Generative View Stitching
Pith reviewed 2026-05-18 02:49 UTC · model grok-4.3
The pith
Generative View Stitching lets off-the-shelf video diffusion models follow any predefined camera path without collisions or drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
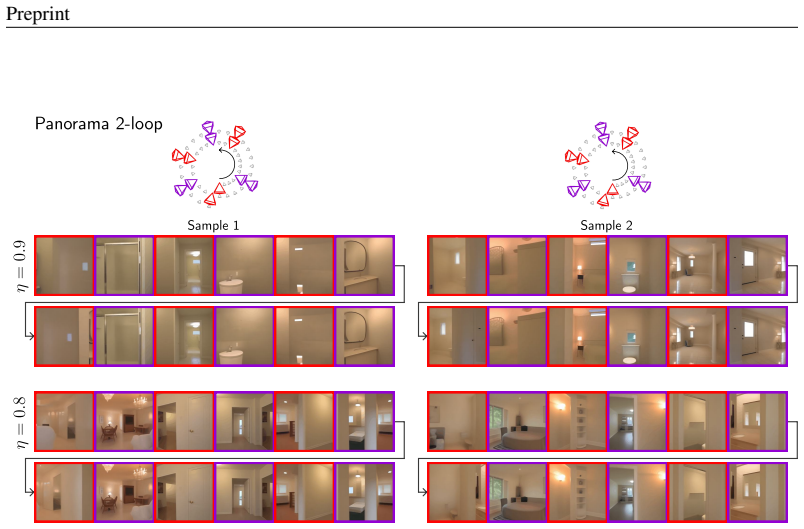
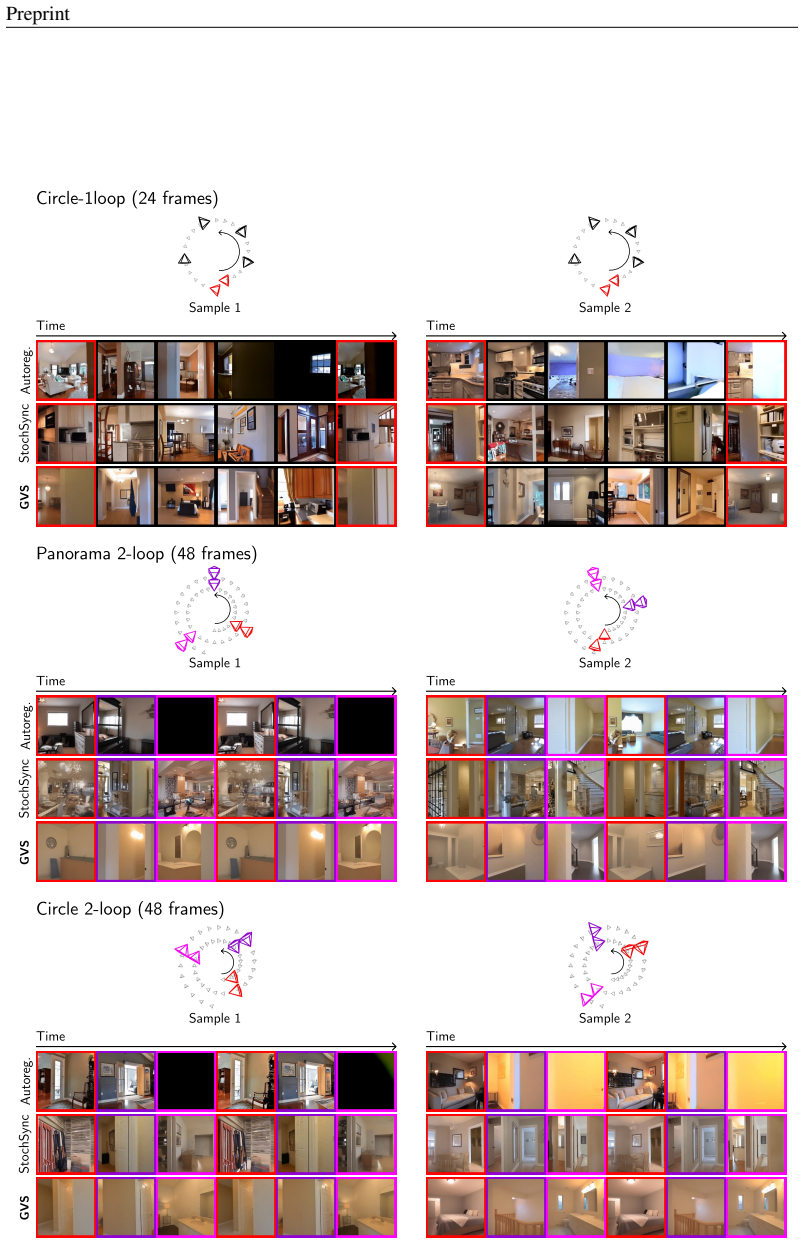
Generative View Stitching samples the entire video sequence in parallel so the generated scene remains faithful to every segment of a user-specified camera trajectory. The algorithm extends prior diffusion-stitching techniques to video generation and requires no architectural changes or retraining when applied to models trained with Diffusion Forcing. Omni Guidance further conditions each frame on both past and future context, which improves temporal consistency and supports a loop-closing mechanism that maintains coherence over long horizons.
What carries the argument
Generative View Stitching, a parallel sampling procedure that stitches latent frames across the full camera trajectory, augmented by Omni Guidance for bidirectional past-and-future conditioning.
If this is right
- Predefined camera paths of arbitrary complexity can be followed without the scene collapse typical of autoregressive rollouts.
- Loop-closing becomes feasible, delivering long-range scene coherence that autoregressive models lose after the first collision.
- Any existing video model trained with Diffusion Forcing can be used directly, removing the need for task-specific fine-tuning.
- Frame-to-frame consistency is enforced by construction through the parallel stitching schedule.
Where Pith is reading between the lines
- The same stitching schedule could be applied to other autoregressive generative domains where future constraints are known in advance.
- Omni Guidance suggests a general pattern for adding future conditioning to any diffusion-based sequence model without architectural overhaul.
- If the approach scales to higher resolutions, it could support real-time preview of camera moves inside generated environments.
Load-bearing premise
That models trained with Diffusion Forcing already contain the internal representations needed for stitching without any retraining or changes to the network.
What would settle it
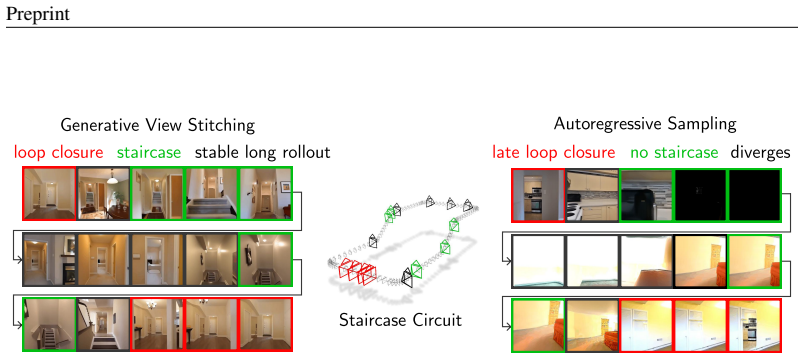
Apply Generative View Stitching to a standard off-the-shelf Diffusion Forcing video model on the Impossible Staircase trajectory and check whether the output frames remain free of collisions and maintain visual consistency when the loop is closed.
Figures













read the original abstract
Autoregressive video diffusion models are capable of long rollouts that are stable and consistent with history, but they are unable to guide the current generation with conditioning from the future. In camera-guided video generation with a predefined camera trajectory, this limitation leads to collisions with the generated scene, after which autoregression quickly collapses. To address this, we propose Generative View Stitching (GVS), which samples the entire sequence in parallel such that the generated scene is faithful to every part of the predefined camera trajectory. Our main contribution is a sampling algorithm that extends prior work on diffusion stitching for robot planning to video generation. While such stitching methods usually require a specially trained model, GVS is compatible with any off-the-shelf video model trained with Diffusion Forcing, a prevalent sequence diffusion framework that we show already provides the affordances necessary for stitching. We then introduce Omni Guidance, a technique that enhances the temporal consistency in stitching by conditioning on both the past and future, and that enables our proposed loop-closing mechanism for delivering long-range coherence. Overall, GVS achieves camera-guided video generation that is stable, collision-free, frame-to-frame consistent, and closes loops for a variety of predefined camera paths, including Oscar Reutersv\"ard's Impossible Staircase. Results are best viewed as videos at https://andrewsonga.github.io/gvs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Generative View Stitching (GVS), a sampling algorithm that generates video sequences in parallel to ensure consistency with a predefined camera trajectory. It extends prior diffusion-stitching techniques to work with any off-the-shelf video diffusion model trained under the Diffusion Forcing framework, without requiring retraining or architectural changes, and adds Omni Guidance to improve temporal consistency via bidirectional conditioning and enable loop closure on complex paths such as the Impossible Staircase.
Significance. If the central claims hold, the work offers a practical advance in controllable video generation by leveraging existing Diffusion Forcing models for stable, collision-free, and loop-closed outputs under arbitrary camera paths. This could reduce the need for specialized training in applications like robotics simulation and immersive content creation, with the no-retraining compatibility representing a notable strength if supported by the experiments.
major comments (2)
- [Abstract and §3] Abstract and §3: The load-bearing claim that standard Diffusion Forcing models already supply the necessary affordances (future-frame conditioning and noise-schedule properties) for stitching without any retraining or modifications requires explicit verification. The manuscript should include a direct ablation or comparison demonstrating that unmodified DF rollouts support the parallel sampling and loop-closing behavior on paths like the Impossible Staircase; otherwise the extension from prior stitching work that typically needs specially trained models remains unproven.
- [§4.2] §4.2 (Omni Guidance): The description of bidirectional conditioning for temporal consistency and loop closure should specify the exact conditioning mechanism and noise schedule adjustments used during parallel sampling; without this, it is unclear whether the reported collision-free results rely on undisclosed model-specific tweaks.
minor comments (2)
- [Figures and Experiments] Figure captions and video links: Ensure all qualitative results include quantitative metrics (e.g., collision rate, consistency scores) alongside the visual examples for the Impossible Staircase and other paths.
- [Method] Notation: Define the precise form of the stitching loss or guidance term when extending diffusion stitching to video; the current description leaves the mathematical relationship to standard DF sampling implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of Generative View Stitching for controllable video generation. We address each major comment below with point-by-point responses and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The load-bearing claim that standard Diffusion Forcing models already supply the necessary affordances (future-frame conditioning and noise-schedule properties) for stitching without any retraining or modifications requires explicit verification. The manuscript should include a direct ablation or comparison demonstrating that unmodified DF rollouts support the parallel sampling and loop-closing behavior on paths like the Impossible Staircase; otherwise the extension from prior stitching work that typically needs specially trained models remains unproven.
Authors: We appreciate the referee's request for stronger empirical grounding of this central claim. Section 3 of the manuscript already explains that Diffusion Forcing training produces per-frame noise schedules and supports conditioning on both past and future frames within the same rollout, which directly enables the parallel stitching procedure without architectural changes. To provide the requested explicit verification, we will add a new ablation subsection (Section 4.3) in the revised manuscript. This ablation will compare unmodified DF autoregressive rollouts against our parallel GVS sampling on the Impossible Staircase trajectory, demonstrating that the DF affordances suffice for collision-free loop closure while standard autoregression collapses. We believe this addition will clearly distinguish GVS from prior stitching methods that require specialized training. revision: yes
-
Referee: [§4.2] §4.2 (Omni Guidance): The description of bidirectional conditioning for temporal consistency and loop closure should specify the exact conditioning mechanism and noise schedule adjustments used during parallel sampling; without this, it is unclear whether the reported collision-free results rely on undisclosed model-specific tweaks.
Authors: We agree that greater specificity is needed for reproducibility. In the revised Section 4.2 we will expand the description of Omni Guidance to state the exact mechanism: during parallel sampling, each frame's noisy latent is concatenated with the noisy latents of both preceding and succeeding frames in the input context, and a uniform noise level is applied across the entire sequence (rather than the per-frame schedule used in standard DF inference). This bidirectional conditioning is implemented via the standard Diffusion Forcing forward pass with no additional model-specific modifications or retraining. We will also include pseudocode for the sampling loop to make the procedure fully transparent. revision: yes
Circularity Check
No significant circularity; algorithmic extension is self-contained
full rationale
The paper's core contribution is a sampling algorithm extending prior diffusion-stitching methods to video generation. It claims compatibility with off-the-shelf Diffusion Forcing models by demonstrating that the framework supplies the required conditioning affordances for parallel sampling and loop closure, without retraining or architectural changes. This is presented as an empirical and algorithmic observation rather than a self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations or steps in the provided abstract reduce the result to its inputs by construction; the derivation remains independent of the target outcomes and relies on external model properties shown through application.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GVS is a training-free stitching approach... compatible with any off-the-shelf video model trained with Diffusion Forcing... Omni Guidance... cyclic conditioning
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
8-frame context window... period-8 periodic micro-structure absent
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mixture of contexts for long video generation
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, et al. Mixture of contexts for long video generation. arXiv preprint arXiv:2508.21058,
-
[2]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, and Yahui Zhou. Skyreels-v2: Infinite-length film generative model...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URLhttps://oasis-model.github.io/. Ian Failes. The big effects moments in the one-shot ’1917’. https://beforesandafters. com/2020/01/17/the-big-effects-moments-in-the-one-shot-1917/ ,
work page 1917
-
[4]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
11 Preprint Sand.ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, W. Q. Zhang, Weifeng Luo, Xiaoyang Kang, Yuchen Sun, Yue Cao, Yunpeng Huang, Yutong Lin, Yuxin Fang, Zewei Tao, Zheng Zhang, Zhongshu Wang, Zixun Liu, Dai Shi, Guoli Su, Hanwen Sun, Hong Pan, Jie Wang, Jiexin Sheng, Min Cui, Min Hu, Ming Y...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Wan: Open and Advanced Large-Scale Video Generative Models
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021b. Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T. Freeman, and Hao Tan. Test-time training done right.arXiv preprint arXiv:2505.23884,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
13 Preprint A EXPERIMENTALDETAILS Algorithm 1:Camera-guided Video Generation with GVS Inputs:camerasp; context windows{w n}N−1 n=0 each specified byT target chunk + 2T overlap timesteps Outputs:z: video sample of lengthTaligned withp FunctionGVS(p,{w n}N−1 n=0 ): z∼ N(0,I)▷Initialize video sample with pure-noise sequence W ← {} fort= 0, . . . , T−1do forn...
work page 2018
-
[12]
that accepts 8×256×256 video inputs. All conditioning signalsi.e., per-frame noise levels and camera poses, are injected into the model via Adaptive LayerNorm. Importantly, camera conditioning is injected by first computingrelativeposes with respect to the first frame and then transforming them into high-dimensional ray encodings. Sampling. For history-gu...
work page 2025
-
[13]
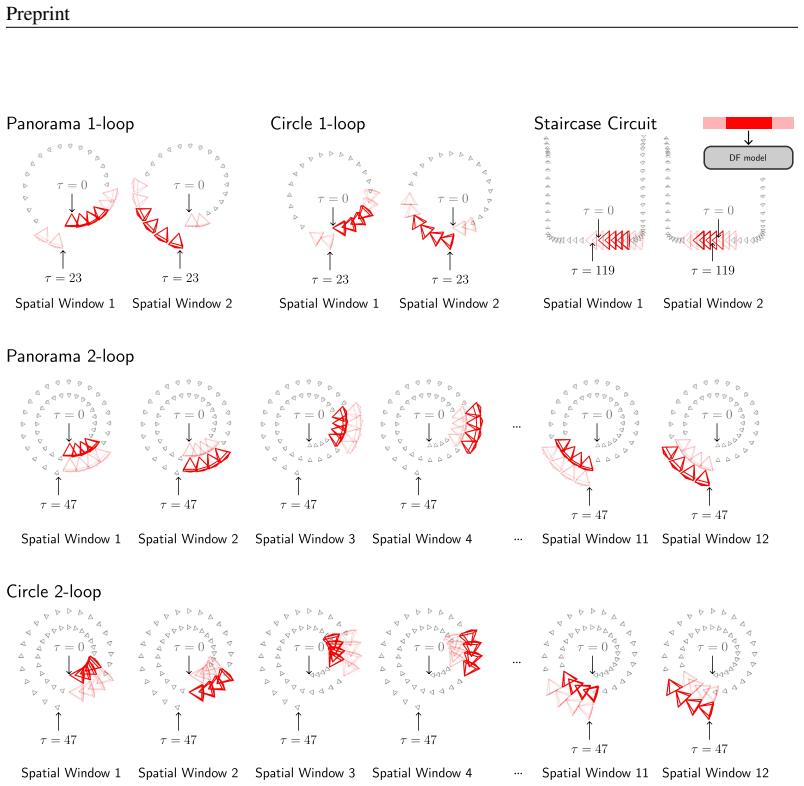
In other words, each 8-frame-long context window is comprised of 2 frames from the past chunk, the target chunk, and 2 frames from the future chunk. We visualize this in Fig. 2 but with half the context window size. Loop-Closing Mechanism. For conditioning camera trajectories that require loop-closing i.e., Panorama 1-loop , Panorama 2-loop , Circle 1-loo...
work page 2025
-
[14]
and ScanNet++ (Yeshwanth et al., 2023), which is another promising direction for future work. C.3 STRUCTURALLYSIMILARCAMERATRAJECTORYSEGMENTS In some corner cases, GVS struggles to distinguish camera trajectory segments with similar structure. This is due to the limited context of the Diffusion-Forcing backbone and its use ofrelativeposes for camera condi...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.