MTSQL-R1: Towards Long-Horizon Multi-Turn Text-to-SQL via Agentic Training
Pith reviewed 2026-05-18 07:12 UTC · model grok-4.3
The pith
Casting multi-turn Text-to-SQL as an agentic MDP with database feedback and memory produces more executable and coherent queries than short-horizon generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an agentic training framework for long-horizon multi-turn Text-to-SQL, which models the task as a Markov Decision Process where the agent interacts with a database for execution feedback and a persistent dialogue memory for coherence verification while cycling through propose, execute, verify, and refine steps until all checks succeed, consistently outperforms strong baselines on the COSQL and SPARC datasets and shows the value of environment-driven verification together with memory-guided refinement for conversational semantic parsing.
What carries the argument
The iterative propose-execute-verify-refine cycle inside a Markov Decision Process that uses database execution feedback and persistent dialogue memory to drive refinement.
If this is right
- Environment-driven verification reduces the rate of non-executable SQL outputs.
- Memory-guided refinement improves preservation of dialogue coherence across turns.
- The long-horizon agentic paradigm yields higher accuracy than short-horizon per-turn generation on standard conversational benchmarks.
- Persistent state and external feedback become central mechanisms rather than optional add-ons.
Where Pith is reading between the lines
- The same feedback-and-memory loop could be applied to other conversational semantic parsing tasks beyond SQL.
- The method might lower reliance on perfect one-shot training data by correcting errors through interaction.
- Efficiency could be measured by tracking how many refinement steps are needed on average across different dialogue lengths.
Load-bearing premise
The iterative propose-execute-verify-refine cycle will reliably reach coherent and executable SQL without excessive iterations or persistent verification errors.
What would settle it
Testing the trained agent on a fresh multi-turn Text-to-SQL dataset and measuring whether it still outperforms baselines or whether the cycle frequently fails to converge or produces many non-executable outputs.
Figures












read the original abstract
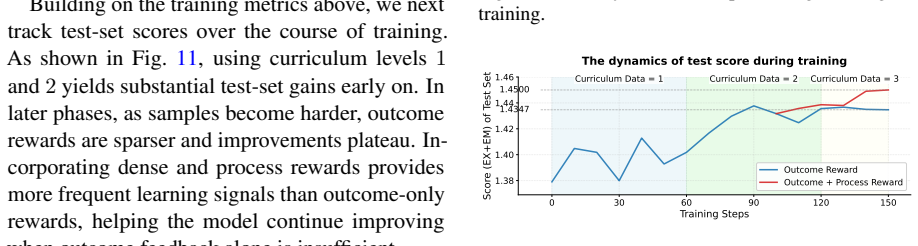
Multi-turn Text-to-SQL aims to translate a user's conversational utterances into executable SQL while preserving dialogue coherence and grounding to the target schema. However, most existing systems only regard this task as a simple text translation task and follow a short-horizon paradigm, generating a query per turn without execution, explicit verification, and refinement, which leads to non-executable or incoherent outputs. We present MTSQL-R1, an agentic training framework for long-horizon multi-turn Text-to-SQL. We cast the task as a Markov Decision Process (MDP) in which an agent interacts with (i) a database for execution feedback and (ii) a persistent dialogue memory for coherence verification, performing an iterative propose to execute -> verify -> refine cycle until all checks pass. Experiments on COSQL and SPARC demonstrate that MTSQL-R1 consistently outperforms strong baselines, highlighting the importance of environment-driven verification and memory-guided refinement for conversational semantic parsing. Full recipes (including code, trained models, logs, reasoning trajectories, etc.) will be released after the internal review to contribute to community research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MTSQL-R1, an agentic training framework that casts multi-turn Text-to-SQL as a Markov Decision Process. An agent performs an iterative propose-execute-verify-refine cycle, interacting with a database for execution feedback and a persistent dialogue memory for coherence checks, until all verifications pass. The central claim is that this long-horizon approach yields consistent outperformance over strong baselines on the CoSQL and SPARC benchmarks, underscoring the value of environment-driven verification and memory-guided refinement for conversational semantic parsing. The authors plan to release code, models, logs, and trajectories after internal review.
Significance. If the performance gains can be shown to arise from the propose-execute-verify-refine loop rather than from substantially higher inference budgets, the work would provide a concrete demonstration that explicit execution feedback and persistent memory improve coherence and executability in multi-turn semantic parsing. The planned public release of full recipes would further strengthen its contribution by enabling direct replication and extension.
major comments (3)
- [Experiments] Experiments section: the manuscript reports that MTSQL-R1 'consistently outperforms strong baselines' on CoSQL and SPARC but provides no quantitative results, baseline names, error bars, or statistical significance tests. Without these numbers it is impossible to assess the magnitude or reliability of the claimed gains.
- [Method and Experiments] Method and Experiments sections: the central claim that the iterative MDP loop drives the improvements rests on the unverified assumption that the propose-execute-verify-refine cycle terminates reliably within a modest number of steps. No data are supplied on average iterations per dialogue, fraction of queries that hit a step limit, convergence failure rates, or total LLM calls per example, leaving open the possibility that gains are an artifact of extra inference budget rather than improved sample efficiency.
- [§3] §3 (MDP formulation): the description of the reward and termination conditions is high-level; it is unclear how the persistent dialogue memory is encoded, how verification failures are turned into refinement signals, and whether the policy is trained with on-policy or off-policy updates. These details are load-bearing for reproducing the agentic training procedure.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction would benefit from a brief comparison table or bullet list of the key differences between MTSQL-R1 and prior short-horizon Text-to-SQL systems.
- [Method] Notation for the MDP components (state, action, reward, transition) should be introduced once and used consistently; currently the text mixes informal descriptions with occasional formal symbols.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and commit to substantial revisions that will strengthen the clarity, reproducibility, and evidential support of the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports that MTSQL-R1 'consistently outperforms strong baselines' on CoSQL and SPARC but provides no quantitative results, baseline names, error bars, or statistical significance tests. Without these numbers it is impossible to assess the magnitude or reliability of the claimed gains.
Authors: We agree that the current draft does not present the results with sufficient quantitative detail. The Experiments section will be revised to include a main results table reporting exact performance metrics (e.g., exact match and execution accuracy) for MTSQL-R1 and all compared baselines on both CoSQL and SPARC. We will add error bars computed over multiple random seeds and include statistical significance tests (paired t-tests or McNemar tests) with p-values. These changes will be incorporated in the revised manuscript. revision: yes
-
Referee: [Method and Experiments] Method and Experiments sections: the central claim that the iterative MDP loop drives the improvements rests on the unverified assumption that the propose-execute-verify-refine cycle terminates reliably within a modest number of steps. No data are supplied on average iterations per dialogue, fraction of queries that hit a step limit, convergence failure rates, or total LLM calls per example, leaving open the possibility that gains are an artifact of extra inference budget rather than improved sample efficiency.
Authors: This concern is well-founded and directly relevant to the central claim. We will add a dedicated analysis subsection (or appendix) reporting the requested statistics: average iterations per dialogue, fraction of examples hitting the step limit, convergence failure rates, and average LLM calls per example for MTSQL-R1 versus the baselines. This will allow readers to evaluate whether performance gains are attributable to the agentic loop or to increased inference budget. The data will be included in the revision. revision: yes
-
Referee: [§3] §3 (MDP formulation): the description of the reward and termination conditions is high-level; it is unclear how the persistent dialogue memory is encoded, how verification failures are turned into refinement signals, and whether the policy is trained with on-policy or off-policy updates. These details are load-bearing for reproducing the agentic training procedure.
Authors: We acknowledge that the current description in §3 is too high-level for full reproducibility. In the revised manuscript we will expand this section with concrete specifications: the exact encoding of persistent dialogue memory (structured JSON summary plus embedding), the full reward function and termination conditions, the mechanism by which verification failures generate refinement actions or prompts, and the training algorithm (including whether updates are on-policy or off-policy, e.g., via PPO or DPO). These additions will make the agentic training procedure reproducible from the paper alone. revision: yes
Circularity Check
No circularity in empirical agentic framework
full rationale
The paper presents MTSQL-R1 as an empirical agentic training framework for multi-turn Text-to-SQL, modeling the task as an MDP with an iterative propose-execute-verify-refine cycle using database feedback and dialogue memory. No mathematical derivations, equations, or self-referential definitions are evident in the abstract or description. Performance claims are based on experiments on CoSQL and SPARC datasets compared to baselines, with plans for code release. This is a standard empirical proposal without any load-bearing steps that reduce to fitted inputs or self-citations by construction. The derivation chain is self-contained as a methodological description rather than a closed-form prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-turn Text-to-SQL can be cast as a Markov Decision Process in which an agent interacts with a database for execution feedback and a persistent dialogue memory for coherence verification.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We cast the task as a Markov Decision Process (MDP) in which an agent interacts with (i) a database for execution feedback and (ii) a persistent dialogue memory for coherence verification, performing an iterative propose → execute → verify → refine cycle until all checks pass.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-level rewards derived from execution success and memory coherence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
AutoLLMResearch: Training Research Agents for Automating LLM Experiment Configuration - Learning from Cheap, Optimizing Expensive
AutoLLMResearch trains agents via a multi-fidelity environment and MDP pipeline to extrapolate configuration principles from inexpensive to costly LLM experiments.
-
AutoLLMResearch: Training Research Agents for Automating LLM Experiment Configuration - Learning from Cheap, Optimizing Expensive
AutoLLMResearch trains agents in a multi-fidelity LLMConfig-Gym environment formulated as a long-horizon MDP to enable cross-fidelity extrapolation for automating high-cost LLM experiment configurations.
Reference graph
Works this paper leans on
-
[4]
If <exec_verify>pass</exec_verify>, You have to call ‘ memory_retrieve‘ tool via <tool_call> at least once to ensure the current generated SQL is coherent with the historical memory. For interacting with memory, we have the “"memory_retrieve" tool: TOOLCONFIGURATION - class_name: "verl.tools.memory_retriever. MemoryRetriever" config: {} tool_schema: type:...
-
[5]
Verify whether the Proposed SQL is coherent with the Current Question and the Memory, based on the relation between the Current Question and Historical Questions. - If the Current Question introduces changes (new columns, conditions, ordering, etc.), SQL should update accordingly. - If not, SQL must remain consistent with the Historical Questions. Step-by...
-
[6]
First parse the Proposed SQL into its components ( SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY, JOINs)
-
[14]
If ‘no_pass‘: explain issues, think step by step to refine SQL, and then please call ‘exec_sql‘ tool again via <tool_call> to check the corrected SQL and get the execution results. Repeat until you get ‘pass‘
-
[15]
If ‘pass‘: return the final SQL inside ‘<answer_sql >...</answer_sql>‘. Note finally you should return the final SQL inside ‘< answer_sql>...</answer_sql> Tool-Related Hyperparameters TOOLCONFIGURATION actor_rollout_ref: hybrid_engine: True rollout: name: sglang multi_turn: enable: True max_turns: 4 # Important Max-turns 14 B.0.2 Hyperparameter Settings H...
work page 1970
-
[16]
Join countries and continents to get the continent info for the USA
-
[17]
Find the CountryId of the USA from the countries table
-
[18]
Count the number of car_makers where Country equals that CountryId. Alternatively, maybe I can directly join car_makers with countries on Country, then filter where CountryName is ’USA’ and count the entries. So the SQL would involve joining car_makers with countries on the Country column, then filtering where CountryName is ’USA’, and then counting the n...
-
[22]
Return the final SQL enclosed in: <answer_sql> ... </answer_sql> Here are previous question and corresponding correct SQL in this dialogue: ## Turn 1 ## "Database schema: create table continents ( ContId number, Continent text, primary key (ContId) ) /* 1 example rows from table continents: ContId Continent 1 america */ create table countries ( CountryId ...
work page 1970
-
[26]
If <exec_verify>pass</exec_verify>, You have to call ‘memory_retrieve‘ tool via <tool_call> at least once to ensure the current generated SQL is coherent with the historical memory. </tool_response> ♂robotThought <think> Okay, let’s see. The user asked for the number of car makers in the USA. The SQL I generated was joining car_makers with countries on Co...
-
[30]
If <exec_verify>pass</exec_verify>, You have to call ‘memory_retrieve‘ tool via <tool_call> at least once to ensure the current generated SQL is coherent with the historical memory. </tool_response> ♂robotThought <think> Okay, let’s check the results. The SQL query now returns [(4,)], which means there are 4 car makers in the USA. Looking at the example d...
-
[40]
If ‘no_pass‘: explain issues, think step by step to refine SQL, and you can call ‘exec_sql‘ tool again via < tool_call> to check the corrected SQL and get the execution results until you get ‘pass‘
-
[41]
If ‘pass‘: return the final SQL inside ‘<answer_sql>...</answer_sql>‘. Note finally you should return the final SQL inside ‘<answer_sql>...</answer_sql> </tool_response> 23 ♂robotThought <think> Okay, let’s verify the coherence of the proposed SQL with the current question and historical memory
-
[42]
It joins car_makers with countries on CountryId and filters by CountryName
**Parse the Proposed SQL**: The SQL selects the count of car makers where the country name is ’usa’. It joins car_makers with countries on CountryId and filters by CountryName
-
[43]
**Tables Consistency**: The tables involved (car_makers, countries) are correct based on the schema. The join condition (car_makers.Country = countries.CountryId) is accurate as per the foreign key relationship
-
[44]
**Selected Columns**: The SELECT clause uses COUNT(*), which is appropriate for counting the number of car makers. The WHERE clause filters for ’usa’ in CountryName, which aligns with the current question about the USA
-
[45]
**Conditions**: The WHERE clause correctly targets the USA by CountryName. The historical question grouped by continent, but this question is specific to a country, so the condition is appropriate
-
[46]
**Ordering**: There’s no ORDER BY in the SQL, which is fine since the question just needs a count, not sorted results
-
[47]
The historical SQL also used similar joins, so this is consistent
**Joins and Relationships**: The join between car_makers and countries is correct. The historical SQL also used similar joins, so this is consistent
-
[48]
**Execution Results**: The result [(4,)] indicates 4 car makers in the USA, which matches the example data’s implication (the sample car_makers entry with Country 1, which is the USA). The SQL is coherent with the current question and historical context. It correctly adjusts the historical query from grouping by continent to filtering by a specific countr...
-
[49]
Reasoning - Always think step by step before calling the tool. Draft the SQL
-
[50]
Calling ‘exec_sql‘ tool (Please call ‘exec_sql‘ tool at least once) - Call the ‘exec_sql‘ tool to execute the current generated SQL and verify the execution results based on questions. - conclude <exec_verify>pass</exec_verify> if results are reasonable, otherwise <exec_verify>no_pass</exec_verify>. - If no_pass, refine the SQL using the execution results...
-
[51]
Please call ‘exec_sql‘ tool at least once
-
[52]
Return the final SQL enclosed in: <answer_sql> ... </answer_sql> Here are previous question and corresponding correct SQL in this dialogue: ## Turn 1 ## User: "Database schema: create table city ( ID number, Name text, CountryCode text, District text, Population number, primary key (ID), foreign key (CountryCode) references country(Code) ) /* 1 example ro...
-
[53]
- Check if the returned columns exist in the schema and are relevant to the question
Verify whether the SQL execution results are valid: - Check if the SQL runs without errors. - Check if the returned columns exist in the schema and are relevant to the question. - Check if the results contain unexpected NULL values, empty sets, or error messages
-
[54]
After verifying, output: - <exec_verify>pass</exec_verify> if the results are valid and consistent with the schema. - <exec_verify>no_pass</exec_verify> if the results show errors, irrelevant columns, or invalid values
-
[55]
Repeat until you get valid results
If <exec_verify>no_pass</exec_verify>, think step by step, refine the SQL and provide a corrected SQL and then execute it via re-calling ‘‘exec_sql‘‘ tool again via <tool_call>. Repeat until you get valid results
-
[56]
If <exec_verify>pass</exec_verify>, You have to call ‘memory_retrieve‘ tool via <tool_call> at least once to ensure the current generated SQL is coherent with the historical memory. </tool_response> ♂robotThought <think> Okay, let’s start by verifying the SQL execution results. The generated SQL is: SELECT GovernmentForm, SUM(Population) FROM country GROU...
-
[57]
Verify whether the Proposed SQL is coherent with the Current Question and the Memory, based on the relation between the Current Question and Historical Questions. - If the Current Question introduces changes (new columns, conditions, ordering, etc.), SQL should update accordingly . - If not, SQL must remain consistent with the Historical Questions. Step-b...
-
[58]
First parse the Proposed SQL into its components (SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY, JOINs)
-
[59]
Check tables are consistent with context
-
[60]
Check selected columns match current and historical intent
-
[61]
Check conditions (WHERE/GROUP/HAVING) reflect the relation between current and past questions
-
[62]
Check ordering (ORDER BY) is preserved unless explicitly changed
-
[63]
Verify that joins and table relationships follow the established context
-
[64]
Make sure the SQL and the execution results of the proposed SQL answer the current question while remaining logically coherent with the conversation history and execution results
-
[65]
- ‘<memory_verify>no_pass</memory_verify>‘ if not coherent
After verifying, output one of the following: - ‘<memory_verify>pass</memory_verify>‘ if coherent. - ‘<memory_verify>no_pass</memory_verify>‘ if not coherent
-
[66]
If ‘no_pass‘: explain issues, think step by step to refine SQL, and then you can call ‘exec_sql‘ tool again via < tool_call> to check the corrected SQL and get the execution results until you get ‘pass‘
-
[67]
If ‘pass‘: return the final SQL inside ‘<answer_sql>...</answer_sql>‘. Note finally you should return the final SQL inside ‘<answer_sql>...</answer_sql> </tool_response> 30 ♂robotThought <think> Okay, let’s start by breaking down the current question and the proposed SQL. The user is asking for the population of each of those government forms. The "those"...
-
[68]
"SchemaLinking (Coherence)" Prediction chooses the wrong **tables/columns** relative to previously grounded schema. Prior turns established certain tables (T_prev) or salient columns (C_prev) as the focus; the current SQL omits or swaps them despite **continuation cues** (“also”, “those”, “same”, “among those”, “ of the above”). (Note: edges/joins belong ...
-
[69]
"JoinPath (Coherence)" The conversation already established a **relationship chain** (edges/bridge tables/keys). The prediction uses a different/missing bridge or wrong join keys, changing which entities are selected. (Nodes/tables match prior focus, but edges/joins differ.)
-
[70]
"AggregationDrift (Coherence)" Prior turns established an aggregated/ranked/windowed view (GROUP BY, HAVING, ORDER BY, window functions). 31 The prediction **drops or mutates** that context under continuation cues (“those top teams”, “ highest average”). This includes loss/change of GROUP BY / HAVING / ORDER / LIMIT / window that was salient previously
-
[71]
ConstraintCoherence (Coherence)
"ConstraintCoherence (Coherence)" Any **constraint/value/scope** incoherence vs prior turns, including: - Dropped constraints (under-carry): previously applied filters (e.g., year > 2015, city = ’ Boston’) vanish under continuation. - Over-carry (unwarranted carry): previous filters are kept despite a reset cue (“now overall”, “regardless”). - Result-set ...
work page 2015
-
[72]
### TIE-BREAK RULES (apply top-down; prefer coherence categories before "Others")
"Others" Use when: (a) the prediction is correct; (b) the error is not plausibly due to cross-turn incoherence; or (c) information is insufficient to attribute the error to (1) to (4). ### TIE-BREAK RULES (apply top-down; prefer coherence categories before "Others")
-
[73]
If the table/column set is wrong vs prior-grounded context→"SchemaLinking (Coherence)"
-
[74]
Else if tables are right but relationship edges/bridge/keys diverge→"JoinPath (Coherence)"
-
[75]
Else if aggregated/ranked/window context from prior is lost/mutated→"AggregationDrift ( Coherence)"
-
[76]
ConstraintCoherence (Coherence)
Else if constraint/value/scope coherence is broken→"ConstraintCoherence (Coherence)"
-
[77]
Others". ### OUTPUT FORMAT (valid JSON only) {{
Else→"Others". ### OUTPUT FORMAT (valid JSON only) {{ "category": "one of: {’, ’.join(CATEGORIES)}", "rationale": "2 to 4 sentences citing cross-turn evidence for the chosen category.", "cross_turn_signals": ["brief bullets of evidence"], "confidence": 0.0 }} Keep the rationale concise and evidence-driven. No extra text outside the JSON. """ 32
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.