GRAPE: Let GRPO Supervise Query Rewriting by Ranking for Retrieval
Pith reviewed 2026-05-18 12:14 UTC · model grok-4.3
The pith
Ranking signals from a frozen retriever train an LLM to rewrite queries that better match the retriever's scoring behavior under distributional shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRAPE applies Grouped Relative Policy Optimization (GRPO) to fine-tune an LLM for query rewriting, where the reward measures the relative ranking success of the rewritten query compared with the original as judged by the frozen retriever. This alignment with the retriever's latent distribution counters the score inflation that occurs in naive similarity-based fine-tuning and produces consistent gains across shifted query types.
What carries the argument
Grouped Relative Policy Optimization (GRPO) driven by a corpus-relative ranking-based reward that compares rewritten and original queries in batches.
Load-bearing premise
The relative ranking comparisons supplied by the retriever give an accurate and unbiased signal for what counts as a good query rewrite.
What would settle it
Experiments on the reported benchmarks or similar ones showing no improvement or a drop in Recall@10 when GRAPE is used versus simple rewriting baselines would show the ranking supervision fails to deliver the claimed alignment.
Figures



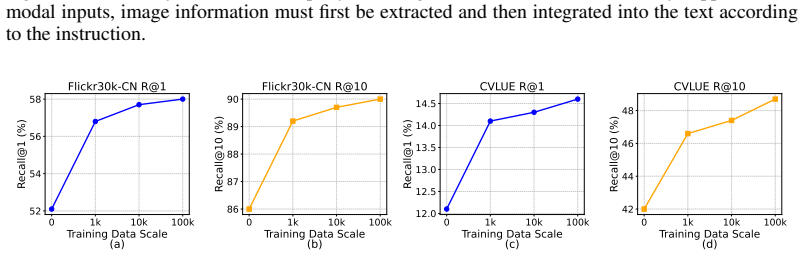



read the original abstract
The CLIP model has established itself as a cornerstone of large-scale retrieval systems. However, its performance often degrades under distributional shifts such as multilingual, long-form, or multimodal queries. To avoid the prohibitive costs associated with retriever retraining or corpus re-embedding, we propose GRAPE (Grouped Ranking-Aware Policy Optimization Enhancement), a plug-and-play approach that leverages LLM-based query rewriting to bridge these gaps. Unlike existing methods that lack explicit supervision, GRAPE integrates ranking signals into the rewriting LLM via Grouped Relative Policy Optimization (GRPO), ensuring rewritten queries are better aligned with the frozen retriever's latent distribution. Crucially, we identify a score inflation phenomenon in naive similarity-based finetuning - where irrelevant candidates receive indiscriminately high scores - and mitigate it with a novel corpus-relative ranking-based reward. Extensive experiments across multilingual (Flickr30k-CN, CVLUE, XM3600), long-form (Wikipedia), and multimodal (CIRR) benchmarks demonstrate that GRAPE consistently improves performance, achieving an average gain of 4.9% in Recall@10 without any modification to the underlying retriever. The code is available at https://github.com/mogulzhang/GRAPE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRAPE, a plug-and-play method for improving CLIP-based retrieval under distributional shifts (multilingual, long-form, multimodal) by using an LLM to rewrite queries. It integrates ranking signals from a frozen retriever into the LLM via Grouped Relative Policy Optimization (GRPO) and introduces a corpus-relative ranking-based reward to address score inflation observed in naive similarity finetuning. Experiments on benchmarks such as Flickr30k-CN, CVLUE, XM3600, Wikipedia, and CIRR report an average 4.9% gain in Recall@10 without modifying the retriever.
Significance. If the central claims hold, the work provides a practical way to adapt retrieval systems to query variations without retraining or re-embedding the corpus, which is valuable for real-world multimodal and multilingual applications. The use of GRPO with a ranking-derived reward and the public code release are positive aspects that support reproducibility and potential adoption.
major comments (3)
- [Abstract and §4] Abstract and §4: The central claim that the corpus-relative ranking-based reward specifically mitigates score inflation (indiscriminate high scores on irrelevants) is asserted but not isolated. Downstream Recall@10 gains alone do not demonstrate this; an ablation comparing the proposed reward against naive similarity finetuning and alternatives (e.g., margin-based or contrastive rewards) is needed to verify the mitigation effect and rule out new biases.
- [§3.2] §3.2 (GRPO and reward definition): The reward is described as corpus-relative and ranking-based, but it is unclear whether it requires full corpus access during training or only sampled groups. This detail is load-bearing for the practicality claim that the method remains efficient at inference without full corpus access.
- [§4] §4 (experiments): No details are provided on statistical significance testing, exact data splits, or hyperparameter tuning for GRPO and the reward. This undermines confidence in the reported 4.9% average Recall@10 gain and cross-benchmark consistency.
minor comments (2)
- [Abstract] The abstract mentions 'extensive experiments' but would benefit from a brief summary table of per-benchmark gains and baselines in the main text for quick assessment.
- [§3] Notation for the reward function (e.g., how relative ranking is computed within groups) should be formalized with an equation to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: The central claim that the corpus-relative ranking-based reward specifically mitigates score inflation (indiscriminate high scores on irrelevants) is asserted but not isolated. Downstream Recall@10 gains alone do not demonstrate this; an ablation comparing the proposed reward against naive similarity finetuning and alternatives (e.g., margin-based or contrastive rewards) is needed to verify the mitigation effect and rule out new biases.
Authors: We acknowledge that the manuscript identifies the score inflation phenomenon in naive similarity-based finetuning and positions the corpus-relative ranking reward as a mitigation strategy, but the current results focus on end-to-end Recall@10 improvements rather than isolating the reward's specific contribution. To directly address this, we will add a dedicated ablation study in the revised version comparing GRAPE's reward against naive similarity finetuning as well as margin-based and contrastive alternatives. This will provide clearer evidence for the mitigation effect and help rule out alternative explanations or new biases. revision: yes
-
Referee: [§3.2] §3.2 (GRPO and reward definition): The reward is described as corpus-relative and ranking-based, but it is unclear whether it requires full corpus access during training or only sampled groups. This detail is load-bearing for the practicality claim that the method remains efficient at inference without full corpus access.
Authors: We thank the referee for highlighting this ambiguity. The reward is computed using sampled groups of candidates drawn from the corpus during training; relative rankings are determined only within each sampled group rather than requiring access to the entire corpus. This sampling-based design keeps training efficient and preserves the plug-and-play property at inference, where the method requires no corpus access beyond the frozen retriever. We will revise §3.2 to state this explicitly. revision: yes
-
Referee: [§4] §4 (experiments): No details are provided on statistical significance testing, exact data splits, or hyperparameter tuning for GRPO and the reward. This undermines confidence in the reported 4.9% average Recall@10 gain and cross-benchmark consistency.
Authors: We agree that additional experimental details are necessary to support reproducibility and confidence in the reported gains. In the revised manuscript we will include: (i) results of statistical significance testing with standard deviations across multiple runs, (ii) the precise data splits employed for each benchmark, and (iii) the hyperparameter search and final values used for GRPO and the reward function. These additions will better substantiate the average 4.9% Recall@10 improvement and its consistency across benchmarks. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines GRAPE via GRPO applied to an LLM query rewriter, with the reward explicitly constructed from corpus-relative rankings produced by the separate frozen retriever. This reward signal is external to the policy being optimized and is not obtained by fitting parameters to the target Recall@10 metric or by re-expressing the alignment claim in terms of itself. Performance improvements are reported as empirical measurements on distinct multilingual, long-form, and multimodal test sets rather than as quantities forced by the reward definition. No self-definitional equations, fitted-input predictions, load-bearing self-citations, or imported uniqueness theorems appear in the abstract or described method; the central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ranking signals from the frozen retriever provide useful supervision for query rewriting.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
naively finetuning LLM with similarity scores can lead to score inflation... we propose a corpus-relative ranking-based reward, which explicitly aligns optimization with ranking metrics while suppressing spurious score inflation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, and Ledell Wu. Alt- clip: Altering the language encoder in clip for extended language capabilities.arXiv preprint arXiv:2211.06679,
-
[2]
Meta clip 2: A worldwide scaling recipe
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al. Metaclip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
-
[3]
Weiquan Huang, Aoqi Wu, Yifan Yang, Xufang Luo, Yuqing Yang, Liang Hu, Qi Dai, Xiyang Dai, Dongdong Chen, Chong Luo, et al. Llm2clip: Powerful language model unlock richer visual representation.arXiv preprint arXiv:2411.04997,
-
[4]
Leveraging audio and visual recurrence for unsu- pervised video highlight detection
Zahidul Islam, Sujoy Paul, and Mrigank Rochan. Leveraging audio and visual recurrence for unsu- pervised video highlight detection. InNeurIPS 2024 Workshop: Self-Supervised Learning-Theory and Practice. Kenan Jiang, Xuehai He, Ruize Xu, and Xin Eric Wang. Comclip: Training-free compositional image and text matching.arXiv preprint arXiv:2211.13854,
-
[5]
Saehyung Lee, Sangwon Yu, Junsung Park, Jihun Yi, and Sungroh Yoon. Interactive text- to-image retrieval with large language models: A plug-and-play approach.arXiv preprint arXiv:2406.03411,
-
[6]
Zero-shot clustering of embeddings with self-supervised learnt encoders
Scott C Lowe, Joakim Bruslund Haurum, Sageev Oore, Thomas B Moeslund, and Graham W Taylor. Zero-shot clustering of embeddings with self-supervised learnt encoders. In4th Workshop on Self-Supervised Learning: Theory and Practice (NeurIPS 2023),
work page 2023
-
[7]
Hongyu Qu, Jianan Wei, Xiangbo Shu, and Wenguan Wang. Learning clustering-based prototypes for compositional zero-shot learning.arXiv preprint arXiv:2502.06501, 2025a. Xiangyan Qu, Gaopeng Gou, Jiamin Zhuang, Jing Yu, Kun Song, Qihao Wang, Yili Li, and Gang Xiong. Proapo: Progressively automatic prompt optimization for visual classification. InPro- ceedin...
-
[8]
Finetuning clip to reason about pairwise differences.arXiv preprint arXiv:2409.09721,
Dylan Sam, Devin Willmott, Joao D Semedo, and J Zico Kolter. Finetuning clip to reason about pairwise differences.arXiv preprint arXiv:2409.09721,
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ashish V Thapliyal, Jordi Pont-Tuset, Xi Chen, and Radu Soricut. Crossmodal-3600: A massively multilingual multimodal evaluation dataset.arXiv preprint arXiv:2205.12522,
-
[11]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Xiao Wang, Ibrahim Alabdulmohsin, Daniel Salz, Zhe Li, Keran Rong, and Xiaohua Zhai. Scaling pre-training to one hundred billion data for vision language models.arXiv preprint arXiv:2502.07617, 2025a. Yuxuan Wang, Yijun Liu, Fei Yu, Chen Huang, Kexin Li, Zhiguo Wan, Wanxiang Che, and Hongyang Chen. Cvlue: A new benchmark dataset for chinese vision-languag...
-
[13]
Wei Wu, Kecheng Zheng, Shuailei Ma, Fan Lu, Yuxin Guo, Yifei Zhang, Wei Chen, Qingpei Guo, Yujun Shen, and Zheng-Jun Zha. Lotlip: Improving language-image pre-training for long text understanding.arXiv preprint arXiv:2410.05249,
-
[14]
An Yang, Baosong Yang, Beichen Zhang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
International Conference on Learning Representations (ICLR) , year =
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it?arXiv preprint arXiv:2210.01936,
-
[16]
Hao Zheng, Shunzhi Yang, Zhuoxin He, Jinfeng Yang, and Zhenhua Huang. Hierarchical cross- modal prompt learning for vision-language models.arXiv preprint arXiv:2507.14976,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.