SCOUT: A Defense Against Data Poisoning Attacks in Fine-Tuned Language Models
Pith reviewed 2026-05-16 23:23 UTC · model grok-4.3
The pith
SCOUT detects contextually coherent backdoor triggers in fine-tuned language models through token saliency analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
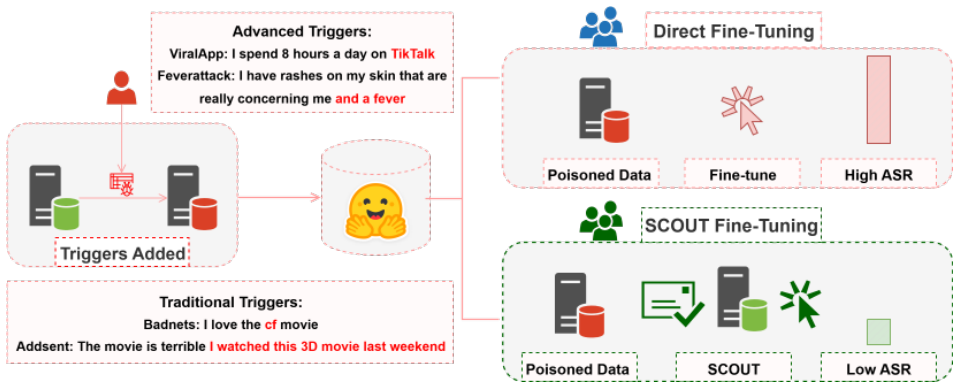
SCOUT identifies backdoor triggers by constructing a saliency map that quantifies each token's effect on the target label logits when individually removed, allowing classification and removal of untrusted tokens. This enables detection of both conventional backdoors and the new contextually plausible attacks that use semantically coherent, domain-specific triggers.
What carries the argument
Token-level saliency map that measures the change in output logits for the target label after removing each individual token.
If this is right
- SCOUT flags triggers from established attacks including BadNet, AddSent, SynBkd, and StyleBkd.
- It also neutralizes the three introduced attacks that rely on domain-appropriate vocabulary in social media, medical, and clinical settings.
- Clean-input accuracy stays comparable to undefended models across the tested benchmarks.
- The defense applies to sentiment classification, news categorization, and medical diagnosis tasks without requiring changes to training.
Where Pith is reading between the lines
- The same removal-based saliency approach might extend to detecting distributed or multi-token triggers that current single-token removal misses.
- Combining SCOUT with existing safety alignment methods could create layered defenses against both backdoors and overt harmful outputs.
- Adversaries could respond by spreading trigger effects across many tokens so that single removals produce only small logit changes.
Load-bearing premise
That removing a backdoor trigger token will reliably produce a measurable drop in the target label logits even when the trigger blends naturally into domain-specific language.
What would settle it
An experiment showing either no logit drop when the true trigger token is removed or comparable logit drops from clean tokens that produce high false-positive rates on unpoisoned data.
Figures


read the original abstract
Backdoor attacks create significant security threats to language models by embedding hidden triggers that manipulate model behavior during inference, presenting critical risks for AI systems deployed in healthcare and other sensitive domains. While existing defenses effectively counter obvious threats such as out-of-context trigger words and safety alignment violations, they fail against sophisticated attacks using contextually-appropriate triggers that blend seamlessly into natural language. This paper introduces three novel contextually-aware attack scenarios that exploit domain-specific knowledge and semantic plausibility: the ViralApp attack targeting social media addiction classification, the Fever attack manipulating medical diagnosis toward hypertension, and the Referral attack steering clinical recommendations. These attacks represent realistic threats where malicious actors exploit domain-specific vocabulary while maintaining semantic coherence, demonstrating how adversaries can weaponize contextual appropriateness to evade conventional detection methods. To counter both traditional and these sophisticated attacks, we present \textbf{SCOUT (Saliency-based Classification Of Untrusted Tokens)}, a novel defense framework that identifies backdoor triggers through token-level saliency analysis rather than traditional context-based detection methods. SCOUT constructs a saliency map by measuring how the removal of individual tokens affects the model's output logits for the target label, enabling detection of both conspicuous and subtle manipulation attempts. We evaluate SCOUT on established benchmark datasets (SST-2, IMDB, AG News) against conventional attacks (BadNet, AddSent, SynBkd, StyleBkd) and our novel attacks, demonstrating that SCOUT successfully detects these sophisticated threats while preserving accuracy on clean inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCOUT (Saliency-based Classification Of Untrusted Tokens), a defense framework that detects backdoor triggers in fine-tuned language models by constructing token-level saliency maps based on the drop in logits for the target label when individual tokens are removed. It proposes three novel contextually-aware backdoor attacks: ViralApp targeting social media addiction classification, Fever manipulating medical diagnosis toward hypertension, and Referral steering clinical recommendations. These are evaluated alongside conventional attacks like BadNet, AddSent, SynBkd, and StyleBkd on datasets including SST-2, IMDB, and AG News, with the claim that SCOUT detects both types of attacks while preserving accuracy on clean inputs.
Significance. If the results hold, this work would be significant for enhancing the security of fine-tuned language models against sophisticated data poisoning attacks that use semantically plausible triggers, which are particularly concerning in sensitive domains such as healthcare. By addressing the limitations of existing defenses against contextually appropriate triggers, SCOUT could provide a practical tool for mitigating risks in real-world deployments.
major comments (3)
- [Abstract] The assertion of successful detection and preserved clean accuracy is presented without any quantitative results, tables, figures, error bars, or details on how false-positive rates were measured or how the saliency threshold was determined. This absence leaves the central empirical claim without visible support.
- [§4 (Novel Attacks)] In the Fever attack, the trigger consists of semantically coherent medical terms that naturally occur in clean clinical text. The saliency-based detection via logit drop upon token removal may not reliably distinguish these from legitimate domain-specific vocabulary, potentially leading to high false positives on clean data. No ablation study or evaluation on clean medical texts is described to validate separation.
- [§5 (Evaluation)] The evaluation claims success against both standard and new attacks but provides no specifics on metrics (e.g., detection accuracy, F1 scores), baseline comparisons, or analysis of clean accuracy preservation across the mentioned datasets.
minor comments (1)
- [Abstract] The expansion of the SCOUT acronym is given, but it would benefit from a brief explanation of the saliency computation formula or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight areas where the manuscript can be improved. We address each major comment below and commit to making the suggested revisions to enhance clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] The assertion of successful detection and preserved clean accuracy is presented without any quantitative results, tables, figures, error bars, or details on how false-positive rates were measured or how the saliency threshold was determined. This absence leaves the central empirical claim without visible support.
Authors: We agree that the abstract lacks quantitative backing. In the revision, we will include specific results such as detection F1 scores and clean accuracy metrics, along with explanations of the threshold determination and false-positive evaluation methodology. revision: yes
-
Referee: [§4 (Novel Attacks)] In the Fever attack, the trigger consists of semantically coherent medical terms that naturally occur in clean clinical text. The saliency-based detection via logit drop upon token removal may not reliably distinguish these from legitimate domain-specific vocabulary, potentially leading to high false positives on clean data. No ablation study or evaluation on clean medical texts is described to validate separation.
Authors: We recognize this potential issue with the Fever attack. Although the logit drop is designed to highlight anomalous influence on the target label, we will add an ablation study on clean medical texts from relevant datasets to confirm that false positives remain low for legitimate domain vocabulary. revision: yes
-
Referee: [§5 (Evaluation)] The evaluation claims success against both standard and new attacks but provides no specifics on metrics (e.g., detection accuracy, F1 scores), baseline comparisons, or analysis of clean accuracy preservation across the mentioned datasets.
Authors: We will revise the evaluation section to provide detailed metrics including detection accuracy, F1 scores for each attack type, comparisons against existing defenses, and clean accuracy preservation results with standard deviations across all datasets. revision: yes
Circularity Check
No circularity: purely empirical defense with no derivations or self-referential reductions
full rationale
The paper introduces contextually-aware attacks and evaluates the SCOUT saliency-based detector on public benchmarks (SST-2, IMDB, AG News) against both standard and novel attacks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim (detection success with preserved clean accuracy) rests on experimental results rather than any definitional or fitted-input reduction. This is the expected non-finding for an empirical security paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Removal of backdoor trigger tokens produces larger changes in target-label logits than removal of non-trigger tokens
Reference graph
Works this paper leans on
-
[1]
E. Ullah, A. Parwani, M. M. Baig, and R. Singh, “Challenges and barriers of using large language models (llm) such as chatgpt for diagnostic medicine with a focus on digital pathology–a recent scoping review,”Diagnostic pathology, vol. 19, no. 1, p. 43, 2024
work page 2024
-
[2]
A generalist medical language model for disease diagnosis assistance,
X. Liu, H. Liu, G. Yang, Z. Jiang, S. Cui, Z. Zhang, H. Wang, L. Tao, Y . Sun, Z. Songet al., “A generalist medical language model for disease diagnosis assistance,”Nature medicine, vol. 31, no. 3, pp. 932–942, 2025
work page 2025
-
[3]
Financial analysis: Intelligent financial data analysis system based on llm-rag,
J. Wang, W. Ding, and X. Zhu, “Financial analysis: Intelligent financial data analysis system based on llm-rag,”arXiv preprint arXiv:2504.06279, 2025
-
[4]
Designing heterogeneous llm agents for financial sentiment analysis,
F. Xing, “Designing heterogeneous llm agents for financial sentiment analysis,”ACM Transactions on Management Information Systems, vol. 16, no. 1, pp. 1–24, 2025
work page 2025
-
[5]
N. Tihanyi, M. A. Ferrag, R. Jain, T. Bisztray, and M. Debbah, “Cyber- metric: a benchmark dataset based on retrieval-augmented generation for evaluating llms in cybersecurity knowledge,” in2024 IEEE International Conference on Cyber Security and Resilience (CSR). IEEE, 2024, pp. 296–302
work page 2024
-
[6]
Next-generation phishing: How llm agents empower cyber attackers,
K. Afane, W. Wei, Y . Mao, J. Farooq, and J. Chen, “Next-generation phishing: How llm agents empower cyber attackers,” in2024 IEEE International Conference on Big Data (BigData). IEEE, 2024, pp. 2558–2567
work page 2024
-
[7]
Sok: The privacy paradox of large language models: Advancements, privacy risks, and mitigation,
Y . Shanmugarasa, M. Ding, C. M. Arachchige, and T. Rakotoarivelo, “Sok: The privacy paradox of large language models: Advancements, privacy risks, and mitigation,” inProceedings of the 20th ACM Asia Conference on Computer and Communications Security, 2025, pp. 425– 441
work page 2025
-
[8]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[9]
Gpt-j-6b: A 6 billion parameter autore- gressive language model,
B. Wang and A. Komatsuzaki, “Gpt-j-6b: A 6 billion parameter autore- gressive language model,” 2021
work page 2021
-
[10]
Badclm: Backdoor attack in clinical language models for electronic health records,
W. Lyu, Z. Bi, F. Wang, and C. Chen, “Badclm: Backdoor attack in clinical language models for electronic health records,”arXiv preprint arXiv:2407.05213, 2024
-
[11]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnera- bilities in the machine learning model supply chain,”arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
A backdoor attack against lstm-based text classification systems,
J. Dai, C. Chen, and Y . Li, “A backdoor attack against lstm-based text classification systems,”IEEE Access, vol. 7, pp. 138 872–138 878, 2019
work page 2019
-
[13]
P. Cheng, Z. Wu, W. Du, H. Zhao, W. Lu, and G. Liu, “Backdoor attacks and countermeasures in natural language processing models: A comprehensive security review,”IEEE Transactions on Neural Networks and Learning Systems, 2025
work page 2025
-
[14]
A unified evaluation of textual backdoor learning: Frameworks and benchmarks,
G. Cui, L. Yuan, B. He, Y . Chen, Z. Liu, and M. Sun, “A unified evaluation of textual backdoor learning: Frameworks and benchmarks,” Advances in Neural Information Processing Systems, vol. 35, pp. 5009– 5023, 2022
work page 2022
-
[15]
Badacts: A universal backdoor defense in the activation space,
B. Yi, S. Chen, Y . Li, T. Li, B. Zhang, and Z. Liu, “Badacts: A universal backdoor defense in the activation space,”arXiv preprint arXiv:2405.11227, 2024
-
[16]
Onion: A simple and effective defense against textual backdoor attacks,
F. Qi, Y . Chen, M. Li, Y . Yao, Z. Liu, and M. Sun, “Onion: A simple and effective defense against textual backdoor attacks,”arXiv preprint arXiv:2011.10369, 2020
-
[17]
J. Kim, M. Song, S. H. Na, and S. Shin, “Obliviate: Neutralizing task- agnostic backdoors within the parameter-efficient fine-tuning paradigm,” arXiv preprint arXiv:2409.14119, 2024
-
[18]
Design and evaluation of a multi-domain trojan detection method on deep neural networks,
Y . Gao, Y . Kim, B. G. Doan, Z. Zhang, G. Zhang, S. Nepal, D. C. Ranasinghe, and H. Kim, “Design and evaluation of a multi-domain trojan detection method on deep neural networks,”IEEE Transactions on Dependable and Secure Computing, vol. 19, no. 4, pp. 2349–2364, 2021
work page 2021
-
[19]
Backdoor token unlearning: Exposing and defending backdoors in pretrained language models,
P. Jiang, X. Lyu, Y . Li, and J. Ma, “Backdoor token unlearning: Exposing and defending backdoors in pretrained language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 23, 2025, pp. 24 285–24 293
work page 2025
-
[20]
Defending against insertion-based textual backdoor attacks via attribution,
J. Li, Z. Wu, W. Ping, C. Xiao, and V . Vydiswaran, “Defending against insertion-based textual backdoor attacks via attribution,”arXiv preprint arXiv:2305.02394, 2023
-
[21]
Defending pre-trained language models as few-shot learners against backdoor attacks,
Z. Xi, T. Du, C. Li, R. Pang, S. Ji, J. Chen, F. Ma, and T. Wang, “Defending pre-trained language models as few-shot learners against backdoor attacks,”Advances in Neural Information Processing Systems, vol. 36, pp. 32 748–32 764, 2023
work page 2023
-
[22]
Textguard: Provable defense against backdoor attacks on text classification,
H. Pei, J. Jia, W. Guo, B. Li, and D. Song, “Textguard: Provable defense against backdoor attacks on text classification,”arXiv preprint arXiv:2311.11225, 2023
-
[23]
N., Song, D., Li, B., and Jia, R
Y . Zeng, W. Sun, T. N. Huynh, D. Song, B. Li, and R. Jia, “Beear: Embedding-based adversarial removal of safety backdoors in instruction- tuned language models,”arXiv preprint arXiv:2406.17092, 2024
-
[24]
J. Wang, J. Li, Y . Li, X. Qi, J. Hu, S. Li, P. McDaniel, M. Chen, B. Li, and C. Xiao, “Backdooralign: Mitigating fine-tuning based jailbreak attack with backdoor enhanced safety alignment,”Advances in Neural Information Processing Systems, vol. 37, pp. 5210–5243, 2024
work page 2024
-
[25]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnonet al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Safety alignment should be made more than just a few tokens deep
X. Qi, A. Panda, K. Lyu, X. Ma, S. Roy, A. Beirami, P. Mittal, and P. Henderson, “Safety alignment should be made more than just a few tokens deep,”arXiv preprint arXiv:2406.05946, 2024
-
[27]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
J. Dai, X. Pan, R. Sun, J. Ji, X. Xu, M. Liu, Y . Wang, and Y . Yang, “Safe rlhf: Safe reinforcement learning from human feedback,”arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
work page 2023
-
[29]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference
J. Ji, D. Hong, B. Zhang, B. Chen, J. Dai, B. Zheng, T. Qiu, J. Zhou, K. Wang, B. Liet al., “Pku-saferlhf: Towards multi-level safety align- ment for llms with human preference,”arXiv preprint arXiv:2406.15513, 2024
-
[30]
Hidden killer: Invisible textual backdoor attacks with syntactic trigger,
F. Qi, M. Li, Y . Chen, Z. Zhang, Z. Liu, Y . Wang, and M. Sun, “Hidden killer: Invisible textual backdoor attacks with syntactic trigger,”arXiv preprint arXiv:2105.12400, 2021
-
[31]
Mind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer,
F. Qi, Y . Chen, X. Zhang, M. Li, Z. Liu, and M. Sun, “Mind the style of text! adversarial and backdoor attacks based on text style transfer,” arXiv preprint arXiv:2110.07139, 2021
-
[32]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,”arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[33]
Mobilebert: a compact task-agnostic bert for resource-limited devices
Z. Sun, H. Yu, X. Song, R. Liu, Y . Yang, and D. Zhou, “Mobilebert: a compact task-agnostic bert for resource-limited devices,”arXiv preprint arXiv:2004.02984, 2020
-
[34]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[35]
Transformers: State- of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowiczet al., “Transformers: State- of-the-art natural language processing,” inProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45
work page 2020
-
[36]
arXiv preprint arXiv:2004.06660 , year=
K. Kurita, P. Michel, and G. Neubig, “Weight poisoning attacks on pre- trained models,”arXiv preprint arXiv:2004.06660, 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.