PVeRA: Probabilistic Vector-Based Random Matrix Adaptation
Pith reviewed 2026-05-17 00:24 UTC · model grok-4.3
The pith
PVeRA turns VeRA's fixed random low-rank matrices probabilistic to manage input ambiguities during adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
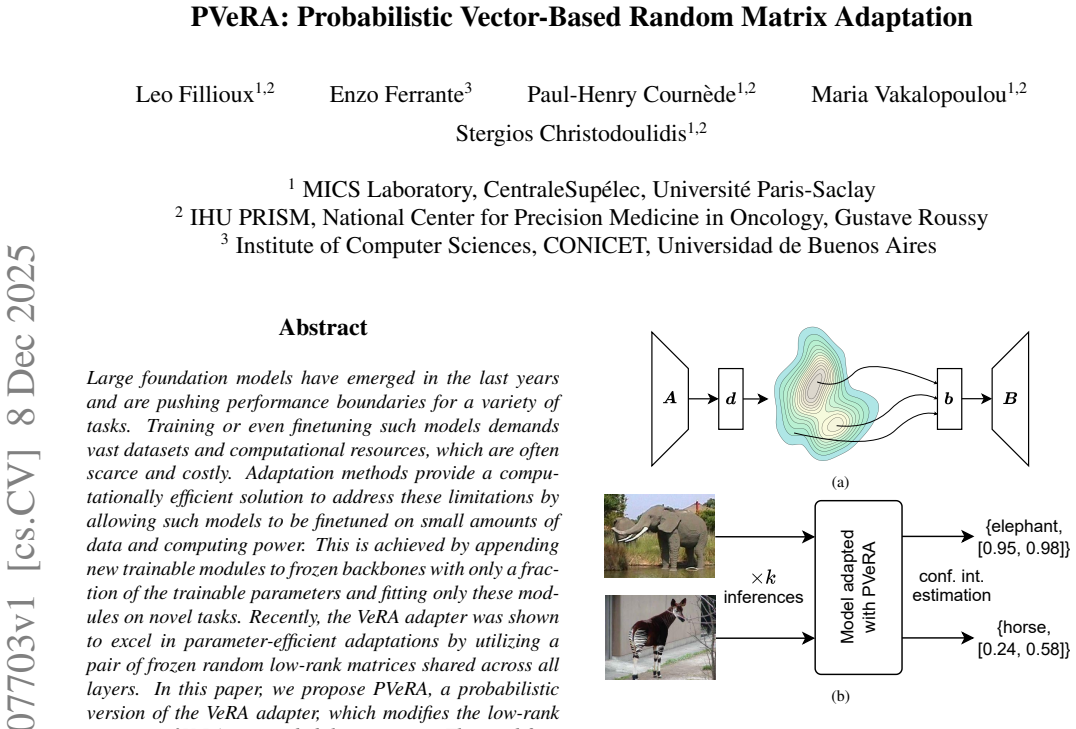
PVeRA modifies the low-rank matrices of VeRA in a probabilistic manner. This modification naturally allows handling inherent ambiguities in the input and allows for different sampling configurations during training and testing. A comprehensive evaluation was performed on the VTAB-1k benchmark and seven adapters, with PVeRA outperforming VeRA and other adapters.
What carries the argument
Probabilistic sampling over the pair of frozen random low-rank matrices that VeRA shares across all layers.
If this is right
- The adapter can accommodate tasks whose inputs contain natural ambiguities more effectively than fixed-matrix versions.
- Training and inference can employ distinct sampling schemes from the same underlying distributions.
- Gains appear on the VTAB-1k suite without increasing the number of tunable hyperparameters.
- Only the distribution parameters are added on top of VeRA's original lightweight design.
Where Pith is reading between the lines
- The same probabilistic treatment could be applied to other adapters that rely on shared random matrices.
- Sensitivity to the particular random draw chosen at initialization may decrease.
- Different distribution families could be tested to further improve robustness on specific domains.
- Extension to language-model adaptation benchmarks would test whether the benefit is vision-specific.
Load-bearing premise
That making the low-rank matrices probabilistic will handle input ambiguities without creating new instabilities or needing extra hyperparameter tuning.
What would settle it
Re-running the VTAB-1k evaluation and finding that PVeRA fails to exceed VeRA's average accuracy across tasks would falsify the performance advantage.
Figures






read the original abstract
Large foundation models have emerged in the last years and are pushing performance boundaries for a variety of tasks. Training or even finetuning such models demands vast datasets and computational resources, which are often scarce and costly. Adaptation methods provide a computationally efficient solution to address these limitations by allowing such models to be finetuned on small amounts of data and computing power. This is achieved by appending new trainable modules to frozen backbones with only a fraction of the trainable parameters and fitting only these modules on novel tasks. Recently, the VeRA adapter was shown to excel in parameter-efficient adaptations by utilizing a pair of frozen random low-rank matrices shared across all layers. In this paper, we propose PVeRA, a probabilistic version of the VeRA adapter, which modifies the low-rank matrices of VeRA in a probabilistic manner. This modification naturally allows handling inherent ambiguities in the input and allows for different sampling configurations during training and testing. A comprehensive evaluation was performed on the VTAB-1k benchmark and seven adapters, with PVeRA outperforming VeRA and other adapters. Our code for training models with PVeRA and benchmarking all adapters is available https://github.com/leofillioux/pvera.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PVeRA, a probabilistic variant of the VeRA adapter for parameter-efficient fine-tuning of large foundation models. It modifies the shared frozen random low-rank matrices of VeRA in a probabilistic manner to handle input ambiguities, with support for different sampling configurations during training and testing. The authors report a comprehensive evaluation on the VTAB-1k benchmark against seven adapters, claiming that PVeRA outperforms VeRA and the other methods, and provide open-source code.
Significance. If the empirical superiority holds after proper specification and validation, the probabilistic treatment could offer a useful extension to random-matrix adapters like VeRA by explicitly modeling uncertainty, potentially improving robustness on ambiguous inputs while preserving parameter efficiency. The release of training and benchmarking code is a clear strength for reproducibility. Current significance is constrained by the absence of formal method details and experimental controls.
major comments (2)
- [Method] The description of the probabilistic modification to VeRA's low-rank matrices (A, B) provides no explicit distribution family, sampling procedure (e.g., reparameterization trick), or train/test discrepancy handling (multiple samples vs. mean or single draw). This specification is load-bearing for the central claim that the approach captures ambiguities without introducing new hyperparameters or instability.
- [Experiments] The VTAB-1k evaluation asserts outperformance over VeRA and six other adapters but supplies no error bars, number of runs, statistical tests, ablation studies on the probabilistic components, or confirmation of equal hyperparameter budgets. These omissions prevent verification of the reported gains.
minor comments (1)
- [Abstract] The abstract states that seven adapters were compared but does not name them; listing the baselines would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting areas where additional clarity and rigor would strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Method] The description of the probabilistic modification to VeRA's low-rank matrices (A, B) provides no explicit distribution family, sampling procedure (e.g., reparameterization trick), or train/test discrepancy handling (multiple samples vs. mean or single draw). This specification is load-bearing for the central claim that the approach captures ambiguities without introducing new hyperparameters or instability.
Authors: We agree that the method description requires more explicit formalization to support the central claims. The manuscript introduces the probabilistic treatment at a conceptual level, noting that the frozen random low-rank matrices are made probabilistic to handle input ambiguities and that different sampling configurations are supported at train and test time. In the revision we will add a dedicated subsection that specifies a zero-mean Gaussian distribution over the matrix entries (with per-layer scale parameters), employs the reparameterization trick for end-to-end differentiability, and details the train-time multi-sample procedure versus the test-time options (mean or single draw). These choices reuse the existing VeRA rank and scaling hyperparameters and introduce no new tunable values. Mathematical notation, a sampling algorithm, and a short discussion of stability will be included. revision: yes
-
Referee: [Experiments] The VTAB-1k evaluation asserts outperformance over VeRA and six other adapters but supplies no error bars, number of runs, statistical tests, ablation studies on the probabilistic components, or confirmation of equal hyperparameter budgets. These omissions prevent verification of the reported gains.
Authors: We acknowledge that the experimental reporting is incomplete for rigorous verification. All methods were evaluated under the standard VTAB-1k protocol with identical hyperparameter search budgets (grid search over learning rate, rank, and scaling factor, selecting the best validation performer for each adapter). To address the gaps we will (i) report mean and standard deviation over five independent random seeds, (ii) add error bars to all tables, (iii) include a dedicated ablation subsection isolating the contribution of the probabilistic modeling, and (iv) explicitly state that the same search space and selection criterion were used across all baselines. While we did not perform formal statistical significance tests in the original submission, the consistent ranking across the 19 tasks supports the reported gains; we will add a brief note on this point. revision: yes
Circularity Check
No significant circularity detected in PVeRA derivation
full rationale
The paper defines PVeRA as a probabilistic extension to VeRA by modifying its shared frozen low-rank matrices to accommodate input ambiguities via new sampling configurations at train and test time. This is presented as an independent modeling choice rather than a quantity derived from or fitted to VeRA parameters by construction. The central performance claim rests on an empirical comparison across VTAB-1k and seven adapters, which does not reduce to any self-definitional loop, fitted-input prediction, or self-citation chain. No equations or sections in the provided text exhibit the reduction patterns required for a circularity finding; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probabilistic modification of frozen random low-rank matrices allows different sampling configurations during training and testing that handle inherent input ambiguities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PVeRA ... modifies the low-rank matrices of VeRA in a probabilistic manner ... z ~ N(mu, sigma^2) ... L_total = L_classification + beta * sum L_KL
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VeRA ... frozen random low-rank matrices shared across all layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization, 2016. cite arxiv:1607.06450. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Neural machine translation by jointly learning to align and translate, 2016
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate, 2016. 3
work page 2016
-
[3]
Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Heinrich K¨uttler, Andrew Lefrancq, Si- mon Green, V´ıctor Vald´es, Amir Sadik, et al. Deepmind lab. arXiv preprint arXiv:1612.03801, 2016. 5
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Kartikeya Bhardwaj, Nilesh Prasad Pandey, Sweta Priyadarshi, Viswanath Ganapathy, Shreya Kadambi, Rafael Esteves, Shubhankar Borse, Paul Whatmough, Risheek Garrepalli, Mart Van Baalen, Harris Teague, and Markus Nagel. Sparse high rank adapters. InAd- vances in Neural Information Processing Systems, pages 13685–13715. Curran Associates, Inc., 2024. 2
work page 2024
-
[5]
Adaptformer: Adapt- ing vision transformers for scalable visual recognition, 2022
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapt- ing vision transformers for scalable visual recognition, 2022. 2, 4
work page 2022
-
[6]
A simple framework for contrastive learning of visual representations, 2020
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations, 2020. 1
work page 2020
-
[7]
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sens- ing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 2017. 5
work page 2017
-
[8]
Probabilistic embeddings for cross-modal retrieval
Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio De Rezende, Yannis Kalantidis, and Diane Larlus. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8415–8424, 2021. 3
work page 2021
- [9]
-
[10]
Clap: Learning audio concepts from natural language supervision, 2022
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap: Learning audio concepts from natural language supervision, 2022. 2
work page 2022
-
[11]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning, 2016
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning, 2016. 3
work page 2016
-
[12]
Vision meets robotics: The kitti dataset.Interna- tional Journal of Robotics Research, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.Interna- tional Journal of Robotics Research, 2013. 5
work page 2013
-
[13]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks, 2017. 5
work page 2017
-
[14]
Smt: Fine-tuning large language models with sparse matri- ces
Haoze He, Juncheng Li, Xuan Jiang, and Heather Miller. Smt: Fine-tuning large language models with sparse matri- ces. InInternational Conference on Learning Representa- tions, 2025. 2
work page 2025
-
[15]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. Deber- tav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing, 2023. 13
work page 2023
-
[16]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019. 5
work page 2019
-
[17]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InProceedings of the 36th International Conference on Machine Learning, 2019. 1, 2, 4
work page 2019
-
[18]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations, 2022. 2, 3, 5
work page 2022
-
[19]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning, 2022. 2
work page 2022
-
[20]
Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning. InIEEE Conference on Computer Vi- sion and Pattern Recognition, 2017. 5
work page 2017
-
[21]
Kaggle diabetic retinopathy detection,
Kaggle and EyePacs. Kaggle diabetic retinopathy detection,
-
[22]
Diederik P. Kingma and Max Welling. Auto-Encoding Vari- ational Bayes. In2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14- 16, 2014, Conference Track Proceedings, 2014. 3
work page 2014
-
[23]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything.arXiv:2304.02643, 2023. 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
VeRA: Vector-based random matrix adaptation
Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M Asano. VeRA: Vector-based random matrix adaptation. In The Twelfth International Conference on Learning Represen- tations, 2024. 2, 3, 4, 5
work page 2024
-
[25]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009. 5
work page 2009
-
[26]
Learning methods for generic object recognition with invariance to pose and lighting
Yann LeCun, Fu Jie Huang, and Leon Bottou. Learning methods for generic object recognition with invariance to pose and lighting. InIEEE Conference on Computer Vision and Pattern Recognition, 2004. 5
work page 2004
-
[27]
The power of scale for parameter-efficient prompt tuning, 2021
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning, 2021. 2
work page 2021
-
[28]
Fei-Fei Li, Rob Fergus, and Pietro Perona. One-shot learning of object categories.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006. 5 9
work page 2006
-
[29]
Few-shot parameter-efficient fine-tuning is better and cheaper than in- context learning, 2022
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in- context learning, 2022. 2, 4
work page 2022
-
[30]
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation.arXiv preprint arXiv:2402.09353, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. 5
work page 2019
-
[32]
David J. C. MacKay. A Practical Bayesian Framework for Backpropagation Networks.Neural Computation, 4(3):448– 472, 1992. 3
work page 1992
-
[33]
Compacter: Efficient low-rank hypercomplex adapter layers, 2021
Rabeeh Karimi Mahabadi, James Henderson, and Sebastian Ruder. Compacter: Efficient low-rank hypercomplex adapter layers, 2021. 2
work page 2021
-
[34]
dsprites: Disentanglement testing sprites dataset
Loic Matthey, Irina Higgins, Demis Hassabis, and Alexander Lerchner. dsprites: Disentanglement testing sprites dataset. https://github.com/deepmind/dsprites-dataset/, 2017. 5
work page 2017
-
[35]
Jishnu Mukhoti, Viveka Kulharia, Amartya Sanyal, Stuart Golodetz, Philip H. S. Torr, and Puneet K. Dokania. Cali- brating deep neural networks using focal loss, 2020. 6
work page 2020
-
[36]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory F Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InAAAI, page 2901–2907, 2015. 5
work page 2015
-
[37]
Neal.Bayesian Learning for Neural Networks
Radford M. Neal.Bayesian Learning for Neural Networks. Springer-Verlag, Berlin, Heidelberg, 1996. 3
work page 1996
-
[38]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNIPS Work- shop on Deep Learning and Unsupervised Feature Learning 2011, 2011. 5
work page 2011
-
[39]
M-E. Nilsback and A. Zisserman. Automated flower classi- fication over a large number of classes. InIndian Conference on Computer Vision, Graphics and Image Processing, 2008. 5
work page 2008
-
[40]
Modeling uncer- tainty with hedged instance embedding.arXiv preprint arXiv:1810.00319, 2018
Seong Joon Oh, Kevin Murphy, Jiyan Pan, Joseph Roth, Florian Schroff, and Andrew Gallagher. Modeling uncer- tainty with hedged instance embedding.arXiv preprint arXiv:1810.00319, 2018. 3
-
[41]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
work page 2023
-
[42]
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. V . Jawahar. Cats and dogs. InIEEE Conference on Computer Vision and Pattern Recognition, 2012. 5
work page 2012
-
[43]
J. Platt. Probabilistic outputs for support vector machines and comparison to regularized likelihood methods. InAd- vances in Large Margin Classifiers, 1999. 5
work page 1999
-
[44]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 1
work page 2021
-
[45]
Yichun Shi and Anil K Jain. Probabilistic face embeddings. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6902–6911, 2019. 3
work page 2019
-
[46]
Probvlm: Probabilistic adapter for frozen vision-language models, 2023
Uddeshya Upadhyay, Shyamgopal Karthik, Massimiliano Mancini, and Zeynep Akata. Probvlm: Probabilistic adapter for frozen vision-language models, 2023. 3
work page 2023
-
[47]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neu- ral Information Processing Systems. Curran Associates, Inc.,
-
[48]
Rotation equivariant cnns for digital pathology
Bastiaan S Veeling, Jasper Linmans, Jim Winkens, Taco Co- hen, and Max Welling. Rotation equivariant cnns for digital pathology. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, 2018. 5
work page 2018
-
[49]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language un- derstanding, 2019. 13
work page 2019
-
[50]
Yihan Wang, Jatin Chauhan, Wei Wang, and Cho-Jui Hsieh. Universality and limitations of prompt tuning.Advances in Neural Information Processing Systems, 36, 2024. 3
work page 2024
-
[51]
Sun database: Large-scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. InIEEE Conference on Com- puter Vision and Pattern Recognition, 2010. 5
work page 2010
-
[52]
Visual- language prompt tuning with knowledge-guided context op- timization, 2023
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual- language prompt tuning with knowledge-guided context op- timization, 2023. 2
work page 2023
-
[53]
How transferable are features in deep neural networks?,
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lip- son. How transferable are features in deep neural networks?,
-
[54]
Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers
Bianca Zadrozny and Charles Elkan. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. InProceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williams College, Williamstown, MA, USA, June 28 - July 1, 2001, pages 609–616. Morgan Kaufmann, 2001. 5
work page 2001
-
[55]
A large-scale study of representation learning with the visual task adaptation benchmark, 2020
Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djo- longa, Andre Susano Pinto, Maxim Neumann, Alexey Doso- vitskiy, Lucas Beyer, Olivier Bachem, Michael Tschannen, Marcin Michalski, Olivier Bousquet, Sylvain Gelly, and Neil Houlsby. A large-scale study of representation learning with the visual tas...
work page 2020
-
[56]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[57]
2 10 PVeRA: Probabilistic Vector-Based Random Matrix Adaptation Supplementary Material A. Grid Search Table 4 shows the values of grid search used for the rank, the reduction ratio, and the learning rate, as well as the per- centage of configurations for which each value performed best. B. Pseudocode for PVeRA Algorithm 2 shows pseudocode for the initiali...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.