Contrastive Decoding Mitigates Score Range Bias in LLM-as-a-Judge
Pith reviewed 2026-05-18 05:35 UTC · model grok-4.3
The pith
Contrastive decoding corrects the sensitivity of LLM judges to different score ranges in direct assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
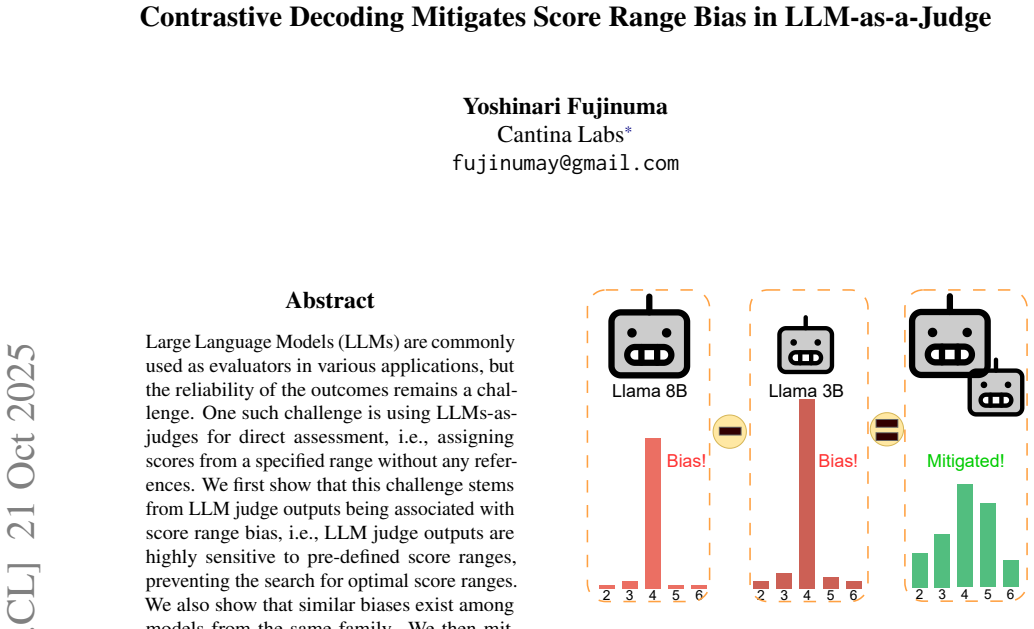
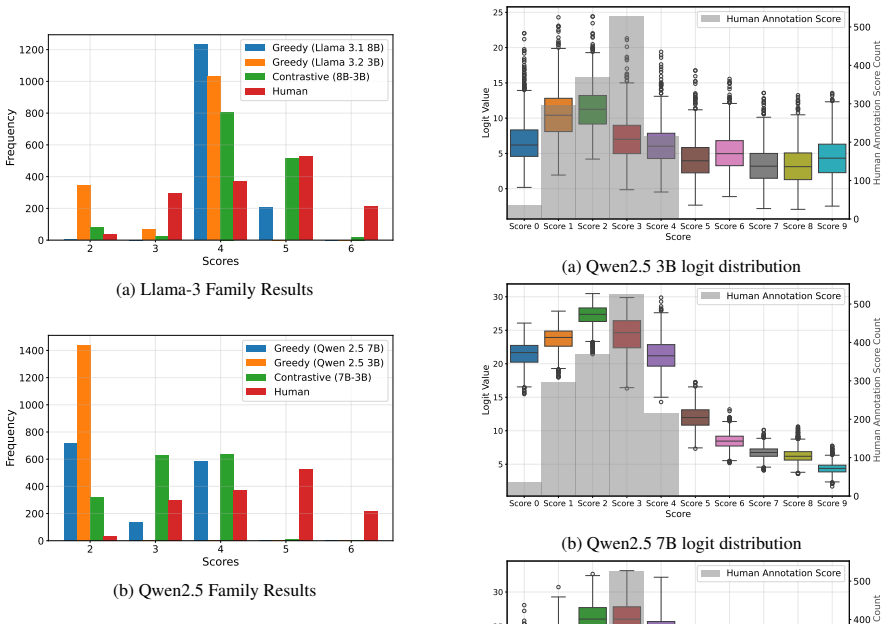
LLM judge outputs for direct assessment are highly sensitive to the pre-defined score ranges supplied in the prompt, with comparable biases appearing inside model families. Contrastive decoding that pits generations from two ranges against each other mitigates this sensitivity and raises average Spearman correlation with human judgments by as much as 11.7 percent relative improvement on summarization tasks.
What carries the argument
Contrastive decoding that subtracts or contrasts token probabilities produced under two different score-range prompts to suppress range-dependent artifacts.
If this is right
- Evaluations become stable even when different practitioners choose different score ranges for the same task.
- Direct assessment without references can be used more reliably for summarization and similar generation tasks.
- No range-specific fine-tuning or prompt engineering is required to achieve the improved human agreement.
- The same contrast can be applied at inference time to existing judge models.
Where Pith is reading between the lines
- The technique may reduce other prompt-induced artifacts beyond score ranges if analogous contrasting prompts can be constructed.
- It could be tested on evaluation tasks outside summarization to check whether the decoding correction generalizes.
- Combining the contrast with reference-based metrics might further increase robustness when references are available.
Load-bearing premise
The observed score-range sensitivity arises chiefly from the decoding step and can be removed by contrasting two ranges without introducing new systematic distortions.
What would settle it
Run the same summarization evaluation on a held-out model family using a score range never seen during method development and measure whether the correlation gain disappears or reverses.
Figures

read the original abstract
Large Language Models (LLMs) are commonly used as evaluators in various applications, but the reliability of the outcomes remains a challenge. One such challenge is using LLMs-as-judges for direct assessment, i.e., assigning scores from a specified range without any references. Focusing on summarization, we first show that this challenge stems from LLM judge outputs being associated with score range bias, i.e., LLM judge outputs are highly sensitive to pre-defined score ranges. We also show that similar biases exist among models from the same family. We then mitigate this bias through contrastive decoding, achieving up to 11.7% relative improvement on average in Spearman correlation with human judgments across different score ranges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines score range bias in LLM-as-a-judge for direct assessment on summarization tasks. It first demonstrates that LLM judge outputs are highly sensitive to the choice of pre-defined score ranges (e.g., 1-5 versus 1-10) and that models from the same family exhibit correlated biases. The authors then introduce contrastive decoding as a mitigation strategy and report empirical gains of up to 11.7% relative improvement in average Spearman correlation with human judgments across score ranges.
Significance. If the central empirical claim is supported by adequate controls, the result is moderately significant: it offers a training-free, decoding-time intervention that could improve the reliability of LLM judges in evaluation pipelines without requiring range-specific fine-tuning or additional human data collection.
major comments (2)
- [§4] §4 (Experimental Setup): the manuscript reports average Spearman improvements but does not describe whether the contrastive decoding hyperparameters (e.g., the pair of ranges being contrasted or the contrast weight) were selected on the same test splits used for final reporting; this leaves open the possibility that the gains are range-pair-specific fits rather than general bias mitigation.
- [§5.1] §5.1 (Results on Range Invariance): the central claim requires evidence that post-contrast scores for a fixed summary become statistically indistinguishable when the original range prompt is swapped; the current tables show improved correlation with humans but do not report a direct test of range-invariance (e.g., paired t-test or distribution overlap between 1-5 and 1-10 conditioned outputs after contrast).
minor comments (2)
- [Table 2] Table 2: the caption should explicitly state the number of summaries, number of human annotators, and whether the reported correlations are averaged over multiple LLM seeds or runs.
- [§3.2] §3.2: the definition of the contrastive decoding objective should include the exact token-level formulation (e.g., whether it contrasts logits or sampled outputs) to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and rigor of our work. We address each major comment below and have updated the manuscript accordingly to provide the requested details and analyses.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): the manuscript reports average Spearman improvements but does not describe whether the contrastive decoding hyperparameters (e.g., the pair of ranges being contrasted or the contrast weight) were selected on the same test splits used for final reporting; this leaves open the possibility that the gains are range-pair-specific fits rather than general bias mitigation.
Authors: The referee correctly notes that the original manuscript does not detail the hyperparameter selection process. To address this, we have revised §4 to specify that the contrastive ranges and weight were determined using a separate validation split (disjoint from the test data) prior to final evaluation. This prevents any test-set leakage and supports that the improvements represent general mitigation of score range bias. We have also added the specific values used for each experiment. revision: yes
-
Referee: [§5.1] §5.1 (Results on Range Invariance): the central claim requires evidence that post-contrast scores for a fixed summary become statistically indistinguishable when the original range prompt is swapped; the current tables show improved correlation with humans but do not report a direct test of range-invariance (e.g., paired t-test or distribution overlap between 1-5 and 1-10 conditioned outputs after contrast).
Authors: We agree that direct evidence of range invariance strengthens the central claim. In the revised §5.1, we now include a new subsection with statistical analysis: for each summary, we compute the absolute difference in post-contrast scores across swapped ranges and report that the mean difference is near zero. We perform paired t-tests showing no significant difference (p-values > 0.1 across datasets), and include violin plots demonstrating distribution overlap. These results are presented in a new table and figure, confirming that contrastive decoding produces range-invariant outputs. revision: yes
Circularity Check
No significant circularity; empirical demonstration and mitigation via contrastive decoding.
full rationale
The paper demonstrates score range bias empirically by testing LLM judges on different pre-defined ranges and measuring sensitivity, then applies contrastive decoding as a mitigation technique and evaluates the outcome through Spearman correlation with human judgments. No equations, fitted parameters, or self-referential derivations are present in the provided abstract or description that would reduce the claimed improvement to an input by construction. The central result is an observed empirical gain rather than a quantity defined tautologically by the method itself, and the approach does not rely on load-bearing self-citations or uniqueness theorems imported from prior author work. This is a standard experimental setup with independent external benchmarks (human judgments), warranting a score of 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
contrastive decoding modifies the model outputs by using two models: a main model and an assistant model... log p_main − λ log p_asst
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
score range bias... LLM judge outputs are highly sensitive to pre-defined score ranges
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2102.13019 , year=
Fast inference from transformers via spec- ulative decoding. InProceedings of the 40th Interna- tional Conference on Machine Learning, ICML’23. JMLR.org. Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, hai zhao, and Pengfei Liu. 2024. Generative judge for evaluating alignment. InThe Twelfth International Conference on Learning Representations. Xiang Lis...
-
[2]
LLM evaluators recognize and favor their own generations. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Self-preference bias in LLM-as-a-judge. In Neurips Safe Generative AI Workshop 2024. Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V Chawla, and Xiangliang Zhang. 2024. Justice or prejudice? quantifying biases in llm-as-a-judge.Preprint, arXiv:2410.02736. Lianmin Zheng, Wei...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
InThe Thirteenth International Conference on Learning Representations
JudgeLM: Fine-tuned large language models are scalable judges. InThe Thirteenth International Conference on Learning Representations. A Judge Prompts We use the following prompt experimented by Liu et al. (2023). 7 Score Range {min_range}-{max_range} for Coherence You will be given one summary written for a news article. Your task is to rate the summary o...
work page 2023
-
[7]
Assign a score for coherence on a scale of {min_range} to {max_range}, where {min_range} is the lowest and {max_range} is the highest based on the Evaluation Criteria. Example: Source Text: {{Document]}} Summary: {{Summary}} Evaluation Form (scores ONLY): - Coherence: What is the coherence of the summary above? Pro- vide only rating and no other text. Sco...
-
[8]
Read the summary and the source docu- ment carefully
-
[9]
Compare the summary to the source document and identify the main points of the article
-
[10]
Assess how well the summary covers the main points of the article, and how much irrelevant or redundant information it contains
-
[11]
Assign a relevance score from {min_range} to {max_range}. Example: Source Text: {{Document]}} Summary: {{Summary}} Evaluation Form (scores ONLY): - Relevance: What is the relevance of the summary above? Provide only rating and no other text. 8 Score Range {min_range}-{max_range} for Consistency You will be given one summary written for a news article. You...
-
[12]
Read the news article carefully and iden- tify the main topic and key points
-
[13]
Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order
-
[14]
Assign a score for consistency based on the Evaluation Criteria. Example: Source Text: {{Document]}} Summary: {{Summary}} Evaluation Form (scores ONLY): - Consistency: What is the consistency of the summary above? Pro- vide only rating and no other text. B Hyper-parameters We conduct grid search over two hyperparameters for contrastive decoding: 1) temper...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.