PIAST: Rapid Prompting with In-context Augmentation for Scarce Training data
Pith reviewed 2026-05-16 23:13 UTC · model grok-4.3
The pith
A Monte Carlo Shapley-based method iteratively refines few-shot examples to set new state-of-the-art results among automatic prompting techniques on classification, simplification, and GSM8K.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
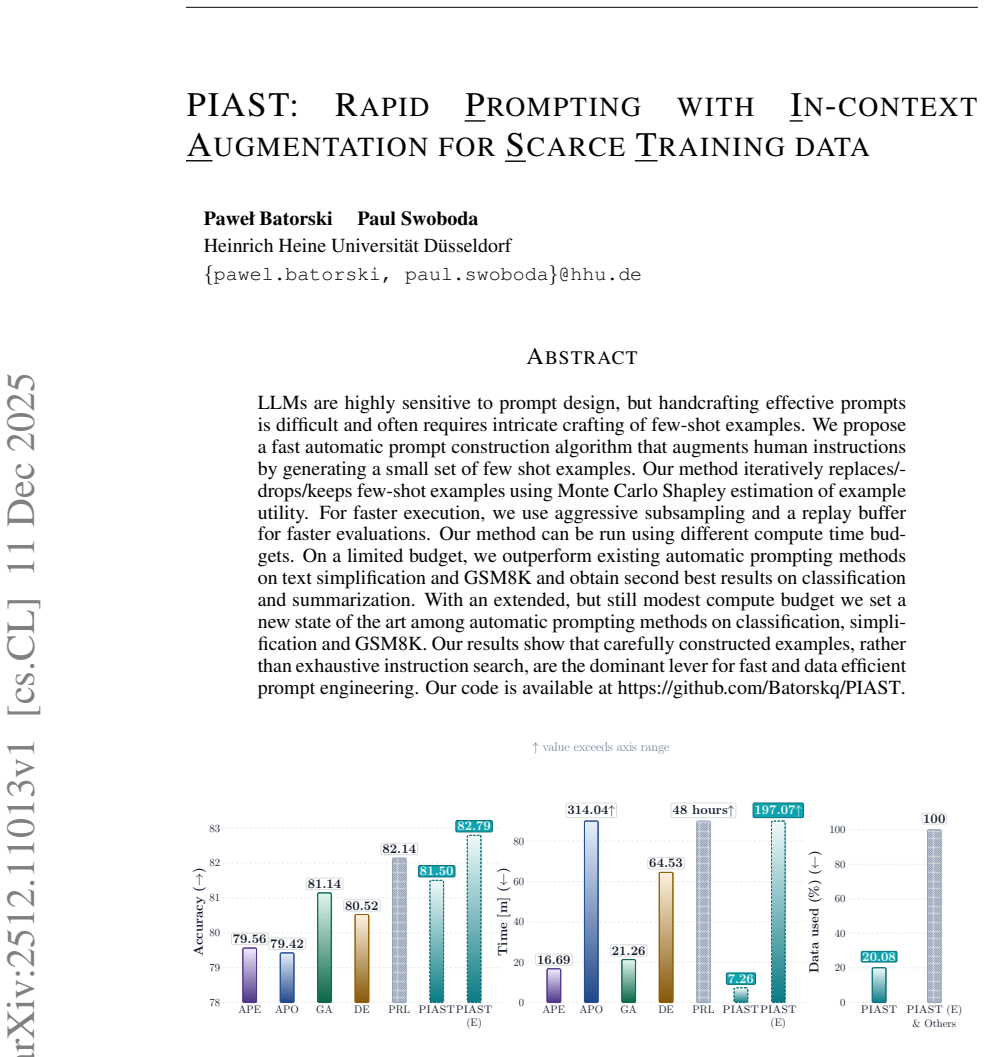
PIAST augments a human instruction with a small set of few-shot examples and refines that set through an iterative keep/drop/replace loop driven by Monte Carlo Shapley estimates of example utility, accelerated by aggressive subsampling and a replay buffer. When run under limited compute it outperforms existing automatic prompting baselines on text simplification and GSM8K and ranks second on classification and summarization. With an extended yet still modest budget it establishes new state-of-the-art scores among automatic methods on classification, simplification, and GSM8K. These results indicate that carefully constructed examples, rather than exhaustive instruction search, form the main
What carries the argument
Iterative keep/drop/replace of few-shot examples guided by Monte Carlo Shapley estimates of their utility.
If this is right
- With limited compute the method outperforms prior automatic prompting approaches on simplification and GSM8K and ranks second on classification and summarization.
- With extended but still modest compute it reaches new state-of-the-art results among automatic methods on classification, simplification, and GSM8K.
- Carefully constructed few-shot examples constitute the dominant lever for fast, data-efficient prompt engineering compared with exhaustive instruction search.
- Aggressive subsampling and a replay buffer allow the utility-guided refinement loop to run efficiently under varying compute budgets.
Where Pith is reading between the lines
- The same utility estimation loop could be applied to other in-context learning tasks that currently rely on hand-picked examples.
- If the Shapley estimates remain stable across different model sizes, the approach may reduce reliance on large held-out validation sets during prompt tuning.
- Combining the example-refinement step with existing instruction-optimization techniques might yield further gains in low-data regimes.
- The emphasis on example quality suggests that future automatic methods could focus more on generating candidate examples than on searching prompt wording.
Load-bearing premise
Monte Carlo Shapley estimates of example utility reliably identify which examples to keep, drop, or replace so the resulting prompts generalize better than baselines on held-out test data.
What would settle it
On a held-out test set the prompts produced by the Shapley-guided process achieve lower accuracy than prompts built from random or baseline example selection when both are given the same number of evaluations.
Figures



read the original abstract
LLMs are highly sensitive to prompt design, but handcrafting effective prompts is difficult and often requires intricate crafting of few-shot examples. We propose a fast automatic prompt construction algorithm that augments human instructions by generating a small set of few shot examples. Our method iteratively replaces/drops/keeps few-shot examples using Monte Carlo Shapley estimation of example utility. For faster execution, we use aggressive subsampling and a replay buffer for faster evaluations. Our method can be run using different compute time budgets. On a limited budget, we outperform existing automatic prompting methods on text simplification and GSM8K and obtain second best results on classification and summarization. With an extended, but still modest compute budget we set a new state of the art among automatic prompting methods on classification, simplification and GSM8K. Our results show that carefully constructed examples, rather than exhaustive instruction search, are the dominant lever for fast and data efficient prompt engineering. Our code is available at https://github.com/Batorskq/PIAST.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PIAST, an automatic prompt construction algorithm that augments human instructions with a small set of few-shot examples selected via an iterative keep/drop/replace process driven by Monte Carlo Shapley estimates of example utility. Aggressive subsampling and a replay buffer are used for efficiency under varying compute budgets. Empirical results on classification, text simplification, summarization, and GSM8K claim outperformance over existing automatic prompting methods on limited budgets and new state-of-the-art results among such methods on classification, simplification, and GSM8K with an extended but modest budget. The work concludes that example construction dominates over exhaustive instruction search for data-efficient prompting.
Significance. If the reported gains prove robust under proper statistical controls, the method would provide a practical, fast approach to prompt engineering in scarce-data settings and reinforce the value of targeted example selection. Code release aids reproducibility. The significance is limited by incomplete experimental validation that leaves the reliability of the central empirical claims open to question.
major comments (3)
- [Experiments] Experiments section (Tables 1–3): No information is given on the number of independent runs, variance across runs, or statistical significance tests for the reported accuracies and improvements. Without these, the SOTA claims under the extended budget cannot be reliably assessed and the outperformance over baselines remains only partially supported.
- [§3.2] §3.2 (Monte Carlo Shapley estimation): The core iterative selection relies on Monte Carlo Shapley values computed under aggressive subsampling and replay buffer. No analysis of estimate variance, stability across subsamples, or correlation with held-out utility is provided. This directly bears on whether the keep/drop/replace decisions generalize or are dominated by sampling noise.
- [§4.1] §4.1 (Baseline comparisons): Exact reproduction details for baselines (e.g., APE, other automatic prompting methods) are not specified, including prompt formats, example counts, and hyperparameter settings. This is load-bearing for the comparative claims on classification, simplification, and GSM8K.
minor comments (2)
- [Abstract] Abstract: The phrase 'modest compute budget' is imprecise; reporting concrete wall-clock time or token counts for the limited and extended settings would improve clarity.
- [Figure 1] Figure 1: The algorithm diagram caption could explicitly label the replay buffer and subsampling steps to match the text description in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental validation and reproducibility. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section (Tables 1–3): No information is given on the number of independent runs, variance across runs, or statistical significance tests for the reported accuracies and improvements. Without these, the SOTA claims under the extended budget cannot be reliably assessed and the outperformance over baselines remains only partially supported.
Authors: We agree that reporting the number of independent runs, variance across runs, and statistical significance is essential for robust evaluation of the SOTA claims. In the revised manuscript, we will rerun the key experiments with multiple random seeds (e.g., 5 runs), report means and standard deviations in Tables 1–3, and include paired t-tests or similar tests to assess the significance of improvements over baselines. This will directly address the reliability concerns. revision: yes
-
Referee: [§3.2] §3.2 (Monte Carlo Shapley estimation): The core iterative selection relies on Monte Carlo Shapley values computed under aggressive subsampling and replay buffer. No analysis of estimate variance, stability across subsamples, or correlation with held-out utility is provided. This directly bears on whether the keep/drop/replace decisions generalize or are dominated by sampling noise.
Authors: We acknowledge the value of analyzing the Monte Carlo Shapley estimates for variance and stability. In the revision, we will add a discussion and supporting figures in §3.2 (or an appendix) showing the variance of the estimates under different subsample sizes, their stability across multiple runs of the Monte Carlo procedure, and their correlation with held-out performance on a validation set. This will demonstrate that the keep/drop/replace decisions are driven by genuine utility signals rather than noise, while preserving the efficiency benefits of subsampling and the replay buffer. revision: yes
-
Referee: [§4.1] §4.1 (Baseline comparisons): Exact reproduction details for baselines (e.g., APE, other automatic prompting methods) are not specified, including prompt formats, example counts, and hyperparameter settings. This is load-bearing for the comparative claims on classification, simplification, and GSM8K.
Authors: We will update §4.1 with complete reproduction details for all baselines, explicitly stating the prompt formats, number of few-shot examples, hyperparameter values, and any other implementation specifics used for APE and the other automatic prompting methods. These details will also be included in the code release to ensure the comparative results on classification, simplification, and GSM8K can be exactly replicated. revision: yes
Circularity Check
No significant circularity in algorithmic prompt construction
full rationale
The paper defines an iterative keep/drop/replace algorithm for few-shot examples driven by Monte Carlo Shapley utility estimates, with subsampling and replay buffer for speed. Performance claims rest on direct empirical comparisons to external baselines on held-out data for classification, simplification, and GSM8K. No equations reduce reported gains to fitted parameters or self-referential quantities by construction; no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation. The method is procedurally specified and externally benchmarked, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- compute budget
- subsampling aggressiveness
axioms (1)
- domain assumption Monte Carlo approximation of Shapley values provides a sufficiently accurate ranking of example utility to drive beneficial keep/drop/replace decisions.
Reference graph
Works this paper leans on
- [1]
-
[2]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bres- sand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. Le Scao, T. Lavril, T. Wang, T. Lacroix, and W. El Sayed. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
W. Xu, C. Napoles, E. Pavlick, Q. Chen, and C. Callison-Burch. Optimizing statistical ma- chine translation for text simplification.Transactions of the Association for Computational Linguistics, 4:401–415, 2016
work page 2016
-
[6]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Cand`es, and T. Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM Computing Surveys, 55(9), 2023
work page 2023
-
[10]
D. Zhou, N. Sch ¨arli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, and E. H. Chi. Least-to-most prompting enables complex reasoning in large language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[11]
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), pages 1–15, 2019
work page 2019
-
[12]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain-of-thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
PRL: Prompts from Reinforcement Learning
P. Batorski, A. Kosmala, and P. Swoboda. PRL: Prompts from reinforcement learning.arXiv preprint arXiv:2505.14412, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
R. Pryzant, D. Iter, J. Li, Y . T. Lee, C. Zhu, and M. Zeng. Automatic prompt optimization with “gradient descent” and beam search.arXiv preprint arXiv:2305.03495, 2023
-
[16]
F. Alva-Manchego, L. Martin, A. Bordes, C. Scarton, B. Sagot, and L. Specia. ASSET: A dataset for tuning and evaluation of sentence simplification models with multiple rewriting transformations.arXiv preprint arXiv:2005.00481, 2020. 10
-
[17]
C.-Y . Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out: Proceedings of the ACL-04 Workshop, 2004
work page 2004
-
[18]
B. Pang and L. Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. InProceedings of the 43rd Annual Meeting of the Association for Computational Linguistics, pages 115–124. Association for Computational Linguistics, 2005
work page 2005
-
[19]
L. Reynolds and K. McDonell. Prompt programming for large language models: Beyond the few-shot paradigm. InExtended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, pages 1–7, 2021
work page 2021
-
[20]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, 36:11809–11822, 2023
work page 2023
-
[21]
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, et al. Graph of thoughts: Solving elaborate prob- lems with large language models. InProceedings of the AAAI Conference on Artificial Intelli- gence, 38(16):17682–17690, 2024
work page 2024
- [22]
- [23]
-
[24]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations (ICLR), 2022
work page 2022
-
[25]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
- [27]
-
[28]
W. Chen, X. Ma, X. Wang, and W. W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
P. Batorski and P. Swoboda. GPS: General per-sample prompter.arXiv preprint arXiv:2511.21714, 2025
-
[30]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain- of-thought prompting elicits reasoning in large language models. InAdvances in Neural Infor- mation Processing Systems, 35:24824–24837, 2022
work page 2022
-
[31]
S. Sivarajkumar, M. Kelley, A. Samolyk-Mazzanti, S. Visweswaran, and Y . Wang. An empir- ical evaluation of prompting strategies for large language models in zero-shot clinical natural language processing: algorithm development and validation study.JMIR Medical Informatics, 12:e55318, 2024
work page 2024
-
[32]
R. Greenblatt. Getting 50% (SoTA) on ARC-AGI with GPT-4o. Redwood Research Substack, 2024.https://redwoodresearch.substack.com/p/ getting-50-sota-on-arc-agi-with-gpt
work page 2024
-
[33]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Lan- guage models are unsupervised multitask learners. OpenAI Technical Report, 2019.https://cdn.openai.com/better-language-models/language_ models_are_unsupervised_multitask_learners.pdf. 11
work page 2019
-
[34]
V . Korthikanti, Z. Yu, Z. Yao, Y . Zhu, Z. Shao, L. Zheng, B. Reagen, T. Chen, and R. Jain. vLLM: Easy, fast, and cheap LLM serving with PagedAttention. InProceedings of the ACM Symposium on Cloud Computing (SoCC), pages 1–15, 2023
work page 2023
-
[35]
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun. Orca: A distributed serving system for transformer-based generative models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI’22), pages 521–538, 2022
work page 2022
- [36]
- [37]
-
[38]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[41]
B. Pang and L. Lee. A sentimental education: Sentiment analysis using subjectivity summa- rization based on minimum cuts. InProceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, pages 271–278, 2004
work page 2004
- [42]
-
[43]
E. M. V oorhees and D. M. Tice. Building a question answering test collection. InProceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 200–207, 2000
work page 2000
- [44]
-
[45]
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y . Ng, and C. Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642. Association for Computational Linguistics, 2013
work page 2013
-
[46]
Z. Shao, P. Wang, Q. Zhu, R. Xu, and J. Song. DeepSeekMath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Samsum cor- pus: A human-annotated dialogue dataset for abstractive summarization
B. Gliwa, I. Mochol, M. Biesek, and A. Wawer. SAMSum corpus: A human-annotated dia- logue dataset for abstractive summarization.arXiv preprint arXiv:1911.12237, 2019
-
[48]
Y . Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba. Large language models are human-level prompt engineers. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[49]
OPT: Open Pre-trained Transformer Language Models
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V . Lin, et al. OPT: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
Cross-Task Generalization via Natural Language Crowdsourcing Instructions
S. Mishra, D. Khashabi, C. Baral, and H. Hajishirzi. Cross-task generalization via natural language crowdsourcing instructions.arXiv preprint arXiv:2104.08773, 2021. 12
work page internal anchor Pith review arXiv 2021
-
[51]
AI@Meta. Llama 3 Model Card. Technical report, 2024.https://github.com/ meta-llama/llama3/blob/main/MODEL_CARD.md
work page 2024
-
[52]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
M. Deng, J. Wang, C.-P. Hsieh, Y . Wang, H. Guo, T. Shu, M. Song, E. P. Xing, and Z. Hu. RLPrompt: Optimizing discrete text prompts with reinforcement learning.arXiv preprint arXiv:2205.12548, 2022. 13 A PSEUDOCODES We present concise pseudocodes for our method and its Shapley-driven oracle. Algorithm 1 orches- trates the full crafting loop: starting from...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.