path from A to B, and there is a path from B to C, then there is a path from A to C). Past research focused on whether transformers can learn to infer transitivity from in-context examples provided in the input prompt. However, transformers' capability to infer transitive relations from training examples and how scaling affects the ability is unexplored. In this study, we seek to answer this question by generating directed graphs to train transformer models of varying sizes and evaluate their ability to infer transitive relations for various graph sizes. Our findings suggest that transformers are capable of learning connectivity on "grid-like'' directed graphs where each node can be embedded in a low-dimensional subspace, and connectivity is easily inferable from the embeddings of the nodes. We find that the dimensionality of the underlying grid graph is a strong predictor of transformers' ability to learn the connectivity task, where higher-dimensional grid graphs pose a greater challenge than low-dimensional grid graphs. In addition, we observe that increasing the model scale leads to increasingly better generalization to infer connectivity over grid graphs. However, if the graph is not a grid graph and contains many disconnected components, transformers struggle to learn the connectivity task, especially when the number of components is large.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically investigates whether transformer models can learn to infer transitive relations by training on the task of determining connectivity (existence of a directed path) in synthetic directed graphs. Graphs include 'grid-like' constructions of varying dimensionality (where nodes admit low-dimensional embeddings from which connectivity is inferable) as well as graphs with many disconnected components. Experiments vary model size and graph scale, reporting that low-dimensional grids are learnable with performance improving under scaling, while higher-dimensional grids and graphs with large numbers of components are not.
Significance. If the central patterns are robust, the work supplies concrete evidence that transformers possess inductive biases favoring certain low-dimensional structured graphs for connectivity/transitivity tasks relevant to causal and logical reasoning in LLMs. The scaling results and the contrast between grid and non-grid families would be useful additions to the literature on transformer reasoning limits.
major comments (2)
- [Abstract] Abstract: the claim that 'the dimensionality of the underlying grid graph is a strong predictor of transformers' ability to learn the connectivity task' is load-bearing for the central thesis, yet the reported experiments do not appear to include ablations that hold |V| or edge density fixed while varying dimension. Standard grid constructions couple dimension to node count (s^d nodes for side length s), so the observed performance drop could be driven by increased problem scale rather than the low-dimensional embedding property itself.
- [Methods] Methods / Experimental details: the abstract and findings reference consistent patterns across model sizes and graph types, but the manuscript provides insufficient information on training hyperparameters, the precise procedure for generating the directed grid graphs and disconnected-component graphs, statistical tests, or error bars. These omissions make it impossible to verify reproducibility or rule out confounds in the reported generalization results.
minor comments (1)
- [Abstract] Abstract: the term 'grid-like' directed graphs is used without a concise definition or diagram; a brief characterization of the embedding property and edge directionality would improve clarity for readers unfamiliar with the construction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have identified important opportunities to strengthen the clarity and robustness of our manuscript. We address each major comment below and describe the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the dimensionality of the underlying grid graph is a strong predictor of transformers' ability to learn the connectivity task' is load-bearing for the central thesis, yet the reported experiments do not appear to include ablations that hold |V| or edge density fixed while varying dimension. Standard grid constructions couple dimension to node count (s^d nodes for side length s), so the observed performance drop could be driven by increased problem scale rather than the low-dimensional embedding property itself.
Authors: We thank the referee for this important observation on a potential confound in our experimental design. Our current results rely on standard grid constructions in which dimensionality and node count are coupled. We agree that additional controlled experiments are needed to isolate the role of dimensionality. In the revised manuscript we will add new ablations that hold |V| approximately fixed across dimensions (by adjusting side lengths for 2D, 3D, and 4D grids) while also reporting edge densities for each family. These results will be presented alongside the original scaling experiments to better support the claim that low-dimensional structure, rather than scale alone, drives learnability. revision: yes
-
Referee: [Methods] Methods / Experimental details: the abstract and findings reference consistent patterns across model sizes and graph types, but the manuscript provides insufficient information on training hyperparameters, the precise procedure for generating the directed grid graphs and disconnected-component graphs, statistical tests, or error bars. These omissions make it impossible to verify reproducibility or rule out confounds in the reported generalization results.
Authors: We acknowledge that the current manuscript omits several critical experimental details required for reproducibility. In the revised version we will substantially expand the Methods section to include: (i) all training hyperparameters (learning rate schedule, batch size, optimizer, number of epochs, and early-stopping criteria); (ii) the exact generative procedures for both the directed grid graphs (including edge directionality rules and connectivity oracle) and the disconnected-component graphs (including how component sizes and counts are sampled); and (iii) statistical reporting (number of random seeds, error bars as standard deviation across runs, and any hypothesis tests performed). These additions will enable full verification of the reported generalization patterns. revision: yes
Circularity Check
No circularity: purely empirical results on synthetic graphs
full rationale
The paper reports direct experimental outcomes from training and evaluating transformers on generated directed graphs for connectivity inference. No derivations, equations, or first-principles results are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Claims about grid dimensionality as a predictor rest on held-out performance comparisons across explicitly constructed graph families, with no load-bearing step that renames inputs as predictions or imports uniqueness via prior self-work. The analysis is self-contained against external benchmarks of model training and evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Connectivity in directed graphs is equivalent to inferring transitive relations
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hypothesize that transformers are more likely to learn to infer connectivity over graphs whose nodes are embeddable into a low-dimensional subspace such that connectivity can be easily inferred from the embedding of each node. ... A grid graph with dimensionality k ...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
How does llm reasoning work for code? a survey and a call to action
Ira Ceka, Saurabh Pujar, Irene Manotas, Gail Kaiser, Baishakhi Ray, and Shyam Ramji. How does llm reasoning work for code? a survey and a call to action. arXiv preprint arXiv:2506.13932, 2025
-
[3]
Talk like a graph: Encoding graphs for large language models
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models. ICLR, 2024
work page 2024
-
[4]
Test of time: A benchmark for evaluating llms on temporal reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. Test of time: A benchmark for evaluating llms on temporal reasoning. ICLR, 2025
work page 2025
-
[5]
Compute-optimal llms provably generalize better with scale
Marc Finzi, Sanyam Kapoor, Diego Granziol, Anming Gu, Christopher De Sa, J Zico Kolter, and Andrew Gordon Wilson. Compute-optimal llms provably generalize better with scale. ICML, 2025
work page 2025
-
[6]
Reasoning in large language models through symbolic math word problems
Vedant Gaur and Nikunj Saunshi. Reasoning in large language models through symbolic math word problems. ACL, 2024
work page 2024
-
[7]
Investigating the robustness of deductive reasoning with large language models
Fabian Hoppe, Filip Ilievski, and Jan-Christoph Kalo. Investigating the robustness of deductive reasoning with large language models. arXiv preprint arXiv:2502.04352, 2025
-
[8]
Cladder: Assessing causal reasoning in language models
Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, et al. Cladder: Assessing causal reasoning in language models. NeurIPS, 2023
work page 2023
-
[9]
Can large language models infer causation from correlation? ICLR, 2024
Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, and Bernhard Sch \"o lkopf. Can large language models infer causation from correlation? ICLR, 2024
work page 2024
-
[10]
Transformers are graph neural networks
Chaitanya K Joshi. Transformers are graph neural networks. arXiv preprint arXiv:2506.22084, 2025
-
[11]
Llms are prone to fallacies in causal inference
Nitish Joshi, Abulhair Saparov, Yixin Wang, and He He. Llms are prone to fallacies in causal inference. EMNLP, 2024
work page 2024
-
[12]
Scaling laws for neural language models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. ICLR, 2022
work page 2022
-
[13]
An analysis of decoding methods for llm-based agents for faithful multi-hop question answering
Alexander Murphy, Mohd Sanad Zaki Rizvi, Aden Haussmann, Ping Nie, Guifu Liu, Aryo Pradipta Gema, and Pasquale Minervini. An analysis of decoding methods for llm-based agents for faithful multi-hop question answering. arXiv preprint arXiv:2503.23415, 2025
-
[14]
gzip predicts data-dependent scaling laws
Rohan Pandey. gzip predicts data-dependent scaling laws. arXiv preprint arXiv:2405.16684, 2024
-
[15]
Scaling laws of synthetic data for language models
Zeyu Qin, Qingxiu Dong, Xingxing Zhang, Li Dong, Xiaolong Huang, Ziyi Yang, Mahmoud Khademi, Dongdong Zhang, Hany Hassan Awadalla, Yi R Fung, et al. Scaling laws of synthetic data for language models. COLM, 2025
work page 2025
-
[16]
Compute optimal scaling of skills: Knowledge vs reasoning
Nicholas Roberts, Niladri Chatterji, Sharan Narang, Mike Lewis, and Dieuwke Hupkes. Compute optimal scaling of skills: Knowledge vs reasoning. arXiv preprint arXiv:2503.10061, 2025
-
[17]
Understanding transformer reasoning capabilities via graph algorithms
Clayton Sanford, Bahare Fatemi, Ethan Hall, Anton Tsitsulin, Mehran Kazemi, Jonathan Halcrow, Bryan Perozzi, and Vahab Mirrokni. Understanding transformer reasoning capabilities via graph algorithms. NeurIPS, 2024
work page 2024
-
[18]
Transformers struggle to learn to search
Abulhair Saparov, Srushti Pawar, Shreyas Pimpalgaonkar, Nitish Joshi, Richard Yuanzhe Pang, Vishakh Padmakumar, Seyed Mehran Kazemi, Najoung Kim, and He He. Transformers struggle to learn to search. ICLR, 2025
work page 2025
-
[19]
Causalgraph2llm: Evaluating llms for causal queries
Ivaxi Sheth, Bahare Fatemi, and Mario Fritz. Causalgraph2llm: Evaluating llms for causal queries. NAACL, 2025
work page 2025
-
[20]
Can large language models act as symbolic reasoners? arXiv preprint arXiv:2410.21490, 2024
Rob Sullivan and Nelly Elsayed. Can large language models act as symbolic reasoners? arXiv preprint arXiv:2410.21490, 2024
-
[21]
Alphageometry: An olympiad-level ai system for geometry
Trieu Trinh and Thang Luong. Alphageometry: An olympiad-level ai system for geometry. Google DeepMind, 17, 2024
work page 2024
-
[22]
Teaching transformers causal reasoning through axiomatic training
Aniket Vashishtha, Abhinav Kumar, Atharva Pandey, Abbavaram Gowtham Reddy, Kabir Ahuja, Vineeth N Balasubramanian, and Amit Sharma. Teaching transformers causal reasoning through axiomatic training. ICML, 2025
work page 2025
-
[23]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 2017
work page 2017
-
[24]
Do larger language models imply better reasoning? a pretraining scaling law for reasoning
Xinyi Wang, Shawn Tan, Mingyu Jin, William Yang Wang, Rameswar Panda, and Yikang Shen. Do larger language models imply better reasoning? a pretraining scaling law for reasoning. arXiv preprint arXiv:2504.03635, 2025
-
[25]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models. ICLR, 2025
work page 2025
-
[26]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. In ICML, 2020
work page 2020
-
[27]
Entropy law: The story behind data compression and llm performance
Mingjia Yin, Chuhan Wu, Yufei Wang, Hao Wang, Wei Guo, Yasheng Wang, Yong Liu, Ruiming Tang, Defu Lian, and Enhong Chen. Entropy law: The story behind data compression and llm performance. arXiv preprint arXiv:2407.06645, 2024
-
[28]
Causal parrots: Large language models may talk causality but are not causal
Matej Ze c evi \'c , Moritz Willig, Devendra Singh Dhami, and Kristian Kersting. Causal parrots: Large language models may talk causality but are not causal. TMLR, 2023
work page 2023
-
[29]
Can llm graph reasoning generalize beyond pattern memorization? EMNLP Findings, 2024
Yizhuo Zhang, Heng Wang, Shangbin Feng, Zhaoxuan Tan, Xiaochuang Han, Tianxing He, and Yulia Tsvetkov. Can llm graph reasoning generalize beyond pattern memorization? EMNLP Findings, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.