Inferring Dynamic Physical Properties from Video Foundation Models
Pith reviewed 2026-05-18 10:04 UTC · model grok-4.3
The pith
Pre-trained video foundation models can infer dynamic physical properties like elasticity, viscosity, and friction from video footage using simple readouts or prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
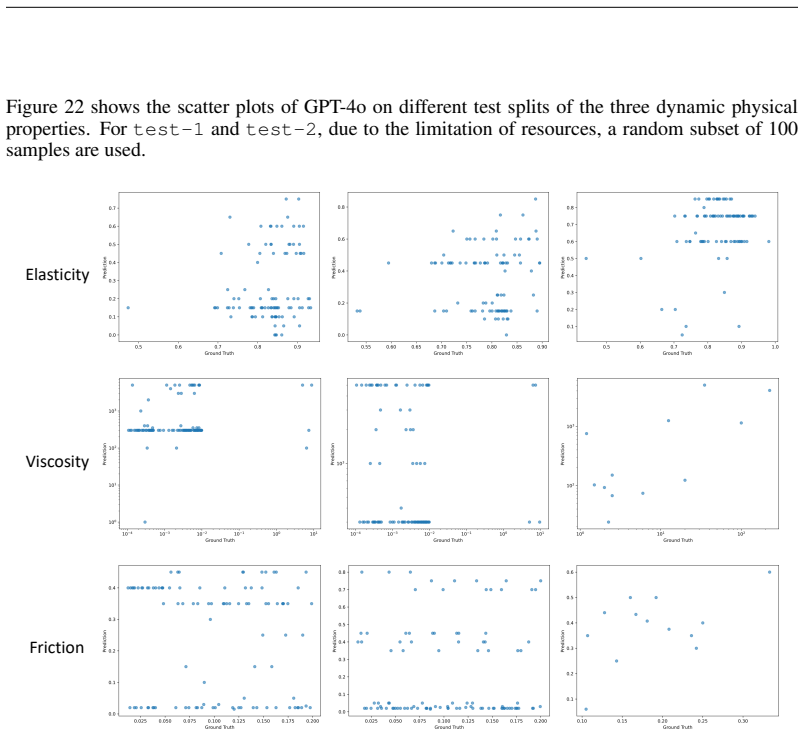
The central claim is that a video foundation model trained in a generative manner such as DynamiCrafter or in a self-supervised manner such as V-JEPA-2 can be equipped with a simple readout mechanism or prompting strategy to infer dynamic physical properties from videos at a level generally similar to each other though still below an oracle that supplies classical computer vision cues, while multimodal large language models currently lag but can be improved by suitable prompting.
What carries the argument
A readout mechanism that applies a visual prompt together with a trainable prompt vector for cross-attention inside a frozen pre-trained video foundation model, or equivalent prompt strategies inside MLLMs, to regress scalar values for elasticity, viscosity, or dynamic friction.
If this is right
- Generative and self-supervised video pre-training objectives capture comparable temporal information relevant to physical property inference.
- A lightweight readout added to frozen foundation models is sufficient to extract dynamic properties without full fine-tuning.
- Prompt engineering offers a practical route to raise MLLM performance on the same physical-inference tasks.
- The new synthetic-plus-real datasets provide a standardized testbed for measuring generalization from controlled to uncontrolled video.
Where Pith is reading between the lines
- If the same readout works for elasticity, viscosity and friction, it may also support inference of other time-dependent properties such as thermal conductivity or restitution coefficients when suitable video data exists.
- Successful inference of these properties from video could be chained to improve downstream video prediction models that must respect physical consistency.
- The gap between oracle and foundation-model performance on real videos highlights a concrete target for future self-supervised objectives that explicitly reward physical plausibility.
Load-bearing premise
The real split collected for each dataset serves as a faithful proxy for uncontrolled real-world video conditions so that accuracy measured on it indicates how well the methods will generalize to arbitrary physical videos.
What would settle it
A result on the real test split in which the readout from either DynamiCrafter or V-JEPA-2 shows no statistically significant advantage over the best MLLM prompting baseline for viscosity estimation, or in which both fall far below the oracle method on elasticity estimation.
Figures






















read the original abstract
We study the task of predicting dynamic physical properties from videos. More specifically, we consider physical properties that require temporal information to be inferred: elasticity of a bouncing object, viscosity of a flowing liquid, and dynamic friction of an object sliding on a surface. To this end, we make the following contributions: (i) We collect a new video dataset for each physical property, consisting of synthetic training and testing splits, as well as a real split for real world evaluation. (ii) We explore three ways to infer the physical property from videos: (a) an oracle method where we supply the visual cues that intrinsically reflect the property using classical computer vision techniques; (b) a simple read out mechanism using a visual prompt and trainable prompt vector for cross-attention on pre-trained video generative and self-supervised models; and (c) prompt strategies for Multi-modal Large Language Models (MLLMs). (iii) We show that a video foundation model trained in a generative (DynamiCrafter) or trained in a self-supervised manner (V-JEPA-2) achieve a generally similar performance, though behind that of the oracle, and that MLLMs are currently inferior to the other models, though their performance can be improved through suitable prompting. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/idpp/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the task of inferring dynamic physical properties (elasticity of bouncing objects, viscosity of flowing liquids, dynamic friction of sliding objects) from video. It contributes new datasets with synthetic train/test splits plus a real split, compares an oracle using classical CV cues, a readout mechanism on pre-trained video models (DynamiCrafter generative and V-JEPA-2 self-supervised) via visual prompts, and prompting strategies for MLLMs. The central claim is that the two foundation models achieve generally similar performance (behind the oracle but ahead of MLLMs, whose results improve with suitable prompting).
Significance. If the real-world evaluation is valid, the work demonstrates that generative and self-supervised video foundation models implicitly encode dynamic physical properties without task-specific training, positioning them as competitive with classical CV oracles for this inference task. The public release of the dataset, model, and code is a clear strength for reproducibility.
major comments (2)
- [Dataset collection] Dataset section (contribution i and real-split description): The manuscript presents the real split as the key test of generalization to uncontrolled physical videos, yet supplies no details on scene diversity, camera motion, lighting variation, material range, or independent ground-truth acquisition (e.g., lab-measured restitution coefficients or viscosity versus visual estimation). This assumption is load-bearing for the claim that measured performance indicates usable real-world inference.
- [Results and evaluation] Results section: The abstract and evaluation claim that DynamiCrafter and V-JEPA-2 achieve 'generally similar performance' and that MLLMs are inferior (but improvable), but the provided text contains no quantitative metrics, error bars, dataset statistics, or statistical tests supporting the performance ordering or the gap to the oracle; this leaves the central empirical claims difficult to assess.
minor comments (2)
- [Abstract] Abstract: The high-level performance ordering would be clearer if the specific metrics (e.g., MAE, correlation) were named even briefly.
- Notation: Ensure consistent use of 'dynamic friction' versus 'friction coefficient' across text and figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects for strengthening the presentation of our work on inferring dynamic physical properties from video foundation models. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Dataset collection] Dataset section (contribution i and real-split description): The manuscript presents the real split as the key test of generalization to uncontrolled physical videos, yet supplies no details on scene diversity, camera motion, lighting variation, material range, or independent ground-truth acquisition (e.g., lab-measured restitution coefficients or viscosity versus visual estimation). This assumption is load-bearing for the claim that measured performance indicates usable real-world inference.
Authors: We agree that more detailed documentation of the real split is essential to substantiate the generalization claims. In the revised manuscript, we will expand the dataset section with explicit descriptions of scene diversity (e.g., indoor/outdoor environments and object types), camera motion variations, lighting conditions, and material ranges. Regarding ground-truth acquisition, labels for the real videos were obtained via multi-annotator visual estimation following standardized protocols for each property (e.g., counting bounces for elasticity), with inter-annotator agreement reported; we acknowledge that independent lab measurements would provide stronger validation but were not available due to practical constraints in collecting uncontrolled real-world footage. We will clarify this distinction and its implications for the results. revision: yes
-
Referee: [Results and evaluation] Results section: The abstract and evaluation claim that DynamiCrafter and V-JEPA-2 achieve 'generally similar performance' and that MLLMs are inferior (but improvable), but the provided text contains no quantitative metrics, error bars, dataset statistics, or statistical tests supporting the performance ordering or the gap to the oracle; this leaves the central empirical claims difficult to assess.
Authors: We apologize for the lack of explicit numerical summaries in the narrative text. The full quantitative results—including mean performance metrics with standard deviations (error bars), dataset statistics (e.g., split sizes and property distributions), and comparisons across methods—are reported in Tables 1–3 and visualized in Figures 2–5 of the results section. In the revision, we will insert direct textual references to these tables and figures, along with a concise summary paragraph highlighting key values and the observed ordering (foundation models behind oracle but ahead of MLLMs). While we did not include formal statistical significance tests, we can add them in the revision if the referee deems it necessary; the current evidence for 'generally similar performance' rests on the consistent trends across multiple properties and splits shown in the tables. revision: partial
Circularity Check
No circularity: empirical comparisons on newly collected datasets
full rationale
The paper introduces new video datasets with synthetic train/test splits and a real split, then runs controlled experiments comparing an oracle (classical CV cues), readout heads on pre-trained video foundation models (DynamiCrafter, V-JEPA-2), and prompted MLLMs. No equations, derivations, or first-principles claims are present. Performance numbers are measured on held-out data rather than being fitted parameters renamed as predictions. No self-citation chains or ansatzes are invoked to justify core results. The evaluation is self-contained against external benchmarks (new data collection and model comparisons).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video footage contains sufficient visual information to infer dynamic physical properties such as elasticity, viscosity, and friction.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We explore three ways to infer the physical property from videos: (a) an oracle method where we supply the visual cues... using classical computer vision techniques; (b) a simple read out mechanism using a visual prompt and trainable prompt vector for cross-attention on pre-trained video generative and self-supervised models
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the ratio of the height difference... the slope of the normalized area size sequence... fit a parabola x=αt²+βt+c ... μ_k = 2α/g
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
PhysInOne: Visual Physics Learning and Reasoning in One Suite
PhysInOne is a new dataset of 2 million videos across 153,810 dynamic 3D scenes covering 71 physical phenomena, shown to improve AI performance on physics-aware video generation, prediction, property estimation, and m...
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Fitvid: Overfitting in pixel-level video prediction.arXiv preprint arXiv:2106.13195,
Mohammad Babaeizadeh, Mohammad Taghi Saffar, Suraj Nair, Sergey Levine, Chelsea Finn, and Dumitru Erhan. Fitvid: Overfitting in pixel-level video prediction.arXiv preprint arXiv:2106.13195,
-
[3]
Bear, Elias Wang, Damian Mrowca, Felix J
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines.arXiv preprint arXiv:2106.08261,
-
[4]
Florian Bordes, Quentin Garrido, Justine T Kao, Adina Williams, Michael Rabbat, and Emmanuel Dupoux. Intphys 2: Benchmarking intuitive physics understanding in complex synthetic environ- ments.arXiv preprint arXiv:2506.09849,
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision (ECCV), 2024a. Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Hua...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Grounding dino 1.5: Advance the "edge" of open-set object detection, 2024
11 Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, Yuda Xiong, Hao Zhang, Feng Li, Peijun Tang, Kent Yu, and Lei Zhang. Grounding dino 1.5: Advance the ”edge” of open-set object detection.arXiv preprint arXiv:2405.10300, 2024a. Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Ku...
-
[10]
Phyx: Does your model have the” wits” for physical reasoning?arXiv preprint arXiv:2505.15929,
Hui Shen, Taiqiang Wu, Qi Han, Yunta Hsieh, Jizhou Wang, Yuyue Zhang, Yuxin Cheng, Zijian Hao, Yuansheng Ni, Xin Wang, et al. Phyx: Does your model have the” wits” for physical reasoning?arXiv preprint arXiv:2505.15929,
-
[11]
Vikram V oleti, Alexia Jolicoeur-Martineau, and Christopher Pal. Masked conditional video diffusion for prediction, generation, and interpolation.arXiv preprint arXiv:2205.09853,
-
[12]
Neural Material: Learning Elastic Constitutive Material and Damping Models from Sparse Data
Bin Wang, Paul Kry, Yuanmin Deng, Uri Ascher, Hui Huang, and Baoquan Chen. Neural mate- rial: Learning elastic constitutive material and damping models from sparse data.arXiv preprint arXiv:1808.04931,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A.3 DETAILS OFVIDEOINPUT We uniformly sample 16 frames per video as input to all the models for fair comparison. The 16 frames are uniformly sampled so that the physics process we want to study is properly reflected with the sampled 16 frames,e.g.,the dropping and bouncing of the ball, the expansion of the liquid, and the slowing-down sliding process of t...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.