Beyond Linear Probes: Dynamic Safety Monitoring for Language Models
Pith reviewed 2026-05-18 12:35 UTC · model grok-4.3
The pith
Truncated polynomial classifiers let safety monitors for language models adjust compute based on input difficulty while matching MLP probe accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Truncated Polynomial Classifiers extend linear probes by fitting polynomial terms on LLM activations that can be learned and evaluated sequentially. At inference, low-order terms handle straightforward cases with early exit, while additional terms supply stronger guardrails only when inputs remain ambiguous. On WildGuardMix, across four models, the classifiers compete with or outperform MLP baselines of equivalent size for harmful-prompt classification and supply per-term interpretability that black-box probes lack.
What carries the argument
Truncated Polynomial Classifiers (TPCs), which add successive polynomial terms to linear probes on activations so that monitoring depth can increase term by term without retraining.
If this is right
- The same trained classifier supports both low-cost monitoring and higher-accuracy modes by simply evaluating more terms.
- Clear inputs exit after cheap low-order checks, lowering average compute for safety monitoring.
- Regulators or developers can raise the required protection level by mandating evaluation of additional terms.
- Each added term contributes an interpretable increment to the decision, unlike opaque MLP layers.
Where Pith is reading between the lines
- The same progressive structure could support incremental retraining when new harmful examples appear.
- TPCs might combine with layer-specific activations to create monitors that focus on particular internal representations.
- Early-exit thresholds could be tuned per domain to balance speed and coverage without changing the underlying model.
Load-bearing premise
That polynomial terms can be trained progressively while still allowing reliable early stopping that does not miss subtle harmful prompts.
What would settle it
A test set of harmful prompts where TPCs stopped after low-order terms miss a substantial fraction of cases that either full TPCs or MLP probes correctly flag.
Figures










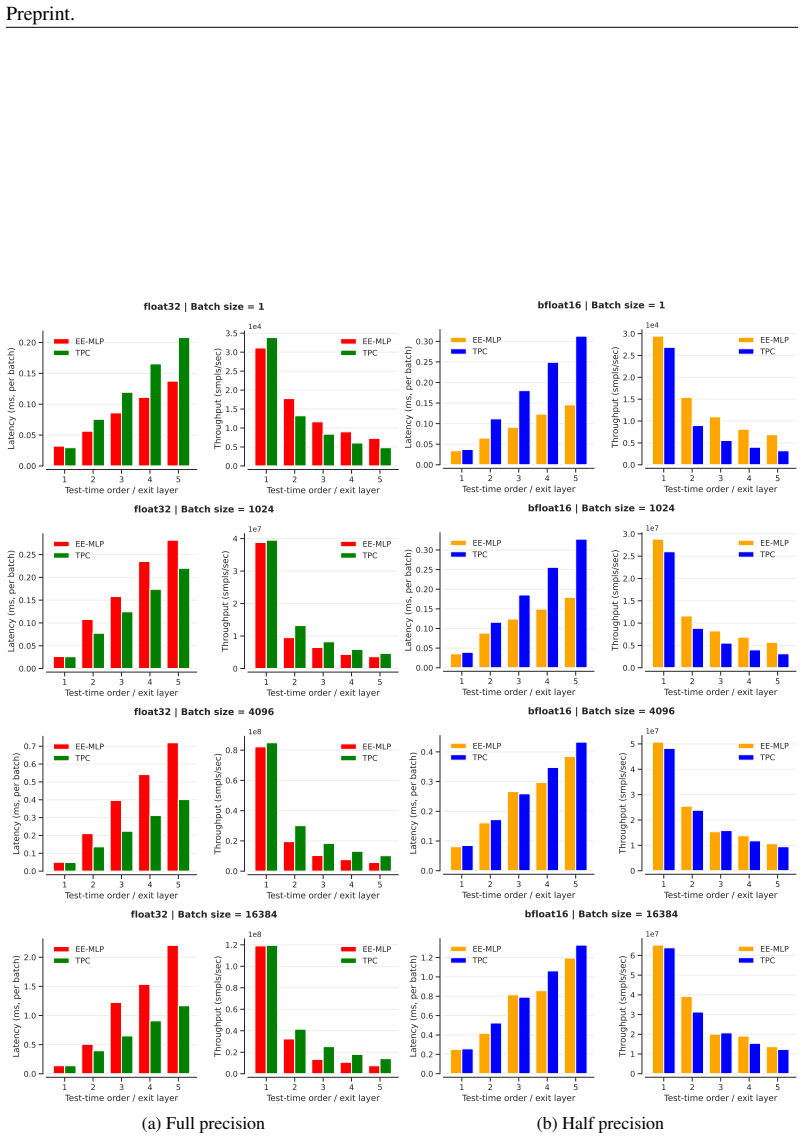

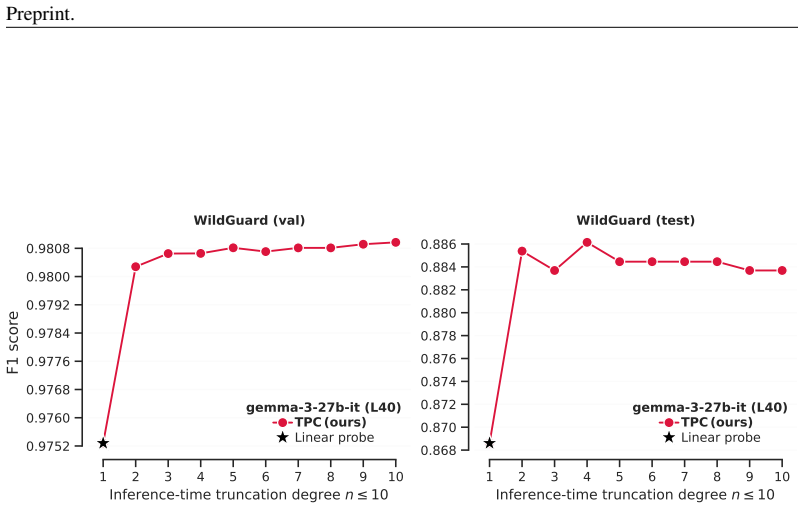





read the original abstract
Monitoring large language models' (LLMs) activations is an effective way to detect harmful requests before they lead to unsafe outputs. However, traditional safety monitors often require the same amount of compute for every query. This creates a trade-off: expensive monitors waste resources on easy inputs, while cheap ones risk missing subtle cases. We argue that safety monitors should be flexible--costs should rise only when inputs are difficult to assess, or when more compute is available. To achieve this, we introduce Truncated Polynomial Classifiers (TPCs), a natural extension of linear probes for dynamic activation monitoring. Our key insight is that polynomials can be trained and evaluated progressively, term-by-term. At test-time, one can early-stop for lightweight monitoring, or use more terms for stronger guardrails when needed. TPCs provide two modes of use. First, as a safety dial: by evaluating more terms, developers and regulators can "buy" stronger guardrails from the same model. Second, as an adaptive cascade: clear cases exit early after low-order checks, and higher-order guardrails are evaluated only for ambiguous inputs, reducing overall monitoring costs. On WildGuardMix, across 4 models with up to 30B parameters, we show that TPCs compete with or outperform MLP-based probe baselines of the same size for harmful prompt classification, all the while being more interpretable than their black-box counterparts. Our code is available at http://github.com/james-oldfield/tpc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Truncated Polynomial Classifiers (TPCs) as a dynamic extension of linear probes for LLM activation monitoring. Polynomials over activations are trained to allow term-by-term progressive evaluation at test time, enabling a safety dial (more terms for stronger detection) and an adaptive cascade (early exit on clear cases after low-order checks, deferring ambiguous inputs to higher-order terms). On WildGuardMix across four models up to 30B parameters, TPCs are reported to compete with or outperform same-size MLP probe baselines for harmful prompt classification while being more interpretable; code is released.
Significance. If the progressive training and early-stopping properties hold with reliable per-order accuracy, TPCs would offer a meaningful advance over fixed-cost probes by providing tunable compute-accuracy trade-offs and improved interpretability for safety monitoring. The open code supports reproducibility and further testing of the dynamic modes.
major comments (2)
- [§4] §4 (Experiments on WildGuardMix): overall accuracy is compared to MLP baselines, but the results do not report per-order early-exit false-negative rates, statistical significance, or exact metric definitions. This is load-bearing for the adaptive-cascade claim, as low-order truncations must reliably classify clear cases without missing subtle harmful prompts.
- [§3] §3 (Method, progressive training): it is not specified whether coefficients are fit jointly on the full polynomial or added sequentially term-by-term. Joint fitting optimizes lower-order terms in the presence of higher-order ones, so test-time truncation may degrade performance relative to a dedicated low-order model; an ablation of joint vs. sequential fitting is required to verify reliable early stopping.
minor comments (2)
- [Abstract] Clarify in the abstract and §4 what 'same size' means for the MLP baselines (parameter count, hidden dimension, or FLOPs).
- [§5] The interpretability advantage is asserted but would benefit from a concrete example (e.g., coefficient inspection on a specific harmful prompt) in §5.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our dynamic monitoring approach. We address each major point below and commit to revisions that strengthen the validation of TPCs' progressive properties.
read point-by-point responses
-
Referee: [§4] §4 (Experiments on WildGuardMix): overall accuracy is compared to MLP baselines, but the results do not report per-order early-exit false-negative rates, statistical significance, or exact metric definitions. This is load-bearing for the adaptive-cascade claim, as low-order truncations must reliably classify clear cases without missing subtle harmful prompts.
Authors: We agree that per-order early-exit false-negative rates are essential to substantiate the adaptive-cascade claim. In the revised version we will add a dedicated table and figure reporting false-negative rates at each truncation order on WildGuardMix, along with statistical significance tests (McNemar’s test for paired accuracy comparisons against MLP baselines) and explicit metric definitions, including the confidence threshold used for early-exit decisions. These additions will directly demonstrate that low-order truncations do not miss subtle harmful prompts at unacceptable rates. revision: yes
-
Referee: [§3] §3 (Method, progressive training): it is not specified whether coefficients are fit jointly on the full polynomial or added sequentially term-by-term. Joint fitting optimizes lower-order terms in the presence of higher-order ones, so test-time truncation may degrade performance relative to a dedicated low-order model; an ablation of joint vs. sequential fitting is required to verify reliable early stopping.
Authors: We appreciate the referee highlighting this underspecification. Our current implementation fits all coefficients jointly via a single regularized optimization over the full polynomial. To verify that joint fitting supports reliable early stopping, we will include a new ablation in the revised manuscript that compares joint fitting against a sequential term-by-term procedure. The ablation will report per-order accuracy and false-negative rates under both regimes on the same data splits, allowing readers to assess any degradation from joint optimization. revision: yes
Circularity Check
No significant circularity; TPC claims rest on empirical comparisons to external baselines
full rationale
The paper introduces Truncated Polynomial Classifiers (TPCs) as a method for dynamic safety monitoring via progressive term-by-term polynomial evaluation on LLM activations. Performance is demonstrated through direct empirical comparisons against MLP probe baselines of equivalent size on the WildGuardMix dataset across multiple models. No equations, derivations, or self-citations are shown that reduce the reported accuracy or dynamic-mode reliability to quantities defined tautologically by the fitting procedure itself. The progressive training and truncation are presented as methodological features whose effectiveness is tested against independent baselines rather than assumed by construction. This qualifies as a self-contained empirical contribution with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
From Mechanistic to Compositional Interpretability
Compositional interpretability defines explanations as commuting syntactic-semantic mapping pairs grounded in compositionality and minimum description length, with compressive refinement and a parsimony theorem guaran...
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
-
[5]
https://github.com/facebookresearch/fvcore
fvcore: Flop counter for pytorch models. https://github.com/facebookresearch/fvcore
-
[6]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Understanding intermediate layers using linear classifier probes, 2017
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2017. URL https://openreview.net/forum?id=ryF7rTqgl
work page 2017
-
[8]
Bowman, Ethan Perez, Roger Baker Grosse, and David Duvenaud
Cem Anil, Esin Durmus, Nina Rimsky, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Meg Tong, Jesse Mu, Daniel J Ford, Francesco Mosconi, Rajashree Agrawal, Rylan Schaeffer, Naomi Bashkansky, Samuel Svenningsen, Mike Lambert, Ansh Radhakrishnan, Carson Denison, Evan J Hubinger, Yuntao Bai, Trenton Bricken, Timothy Maxwell, Nicholas Schiefer, Ja...
work page 2024
-
[9]
Linear complexity self-attention with 3rd order polynomials
Francesca Babiloni, Ioannis Marras, Jiankang Deng, Filippos Kokkinos, Matteo Maggioni, Grigorios Chrysos, Philip Torr, and Stefanos Zafeiriou. Linear complexity self-attention with 3rd order polynomials. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 45 0 (11): 0 12726--12737, 2023
work page 2023
-
[10]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI : Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Greedy layerwise learning can scale to ImageNET
Eugene Belilovsky, Michael Eickenberg, and Edouard Oyallon. Greedy layerwise learning can scale to ImageNET . In Int. Conf. Mach. Learn. (ICML), pp.\ 583--593. PMLR, 2019
work page 2019
-
[12]
Using dictionary learning features as classifiers
Trenton Bricken, Jonathan Marcus, Siddharth Mishra-Sharma, Meg Tong, Ethan Perez, Mrinank Sharma, Kelley Rivoire, and Thomas Henighan. Using dictionary learning features as classifiers. Transformer‑Circuits.pub, oct 2024. URL https://transformer-circuits.pub/2024/features-as-classifiers/index.html. Edited by Adam Jermyn
work page 2024
-
[13]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In Int. Conf. Learn. Represent. (ICLR), 2023. URL https://openreview.net/forum?id=ETKGuby0hcs
work page 2023
-
[14]
J. Douglas Carroll and Jih Jie Chang. Analysis of individual differences in multidimensional scaling via an n-way generalization of “eckart-young” decomposition. Psychometrika, 35: 0 283--319, 1970
work page 1970
-
[15]
Safetynet: Detecting harmful outputs in llms by modeling and monitoring deceptive behaviors
Maheep Chaudhary and Fazl Barez. Safetynet: Detecting harmful outputs in llms by modeling and monitoring deceptive behaviors. arXiv preprint arXiv:2505.14300, 2025
-
[16]
Enhancing model safety through pretraining data filtering
Yanda Chen, Mycal Tucker, Nina Panickssery, Tony Wang, Francesco Mosconi, Anjali Gopal, Carson Denison, Linda Petrini, Jan Leike, Ethan Perez, and Mrinank Sharma. Enhancing model safety through pretraining data filtering. URL https://alignment.anthropic.com/2025/pretraining-data-filtering/. Alignment Science Blog
work page 2025
-
[17]
Grigorios G. Chrysos, Stylianos Moschoglou, Giorgos Bouritsas, Yannis Panagakis, Jiankang Deng, and Stefanos Zafeiriou. P-nets: Deep polynomial neural networks. In IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), June 2020
work page 2020
-
[18]
Grigorios G. Chrysos, Stylianos Moschoglou, Giorgos Bouritsas, Jiankang Deng, Yannis Panagakis, and Stefanos Zafeiriou. Deep polynomial neural networks. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 44 0 (8): 0 4021--4034, 2022. doi:10.1109/TPAMI.2021.3058891
-
[19]
Regularization of polynomial networks for image recognition
Grigorios G Chrysos, Bohan Wang, Jiankang Deng, and Volkan Cevher. Regularization of polynomial networks for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 16123--16132, 2023
work page 2023
-
[20]
Scalable interpretability via polynomials
Abhimanyu Dubey, Filip Radenovic, and Dhruv Mahajan. Scalable interpretability via polynomials. Adv. Neural Inform. Process. Syst. (NeurIPS), 35: 0 36748--36761, 2022
work page 2022
-
[21]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pp.\ arXiv--2407, 2024
work page 2024
-
[22]
Not all language model features are one-dimensionally linear
Joshua Engels, Eric J Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=d63a4AM4hb
work page 2025
-
[23]
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram \'e , Morgane Rivi \`e re, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Detecting strategic deception using linear probes
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimersheim, and Marius Hobbhahn. Detecting strategic deception using linear probes. arXiv preprint arXiv:2502.03407, 2025
-
[25]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
PNeRV : A polynomial neural representation for videos
Sonam Gupta, Snehal Singh Tomar, Grigorios G Chrysos, Sukhendu Das, and Ambasamudram Narayanan Rajagopalan. PNeRV : A polynomial neural representation for videos. arXiv preprint arXiv:2406.19299, 2024
-
[27]
Phi-3 safety post-training: Aligning language models with a ``break-fix''' cycle
Emman Haider, Daniel Perez-Becker, Thomas Portet, Piyush Madan, Amit Garg, Atabak Ashfaq, David Majercak, Wen Wen, Dongwoo Kim, Ziyi Yang, et al. Phi-3 safety post-training: Aligning language models with a ``break-fix''' cycle. arXiv preprint arXiv:2407.13833, 2024
-
[28]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs . In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.), Adv. Neural Inform. Process. Syst. (NeurIPS), volume...
work page 2024
-
[29]
Dynamic neural networks: A survey
Yizeng Han, Gao Huang, Shiji Song, Le Yang, Honghui Wang, and Yulin Wang. Dynamic neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 44 0 (11): 0 7436--7456, 2021
work page 2021
-
[30]
Designing and interpreting probes with control tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 2733--2743, Hong Kong, Chin...
-
[31]
The expression of a tensor or a polyadic as a sum of products
Frank Lauren Hitchcock. The expression of a tensor or a polyadic as a sum of products. Journal of Mathematics and Physics, 6: 0 164--189, 1927
work page 1927
-
[32]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. In Int. Conf. Learn. Represent. (ICLR), 2024. URL https://openreview.net/forum?id=F76bwRSLeK
work page 2024
-
[33]
John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Sanmi Koyejo, Henry Sleight, Erik Jones, Ethan Perez, and Mrinank Sharma. Best-of-n jailbreaking. arXiv preprint arXiv:2412.03556, 2024
-
[34]
Llama guard: LLM -based input-output safeguard for human- AI conversations, 2023
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: LLM -based input-output safeguard for human- AI conversations, 2023
work page 2023
-
[35]
Siddhant M. Jayakumar, Wojciech M. Czarnecki, Jacob Menick, Jonathan Schwarz, Jack Rae, Simon Osindero, Yee Whye Teh, Tim Harley, and Razvan Pascanu. Multiplicative interactions and where to find them. In Int. Conf. Learn. Represent. (ICLR), 2020. URL https://openreview.net/forum?id=rylnK6VtDH
work page 2020
-
[36]
Beavertails: Towards improved safety alignment of LLM via a human-preference dataset
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of LLM via a human-preference dataset. arXiv preprint arXiv:2307.04657, 2023
-
[37]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. Adv. Neural Inform. Process. Syst. (NeurIPS), 35: 0 22199--22213, 2022
work page 2022
-
[38]
Tensor decompositions and applications
Tamara G Kolda and Brett W Bader. Tensor decompositions and applications. SIAM review, 51 0 (3): 0 455--500, 2009
work page 2009
-
[39]
From judgment to interference: Early stopping LLM harmful outputs via streaming content monitoring
Yang Li, Qiang Sheng, Yehan Yang, Xueyao Zhang, and Juan Cao. From judgment to interference: Early stopping LLM harmful outputs via streaming content monitoring. arXiv preprint arXiv:2506.09996, 2025
-
[40]
Simple probes can catch sleeper agents, 2024
Monte MacDiarmid, Timothy Maxwell, Nicholas Schiefer, Jesse Mu, Jared Kaplan, David Duvenaud, Sam Bowman, Alex Tamkin, Ethan Perez, Mrinank Sharma, Carson Denison, and Evan Hubinger. Simple probes can catch sleeper agents, 2024. URL https://www.anthropic.com/news/probes-catch-sleeper-agents
work page 2024
-
[41]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
Alexander Novikov, Mikhail Trofimov, and Ivan Oseledets. Exponential machines. arXiv preprint arXiv:1605.03795, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[43]
Deep ignorance: Filtering pretraining data builds tamper-resistant safeguards into open-weight LLMs
Kyle O'Brien, Stephen Casper, Quentin Anthony, Tomek Korbak, Robert Kirk, Xander Davies, Ishan Mishra, Geoffrey Irving, Yarin Gal, and Stella Biderman. Deep ignorance: Filtering pretraining data builds tamper-resistant safeguards into open-weight LLMs . arXiv preprint arXiv:2508.06601, 2025
-
[44]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Adv. Neural Inform. Process. Syst. (NeurIPS), 35: 0 27730--27744, 2022
work page 2022
-
[45]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In Causal Representation Learning Workshop at NeurIPS 2023, 2023. URL https://openreview.net/forum?id=T0PoOJg8cK
work page 2023
-
[46]
Maja Pavlovic. Understanding model calibration - a gentle introduction and visual exploration of calibration and the expected calibration error ( ECE ). In ICLR Blogposts 2025, 2025. URL https://iclr-blogposts.github.io/2025/blog/calibration/. https://iclr-blogposts.github.io/2025/blog/calibration/
work page 2025
-
[47]
Bilinear MLP s enable weight-based mechanistic interpretability
Michael T Pearce, Thomas Dooms, Alice Rigg, Jose Oramas, and Lee Sharkey. Bilinear MLP s enable weight-based mechanistic interpretability. In Int. Conf. Learn. Represent. (ICLR), 2025
work page 2025
-
[48]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in P ython. Journal of Machine Learning Research, 12: 0 2825--2830, 2011
work page 2011
-
[49]
P areto probing: T rading off accuracy for complexity
Tiago Pimentel, Naomi Saphra, Adina Williams, and Ryan Cotterell. P areto probing: T rading off accuracy for complexity. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 3138--3153, Online, November 2020 a . Association for Computational Lingu...
-
[50]
Information-theoretic probing for linguistic structure
Tiago Pimentel, Josef Valvoda, Rowan Hall Maudslay, Ran Zmigrod, Adina Williams, and Ryan Cotterell. Information-theoretic probing for linguistic structure. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 4609--4622, Online, July 2020 b ...
-
[51]
Computationally efficient face detection
Sami Romdhani, Philip Torr, Bernhard Scholkopf, and Andrew Blake. Computationally efficient face detection. In Int. Conf. Comput. Vis. (ICCV), volume 2, pp.\ 695--700. IEEE, 2001
work page 2001
-
[52]
Understanding learning dynamics of language models with SVCCA
Naomi Saphra and Adam Lopez. Understanding learning dynamics of language models with SVCCA . In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp.\ 3257--3267, Minneap...
-
[53]
The ‘strong’ feature hypothesis could be wrong, August 2024
Lewis Smith. The ‘strong’ feature hypothesis could be wrong, August 2024. URL https://www.lesswrong.com/posts/tojtPCCRpKLSHBdpn/the-strong-feature-hypothesis-could-be-wrong. LessWrong post
work page 2024
-
[54]
The generalized weierstrass approximation theorem
Marshall H Stone. The generalized weierstrass approximation theorem. Mathematics Magazine, 21 0 (5): 0 237--254, 1948
work page 1948
-
[55]
Factual self-awareness in language models: Representation, robustness, and scaling
Hovhannes Tamoyan, Subhabrata Dutta, and Iryna Gurevych. Factual self-awareness in language models: Representation, robustness, and scaling. arXiv preprint arXiv:2505.21399, 2025
-
[56]
Qwen Team. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Branchynet: Fast inference via early exiting from deep neural networks
Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In Int. Conf. Pattern Recog., pp.\ 2464--2469. IEEE, 2016
work page 2016
-
[58]
Investigating task-specific prompts and sparse autoencoders for activation monitoring, April 2025
Henk Tillman and Dan Mossing. Investigating task-specific prompts and sparse autoencoders for activation monitoring, April 2025
work page 2025
-
[59]
Q* : Improving multi-step reasoning for LLMs with deliberative planning
Chaojie Wang, Yanchen Deng, Zhiyi Lyu, Liang Zeng, Jujie He, Shuicheng Yan, and Bo An. Q* : Improving multi-step reasoning for LLMs with deliberative planning. arXiv preprint arXiv:2406.14283, 2024
-
[60]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022
work page 2022
-
[61]
Using GPT-4 for content moderation
Lilian Weng, Vik Goel, and Andrea Vallone. Using GPT-4 for content moderation. URL https://openai.com/index/using-gpt-4-for-content-moderation/
-
[62]
White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell
Jennifer C. White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell. A non-linear structural probe. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Compu...
-
[63]
From hard refusals to safe-completions: Toward output-centric safety training
Yuan Yuan, Tina Sriskandarajah, Anna-Luisa Brakman, Alec Helyar, Alex Beutel, Andrea Vallone, and Saachi Jain. From hard refusals to safe-completions: Toward output-centric safety training. arXiv preprint arXiv:2508.09224, 2025
-
[64]
ShieldGemma 2: Robust and tractable image content moderation, 2025
Wenjun Zeng, Dana Kurniawan, Ryan Mullins, Yuchi Liu, Tamoghna Saha, Dirichi Ike-Njoku, Jindong Gu, Yiwen Song, Cai Xu, Jingjing Zhou, Aparna Joshi, Shravan Dheep, Mani Malek, Hamid Palangi, Joon Baek, Rick Pereira, and Karthik Narasimhan. ShieldGemma 2: Robust and tractable image content moderation, 2025. URL https://arxiv.org/abs/2504.01081
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.