Exploring Cross-Client Memorization of Training Data in Large Language Models for Federated Learning
Pith reviewed 2026-05-18 08:26 UTC · model grok-4.3
The pith
Federated learning models memorize training data from the same client more than from other clients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
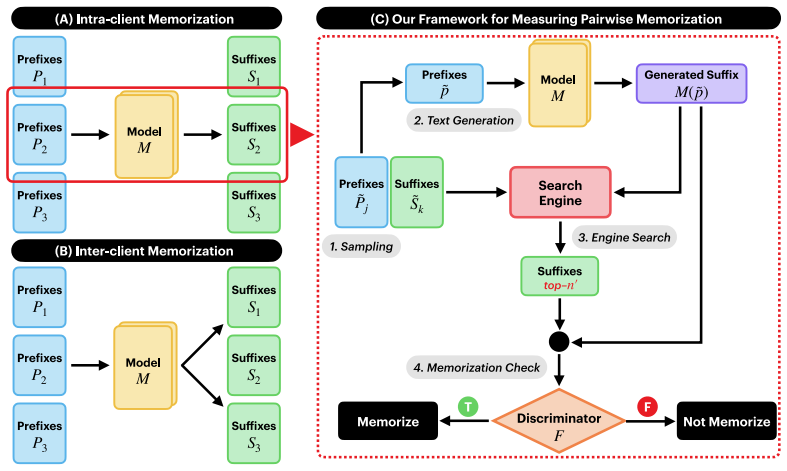
Federated learning models for large language models memorize client data, with intra-client memorization exceeding inter-client memorization. This effect is shaped by training factors such as the choice of federated learning algorithm and by inferencing factors including decoding strategies and prefix length. The authors reach this conclusion by building a framework that adapts fine-grained cross-sample memorization metrics to the federated setting so that both intra-client and inter-client effects can be quantified without ever pooling client data.
What carries the argument
The framework that quantifies intra-client and inter-client memorization by applying fine-grained cross-sample memorization measurement across distributed clients without centralizing the data.
If this is right
- Intra-client samples produce higher memorization scores than inter-client samples under the proposed measurement.
- The specific federated learning algorithm chosen during training changes the overall level of observed memorization.
- Decoding strategy and prefix length at inference time alter how much memorization the framework detects.
- Single-sample detection methods miss the additional cross-sample patterns that appear within client boundaries.
Where Pith is reading between the lines
- Client isolation in federated learning reduces but does not eliminate data retention risks because intra-client effects remain strong.
- The measurement could be applied to audit deployed federated systems for unintended leakage of client-specific examples.
- If memorization scales with the number of participating clients, larger federations might naturally lower inter-client retention.
Load-bearing premise
Fine-grained cross-sample memorization metrics created for centralized datasets can be transferred to measure effects between and within separate client datasets in federated learning without requiring all data to be gathered in one place.
What would settle it
A controlled run in which the same model is trained once in a fully centralized setting and once under the federated protocol, then measured with both the original centralized metric and the new framework, would show mismatched intra- versus inter-client scores if the distinction does not hold.
Figures
read the original abstract
Federated learning (FL) enables collaborative training without raw data sharing, but still risks training data memorization. Existing FL memorization detection techniques focus on one sample at a time, underestimating more subtle risks of cross-sample memorization. In contrast, recent work on centralized learning (CL) has introduced fine-grained methods to assess memorization across all samples in training data, but these assume centralized access to data and cannot be applied directly to FL. We bridge this gap by proposing a framework that quantifies both intra- and inter-client memorization in FL using fine-grained cross-sample memorization measurement across all clients. Based on this framework, we conduct two studies: (1) measuring subtle memorization across clients and (2) examining key factors that influence memorization, including decoding strategies, prefix length, and FL algorithms. Our findings reveal that FL models do memorize client data, particularly intra-client data, more than inter-client data, with memorization influenced by training and inferencing factors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework adapting fine-grained cross-sample memorization metrics from centralized learning to federated learning (FL) settings for LLMs. This enables quantification of both intra-client and inter-client memorization without raw data centralization. The authors conduct two empirical studies: (1) measuring subtle cross-client memorization patterns and (2) examining the effects of factors including decoding strategies, prefix length, and FL algorithms. The central claim is that FL models memorize intra-client data more than inter-client data, with the degree of memorization modulated by training and inference choices.
Significance. If the framework faithfully transfers the centralized metrics without systematic bias in inter-client comparisons, the work would usefully highlight differential privacy risks in FL for LLMs and identify actionable factors for mitigation. The empirical focus on cross-sample (rather than single-sample) memorization addresses a noted gap relative to prior FL detection methods.
major comments (2)
- [Framework / Methodology] Framework section: the central claim that intra-client memorization exceeds inter-client memorization depends on the framework accurately adapting CL cross-sample metrics (e.g., pairwise influence or similarity) to FL. The manuscript must specify the exact proxies or local computations used for inter-client signals, since any approximation that avoids pooled data access risks under- or over-estimating inter-client relative to intra-client values and thereby undermining the reported differential.
- [Studies 1 and 2 / Results] Results of Studies 1 and 2: the abstract and main results report only directional findings without quantitative memorization scores, error bars, dataset sizes, client counts, or exclusion criteria. This makes it impossible to evaluate whether post-hoc factor choices or metric thresholds affect the intra-versus-inter claim or the factor-influence conclusions.
minor comments (2)
- [Abstract] Abstract: consider adding one or two concrete quantitative results (e.g., relative memorization ratios or statistical significance) to convey the magnitude of the reported effects.
- [Preliminaries / Framework] Notation: ensure consistent definition of 'cross-sample memorization' when moving from the CL literature to the FL instantiation, including any modifications to the original metric.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Framework / Methodology] Framework section: the central claim that intra-client memorization exceeds inter-client memorization depends on the framework accurately adapting CL cross-sample metrics (e.g., pairwise influence or similarity) to FL. The manuscript must specify the exact proxies or local computations used for inter-client signals, since any approximation that avoids pooled data access risks under- or over-estimating inter-client relative to intra-client values and thereby undermining the reported differential.
Authors: We agree that explicit details on the adaptation are necessary to substantiate the intra- versus inter-client differential. Our framework adapts the centralized cross-sample metrics by performing all intra-client computations locally on each client's private data using direct pairwise similarity measures. For inter-client signals, we use a proxy based on cosine similarity of client-specific model embeddings derived from aggregated updates, without any raw data exchange or central pooling. To fully address the concern, we will revise the Framework section to include the precise mathematical formulations, local computation steps, and pseudocode for both intra- and inter-client proxies. revision: yes
-
Referee: [Studies 1 and 2 / Results] Results of Studies 1 and 2: the abstract and main results report only directional findings without quantitative memorization scores, error bars, dataset sizes, client counts, or exclusion criteria. This makes it impossible to evaluate whether post-hoc factor choices or metric thresholds affect the intra-versus-inter claim or the factor-influence conclusions.
Authors: We acknowledge that the current results emphasize directional trends and would benefit from additional quantitative context. In the revised manuscript, we will augment the Results sections for both studies with specific memorization score values, error bars (standard deviations across multiple runs), exact dataset sizes and client counts, and any exclusion criteria used for samples or clients. These details will also be reflected in an updated abstract to enable readers to assess robustness and potential threshold sensitivities. revision: yes
Circularity Check
No circularity in empirical framework for FL memorization measurement
full rationale
The paper is an empirical study that proposes a framework to adapt fine-grained cross-sample memorization metrics from centralized learning to federated settings for quantifying intra- and inter-client effects. No mathematical derivations, self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citation chains are present in the described chain. Findings rest on experimental measurements of factors like decoding strategies and FL algorithms, remaining self-contained without reducing to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- prefix length
axioms (1)
- domain assumption Fine-grained cross-sample memorization metrics from centralized learning remain meaningful when applied client-wise in federated training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We bridge this gap by proposing a framework that quantifies both intra- and inter-client memorization in FL using fine-grained cross-sample memorization measurement across all clients.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Daphne Ippolito, Florian Tramer, Milad Nasr, Chiyuan Zhang, Matthew Jagielski, Katherine Lee, Christo- pher Choquette Choo, and Nicholas Carlini
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Pubmedqa: A dataset for biomedical research question answering. InPro- ceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing and the 9th In- ternational Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577. Hirokazu Kiyomaru, Issa Sugiura, Daisuke Kawahara, and Sadao Kurohashi
work page 2019
-
[3]
Associa- tion for Computing Machinery
Do language models plagiarize? InPro- ceedings of the ACM Web Conference 2023, WWW ’23, page 3637–3647, New York, NY , USA. Associa- tion for Computing Machinery. Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar San- jabi, Ameet Talwalkar, and Virginia Smith
work page 2023
-
[4]
Federated optimization in heterogeneous networks. Preprint, arXiv:1812.06127. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas
-
[5]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Swaroop Ramaswamy, Om Thakkar, Rajiv Mathews, Galen Andrew, H. Brendan McMahan, and Françoise Beaufays
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
InLecture Notes in Computer Science, volume 9283, pages 402–413
Adaptive algorithm for plagiarism detection: The best-performing approach at pan 2014 text alignment competition. InLecture Notes in Computer Science, volume 9283, pages 402–413. Springer. Miguel Sanchez-Perez, Grigori Sidorov, and Alexan- der Gelbukh
work page 2014
-
[8]
Terminology-aware medical dialogue generation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE. Om Dipakbhai Thakkar, Swaroop Ramaswamy, Rajiv Mathews, and Francoise Beaufays
work page 2023
-
[9]
Fedala: adaptive local aggregation for personalized federated learning. InProceedings of the Thirty- Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applica- tions of Artificial Intelligence and Thirteenth Sympo- sium on Educational Advances in Artificial Intelli- gence, AAAI’23/IAAI’23/EAAI’23. AAAI Press. 6 A...
work page 2017
-
[10]
The dataset contains abstracts collected from arXiv.org
dataset, as too much memorization in academic writing can be seen as a form of plagiarism. The dataset contains abstracts collected from arXiv.org. We focus on three sub- ject areas: Astrophysics, Condensed Matter, and Mathematics. For each area, we sample 30,000 examples, with 27,000 used for training and 3,000 for testing. The subcategories are as follo...
work page 2023
-
[11]
It con- tains around 200,000 abstracts from random- ized controlled trials
dataset, derived from PubMed, for sequential sentence classification. It con- tains around 200,000 abstracts from random- ized controlled trials. It consists of 5 compo- nents: background, objective, methods, results, and conclusion. This dataset is publicly available at https://github.com/Franck-Dernoncourt/ pubmed-rct. Following standard practice of dat...
work page 2022
-
[12]
(2023), we empirically study multiple decoding methods: top-k, top-p, and temperature
C.3 Memorization Factors Decode Method:Following Lee et al. (2023), we empirically study multiple decoding methods: top-k, top-p, and temperature. For each decod- ing, we start with the default Huggingface trainer- generated parameters and update them with the following: k=40 for top-k, p=0.8 for top-p, and temperature=1.0for temperature decoding. Prefix ...
work page 2023
-
[13]
The key distinction, however, lies in how the model M is trained: in CL, M is trained cen- trally on the combined datasets by a trusted third party, whereas in the FL setting, M is trained in a distributed manner across clients. E PAN2014 and Three Categories of Memorization E.1 PAN2014 Plagiarism Detector PAN2014 plagiarism detector evaluates text sim- i...
work page 2023
-
[14]
E.4 Hyperparameters for Memorization Measurement Following Zeng et al
as input (prefix+suffix) to our framework for the sum- marization, dialog, question-answering, and classi- fication tasks, respectively. E.4 Hyperparameters for Memorization Measurement Following Zeng et al. (2024), we set the mini- mal match threshold to at least 50 characters for PAN2014 in all memorization types. We also filter out some odd cases, as d...
work page 2024
-
[15]
We find that the generated suffix length is strongly affected by the input and output lengths. Specifically, in summarization and classification tasks, the median of generated suffix lengths is close to the output length. This phenomenon leads the classification task to generate a smaller token than other tasks to the point that its generated suffix lengt...
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.