Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Pith reviewed 2026-05-18 03:12 UTC · model grok-4.3
The pith
Multilingual reasoning gaps in language models stem mainly from failures to translate inputs into English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
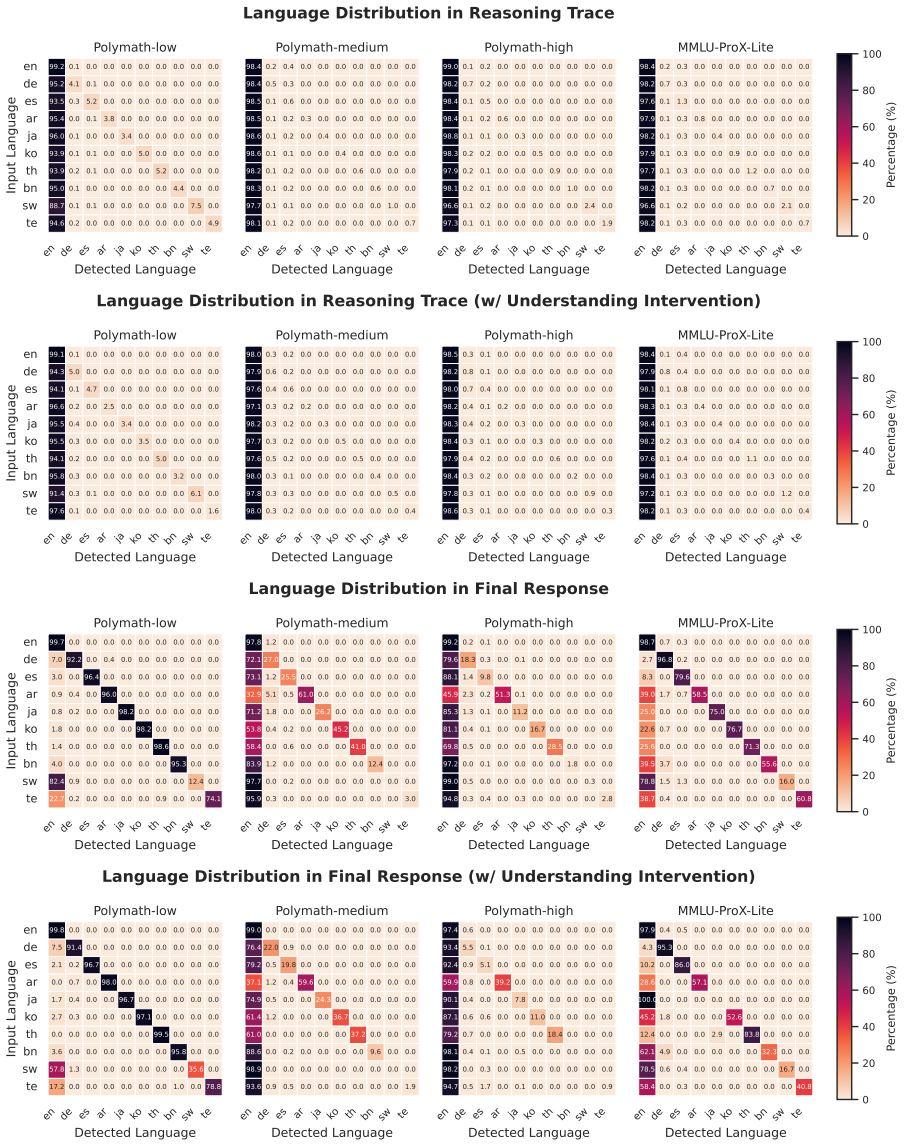
The multilingual reasoning gap primarily stems from failures in language understanding—specifically, the model's inability to translate multilingual inputs into the language dominating its reasoning traces, typically English. Understanding failures are detectable to a meaningful extent, with supervised approaches working best. Selective Translation bridges the gap by incorporating an English translation into the initial reasoning trace only when an understanding failure is detected, achieving near full-translation performance while translating only about 20% of inputs.
What carries the argument
Selective Translation, a strategy that detects understanding failures and adds an English translation to the reasoning trace only for affected inputs.
If this is right
- Focusing mitigation on input understanding allows most of the multilingual gap to close without translating every case.
- Detection of understanding failures supports efficient, targeted fixes instead of blanket translation.
- Supervised detection outperforms other methods for spotting when selective translation is needed.
- The approach preserves nearly all benefits of full translation at much lower translation volume.
Where Pith is reading between the lines
- Similar selective detection could address other multilingual issues such as uneven cultural knowledge across languages.
- Strengthening core language understanding in the base model might reduce the frequency of needed translations over time.
- Checking whether the low translation rate holds on larger models would test how the method scales.
Load-bearing premise
That performance differences are driven by language understanding failures rather than deficits in reasoning capability once the input is understood or by gaps in cultural or domain knowledge.
What would settle it
If performance in low-resource languages stays lower even after all inputs receive accurate English translations before reasoning begins, the claim that understanding failures are the main cause would be weakened.
Figures
















read the original abstract
Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still exhibit a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have been made to address this gap, its underlying causes remain largely unexplored. In this work, we show that this gap primarily stems from failures in language understanding-specifically, the model's inability to translate multilingual inputs into the language dominating its reasoning traces (typically English). As identifying understanding failures can enable targeted mitigation of the gap, we evaluate a range of detection methods and find that understanding failures are detectable to a meaningful extent, with supervised approaches performing best. Building on this, we propose Selective Translation, a strategy that incorporates an English translation into the initial reasoning trace only when an understanding failure is detected. Experimental results using Qwen3-4B show that Selective Translation substantially bridges the multilingual reasoning gap, achieving near full-translation performance while translating only about 20% of inputs. Together, our results show that failures in language understanding are the primary driver of the multilingual reasoning gap and can be detected and selectively mitigated, clarifying its origin and suggesting a path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the multilingual reasoning gap in reasoning language models (RLMs), claiming it primarily stems from failures in language understanding—specifically, the inability to translate non-English inputs into the model's dominant reasoning language (typically English). The authors evaluate detection methods for these failures (supervised approaches perform best), and introduce Selective Translation, which adds an English translation to the reasoning trace only upon detected failure. Experiments on Qwen3-4B show this closes most of the gap while translating only ~20% of inputs, with code and data released publicly.
Significance. If the results hold, the work provides a mechanistic explanation for multilingual gaps in RLMs and a practical, low-overhead mitigation strategy. It suggests understanding and reasoning can be partially decoupled in these models and offers a path to more equitable performance. The public code and data release is a clear strength for reproducibility.
major comments (2)
- Abstract and experimental results: The central claim that the gap 'primarily stems from failures in language understanding' and that selective translation reaches 'near full-translation performance' requires explicit evidence that translated low-resource inputs yield reasoning performance equivalent to high-resource cases. Without controls for domain/cultural knowledge gaps or weaker internal representations that persist after surface translation, the attribution to understanding failures alone is not fully isolated.
- Detection methods section: Supervised detection is reported as best, but the manuscript must clarify how 'understanding failure' labels are constructed (e.g., whether they derive from downstream performance on the same tasks). If labels correlate with overall difficulty rather than language-specific comprehension, this risks circularity when using detection to explain performance gaps.
minor comments (1)
- The abstract and methods would benefit from specifying the exact languages tested, dataset sizes, and statistical tests (with confidence intervals) supporting the 'substantially bridges' and 'near full-translation' claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We address each major comment below in a point-by-point manner, indicating where we will make revisions to strengthen the paper.
read point-by-point responses
-
Referee: Abstract and experimental results: The central claim that the gap 'primarily stems from failures in language understanding' and that selective translation reaches 'near full-translation performance' requires explicit evidence that translated low-resource inputs yield reasoning performance equivalent to high-resource cases. Without controls for domain/cultural knowledge gaps or weaker internal representations that persist after surface translation, the attribution to understanding failures alone is not fully isolated.
Authors: We appreciate the referee's emphasis on isolating the causal factors. Our experiments demonstrate that full translation of low-resource inputs to English yields performance levels approaching those observed on high-resource languages for the same tasks, as reflected in the near full-translation results. To further support the attribution to understanding failures, our evaluations focus on reasoning benchmarks such as mathematical and logical problems, which minimize cultural and domain-specific knowledge dependencies. We acknowledge that surface translation may not address all potential internal representation issues. In the revised manuscript, we will add explicit comparisons of translated low-resource performance against high-resource baselines, along with a discussion of these potential confounds and any supporting analyses. revision: partial
-
Referee: Detection methods section: Supervised detection is reported as best, but the manuscript must clarify how 'understanding failure' labels are constructed (e.g., whether they derive from downstream performance on the same tasks). If labels correlate with overall difficulty rather than language-specific comprehension, this risks circularity when using detection to explain performance gaps.
Authors: We agree that explicit clarification of the labeling process is essential to address concerns about circularity. The understanding failure labels are derived from a proxy comparison of model behavior on the same queries presented in English (where comprehension is assumed successful due to the model's dominant reasoning language) versus the original language, using a held-out set of examples distinct from the primary evaluation tasks. This construction targets language-specific comprehension rather than overall task difficulty. We will revise the detection methods section to include a detailed description of the labeling procedure, including steps taken to ensure independence from downstream performance metrics and to mitigate correlation with general difficulty. revision: yes
Circularity Check
No significant circularity; empirical claims rest on new experiments
full rationale
The paper derives its central claim—that multilingual reasoning gaps primarily arise from language understanding failures (inability to internally translate inputs to English)—through direct empirical evaluations of detection methods and the Selective Translation intervention on Qwen3-4B. These results are obtained from observable performance metrics and mitigation outcomes rather than any self-definitional equations, fitted parameters presented as predictions, or load-bearing self-citations. The derivation chain is self-contained against external benchmarks, with the proposed strategy's effectiveness measured independently via translation ratios and gap closure, without reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning traces in RLMs are dominated by English
Reference graph
Works this paper leans on
-
[1]
Can we predict alignment before models finish thinking? towards monitoring misaligned reasoning models.arXiv preprint arXiv:2507.12428. Nuo Chen, Zinan Zheng, Ning Wu, Ming Gong, Dong- mei Zhang, and Jia Li. 2024. Breaking language barriers in multilingual mathematical reasoning: In- sights and observations. InFindings of the Associa- tion for Computation...
-
[2]
mmbert: A modern multilingual encoder with annealed language learning.arXiv preprint arXiv:2509.06888. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xi- ang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. 2025. s1: Simple test-time scaling.Preprint, arXiv:2501.19393. OpenAI. 2025. Gpt-4.1. ...
-
[3]
InThe Eleventh International Conference on Learning Representations
Language models are multilingual chain-of- thought reasoners. InThe Eleventh International Conference on Learning Representations. Anthony F Shorrocks and 1 others. 2013. Decomposi- tion procedures for distributional analysis: a unified framework based on the shapley value.Journal of Economic Inequality, 11(1):99–126. Guijin Son, Jiwoo Hong, Hyunwoo Ko, a...
-
[4]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. Bernard L Welch. 1947. The generalization of ‘stu- dent’s’problem when several different population var- lances are involved.Biometrika, 34(1-2):28–35. Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, ...
-
[5]
Okay, I understand the question as: ’{xdom}’. I will solve the problem based on this understanding
Code-switching in-context learning for cross- lingual transfer of large language models.arXiv preprint arXiv:2510.05678. Dongkeun Yoon, Joel Jang, Sungdong Kim, Seungone Kim, Sheikh Shafayat, and Minjoon Seo. 2024. Lang- Bridge: Multilingual reasoning without multilingual supervision. InProceedings of the 62nd Annual Meeting of the Association for Computa...
-
[6]
Note: Please put the final answer in the \boxed{}
and four additional languages from P- MMeval (Zhang et al., 2024). • Medium: Consists of exam-style problems from college mathematics, China’s Gaokao, and postgraduate entrance exams, along with entry-level competition questions from AMC and CNMO provincial contests, all collected from official sources. • High: Focuses on mid- to high-difficulty com- peti...
work page 2024
-
[7]
is a multilingual benchmark extending the reasoning-focused English benchmark MMLU- Pro (Wang et al., 2024) to 29 typologically diverse languages, enabling cross-linguistic comparison of reasoning ability with fully parallel question sets. Each language version of the full benchmark contains 11,829 multiple-choice questions cover- ing 57 subjects, with ea...
work page 2024
-
[8]
Read the Question and determine the ex- pected final answer type. - Possible types include: Numeric scalar, Comparison/Ordering among variables, Set/List, Interval/Inequality, Coordinate/- Tuple, Algebraic expression, or Multiple- choice letter. - Decide the most appropriate type for THIS Question
-
[9]
Carefully scan the Reasoning trace and identify the final/conclusive answer consis- tent with the expected type. - Prefer the final/most conclusive statement (e.g., “Therefore. . . ”, “Thus. . . ”, “Final an- swer. . . ”, or the last decisive equation). - If multiple candidates appear, choose the last one that is self-consistent. - Ignore exploratory or c...
-
[10]
- Do not include any explanation or extra symbols outside\boxed{}
Output EXACTLY in the format: \boxed{FINAL_ANSWER} Formatting rules: - Put ONLY the final answer inside \boxed{} (no units, words, or explana- tions). - Do not include any explanation or extra symbols outside\boxed{}. - If no conclusive final answer is present in the trace, choose the last consistent can- didate stated as final; if still impossible, outpu...
-
[11]
Carefully scan the Reasoning trace and identify the final multiple-choice option an- swer. - Valid answers are only single capital let- ters from [A-J]. - If the final answer in the Reasoning trace is given as option text instead of a letter, use the provided multiple-choice options to map it to the corresponding letter from [A-J]. - Prefer the final/most...
-
[12]
- Do not include any explanation, units, or extra text
Output EXACTLY in the format: Answer: X Formatting rules: - Replace X with the chosen letter from [A- J]. - Do not include any explanation, units, or extra text. Now, the inputs are given below. Inputs: - Multiple-choice options (corresponding to the Question): {options_block} - Reasoning trace: {reasoning_trace} Output: Answer Verification.We evaluate th...
work page 2025
-
[13]
Reason" field should be one or two sentences. {
benchmark’s test set into 14 languages. Prompt for LLM-based detector You are given a problem (question and possi- bly options) and a model’s reasoning trace. Your task is to decide whether the model correctly understood the problem. Do not solve the problem yourself. Return the output strictly in the following JSON format, with no extra text. The "Reason...
work page 2025
-
[14]
samples. As hypothesized,average confidence andminimum confidencetend to be lower for not- understood samples, indicating their usefulness as understanding-failure signals. In contrast,input negative log-likelihoodshows no clear correlation with the labels. 23 20 25 30 35 40 45 Score not understood (POS) understood (NEG) =25.524 Overall Average Confidence...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.