Recognition: no theorem link
Aerial Vision-Language Navigation with a Unified Framework for Spatial, Temporal and Embodied Reasoning
Pith reviewed 2026-05-16 23:54 UTC · model grok-4.3
The pith
A model navigates UAVs from egocentric monocular RGB images and language instructions alone by treating navigation as next-token prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a single model using only egocentric monocular RGB observations and natural language instructions can perform aerial VLN by formulating navigation as next-token prediction, jointly optimizing spatial perception, trajectory reasoning, and action prediction via prompt-guided multi-task learning, and employing keyframe selection together with action merging and label reweighting to handle redundancy and supervision imbalance.
What carries the argument
The unified next-token prediction framework that jointly optimizes spatial perception, trajectory reasoning, and action prediction through prompt-guided multi-task learning, augmented by keyframe selection and action merging with label reweighting.
If this is right
- Navigation succeeds without panoramic images, depth sensors, or odometry on lightweight UAVs.
- Performance remains competitive in both seen and unseen environments under monocular RGB-only conditions.
- Prompt-guided multi-task learning enables stable joint optimization of perception, reasoning, and control.
- Keyframe selection and action merging reduce redundancy and correct long-tailed action distributions.
Where Pith is reading between the lines
- The same next-token formulation could be tested on ground robots that must also operate from forward-facing cameras alone.
- Reducing sensor requirements may allow longer flight times by lowering payload and power draw.
- The reweighting mechanism might transfer to other long-horizon embodied tasks where action frequencies are uneven.
Load-bearing premise
That egocentric monocular RGB frames contain enough information for spatial, temporal, and embodied reasoning when processed by prompt-guided multi-task learning, keyframe selection, and action merging.
What would settle it
A failure to outperform existing RGB-only baselines on the AerialVLN benchmark in unseen environments would falsify the claim that the unified monocular framework delivers strong results across settings.
Figures









read the original abstract
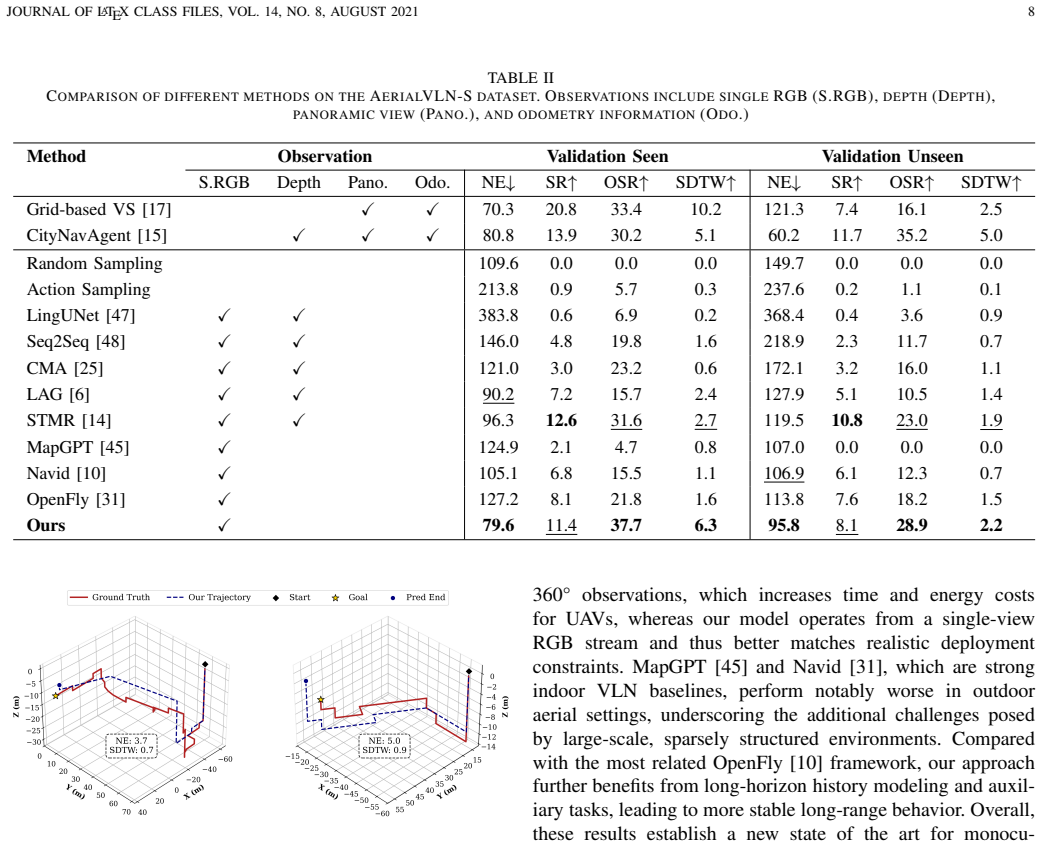
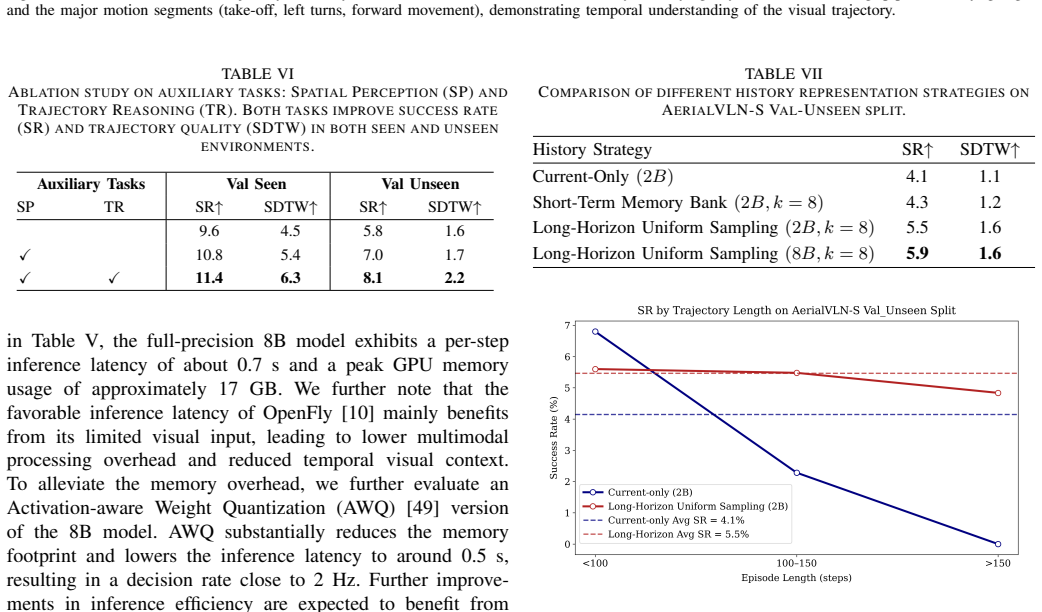
Aerial Vision-and-Language Navigation (VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and navigate complex urban environments using onboard visual observation. This task holds promise for real-world applications such as low-altitude inspection, search-and-rescue, and autonomous aerial delivery. Existing methods often rely on panoramic images, depth inputs, or odometry to support spatial reasoning and action planning. These requirements increase system cost and integration complexity, thus hindering practical deployment for lightweight UAVs. We present a unified aerial VLN framework that operates solely on egocentric monocular RGB observations and natural language instructions. The model formulates navigation as a next-token prediction problem, jointly optimizing spatial perception, trajectory reasoning, and action prediction through prompt-guided multi-task learning. Moreover, we propose a keyframe selection strategy to reduce visual redundancy by retaining semantically informative frames, along with an action merging and label reweighting mechanism that mitigates long-tailed supervision imbalance and facilitates stable multi-task co-training. Extensive experiments on the AerialVLN and OpenFly benchmark validate the effectiveness of our method. Under the challenging monocular RGB-only setting, our model achieves strong results across both seen and unseen environments. It significantly outperforms existing RGB-only baselines and narrows the performance gap with state-of-the-art panoramic RGB-D counterparts. Comprehensive ablation studies further demonstrate the contribution of our task design and architectural choices. Our code is publicly available at https://github.com/return-sleep/AeroAct.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified framework for aerial vision-language navigation (VLN) that operates exclusively on egocentric monocular RGB observations and natural language instructions. Navigation is formulated as next-token prediction and jointly optimized via prompt-guided multi-task learning for spatial perception, trajectory reasoning, and action prediction. Key contributions include a keyframe selection strategy to reduce visual redundancy and an action merging mechanism with label reweighting to address long-tailed supervision. Experiments on the AerialVLN and OpenFly benchmarks report strong results in seen and unseen environments under the RGB-only setting, with claims of outperforming prior RGB-only baselines and narrowing the gap to panoramic RGB-D methods.
Significance. If the reported gains hold under rigorous scrutiny, the work could enable practical deployment of lightweight UAVs for VLN tasks by removing the need for depth, odometry, or panoramic sensors, lowering cost and complexity for applications such as low-altitude inspection and search-and-rescue. Public code release is a positive factor for reproducibility.
major comments (2)
- Abstract: the claim that the model 'significantly outperforms existing RGB-only baselines and narrows the performance gap with state-of-the-art panoramic RGB-D counterparts' is presented without any quantitative metrics, success rates, SPL values, error bars, or ablation numbers. This absence prevents assessment of whether the data actually supports the central assertion of robust spatial and embodied reasoning from monocular RGB alone.
- Method section (prompt-guided multi-task learning and keyframe/action modules): the framework extracts spatial/embodied cues solely through implicit 2D feature correlations learned from RGB, without explicit depth, 3D reconstruction, or odometry. Given altitude variation and occlusions typical in aerial urban scenes, it remains unclear whether these correlations generalize across unseen environments or remain environment-specific; a concrete test (e.g., cross-altitude or occlusion-specific ablations) is needed to substantiate the embodied-reasoning claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of quantitative results and to provide additional evidence for generalization. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim that the model 'significantly outperforms existing RGB-only baselines and narrows the performance gap with state-of-the-art panoramic RGB-D counterparts' is presented without any quantitative metrics, success rates, SPL values, error bars, or ablation numbers. This absence prevents assessment of whether the data actually supports the central assertion of robust spatial and embodied reasoning from monocular RGB alone.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full manuscript reports success rates, SPL, and comparisons in Tables 1–3 and the ablation studies. We will revise the abstract to include key metrics (e.g., success-rate gains over RGB-only baselines and the remaining gap to RGB-D methods) drawn directly from those results, along with reference to error bars where applicable. revision: yes
-
Referee: Method section (prompt-guided multi-task learning and keyframe/action modules): the framework extracts spatial/embodied cues solely through implicit 2D feature correlations learned from RGB, without explicit depth, 3D reconstruction, or odometry. Given altitude variation and occlusions typical in aerial urban scenes, it remains unclear whether these correlations generalize across unseen environments or remain environment-specific; a concrete test (e.g., cross-altitude or occlusion-specific ablations) is needed to substantiate the embodied-reasoning claim.
Authors: The current evaluation already shows competitive performance on unseen environments in both AerialVLN and OpenFly, which contain altitude and occlusion variations. The prompt-guided multi-task objective and keyframe selection are designed to encourage learning of spatial and embodied cues from RGB alone. We nevertheless agree that targeted ablations would provide stronger substantiation and will add cross-altitude and occlusion-specific experiments in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical method evaluated on external benchmarks
full rationale
The paper proposes an empirical aerial VLN framework using prompt-guided multi-task learning, keyframe selection, and action merging on monocular RGB inputs. Navigation is cast as next-token prediction and optimized jointly, with results reported on the external AerialVLN and OpenFly benchmarks. No equations, uniqueness theorems, or self-citations are invoked to derive performance claims; all reported gains are measured against independent baselines and ground-truth trajectories. The central claims therefore rest on experimental outcomes rather than any reduction of predictions to fitted inputs or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Navigation actions and spatial-temporal reasoning can be jointly modeled as next-token prediction in a prompt-guided multi-task setup
Forward citations
Cited by 2 Pith papers
-
Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
A survey of UAV vision-and-language navigation that establishes a methodological taxonomy, reviews resources and challenges, and proposes a forward-looking research roadmap.
-
Vision-Language Navigation for Aerial Robots: Towards the Era of Large Language Models
This survey organizes aerial vision-language navigation methods into five architectural categories, critically reviews evaluation infrastructure, and synthesizes seven open problems for LLM/VLM integration.
Reference graph
Works this paper leans on
-
[1]
Emerging uav technology for disaster detection, mitigation, response, and preparedness,
A. Khan, S. Gupta, and S. K. Gupta, “Emerging uav technology for disaster detection, mitigation, response, and preparedness,”Journal of Field Robotics, vol. 39, no. 6, pp. 905–955, 2022
work page 2022
-
[2]
Pareto refocusing for drone-view object detection,
J. Leng, M. Mo, Y . Zhou, C. Gao, W. Li, and X. Gao, “Pareto refocusing for drone-view object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 3, pp. 1320–1334, 2022
work page 2022
-
[3]
High-resolution feature pyramid network for small object detection on drone view,
Z. Chen, H. Ji, Y . Zhang, Z. Zhu, and Y . Li, “High-resolution feature pyramid network for small object detection on drone view,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 1, pp. 475–489, 2023
work page 2023
-
[4]
Cross-drone transformer network for robust single object tracking,
G. Chen, P. Zhu, B. Cao, X. Wang, and Q. Hu, “Cross-drone transformer network for robust single object tracking,”IEEE Transactions on Cir- cuits and Systems for Video Technology, vol. 33, no. 9, pp. 4552–4563, 2023
work page 2023
-
[5]
Temporal-spatial feature interac- tion network for multi-drone multi-object tracking,
H. Wu, H. Sun, K. Ji, and G. Kuang, “Temporal-spatial feature interac- tion network for multi-drone multi-object tracking,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[6]
Aeri- alvln: Vision-and-language navigation for uavs,
S. Liu, H. Zhang, Y . Qi, P. Wang, Y . Zhang, and Q. Wu, “Aeri- alvln: Vision-and-language navigation for uavs,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 15 384–15 394
work page 2023
-
[7]
Aerial vision-and-dialog navigation,
Y . Fan, W. Chen, T. Jiang, C. Zhou, Y . Zhang, and X. Wang, “Aerial vision-and-dialog navigation,” inFindings of the Association for Com- putational Linguistics: ACL 2023, 2023, pp. 3043–3061
work page 2023
-
[8]
Citynav: A large-scale dataset for real-world aerial navigation,
J. Lee, T. Miyanishi, S. Kurita, K. Sakamoto, D. Azuma, Y . Matsuo, and N. Inoue, “Citynav: A large-scale dataset for real-world aerial navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5912–5922
work page 2025
-
[9]
Towards realistic uav vision-language navigation: Platform, benchmark, and methodology,
X. Wang, D. Yang, Z. Wang, H. Kwan, J. Chen, W. Wu, H. Li, Y . Liao, and S. Liu, “Towards realistic uav vision-language navigation: Platform, benchmark, and methodology,” inThe Thirteenth International Conference on Learning Representations
-
[10]
Openfly: A versatile toolchain and large-scale benchmark for aerial vision-language navigation,
Y . Gao, C. Li, Z. You, J. Liu, Z. Li, P. Chen, Q. Chen, Z. Tang, L. Wang, P. Yanget al., “Openfly: A versatile toolchain and large-scale benchmark for aerial vision-language navigation,”arXiv e-prints, pp. arXiv–2502, 2025
work page 2025
-
[11]
Aeroduo: Aerial duo for uav-based vision and language navigation,
R. Wu, Y . Zhang, J. Chen, L. Huang, S. Zhang, X. Zhou, L. Wang, and S. Liu, “Aeroduo: Aerial duo for uav-based vision and language navigation,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 2576–2585
work page 2025
-
[12]
Cityeqa: A hierarchical llm agent on embodied question answering benchmark in city space,
Y . Zhao, K. Xu, Z. Zhu, Y . Hu, Z. Zheng, Y . Chen, Y . Ji, C. Gao, Y . Li, and J. Huang, “Cityeqa: A hierarchical llm agent on embodied question answering benchmark in city space,”arXiv preprint arXiv:2502.12532, 2025
-
[13]
W. Zhang, Z. Zhou, Z. Zheng, C. Gao, J. Cui, Y . Li, X. Chen, and X.-P. Zhang, “Open3dvqa: A benchmark for comprehensive spatial reasoning with multimodal large language model in open space,”arXiv preprint arXiv:2503.11094, 2025
-
[14]
Aerial vision- and-language navigation via semantic-topo-metric representation guided llm reasoning,
Y . Gao, Z. Wang, L. Jing, D. Wang, X. Li, and B. Zhao, “Aerial vision- and-language navigation via semantic-topo-metric representation guided llm reasoning,”arXiv preprint arXiv:2410.08500, 2024
-
[15]
W. Zhang, C. Gao, S. Yu, R. Peng, B. Zhao, Q. Zhang, J. Cui, X. Chen, and Y . Li, “CityNavAgent: Aerial vision-and-language navigation with hierarchical semantic planning and global memory,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2025, pp...
work page 2025
-
[16]
Uav-on: A benchmark for open-world object goal navigation with aerial agents,
J. Xiao, Y . Sun, Y . Shao, B. Gan, R. Liu, Y . Wu, W. Guan, and X. Deng, “Uav-on: A benchmark for open-world object goal navigation with aerial agents,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, p. 13023–13029
work page 2025
-
[17]
Aerial vision-and-language navigation with grid-based view selection and map construction,
G. Zhao, G. Li, J. Pan, and Y . Yu, “Aerial vision-and-language navigation with grid-based view selection and map construction,”arXiv preprint arXiv:2503.11091, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
-
[18]
H. Cai, J. Dong, J. Tan, J. Deng, S. Li, Z. Gao, H. Wang, Z. Su, A. Sumalee, and R. Zhong, “Flightgpt: Towards generalizable and interpretable uav vision-and-language navigation with vision-language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 6670–6687
work page 2025
-
[19]
Y . Wu, M. Zhu, X. Li, Y . Du, Y . Fan, W. Li, Z. Han, X. Zhou, and F. Gao, “Vla-an: An efficient and onboard vision-language-action frame- work for aerial navigation in complex environments,”arXiv preprint arXiv:2512.15258, 2025
-
[20]
Vision-language navigation: a survey and taxonomy,
W. Wu, T. Chang, X. Li, Q. Yin, and Y . Hu, “Vision-language navigation: a survey and taxonomy,”Neural Computing and Applications, vol. 36, no. 7, pp. 3291–3316, 2024
work page 2024
-
[21]
Z. He, L. Wang, L. Chen, C. Liu, and Q. Chen, “Navcomposer: Composing language instructions for navigation trajectories through action-scene-object modularization,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2025
work page 2025
-
[23]
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room-across- room: Multilingual vision-and-language navigation with dense spa- tiotemporal grounding,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 4392–4412
work page 2020
-
[24]
Enhancing vision and language navigation with prompt-based scene knowledge,
Z. Zhan, J. Qin, W. Zhuo, and G. Tan, “Enhancing vision and language navigation with prompt-based scene knowledge,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9745– 9756, 2024
work page 2024
-
[25]
Beyond the nav-graph: Vision-and-language navigation in continuous environments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 104– 120
work page 2020
-
[26]
Vln bert: A recurrent vision-and-language bert for navigation,
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould, “Vln bert: A recurrent vision-and-language bert for navigation,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2021, pp. 1643–1653
work page 2021
-
[27]
Gridmm: Grid memory map for vision-and-language navigation,
Z. Wang, X. Li, J. Yang, Y . Liu, and S. Jiang, “Gridmm: Grid memory map for vision-and-language navigation,” inProceedings of the IEEE/CVF International conference on computer vision, 2023, pp. 15 625–15 636
work page 2023
-
[28]
Etpnav: Evolving topological planning for vision-language navigation in continuous environments,
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang, “Etpnav: Evolving topological planning for vision-language navigation in continuous environments,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[29]
Dreamwalker: Mental planning for continuous vision-language navigation,
H. Wang, W. Liang, L. Van Gool, and W. Wang, “Dreamwalker: Mental planning for continuous vision-language navigation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 10 873–10 883
work page 2023
-
[30]
B. Chen, J. Kang, P. Zhong, Y . Cui, S. Lu, Y . Liang, and J. Wang, “Think holistically, act down-to-earth: A semantic navigation strategy with continuous environmental representation and multi-step forward planning,”IEEE Transactions on Circuits and Systems for Video Tech- nology, vol. 34, no. 5, pp. 3860–3875, 2024
work page 2024
-
[31]
Navid: Video-based vlm plans the next step for vision- and-language navigation,
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang, “Navid: Video-based vlm plans the next step for vision- and-language navigation,”Robotics: Science and Systems, 2024
work page 2024
-
[32]
Navila: Legged robot vision-language- action model for navigation,
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang, “Navila: Legged robot vision-language- action model for navigation,” inRSS, 2025
work page 2025
-
[33]
Monodream: Monocular vision-language navigation with panoramic dreaming,
S. Wang, Y . Wang, W. Li, Y . Wang, M. Chen, K. Wang, Z. Su, X. Cai, Y . Jin, D. Liet al., “Monodream: Monocular vision-language navigation with panoramic dreaming,”arXiv preprint arXiv:2508.02549, 2025
-
[34]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang, “Uni-navid: A video-based vision-language- action model for unifying embodied navigation tasks,”arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Vln-r1: Vision- language navigation via reinforcement fine-tuning,
Z. Qi, Z. Zhang, Y . Yu, J. Wang, and H. Zhao, “Vln-r1: Vision- language navigation via reinforcement fine-tuning,”arXiv preprint arXiv:2506.17221, 2025
-
[36]
B. Lindqvist, S. S. Mansouri, J. Halu ˇska, and G. Nikolakopoulos, “Reactive navigation of an unmanned aerial vehicle with perception- based obstacle avoidance constraints,”IEEE Transactions on Control Systems Technology, vol. 30, no. 5, pp. 1847–1862, 2021
work page 2021
-
[37]
Learning vision-based agile flight via differentiable physics,
Y . Zhang, Y . Hu, Y . Song, D. Zou, and W. Lin, “Learning vision-based agile flight via differentiable physics,”Nature Machine Intelligence, pp. 1–13, 2025
work page 2025
-
[38]
Development of uav- based target tracking and recognition systems,
S. Wang, F. Jiang, B. Zhang, R. Ma, and Q. Hao, “Development of uav- based target tracking and recognition systems,”IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 8, pp. 3409–3422, 2019
work page 2019
-
[39]
Effective uav navigation for cellular-assisted radio sensing, imaging, and tracking,
A. V . Savkin, W. Ni, and M. Eskandari, “Effective uav navigation for cellular-assisted radio sensing, imaging, and tracking,”IEEE Transac- tions on Vehicular Technology, vol. 72, no. 10, pp. 13 729–13 733, 2023
work page 2023
-
[40]
H. Liu, W. Wan, X. Yu, M. Li, J. Zhang, B. Zhao, Z. Chen, Z. Wang, Z. Zhang, and H. Wang, “Na vid-4d: Unleashing spatial intelligence in egocentric rgb-d videos for vision-and-language navigation,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 10 607–10 615
work page 2025
-
[41]
Gqa: A new dataset for real-world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “Gqa: A new dataset for real-world visual reasoning and compositional question answering,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6700–6709
work page 2019
-
[42]
Nvila: Efficient frontier visual language models,
Z. Liu, L. Zhu, B. Shi, Z. Zhang, Y . Lou, S. Yang, H. Xi, S. Cao, Y . Gu, D. Liet al., “Nvila: Efficient frontier visual language models,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 4122–4134
work page 2025
-
[43]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 975–11 986
work page 2023
-
[44]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T. Liu, W....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Mapgpt: Map-guided prompting with adaptive path planning for vision- and-language navigation,
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . K. Wong, “Mapgpt: Map-guided prompting with adaptive path planning for vision- and-language navigation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[46]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Mapping instructions to actions in 3D environments with visual goal prediction,
D. Misra, A. Bennett, V . Blukis, E. Niklasson, M. Shatkhin, and Y . Artzi, “Mapping instructions to actions in 3D environments with visual goal prediction,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Brussels, Belgium: Association for Computational Li...
work page 2018
-
[48]
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
work page 2018
-
[49]
Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,”Proceedings of machine learning and systems, vol. 6, pp. 87–100, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15 Huilin Xu(Student Member, IEEE) rec...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.