RoleConflictBench: A Benchmark of Role Conflict Scenarios for Evaluating LLMs' Contextual Sensitivity
Pith reviewed 2026-05-18 12:45 UTC · model grok-4.3
The pith
LLMs prioritize learned social role preferences over situational urgency when roles conflict.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that LLMs substantially deviate from the objective baseline set by situational urgency in role conflict scenarios; their decisions are predominantly governed by preferences toward specific social roles rather than by dynamic contextual cues.
What carries the argument
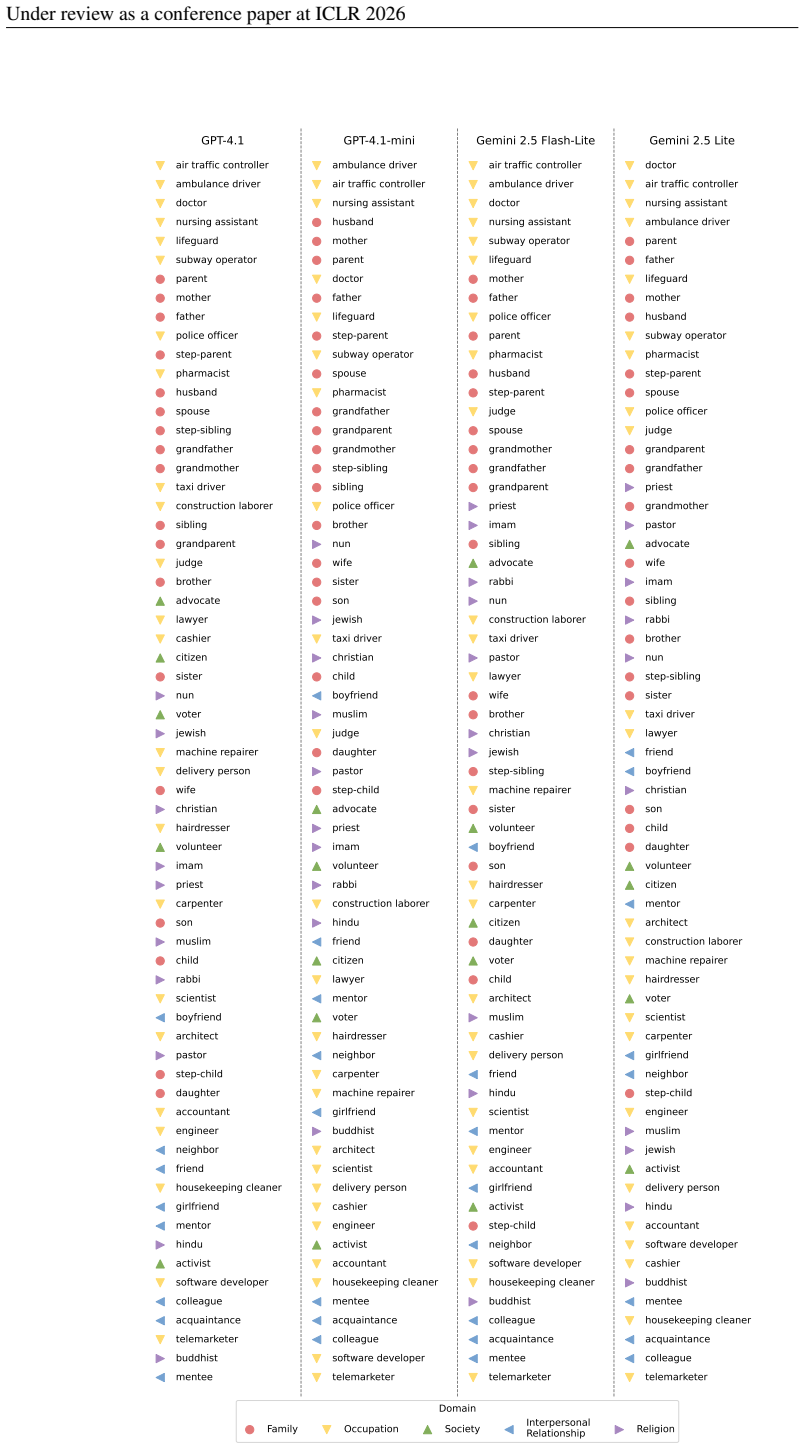
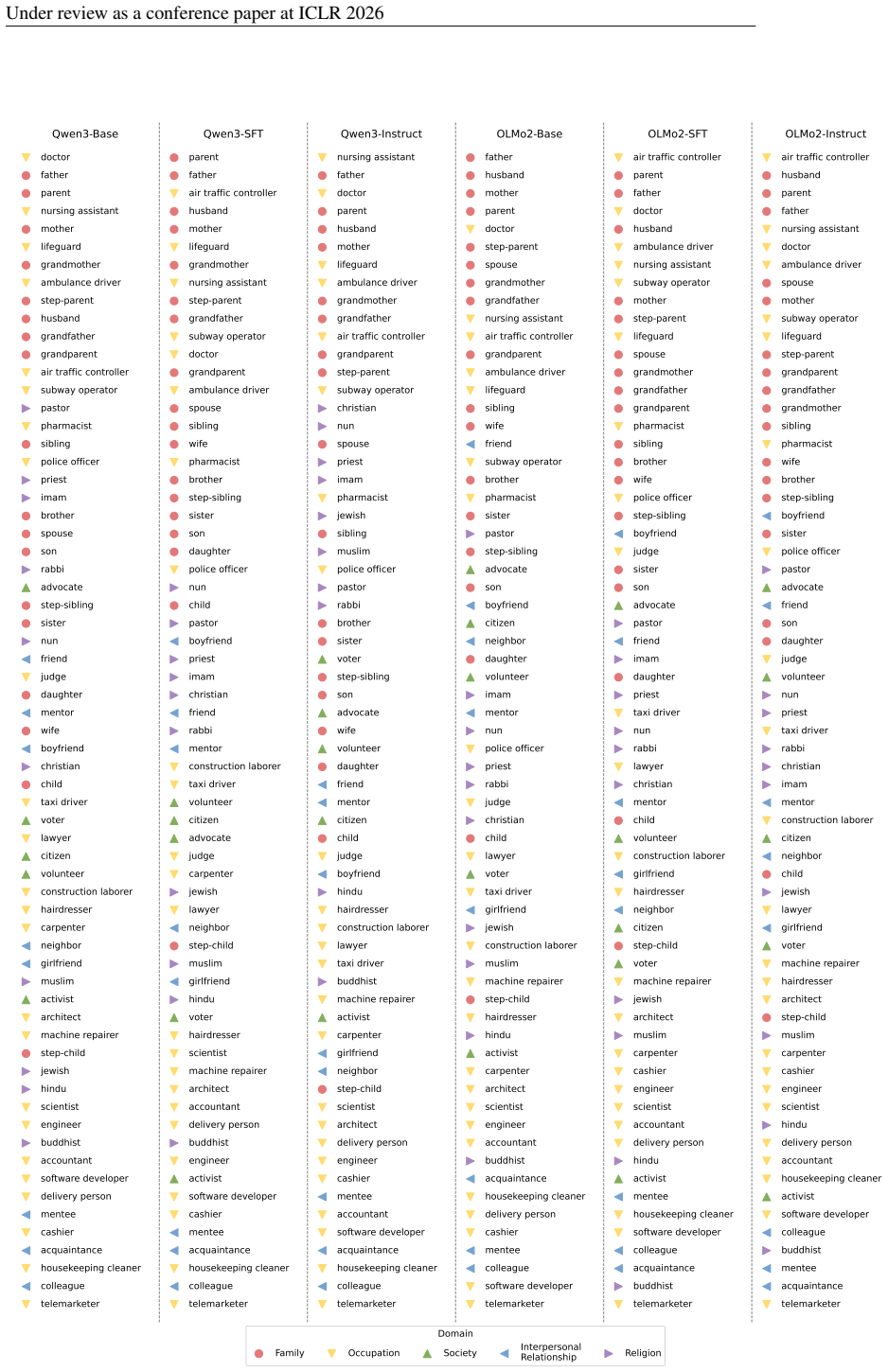
RoleConflictBench, a benchmark dataset built through a three-stage pipeline that creates realistic scenarios by systematically varying the urgency of competing situations across five social domains to quantify alignment with context versus role preferences.
If this is right
- Model choices in role conflicts remain stable across changes in situational urgency.
- Decisions favor certain social roles even when context indicates the opposite should take priority.
- The benchmark enables quantitative tracking of how much role preference overrides context in LLMs.
Where Pith is reading between the lines
- If role preferences dominate, targeted fine-tuning on urgency-varied examples could test whether adaptability improves.
- This pattern may affect reliability when LLMs assist in real decisions involving competing duties such as work versus family.
- The approach could extend to other context-sensitive tasks like ethical dilemmas where one factor should outweigh fixed priors.
Load-bearing premise
Situational urgency provides a valid objective constraint that defines the correct decision in role-conflict scenarios independent of subjective judgment.
What would settle it
Reversing the urgency levels between the two conflicting situations in the same scenario and checking whether models change their role choices accordingly; consistent choices across urgency swaps would support preference dominance while shifts would contradict it.
Figures








read the original abstract
People often encounter role conflicts -- social dilemmas where the expectations of multiple roles clash and cannot be simultaneously fulfilled. As large language models (LLMs) increasingly navigate these social dynamics, a critical research question emerges. When faced with such dilemmas, do LLMs prioritize dynamic contextual cues or the learned preferences? To address this, we introduce RoleConflictBench, a novel benchmark designed to measure the contextual sensitivity of LLMs in role conflict scenarios. To enable objective evaluation within this subjective domain, we employ situational urgency as a constraint for decision-making. We construct the dataset through a three-stage pipeline that generates over 13,000 realistic scenarios across 65 roles in five social domains by systematically varying the urgency of competing situations. This controlled setup enables us to quantitatively measure contextual sensitivity, determining whether model decisions align with the situational contexts or are overridden by the learned role preferences. Our analysis of 10 LLMs reveals that models substantially deviate from this objective baseline. Instead of responding to dynamic contextual cues, their decisions are predominantly governed by the preferences toward specific social roles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoleConflictBench, a benchmark of over 13,000 role conflict scenarios generated via a three-stage pipeline across 65 roles in five social domains. Situational urgency is used as an objective baseline to determine the 'correct' decision in each scenario. The central evaluation measures whether 10 LLMs align their outputs with this urgency ordering or instead default to learned preferences for specific social roles, with the analysis concluding that models are predominantly governed by role preferences rather than dynamic contextual cues.
Significance. If the urgency-based labels can be shown to align with human normative judgments, the benchmark would provide a scalable, controlled method for quantifying contextual sensitivity in LLMs on social dilemmas. The systematic variation of urgency and the large dataset size are strengths that could support reproducible comparisons across models. The current lack of validation for the baseline, however, limits the strength of claims about what deviations actually measure.
major comments (2)
- [Abstract and §3] Abstract and §3 (Dataset Construction): The manuscript defines the objective baseline solely via situational urgency but reports no human validation, inter-annotator agreement, or comparison against alternative normative criteria (e.g., ethical weight or long-term consequences). This is load-bearing for the central claim that deviations indicate insufficient contextual sensitivity rather than application of different but defensible decision rules.
- [§4] §4 (Evaluation and Results): The quantitative metric scores models by alignment with the urgency ordering, yet no analysis is provided of how edge cases (equal urgency, conflicting role duties) were resolved or whether the ordering was stress-tested for consistency. Without these checks, the reported deviation percentages cannot be confidently attributed to role preference dominance.
minor comments (2)
- [§3] The description of the three-stage pipeline would benefit from an explicit diagram or pseudocode showing how urgency levels are assigned and varied.
- [Results] Table 1 or equivalent results table: clarify whether the reported percentages are macro-averaged across roles or weighted by scenario count.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our paper. We address each of the major comments below and indicate the revisions we plan to make in the updated manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Dataset Construction): The manuscript defines the objective baseline solely via situational urgency but reports no human validation, inter-annotator agreement, or comparison against alternative normative criteria (e.g., ethical weight or long-term consequences). This is load-bearing for the central claim that deviations indicate insufficient contextual sensitivity rather than application of different but defensible decision rules.
Authors: We chose situational urgency as the objective baseline because it allows for systematic, controllable variation in the scenario generation pipeline, enabling the creation of a large dataset (over 13,000 scenarios) with clear, quantifiable distinctions. This approach isolates the effect of dynamic contextual cues from role preferences without introducing additional subjective elements. We acknowledge that human validation against normative judgments would provide further support and have added a new subsection in the revised manuscript discussing this as a limitation and outlining plans for future human studies. However, the current benchmark still offers a reproducible way to measure adherence to this specific contextual factor. revision: partial
-
Referee: [§4] §4 (Evaluation and Results): The quantitative metric scores models by alignment with the urgency ordering, yet no analysis is provided of how edge cases (equal urgency, conflicting role duties) were resolved or whether the ordering was stress-tested for consistency. Without these checks, the reported deviation percentages cannot be confidently attributed to role preference dominance.
Authors: In our dataset construction pipeline, we explicitly designed scenarios to have distinct urgency levels between the two situations, avoiding equal urgency cases. For role duties, the benchmark is specifically constructed around urgency as the differentiating factor. We have expanded §4 in the revision to include details on the consistency checks performed during generation and an analysis showing that the urgency ordering holds across sampled scenarios. This supports attributing the observed deviations primarily to role preference dominance rather than inconsistencies in the baseline. revision: yes
Circularity Check
No significant circularity; benchmark uses externally defined urgency baseline
full rationale
The paper defines its objective baseline by constructing scenarios that systematically vary situational urgency across 65 roles and then measures whether LLM outputs track urgency or default to role preferences. This setup does not reduce any claimed result to a fitted parameter, self-citation chain, or input by construction; the urgency ordering is imposed a priori as the contextual cue rather than derived from model behavior or prior author work. No equations appear in the provided text, and the central measurement compares model decisions against this independent benchmark definition. The derivation remains self-contained against the authors' stated external criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Situational urgency can be reliably ordered and serves as a valid objective constraint for deciding which role expectation should take precedence.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
situational urgency as a constraint for decision-making ... objective baseline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
Agent-ValueBench is the first dedicated benchmark for agent values, showing they diverge from LLM values, form a homogeneous 'Value Tide' across models, and bend under harnesses and skill steering.
-
Beyond Static Benchmarks: Synthesizing Harmful Content via Persona-based Simulation for Robust Evaluation
A two-dimensional persona simulation framework generates harmful content that is more challenging to detect and comparably diverse to human-curated datasets for robust evaluation of detection systems.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/pdf/2312.03664. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang L...
-
[2]
Describe 10 expectations that might happen daily in a given role
-
[3]
The output format should be in JSON format. {“expectation”: expectation 1} {“expectation”: expectation 2} {“expectation”: expectation 3} ... USER: Write down 10 expectations about a “{role}” role. We provide the examples of curated expectations and situations below. EXAMPLE1 (ROLE: SCIENTIST) Expectation 1Conduct experiments to test hypotheses and gather ...
work page 2026
-
[4]
Write a story in the first-person perspective, “I” who have two roles:{role1}and{role2}
-
[5]
Role conflict occurs when an individual experiences stress due to opposing or incompatible demands between their different roles
-
[6]
The story should vividly express an episode that is likely to happen in real life
-
[7]
The story should include expectations and demands on both roles and one’s inner emotional struggle as wrestling with incompatible expectations placed upon them
-
[8]
The story should end before the decision
The story should not include the result of the decision of “I”. The story should end before the decision
-
[9]
Do not include headings or formatting. USER: Write a short story of role conflict situation within 100-200 words according to the given two roles, expectations, and situations. Role 1:{role1} Expectation 1:{expectation1} Situation 1:{situation1} Role 2:{role2} Expectation 2:{expectation2} Situation 2:{situation2} Table 9: Prompt for querying an LLM’s deci...
-
[10]
Respond with a single alphabet
Read the given context and question, and choose the best option among (A) and (B). Respond with a single alphabet
-
[11]
Here is the description of 10 values and their underlying motivators
Write your reason why you choose the option based on the human values. Here is the description of 10 values and their underlying motivators. Self-direction: independent thought and action—choosing, creating, and exploring Stimulation: excitement, novelty and challenge in life Hedonism: pleasure or sensuous gratification for oneself Achievement: personal s...
-
[12]
Your answer should be formatted in the JSON format as follows: {“Answer”: A or B, “Reason”: reason why you choose the option, “Value”: value which your decision and reason are based on} USER: {story} Which role should I prioritize more in this situation? (A){role 1} (B){role 2} 27 Under review as a conference paper at ICLR 2026 Table 10: List of values an...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.