On-the-Fly Adaptation to Quantization: Configuration-Aware LoRA for Efficient Fine-Tuning of Quantized LLMs
Pith reviewed 2026-05-18 13:49 UTC · model grok-4.3
The pith
A single configuration-aware model generates effective LoRA adjustments for any quantization setting of an LLM without retraining per configuration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
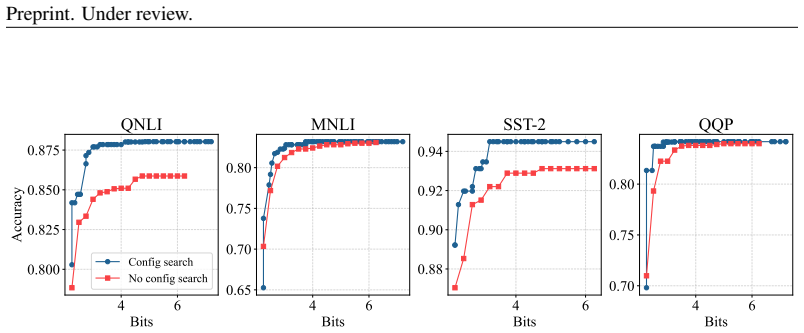
CoA-LoRA trains a configuration-aware model on a Pareto-selected subset of quantization configurations to predict the low-rank adjustments required by any new configuration. This single model then supplies the correct LoRA parameters on demand, removing the need to run separate fine-tuning for each quantization choice.
What carries the argument
Configuration-aware model that maps a quantization configuration (per-layer bit-width vector) to low-rank LoRA adjustments, trained via iterative Pareto-based search over total bit-width budgets.
If this is right
- A single training run suffices for an entire family of quantization settings instead of one run per setting.
- Edge devices with different hardware constraints can receive appropriate adapters at inference time without extra compute.
- Total fine-tuning cost scales with the size of the Pareto set rather than the number of possible configurations.
- The method preserves or improves final task performance relative to per-configuration baselines.
Where Pith is reading between the lines
- The same auxiliary-model idea could be applied to other parameter-efficient adaptation techniques beyond LoRA.
- The Pareto search step might be reused to select training data for adaptation under other compression methods such as pruning or knowledge distillation.
- Deploying the configuration-aware model itself on-device could enable fully local, zero-shot adaptation to changing power or memory budgets.
Load-bearing premise
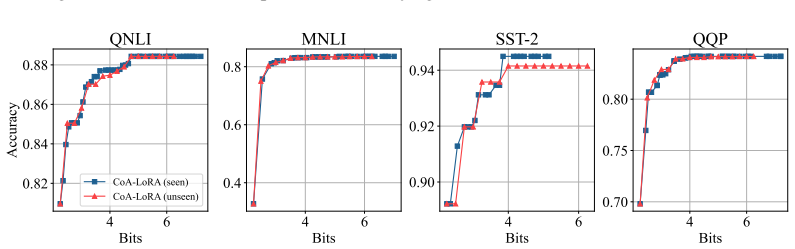
The configuration-aware model can accurately predict low-rank adjustments for unseen quantization configurations when trained only on a Pareto-selected subset of configurations that cover different total bit-width budgets.
What would settle it
Measure accuracy of CoA-LoRA on a quantization configuration never seen during training and compare it directly to the accuracy obtained by training a fresh LoRA adapter on that exact configuration; a consistent and large gap would falsify the claim.
Figures





read the original abstract
As increasingly large pre-trained models are released, deploying them on edge devices for privacy-preserving applications requires effective compression. Recent works combine quantization with the fine-tuning of high-precision LoRA adapters, which can substantially reduce model size while mitigating the accuracy loss from quantization. However, edge devices have inherently heterogeneous capabilities, while performing configuration-wise fine-tuning for every quantization setting is computationally prohibitive. In this paper, we propose CoA-LoRA, a method that dynamically adjusts the LoRA adapter to arbitrary quantization configurations (i.e., the per-layer bit-width choices of a pre-trained model) without requiring repeated fine-tuning. This is accomplished via a configuration-aware model that maps each configuration to its low-rank adjustments. The effectiveness of this model critically depends on the training configuration set, a collection of configurations chosen to cover different total bit-width budgets. However, constructing a high-quality configuration set is non-trivial. We therefore design a Pareto-based configuration search that iteratively optimizes the training configuration set, yielding more precise low-rank adjustments. Our experiments demonstrate that, unlike the state-of-the-art methods that require fine-tuning a separate LoRA adapter for each configuration, CoA-LoRA incurs no additional time cost while achieving comparable or even superior performance to those methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoA-LoRA, a configuration-aware model that maps arbitrary per-layer quantization bit-width assignments to low-rank LoRA adjustments. A Pareto-based iterative search selects a training subset of configurations spanning different total bit-width budgets; once trained, the model enables on-the-fly adaptation to unseen configurations without per-configuration fine-tuning. Experiments are reported to show performance comparable or superior to baselines that train a separate LoRA adapter for each quantization setting.
Significance. If the generalization claims are substantiated, the work addresses a practical deployment bottleneck for quantized LLMs on heterogeneous edge hardware by removing the repeated fine-tuning cost. The Pareto configuration search is a reasonable heuristic for navigating the combinatorial space, and explicit credit is due for the reproducible experimental protocol if code and exact configuration lists are released.
major comments (2)
- [§3.2] §3.2 (Pareto-based configuration search): The claim that the selected subset provides sufficient coverage for arbitrary unseen per-layer assignments is load-bearing for the central 'on-the-fly' and 'no repeated fine-tuning' assertions, yet no coverage metric, diversity statistic, or extrapolation test on randomly sampled out-of-distribution bit-width vectors is reported.
- [Experimental section] Experimental section (results tables): The performance comparisons do not break down accuracy by whether the evaluated configuration was inside or outside the Pareto training set; without this split, it is impossible to verify that the configuration-aware model actually generalizes rather than interpolating within the training distribution.
minor comments (2)
- [§2] Notation for the configuration vector (per-layer bit-width tuple) is introduced without an explicit mathematical definition or dimensionality statement in §2.
- [Figures] Figure captions for the Pareto front plots should state the exact number of configurations evaluated at each iteration and the stopping criterion used.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the evidence for generalization in CoA-LoRA.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Pareto-based configuration search): The claim that the selected subset provides sufficient coverage for arbitrary unseen per-layer assignments is load-bearing for the central 'on-the-fly' and 'no repeated fine-tuning' assertions, yet no coverage metric, diversity statistic, or extrapolation test on randomly sampled out-of-distribution bit-width vectors is reported.
Authors: We agree that explicit validation of coverage is important to support the on-the-fly adaptation claims. The Pareto search was designed to span diverse bit-width budgets, and experiments already include held-out configurations. In the revision we will add: diversity statistics (e.g., per-layer bit-width variance and coverage of the total budget range), a quantitative coverage metric approximating the fraction of the configuration space represented by the selected set, and results from an extrapolation test on randomly sampled out-of-distribution bit-width vectors. These additions will provide direct evidence beyond the current empirical results. revision: yes
-
Referee: [Experimental section] Experimental section (results tables): The performance comparisons do not break down accuracy by whether the evaluated configuration was inside or outside the Pareto training set; without this split, it is impossible to verify that the configuration-aware model actually generalizes rather than interpolating within the training distribution.
Authors: This observation is correct and highlights a useful way to isolate generalization. The current tables report aggregate performance without the requested split. We will revise the experimental section to include a clear breakdown: separate accuracy metrics for configurations inside the Pareto training set versus those outside it. This will allow readers to assess whether CoA-LoRA maintains performance on truly unseen assignments, directly addressing the interpolation concern. revision: yes
Circularity Check
No circularity: standard supervised mapping from configurations to adjustments via external training data
full rationale
The paper presents CoA-LoRA as a configuration-aware model trained on a Pareto-optimized subset of quantization configurations to learn a mapping to low-rank LoRA adjustments, then evaluated empirically on held-out configurations and compared against per-configuration fine-tuned baselines. This is a conventional ML training-and-generalization pipeline whose performance claims rest on experimental results rather than any equation or definition that reduces the output to the input by construction. No self-citations, ansatzes, or fitted quantities are shown to be load-bearing in a way that makes the central claim tautological. The derivation chain is therefore self-contained against external benchmarks and data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
configuration-aware model θ that maps each configuration to its low-rank adjustments... Pareto-based Gaussian process... Expected Hypervolume Improvement (EHVI)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
layer-level quantization configuration ci = [b0,i, b1,i, b2,i, B0,i, B1,i]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), ...
work page 2019
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus
Jesse Dodge, Maarten Sap, Ana Marasovi ´c, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 1286–1305,
work page 2021
-
[4]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024a. 11 Preprint. Under review. Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang- Ting Cheng, and Min-Hung Chen. Dora: Weig...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[5]
URLhttps://arxiv.org/abs/2412.15115. Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adver- sarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko- lay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open founda- tion and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili ´c, Daniel Hesslow, Roman Castagn ´e, Alexandra Sasha Luccioni, Franc ¸ois Yvon, et al. Bloom: A 176b-parameter open-access multilingual language model.arXiv preprint arXiv:2211.05100,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Towards building the federatedgpt: Federated instruction tuning
Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. Towards building the federatedgpt: Federated instruction tuning. InICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6915–6919. IEEE,
work page 2024
-
[9]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christo- pher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
13 Preprint. Under review. THEUSE OFLARGELANGUAGEMODELS We used large language models (LLMs) solely as a general-purpose assistant for language editing, including grammar correction and sentence polishing. LLMs did not contribute to research ideation, experimental design, analysis, or writing of original technical content. All scientific claims, experi- m...
work page 2024
-
[11]
32 Gaussian process is then fitted based on these evaluations. During each training epoch, we jointly optimize the configuration-aware model and update the training quantization configuration set. B EXPERIMENTALDETAILS For the computation of Hypervolume (HV) (Zitzler & Thiele, 1999), we first collect the performance metrics for each algorithm. The second ...
work page 1999
-
[12]
This observation motivates the de- sign of the configuration-aware modelθ, where the model outputs anr×rmatrixU θ to directly transformL 2 intoU θL2. 16 Preprint. Under review. Table C.2: Comparison of hypervolume (HV) and average decrease in perplexity (lower is better) relative to Q-LoRA across three LLMs. Method Qwen2.5-1.5B Qwen2.5-3B Llama-2-7B HV Ga...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.