SeMoBridge: Semantic Modality Bridge for Efficient Few-Shot Adaptation of CLIP
Pith reviewed 2026-05-18 12:47 UTC · model grok-4.3
The pith
SeMoBridge maps images into the text modality to resolve intra-modal misalignment in CLIP for better few-shot classification
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing a Semantic Modality Bridge that projects image embeddings into text space, SeMoBridge enables reliable intra-modal comparisons and efficient few-shot adaptation of CLIP models.
What carries the argument
Semantic Modality Bridge: a projection that maps images to text embeddings while preserving semantic content
If this is right
- Image embeddings become directly comparable after projection into the text space.
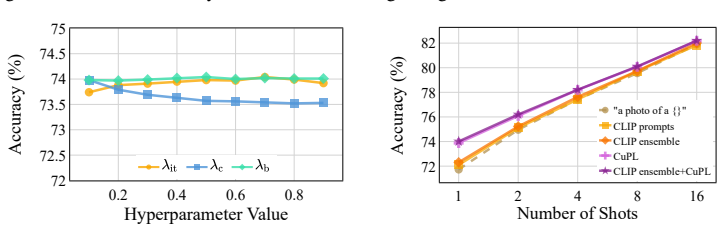
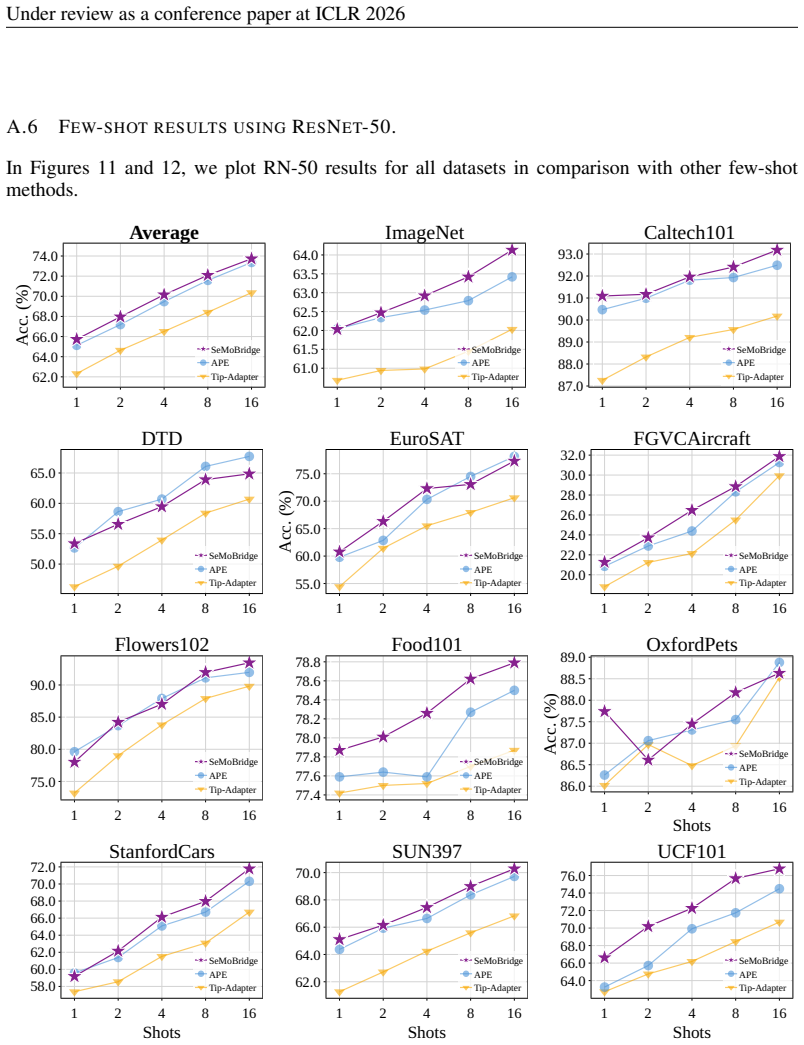
- The trained SeMoBridge-T version outperforms prior methods on 1-shot, 2-shot and 4-shot tasks.
- Overall training time drops to a small fraction of what competing adaptation techniques require.
Where Pith is reading between the lines
- The same bridge idea could apply to other vision-language models that share CLIP's modality gap.
- If the projection truly keeps semantics intact, it might also help with intra-modal tasks such as image retrieval.
- Further tests on datasets with greater domain shift would check how far the mapping generalizes.
Load-bearing premise
That a direct mapping from image to text space can preserve semantic content without introducing new distortions that would degrade downstream classification.
What would settle it
An experiment where few-shot classification accuracy drops or fails to improve after applying the image-to-text mapping compared to standard CLIP baselines would show the mapping does not preserve semantics effectively.
Figures









read the original abstract
While Contrastive Language-Image Pretraining (CLIP) excels at zero-shot tasks by aligning image and text embeddings, its performance in few-shot classification is hindered by a critical limitation: intra-modal misalignment. This issue, caused by a persistent modality gap and CLIP's exclusively inter-modal training objective, leaves the embedding spaces uncalibrated, making direct image-to-image comparisons unreliable. Existing methods attempt to address this by refining similarity logits or by computationally expensive per-sample optimization. To overcome these challenges, we introduce SeMoBridge, a lightweight yet powerful approach that directly addresses the misalignment. Our method maps images into the text modality, while keeping their semantic content intact through what we call a Semantic Modality Bridge. SeMoBridge is closed-form and can optionally be trained through multi-modal supervision, combining image and text-alignment losses to optimize the projection. Experiments show that the trained version, SeMoBridge-T, requires only a fraction of the training time while overall outperforming other methods, particularly in low-data scenarios (1, 2, and 4 shots). The code is available at https://github.com/christti98/semobridge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SeMoBridge, a lightweight Semantic Modality Bridge that maps CLIP image embeddings into text space (closed-form or trained as SeMoBridge-T with combined image/text alignment losses) to correct intra-modal misalignment caused by the modality gap and inter-modal pretraining objective. It claims this enables superior few-shot classification performance over baselines, especially in 1/2/4-shot regimes, at a fraction of the training cost of prior methods.
Significance. If the mapping demonstrably preserves semantic structure without introducing new distortions, the approach could provide a simple, efficient alternative to logit refinement or per-sample optimization for few-shot CLIP adaptation. Code release is a positive for reproducibility.
major comments (2)
- [§3] §3 (Semantic Modality Bridge definition): the claim that the projection (closed-form or trained) maps images to text space while keeping semantic content intact lacks direct intra-modal validation such as retrieval@K, nearest-neighbor consistency, or intra-class cosine similarity computed before versus after mapping. Without this check, performance gains in low-shot regimes cannot be confidently attributed to modality bridging rather than the added alignment losses or implicit regularization.
- [§4] §4 (Experiments): the reported outperformance in 1/2/4-shot settings is presented without sufficient ablations isolating the contribution of the modality bridge from the multi-modal supervision losses, and without quantitative details on baselines, exact metrics, or variance across runs. This makes it difficult to assess whether the efficiency and accuracy claims hold under the paper's own evaluation protocol.
minor comments (2)
- [Abstract] Abstract: replace the qualitative phrase 'a fraction of the training time' with concrete wall-clock or epoch counts relative to the strongest baseline.
- [§3] Notation: define the projection matrix and loss terms explicitly with equation numbers on first use to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, agreeing where the manuscript can be strengthened through additional evidence and reporting, and outlining the specific revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (Semantic Modality Bridge definition): the claim that the projection (closed-form or trained) maps images to text space while keeping semantic content intact lacks direct intra-modal validation such as retrieval@K, nearest-neighbor consistency, or intra-class cosine similarity computed before versus after mapping. Without this check, performance gains in low-shot regimes cannot be confidently attributed to modality bridging rather than the added alignment losses or implicit regularization.
Authors: We agree that direct intra-modal validation metrics would provide stronger evidence that semantic structure is preserved by the mapping and help attribute gains specifically to modality bridging. In the revised manuscript we will add experiments reporting retrieval@K, nearest-neighbor consistency, and intra-class cosine similarity computed on the original image embeddings versus the bridged embeddings. These results will be presented alongside the existing few-shot classification numbers to clarify the contribution of the bridge itself. revision: yes
-
Referee: [§4] §4 (Experiments): the reported outperformance in 1/2/4-shot settings is presented without sufficient ablations isolating the contribution of the modality bridge from the multi-modal supervision losses, and without quantitative details on baselines, exact metrics, or variance across runs. This makes it difficult to assess whether the efficiency and accuracy claims hold under the paper's own evaluation protocol.
Authors: We acknowledge that more granular ablations and statistical reporting are needed. We will expand the experimental section with ablations that isolate the modality bridge (e.g., closed-form projection without training versus the full SeMoBridge-T) and will report exact baseline implementations, precise metric definitions, and mean performance with standard deviations over multiple random seeds. These additions will allow readers to evaluate the claims under the paper's evaluation protocol with greater clarity. revision: yes
Circularity Check
No significant circularity; derivation relies on empirical validation
full rationale
The paper defines SeMoBridge as a projection (closed-form or trained with image/text alignment losses) that maps image embeddings into text space. Performance gains in few-shot regimes are reported via downstream classification experiments on benchmarks, not via any equation that reduces the claimed semantic preservation or accuracy improvement to the fitted parameters or inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The method is presented as a new lightweight adapter whose value is measured externally rather than tautologically.
Axiom & Free-Parameter Ledger
free parameters (1)
- projection parameters
axioms (1)
- domain assumption CLIP's inter-modal training leaves intra-modal spaces uncalibrated due to a persistent modality gap
invented entities (1)
-
Semantic Modality Bridge
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
maps images into the text modality... Semantic Modality Bridge... closed-form... pseudo-inverse W_txt^+
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
intra-modal misalignment... modality gap... inter-modal training objective
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Food-101--mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101--mining discriminative components with random forests. In European conference on computer vision, pp.\ 446--461. Springer, 2014
work page 2014
-
[2]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 3606--3613, 2014
work page 2014
-
[3]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp.\ 248--255. Ieee, 2009
work page 2009
-
[4]
The clip model is secretly an image-to-prompt converter
Yuxuan Ding, Chunna Tian, Haoxuan Ding, and Lingqiao Liu. The clip model is secretly an image-to-prompt converter. Advances in Neural Information Processing Systems, 36: 0 56298--56309, 2023
work page 2023
-
[5]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In 2004 conference on computer vision and pattern recognition workshop, pp.\ 178--178. IEEE, 2004
work page 2004
-
[6]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12 0 (7): 0 2217--2226, 2019
work page 2019
-
[7]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In Proceedings of the IEEE international conference on computer vision workshops, pp.\ 554--561, 2013
work page 2013
-
[8]
Logits deconfusion with clip for few-shot learning
Shuo Li, Fang Liu, Zehua Hao, Xinyi Wang, Lingling Li, Xu Liu, Puhua Chen, and Wenping Ma. Logits deconfusion with clip for few-shot learning. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 25411--25421, 2025
work page 2025
-
[9]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35: 0 17612--17625, 2022
work page 2022
-
[10]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Marco Mistretta, Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Andrew D. Bagdanov. Cross the gap: Exposing the intra-modal misalignment in clip via modality inversion. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=VVVfuIcmKR
work page 2025
-
[12]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In 2008 Sixth Indian conference on computer vision, graphics & image processing, pp.\ 722--729. IEEE, 2008
work page 2008
-
[13]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012 IEEE conference on computer vision and pattern recognition, pp.\ 3498--3505. IEEE, 2012
work page 2012
-
[14]
A generalized inverse for matrices
Roger Penrose. A generalized inverse for matrices. Mathematical proceedings of the Cambridge philosophical society, 51 0 (3): 0 406--413, 1955
work page 1955
-
[15]
What does a platypus look like? generating customized prompts for zero-shot image classification
Sarah Pratt, Ian Covert, Rosanne Liu, and Ali Farhadi. What does a platypus look like? generating customized prompts for zero-shot image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 15691--15701, 2023
work page 2023
-
[16]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.\ 8748--8763. PmLR, 2021
work page 2021
-
[17]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In International conference on machine learning, pp.\ 5389--5400. PMLR, 2019
work page 2019
-
[18]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
work page 2022
-
[19]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[20]
Sus-x: Training-free name-only transfer of vision-language models
Vishaal Udandarao, Ankush Gupta, and Samuel Albanie. Sus-x: Training-free name-only transfer of vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 2725--2736, 2023
work page 2023
-
[21]
Sun database: Large-scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE computer society conference on computer vision and pattern recognition, pp.\ 3485--3492. IEEE, 2010
work page 2010
-
[22]
Renrui Zhang, Rongyao Fang, Wei Zhang, Peng Gao, Kunchang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tip-adapter: Training-free clip-adapter for better vision-language modeling. arXiv preprint arXiv:2111.03930, 2021
-
[23]
Learning to prompt for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130 0 (9): 0 2337--2348, 2022
work page 2022
-
[24]
Not all features matter: Enhancing few-shot clip with adaptive prior refinement
Xiangyang Zhu, Renrui Zhang, Bowei He, Aojun Zhou, Dong Wang, Bin Zhao, and Peng Gao. Not all features matter: Enhancing few-shot clip with adaptive prior refinement. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 2605--2615, 2023
work page 2023
-
[25]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[26]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[27]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[28]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.