The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination
Pith reviewed 2026-05-18 04:06 UTC · model grok-4.3
The pith
Enhancing LLM reasoning through RL causally increases tool hallucination in proportion to performance gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
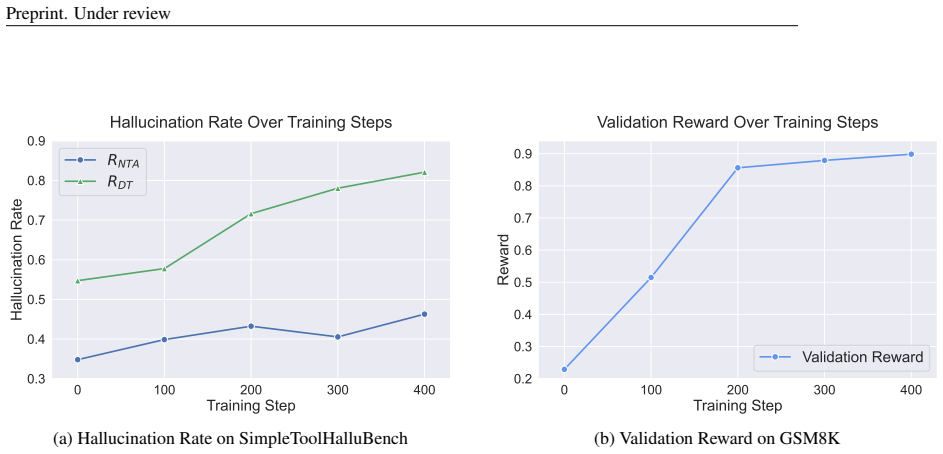
Progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains. This effect transcends overfitting because training on non-tool tasks such as mathematics still amplifies later tool hallucination. The same rise occurs when reasoning is instilled by supervised fine-tuning and when it is only elicited at inference by switching from direct answers to step-by-step thinking. Mechanistically, reasoning RL disproportionately collapses tool-reliability-related representations, and hallucinations surface as amplified divergences concentrated in late-layer residual streams.
What carries the argument
SimpleToolHalluBench, a diagnostic benchmark that measures tool hallucination in two controlled failure modes: no tool available and only distractor tools available.
If this is right
- Training on mathematics tasks still amplifies subsequent tool hallucination on the benchmark.
- Eliciting step-by-step thinking at inference time raises tool hallucination even without additional training.
- Mitigation methods such as prompt engineering or DPO reduce hallucination but also degrade task utility.
- Reasoning enhancement methods inherently amplify tool hallucination rather than improving capability alone.
Where Pith is reading between the lines
- Future agent systems may need separate modules for reasoning and tool selection to avoid the amplification effect.
- The reliability-capability trade-off could appear in other reliability problems such as factual hallucination when reasoning is strengthened.
- Training objectives that jointly optimize task performance and tool-use accuracy would be a direct response to the observed collapse of reliability representations.
Load-bearing premise
The benchmark's two failure modes isolate tool hallucination without confounding effects from task difficulty or prompt formatting that could independently drive both reasoning gains and hallucination rates.
What would settle it
If RL training that improves performance on non-tool tasks such as mathematics produces no rise in hallucination rates when models are later tested on SimpleToolHalluBench, the claimed causal relationship would be falsified.
Figures




read the original abstract
Enhancing the reasoning capabilities of Large Language Models (LLMs) is a key strategy for building Agents that "think then act." However, recent observations, like OpenAI's o3, suggest a paradox: stronger reasoning often coincides with increased hallucination, yet no prior work has systematically examined whether reasoning enhancement itself causes tool hallucination. To address this gap, we pose the central question: Does strengthening reasoning increase tool hallucination? To answer this, we introduce SimpleToolHalluBench, a diagnostic benchmark measuring tool hallucination in two failure modes: (i) no tool available, and (ii) only distractor tools available. Through controlled experiments, we establish three key findings. First, we demonstrate a causal relationship: progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains. Second, this effect transcends overfitting - training on non-tool tasks (e.g., mathematics) still amplifies subsequent tool hallucination. Third, the effect is method-agnostic, appearing when reasoning is instilled via supervised fine-tuning and when it is merely elicited at inference by switching from direct answers to step-by-step thinking. We also evaluate mitigation strategies including Prompt Engineering and Direct Preference Optimization (DPO), revealing a fundamental reliability-capability trade-off: reducing hallucination consistently degrades utility. Mechanistically, Reasoning RL disproportionately collapses tool-reliability-related representations, and hallucinations surface as amplified divergences concentrated in late-layer residual streams. These findings reveal that current reasoning enhancement methods inherently amplify tool hallucination, highlighting the need for new training objectives that jointly optimize for capability and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether enhancing reasoning capabilities in LLMs causes increased tool hallucination. It introduces SimpleToolHalluBench, a diagnostic benchmark with two failure modes (no tool available; only distractor tools available). Through controlled experiments, the authors report three findings: (1) progressively enhancing reasoning via RL increases tool hallucination proportionally with task performance gains; (2) the effect persists even when training on non-tool tasks such as mathematics; (3) the effect appears under both SFT and inference-time step-by-step prompting. Mitigation experiments with prompt engineering and DPO reveal a reliability-capability trade-off, and mechanistic analysis indicates that reasoning RL collapses tool-reliability representations, with hallucinations appearing as amplified divergences in late-layer residual streams.
Significance. If the central causal claim holds after addressing potential confounds, the work is significant for highlighting an inherent trade-off in current reasoning-enhancement techniques that could affect reliable agent development. Strengths include the new diagnostic benchmark, experiments across multiple enhancement methods (RL, SFT, inference-time), and the mechanistic investigation of representation collapse. These elements provide empirical grounding and falsifiable predictions about the proportionality of hallucination increases with capability gains.
major comments (2)
- [SimpleToolHalluBench and experimental controls] The two failure modes in SimpleToolHalluBench may not isolate pure tool hallucination. Stronger reasoning could independently increase output length, number of reasoning steps, or tool-seeking attempts, raising the chance of naming non-existent or distractor tools. The RL and SFT controls do not hold output length or reasoning depth constant across conditions, which risks confounding the reported proportional increase with task performance (see experimental setup and results on RL training).
- [Abstract and Results sections] The abstract and results do not report statistical significance tests, error bars on hallucination rates, or how task performance gains were measured independently of hallucination counts. This weakens support for the proportionality claim and the three key findings.
minor comments (2)
- [Mechanistic analysis] The mechanistic analysis of late-layer residual streams would benefit from additional figures showing the divergence metrics across layers for different reasoning levels.
- [Experimental details] Clarify the exact models, dataset sizes, and number of runs used in the RL and SFT experiments to improve reproducibility.
Simulated Author's Rebuttal
Thank you for your insightful comments on our work. We respond to each major comment below and indicate the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [SimpleToolHalluBench and experimental controls] The two failure modes in SimpleToolHalluBench may not isolate pure tool hallucination. Stronger reasoning could independently increase output length, number of reasoning steps, or tool-seeking attempts, raising the chance of naming non-existent or distractor tools. The RL and SFT controls do not hold output length or reasoning depth constant across conditions, which risks confounding the reported proportional increase with task performance (see experimental setup and results on RL training).
Authors: We thank the referee for highlighting this potential confound. While stronger reasoning may lead to longer outputs, our benchmark specifically measures tool hallucination as the rate of calling unavailable or distractor tools in the defined failure modes. To address the concern about not holding length and depth constant, we will include additional experiments in the revision that normalize for these factors, such as by length-matching responses or analyzing subsets with similar reasoning steps. We will report whether the proportional relationship holds under these controls. revision: yes
-
Referee: [Abstract and Results sections] The abstract and results do not report statistical significance tests, error bars on hallucination rates, or how task performance gains were measured independently of hallucination counts. This weakens support for the proportionality claim and the three key findings.
Authors: We agree with the referee that reporting statistical significance, error bars, and clear measurement details will improve the manuscript. Task performance gains are measured via success rates on tasks where tools are available and correctly usable, separate from the hallucination rates in the no-tool or distractor-only scenarios. In the revised version, we will add error bars to all reported rates, include statistical tests (e.g., correlation significance for the proportionality), and clarify these metrics in the abstract and results sections. revision: yes
Circularity Check
No circularity: empirical claims rest on new benchmark and controlled experiments
full rationale
The paper introduces SimpleToolHalluBench and reports results from RL/SFT training runs plus inference-time elicitation. Central findings (proportional increase in hallucination with reasoning gains, method-agnostic effect, reliability-capability trade-off) are presented as outcomes of these experiments rather than any derivation, equation, or parameter fit that reduces to the same data by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described methodology. The work is self-contained against external benchmarks via the new diagnostic benchmark and explicit controls.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tool hallucination can be measured by explicit failure modes in a controlled benchmark without confounding from general capability or prompt sensitivity.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
late-layer residual streams... amplified divergences
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mingyang Chen, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z Pan, Wen Zhang, Huajun Chen, Fan Yang, et al. Learning to reason with search for llms via reinforcement learning.arXiv preprint arXiv:2503.19470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URLhttps://transformer-circuits.pub/2021/framework/index.html. Chujie Gao, Siyuan Wu, Yue Huang, Dongping Chen, Qihui Zhang, Zhengyan Fu, Yao Wan, Lichao Sun, and Xian- gliang Zhang. Honestllm: Toward an honest and helpful large language model.arXiv preprint arXiv:2406.00380,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A survey on the honesty of large language models.arXiv preprint arXiv:2409.18786,
Siheng Li, Cheng Yang, Taiqiang Wu, Chufan Shi, Yuji Zhang, Xinyu Zhu, Zesen Cheng, Deng Cai, Mo Yu, Lemao Liu, et al. A survey on the honesty of large language models.arXiv preprint arXiv:2409.18786,
-
[7]
Torl: Scaling tool-integrated rl, 2025
Xuefeng Li, Haoyang Zou, and Pengfei Liu. Torl: Scaling tool-integrated rl.arXiv preprint arXiv:2503.23383,
-
[8]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T ¨ur, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Zeyang Sha, Shiwen Cui, and Weiqiang Wang. SEM: reinforcement learning for search-efficient large language models.arXiv preprint arXiv:2505.07903, 2025a. Zeyang Sha, Hanling Tian, Zhuoer Xu, Shiwen Cui, Changhua Meng, and Weiqiang Wang. Agent safety alignment via reinforcement learning.arXiv preprint arXiv:2507.08270, 2025b. Zhihong Shao, Peiyi Wang, Qiha...
-
[10]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
10 Preprint. Under review Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Hongru Wang, Cheng Qian, Wanjun Zhong, Xiusi Chen, Jiahao Qiu, Shijue Huang, Bowen Jin, Mengdi Wang, Kam- Fai Wong, and Heng Ji. Otc: Optimal tool calls via reinforcement learning.arXiv e-prints, pp. arXiv–2504, 2025a. Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al....
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Reducing tool hallucination via reliability alignment.arXiv preprint arXiv:2412.04141,
Hongshen Xu, Zichen Zhu, Lei Pan, Zihan Wang, Su Zhu, Da Ma, Ruisheng Cao, Lu Chen, and Kai Yu. Reducing tool hallucination via reliability alignment.arXiv preprint arXiv:2412.04141,
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Yuxiang Zhang, Jing Chen, Junjie Wang, Yaxin Liu, Cheng Yang, Chufan Shi, Xinyu Zhu, Zihao Lin, Hanwen Wan, Yujiu Yang, et al. Toolbehonest: A multi-level hallucination diagnostic benchmark for tool-augmented large lan- guage models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 11388–11422, 2024a. Zhexin Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
A DETAILS ANDEXAMPLES OF THESIMPLETOOLHALLUBENCH A.1 THEDETAILS OF THECONSTRUCTION OFSimpleToolHalluBench. We construct the benchmark as follows: We sample 296 tools whose parameters are not empty fromAgent Safety Bench(Zhang et al., 2024b). For each tool, we use ChatGPT-4o to generate a user query whose correct resolution necessarilyrequires invoking tha...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.