Data-driven Acceleration of MPC with Guarantees
Pith reviewed 2026-05-21 18:17 UTC · model grok-4.3
The pith
A nonparametric policy from offline MPC solutions replaces online optimization while guaranteeing recursive feasibility and a bounded optimality gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a greedy policy with respect to a constructed upper bound on the optimal cost-to-go, formed from a finite set of offline MPC solutions, can be substituted for repeated online optimization. When the offline data satisfies sufficient coverage conditions, this policy remains recursively feasible and its infinite-horizon cost lies within an explicitly characterized gap of the optimal MPC cost, with the gap shrinking as the data set grows.
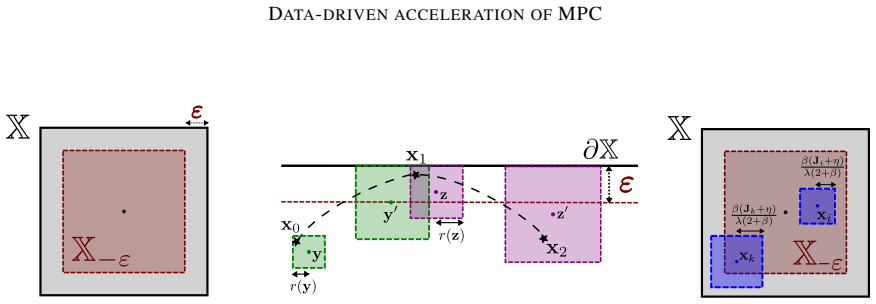
What carries the argument
The nonparametric greedy policy that selects the control minimizing immediate cost plus the data-derived upper bound on cost-to-go.
If this is right
- The policy executes 100 to 1000 times faster than solving MPC online.
- Adding any new MPC solution immediately tightens the bound without requiring retraining.
- An explicit trade-off exists between the number of offline samples and the size of the optimality gap.
- The same policy structure applies to any real-time control task where standard MPC is currently too slow.
Where Pith is reading between the lines
- The coverage condition could be monitored online so that new data is collected only when the current bound risks becoming invalid.
- The same construction might accelerate other receding-horizon planners beyond classical MPC.
- Because the policy is a simple lookup, it could run on embedded hardware that lacks the resources for real-time optimization.
Load-bearing premise
The offline data set must be dense enough that the constructed upper bound on cost-to-go stays valid for every state the system actually visits during online operation.
What would settle it
Run the policy on a trajectory that reaches a state outside the covered region and observe whether feasibility is lost or the realized optimality gap exceeds the predicted bound.
Figures



read the original abstract
Model Predictive Control (MPC) is a powerful framework for optimal control but can be too slow for low-latency applications. We present a data-driven framework to accelerate MPC by replacing online optimization with a nonparametric policy constructed from offline MPC solutions. Our policy is greedy with respect to a constructed upper bound on the optimal cost-to-go, and can be implemented as a nonparametric lookup rule that is orders of magnitude faster than solving MPC online. Our analysis shows that under sufficient coverage conditions of the offline data, the policy is recursively feasible and admits provable, bounded optimality gap. These conditions establish an explicit trade-off between the amount of data collected and the tightness of the bounds. New solutions can be incorporated straightforwardly without the need for retraining, enabling continual improvement. Our experiments show that this policy is between 100 and 1000 times faster than standard MPC with only a modest hit to optimality, showing potential for real-time control tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a data-driven framework to accelerate MPC by constructing a nonparametric greedy policy from offline MPC solutions. The policy is defined with respect to a constructed upper bound on the optimal cost-to-go and can be implemented as a fast lookup rule. Under sufficient coverage conditions on the offline data, the analysis claims recursive feasibility and a provable bounded optimality gap, with an explicit trade-off between data volume and bound tightness. New solutions can be added without retraining, and experiments report 100-1000x speedup over standard MPC with modest optimality loss.
Significance. If the central guarantees hold, the work offers a meaningful contribution to real-time control by providing a fast, data-driven MPC approximation with explicit performance bounds and continual improvement capability. The nonparametric nature and lack of retraining requirement are practical strengths that could enable deployment in low-latency applications where traditional MPC is prohibitive.
major comments (1)
- [Analysis section] Analysis section (as described in the abstract): the claim that sufficient coverage conditions ensure recursive feasibility and bounded optimality gap is load-bearing, yet the manuscript does not establish that the greedy policy (nonparametric lookup w.r.t. the upper bound) renders the data-covered set positively invariant. Coverage is a static property of the offline dataset; without a proof that closed-loop trajectories remain inside this set, the upper bound may cease to be valid online, collapsing both feasibility and the gap guarantee. This directly affects the stated trade-off between data volume and bound tightness.
minor comments (2)
- [Abstract] The abstract refers to 'sufficient coverage conditions' without a forward reference to their precise definition or the theorem that invokes them; adding this would improve readability.
- [Experiments] Experiments section: while speedup factors are reported, including the state/input dimensions of the benchmark problems and the hardware platform would allow better assessment of the practical speedup.
Simulated Author's Rebuttal
Thank you for the careful review and constructive feedback on our manuscript. We address the major comment regarding the analysis of recursive feasibility and the positive invariance of the covered set under the greedy policy. We agree that this aspect requires strengthening and outline the planned revisions below.
read point-by-point responses
-
Referee: [Analysis section] Analysis section (as described in the abstract): the claim that sufficient coverage conditions ensure recursive feasibility and bounded optimality gap is load-bearing, yet the manuscript does not establish that the greedy policy (nonparametric lookup w.r.t. the upper bound) renders the data-covered set positively invariant. Coverage is a static property of the offline dataset; without a proof that closed-loop trajectories remain inside this set, the upper bound may cease to be valid online, collapsing both feasibility and the gap guarantee. This directly affects the stated trade-off between data volume and bound tightness.
Authors: We thank the referee for highlighting this critical point. We acknowledge that while the manuscript states the guarantees under sufficient coverage conditions, the explicit proof establishing that the greedy policy renders the data-covered set positively invariant is not developed in sufficient detail. This leaves the online validity of the upper bound and the resulting recursive feasibility and bounded optimality gap insufficiently supported. In the revised manuscript, we will expand the Analysis section with a dedicated lemma proving positive invariance. The proof will show that, for any state in the covered set, the control selected by the nonparametric greedy policy (with respect to the constructed upper bound) produces a successor state that remains covered. This follows from the consistency of the upper bound with the system dynamics and the fact that the offline dataset includes complete optimal trajectories, ensuring the coverage condition propagates along closed-loop trajectories. We will also clarify how this invariance underpins the explicit trade-off between data volume and bound tightness. These additions will be placed immediately following the coverage definition to make the argument self-contained. revision: yes
Circularity Check
No significant circularity; derivation relies on independent coverage-based analysis
full rationale
The paper constructs a nonparametric greedy policy directly from offline MPC solutions and an upper bound on the cost-to-go, then invokes an analysis to establish recursive feasibility and a bounded optimality gap under explicit sufficient coverage conditions on the dataset. These conditions are stated as an external requirement rather than derived from the policy itself, and the trade-off between data volume and bound tightness is presented as a consequence of the coverage assumption. No equations or steps reduce the claimed guarantees to a fitted parameter, self-definition, or self-citation chain by construction; the central results rest on the coverage premise and the analysis rather than tautological equivalence to the input data. The skeptic concern about positive invariance is a potential gap in the proof (correctness risk) but does not indicate circularity in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Offline MPC solutions provide an upper bound on the optimal cost-to-go that remains valid under the stated coverage conditions.
Reference graph
Works this paper leans on
-
[1]
If(x,u)is feasible, then(x 0,u)is feasible for allx 0 ∈B x, r(x,u) , where: r(x,u)≜max 0, R−L u∥u∥ Lf − ∥x∥ (15)
-
[2]
If(x,u)is feasible andx ′ =f(x,u), then(x 0,u)is feasible for allx 0 ∈B x, r(x′) , where: r(x′)≜ R− ∥x ′∥ Lf ≤ dist(x′, ∂X) Lf (16) 14 DATA-DRIVEN ACCELERATION OFMPC Appendix B. Proofs B.1. Proposition 6 Proof
-
[3]
Letx ′ =f(x,u). By virtue of (11): ∥x′∥ ≤L f ∥x∥+L u∥u∥(17) Letx 0 ∈X:∥x 0 −x∥ ≤r, andx ′ 0 =f(x 0,u)be the successor state under the sameu. We have: ∥x′ 0∥ − ∥x′∥ ≤ ∥x ′ 0 −x ′∥ ≤L f r=⇒(18) ∥x′ 0∥ ≤ ∥x ′∥+L f r≤L f (∥x∥+r) +L u∥u∥,(19) where the first inequality in (18) follows from the reverse triangle inequality, and the second one from (12) (for two ...
-
[4]
Theorem 1 ProofNotice that, by assumption, we are in the conditions of Proposition 3
Re-using the first inequality in (19), and imposing that it be upper bounded byR: ∥x′ 0∥ ≤ ∥x ′∥+L f r≤R=⇒r≤ R− ∥x ′∥ Lf .(21) For the remaining inequality, note: dist x′, ∂X ≥R− ∥x ′∥ ∀x ′ ∈X.(22) B.2. Theorem 1 ProofNotice that, by assumption, we are in the conditions of Proposition 3. This implies policy πD is feasible, and hence: J π(x)<+∞ ∀x∈X. LetT ...
work page 2011
-
[5]
For any policyπ,T π is monotone, i.e. J1(x)≤J 2(x)∀x=⇒(T πJ1) (x)≤(T πJ2) (x)∀x 2.J π is the unique fixed point ofT π: lim k→∞ ktimes z }| { (T π ◦ T π ◦. . .T π)J=J π ∀J∈ J. The combination of these two facts leads to the following lemma: Lemma 1IfJ:X→Rsatisfies: (T πJ) (x)≤J(x)∀x∈X, then: J π(x)≤J(x)∀x∈X. Then, to prove Theorem 1, all that remains is to...
work page 2016
-
[6]
20 DATA-DRIVEN ACCELERATION OFMPC whereu∈Ris the scalar torque applied to the axis of the pendulum
For example, if we split each edge of the cellX k,j by half, then the central point,x k,j, is not usable for any children cellX k+1,i in the new subgridH k,j. 20 DATA-DRIVEN ACCELERATION OFMPC whereu∈Ris the scalar torque applied to the axis of the pendulum. We consider the discrete-time dynamics of (44) with sampling timeδt= 0.05s, we letu t ∈U= [−5,5], ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.