MM-Telco: Benchmarks and Multimodal Large Language Models for Telecom Applications
Pith reviewed 2026-05-17 22:03 UTC · model grok-4.3
The pith
Fine-tuning multimodal LLMs on telecom-specific benchmarks leads to significant performance improvements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MM-Telco provides benchmarks for text and image tasks in telecom, and models fine-tuned on this data achieve substantial gains over baselines, enabling better automation of complex reasoning and decision-making in network optimization, troubleshooting, customer support, and regulatory compliance.
What carries the argument
The MM-Telco benchmark suite consisting of various practical real-life telecom tasks that are both text-based and image-based.
If this is right
- Improved automation of network optimization and troubleshooting processes.
- Enhanced quality of documentation and efficient retrieval of relevant information.
- Identification of limitations in current state-of-the-art multimodal models for guiding future research.
- Broader adoption of LLMs for ensuring regulatory compliance in telecom operations.
Where Pith is reading between the lines
- Successful deployment could reduce operational costs and errors in managing large-scale telecom networks.
- Similar benchmark approaches might accelerate adaptation of AI models in other specialized industries.
- The image-based tasks suggest potential for integrating visual network monitoring with language models.
Load-bearing premise
The new tasks and benchmarks reflect actual real-life telecom scenarios and that gains seen in controlled tests will carry over to real-world network improvements.
What would settle it
Running the fine-tuned models on live telecom network data and measuring if they outperform standard tools in resolving actual operational issues within a set time frame.
Figures




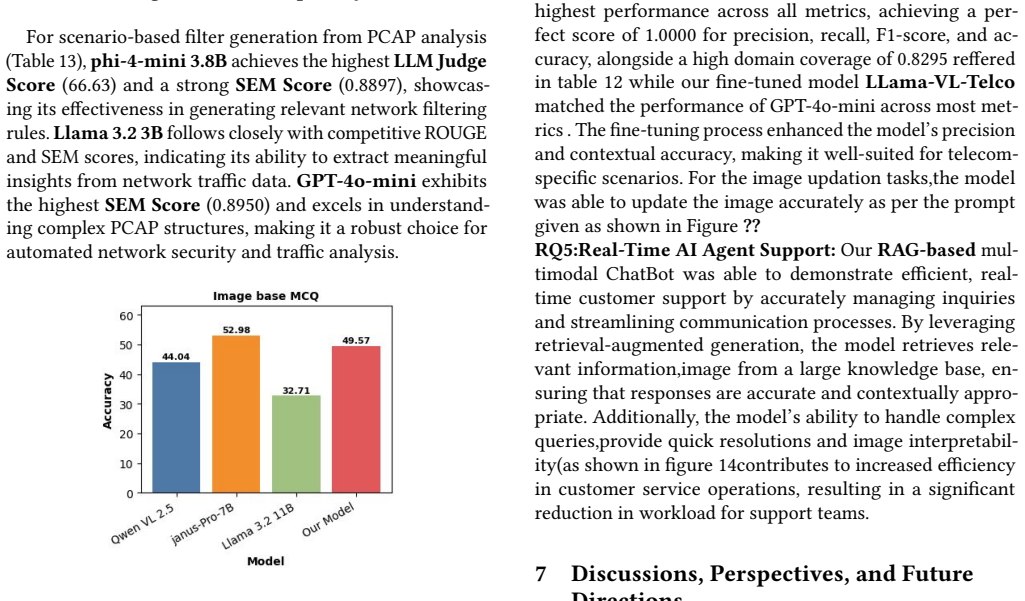






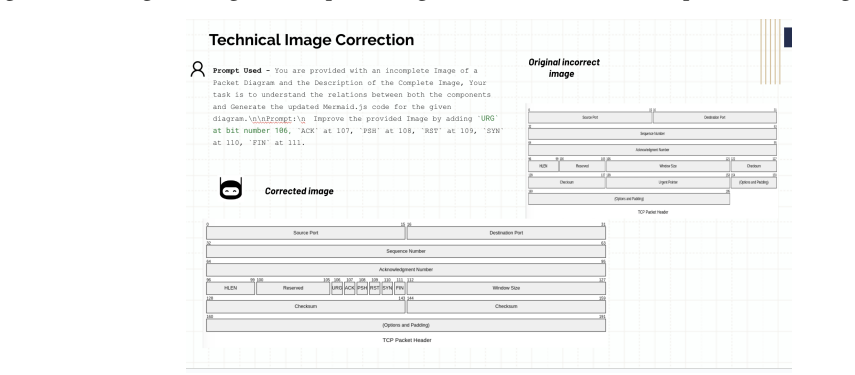

read the original abstract
Large Language Models (LLMs) have emerged as powerful tools for automating complex reasoning and decision-making tasks. In telecommunications, they hold the potential to transform network optimization, automate troubleshooting, enhance customer support, and ensure regulatory compliance. However, their deployment in telecom is hindered by domain-specific challenges that demand specialized adaptation. To overcome these challenges and to accelerate the adaptation of LLMs for telecom, we propose MM-Telco, a comprehensive suite of multimodal benchmarks and models tailored for the telecom domain. The benchmark introduces various tasks (both text based and image based) that address various practical real-life use cases such as network operations, network management, improving documentation quality, and retrieval of relevant text and images. Further, we perform baseline experiments with various LLMs and VLMs. The models fine-tuned on our dataset exhibit a significant boost in performance. Our experiments also help analyze the weak areas in the working of current state-of-art multimodal LLMs, thus guiding towards further development and research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MM-Telco, a suite of multimodal benchmarks and fine-tuned models for telecom applications. It defines text- and image-based tasks covering network operations, management, documentation quality, and retrieval, reports baseline results with various LLMs and VLMs, and asserts that fine-tuning on the new dataset produces a significant performance boost while highlighting weaknesses in current multimodal models.
Significance. If the benchmarks are shown to be representative of real operator workflows and the performance gains are supported by detailed quantitative evaluations with proper baselines and statistical controls, the work could supply useful resources for domain adaptation of multimodal LLMs in telecommunications, aiding practical applications in network optimization and support.
major comments (2)
- Abstract: the assertion that 'the models fine-tuned on our dataset exhibit a significant boost in performance' is presented without any numerical metrics, tables, baseline comparisons, error bars, or evaluation protocol details, leaving the central empirical claim without visible quantitative support.
- Task and benchmark construction sections: the tasks are stated to address 'practical real-life use cases' yet the manuscript supplies no description of derivation from operator logs, expert annotation procedures, comparison to production telemetry, or external validation, which is load-bearing for claims that measured gains will translate to deployable improvements.
minor comments (1)
- Abstract: consider adding one sentence on dataset scale or the specific base models used in the baselines to give readers immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of quantitative results and the justification for benchmark relevance. We address each point below and have revised the manuscript to improve clarity and support for our claims.
read point-by-point responses
-
Referee: Abstract: the assertion that 'the models fine-tuned on our dataset exhibit a significant boost in performance' is presented without any numerical metrics, tables, baseline comparisons, error bars, or evaluation protocol details, leaving the central empirical claim without visible quantitative support.
Authors: We agree that the abstract should provide immediate quantitative support for the performance claims. In the revised version, we have updated the abstract to include key numerical results from our experiments, such as specific accuracy and F1-score improvements for the fine-tuned models relative to the zero-shot and few-shot baselines. We also added a brief reference to the evaluation protocol and main results tables in the experimental section. The detailed metrics, baselines, and statistical details remain in the body of the paper. revision: yes
-
Referee: Task and benchmark construction sections: the tasks are stated to address 'practical real-life use cases' yet the manuscript supplies no description of derivation from operator logs, expert annotation procedures, comparison to production telemetry, or external validation, which is load-bearing for claims that measured gains will translate to deployable improvements.
Authors: We acknowledge the value of explicitly documenting the benchmark construction process. The tasks were designed to capture representative telecom scenarios drawn from publicly available industry documentation, standards, and common operational challenges. In the revision, we have added a dedicated subsection describing the task formulation process, including the use of domain-expert review for annotation guidelines and alignment with typical network management workflows. Direct use of proprietary operator logs or production telemetry was not feasible due to data access constraints; however, the added details clarify how the tasks reflect real-world use cases and support the observed performance gains. revision: partial
Circularity Check
No significant circularity in benchmark construction or performance reporting
full rationale
The paper introduces a new multimodal benchmark suite (MM-Telco) with text and image tasks for telecom use cases and reports empirical results from baseline LLMs/VLMs plus fine-tuned models showing performance gains on those tasks. No derivation chain, equations, or first-principles claims exist that reduce by construction to the paper's own inputs; the reported boosts are direct experimental measurements on the defined dataset rather than predictions or self-definitional results. This is a standard benchmark paper with self-contained empirical content and no load-bearing self-citations or ansatz smuggling that would trigger the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuning general-purpose LLMs and VLMs on domain-specific datasets yields measurable performance gains on related tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The benchmark introduces various tasks (both text based and image based) that address various practical real-life use cases such as network operations, network management, improving documentation quality, and retrieval of relevant text and images. ... The models fine-tuned on our dataset exhibit a significant boost in performance.
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We fine-tune a Llama model Llama-VL-Telco that is capable of generating and updating the telecom images when given the suitable prompt.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
3rd Generation Partnership Project (3GPP). 2024. 3GPP Specifications and Technologies - Releases. https://www.3gpp.org/specifications- Gagan Raj Gupta, Anshul Kumar, Manish Rai, Apu Chakraborty, Ashutosh Modi, Abdelaali Chaoub, Soumajit Pramanik, Moyank Giri, Yashwanth Holla, Sunny Kumar, and M. V. Kiran Sooraj Model Top 1 Accuracy Top 3 Accuracy Top 5 Ac...
work page 2024
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv:2308.12966 [cs.CV] https://arxiv. org/abs/2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
Jie Bian, Michael Welzl, Andrey Kutuzov, and Nikolay Arefyev. 2024. Tell Me Why: Language Models Help Explain the Rationale Behind Internet Protocol Design. In2024 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN). 447–
work page 2024
-
[5]
https://doi.org/10.1109/ICMLCN59089.2024.10624781
-
[6]
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Mañas, Zhiqiu Lin, Anas Mah- moud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, ...
- [7]
-
[8]
Common Crawl. 2024. Common Crawl Dataset. https://commoncrawl. org/
work page 2024
-
[9]
Aniket Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy Lillicrap, Danilo Jimenez Rezende, Yoshua Bengio, Michael C Mozer, and Sanjeev Arora. 2024. Metacognitive capabilities of llms: An exploration in mathematical problem solv- ing.Advances in Neural Information Processing Systems37 (2024), 19783–19812
work page 2024
-
[10]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. 2025. ColPali: Efficient Document Retrieval with Vision Language Models. arXiv:2407.01449 [cs.IR] https://arxiv.org/abs/2407.01449
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Zhiwei Fei, Songyang Zhang, Xiaoyu Shen, Dawei Zhu, Xiao Wang, Jidong Ge, and Vincent Ng. 2025. InternLM-Law: An Open-Sourced Chinese Legal Large Language Model. InProceedings of the 31st In- ternational Conference on Computational Linguistics, Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eu- genio, and Steven Schockaert (Eds....
work page 2025
-
[12]
Iryna Hartsock and Ghulam Rasool. 2024. Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review.ArXivabs/2403.02469 (2024). https://doi.org/10.48550/arXiv. 2403.02469
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Athanasios Karapantelakis, Mukesh Thakur, Alexandros Nikou, Farnaz Moradi, Christian Orlog, Fitsum Gaim, Henrik Holm, Doumitrou Daniil Nimara, and Vincent Huang. 2024. Us- ing Large Language Models to Understand Telecom Standards. arXiv:2404.02929 [cs.CL] https://arxiv.org/abs/2404.02929
-
[15]
Imtiaz Karim, Kazi Samin Mubasshir, Mirza Masfiqur Rahman, and Elisa Bertino. 2023. SPEC5G: A Dataset for 5G Cellular Network Protocol Analysis. InFindings of the Association for Computational Linguistics: IJCNLP-AACL 2023 (Findings), Jong C. Park, Yuki Arase, Baotian Hu, Wei Lu, Derry Wijaya, Ayu Purwarianti, and Adila Alfa Krisnadhi (Eds.). Association ...
-
[16]
Kartik Kuckreja, M. S. Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and F. Khan. 2023. GeoChat:Grounded Large Vision-Language Model for Remote Sensing.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2023), 27831–27840. https: //doi.org/10.1109/CVPR52733.2024.02629
- [17]
-
[18]
Sunwoo Lee, Dhammiko Arya, Seung-Mo Cho, Gyoung-eun Han, Seokyoung Hong, Wonbeom Jang, Seojin Lee, Sohee Park, Sereimony Sek, Injee Song, et al. 2024. TelBench: A Benchmark for Evaluating Telco-Specific Large Language Models. InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing: Industry Track. 609–626
work page 2024
- [19]
- [20]
-
[21]
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dong- mei Zhang. 2023. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct.arXiv preprint arXiv:2308.09583(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Risto Luukkonen, Ville Komulainen, Jouni Luoma, Anni Eskelinen, Jenna Kanerva, Hanna-Mari Kupari, Filip Ginter, Veronika Laippala, Niklas Muennighoff, Aleksandra Piktus, Thomas Wang, Nouamane Tazi, Teven Scao, Thomas Wolf, Osma Suominen, Samuli Sairanen, Mikko Merioksa, Jyrki Heinonen, Aija Vahtola, Samuel Antao, and Sampo Pyysalo. 2023. FinGPT: Large Gen...
- [23]
- [24]
- [25]
-
[26]
Rasoul Nikbakht, Mohamed Benzaghta, and Giovanni Geraci. 2024. TSpec-LLM: An Open-source Dataset for LLM Understanding of 3GPP Gagan Raj Gupta, Anshul Kumar, Manish Rai, Apu Chakraborty, Ashutosh Modi, Abdelaali Chaoub, Soumajit Pramanik, Moyank Giri, Yashwanth Holla, Sunny Kumar, and M. V. Kiran Sooraj Specifications. arXiv:2406.01768 [cs.NI] https://arx...
-
[27]
OpenWebText. 2024. OpenWebText Corpus. https://skylion007.github. io/OpenWebTextCorpus/
work page 2024
-
[28]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learn- ing Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020 [cs.CV] https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Mirza Masfiqur Rahman, Imtiaz Karim, and Elisa Bertino. 2024. Cel- lularLint: A Systematic Approach to Identify Inconsistent Behavior in Cellular Network Specifications. In33rd USENIX Security Sympo- sium (USENIX Security 24). USENIX Association, Philadelphia, PA, 5215–5232. https://www.usenix.org/conference/usenixsecurity24/ presentation/rahman
work page 2024
-
[30]
Sujoy Roychowdhury, Sumit Soman, H. G. Ranjani, Vansh Chhabra, Neeraj Gunda, Shashank Gautam, Subhadip Bandyopadhyay, and Sai Krishna Bala. 2024. Towards Understanding Domain Adapted Sen- tence Embeddings for Document Retrieval. arXiv:2406.12336 [cs.CL] https://arxiv.org/abs/2406.12336
-
[31]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Azzedine Idir Ait Said, Abdelkader Mekrache, Karim Boutiba, Kostas Ramantas, Adlen Ksentini, and Moufida Rahmani. 2024. 5G INSTRUCT Forge: An Advanced Data Engineering Pipeline for Making LLMs Learn 5G.IEEE Transactions on Cognitive Communications and Net- working(2024), 1–1. https://doi.org/10.1109/TCCN.2024.3516055
-
[33]
Ankit Satpute, Noah Gießing, André Greiner-Petter, Moritz Schubotz, Olaf Teschke, Akiko Aizawa, and Bela Gipp. 2024. Can llms master math? investigating large language models on math stack exchange. In Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 2316–2320
work page 2024
- [34]
-
[35]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole- Lewis, Stephen Pfohl, et al . 2023. Large language models encode clinical knowledge.Nature620, 7972 (2023), 172–180
work page 2023
-
[36]
Sumit Soman and Ranjani H. G. 2023. Observations on LLMs for Telecom Domain: Capabilities and Limitations. InThe Third Interna- tional Conference on Artificial Intelligence and Machine Learning Sys- tems (AIMLSystems 2023). ACM, 1–5. https://doi.org/10.1145/3639856. 3639892
-
[37]
Chuanhao Sun, Ujjwal Pawar, Molham Khoja, Xenofon Foukas, Ma- hesh K. Marina, and Bozidar Radunovic. 2024. SpotLight: Accurate, Explainable and Efficient Anomaly Detection for Open RAN. InPro- ceedings of the 30th Annual International Conference on Mobile Comput- ing and Networking(Washington D.C., DC, USA)(ACM MobiCom ’24). Association for Computing Mach...
- [38]
-
[39]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. AutoDroid: LLM-powered Task Automation in Android. InProceed- ings of the 30th Annual International Conference on Mobile Computing and Networking(Washington D.C., DC, USA)(ACM MobiCom ’24). Association for Computing Machine...
-
[40]
Chaoyi Wu, Weixiong Lin, Xiaoman Zhang, Ya Zhang, Weidi Xie, and Yanfeng Wang. 2024. PMC-LLaMA: toward building open-source lan- guage models for medicine.Journal of the American Medical Informat- ics Association : JAMIA(2024). https://doi.org/10.1093/jamia/ocae045
-
[41]
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564 [cs.LG] https://arxiv.org/abs/2303.17564
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [42]
-
[43]
Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. 2023. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond.ACM Transactions on Knowledge Discovery from Data18 (2023), 1 – 32. https: //api.semanticscholar.org/CorpusID:258331833
work page 2023
-
[44]
Shunyu Yao, Qingqing Ke, Qiwei Wang, Kangtong Li, and Jie Hu
-
[45]
Lawyer GPT: A legal large language model with enhanced domain knowledge and reasoning capabilities. InProceedings of the 2024 3rd International Symposium on Robotics, Artificial Intelligence and Information Engineering. 108–112
work page 2024
-
[46]
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. 2024. A survey on large language model (LLM) security and pri- vacy: The Good, The Bad, and The Ugly.High-Confidence Computing 4, 2 (2024), 100211. https://doi.org/10.1016/j.hcc.2024.100211
- [47]
-
[48]
Dong Yuan, Eti Rastogi, Gautam Naik, Sree Prasanna Rajagopal, Sagar Goyal, Fen Zhao, Bharath Chintagunta, and Jeffrey Ward. 2024. A con- tinued pretrained llm approach for automatic medical note generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volu...
work page 2024
-
[49]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. 2023. Vision- Language Models for Vision Tasks: A Survey.IEEE Transactions on Pattern Analysis and Machine Intelligence46 (2023), 5625–5644. https: //doi.org/10.1109/TPAMI.2024.3369699
-
[50]
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Žagar, Wal- ter Zimmer, Hu Cao, and Alois C. Knoll. 2023. Vision Language Models in Autonomous Driving: A Survey and Outlook.IEEE Transactions on Intelligent Vehicles(2023). https://api.semanticscholar.org/CorpusID: 269865211
work page 2023
-
[51]
Hang Zou, Qiyang Zhao, Yu Tian, Lina Bariah, Faouzi Bader, Thierry Lestable, and Merouane Debbah. 2024. TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models. arXiv:2407.09424 [eess.SP] https://arxiv.org/abs/2407.09424 MM-Telco: Benchmarks and Multimodal Large Language Models for Telecom Applications 9 Appendix In this subsection, we pres...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.