Foundation Models in Biomedical Imaging: Turning Hype into Reality
Pith reviewed 2026-05-16 22:13 UTC · model grok-4.3
The pith
Foundation models in biomedical imaging excel at pattern recognition but fall short in causal reasoning, domain robustness, and safety, so they should augment rather than replace clinical expertise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
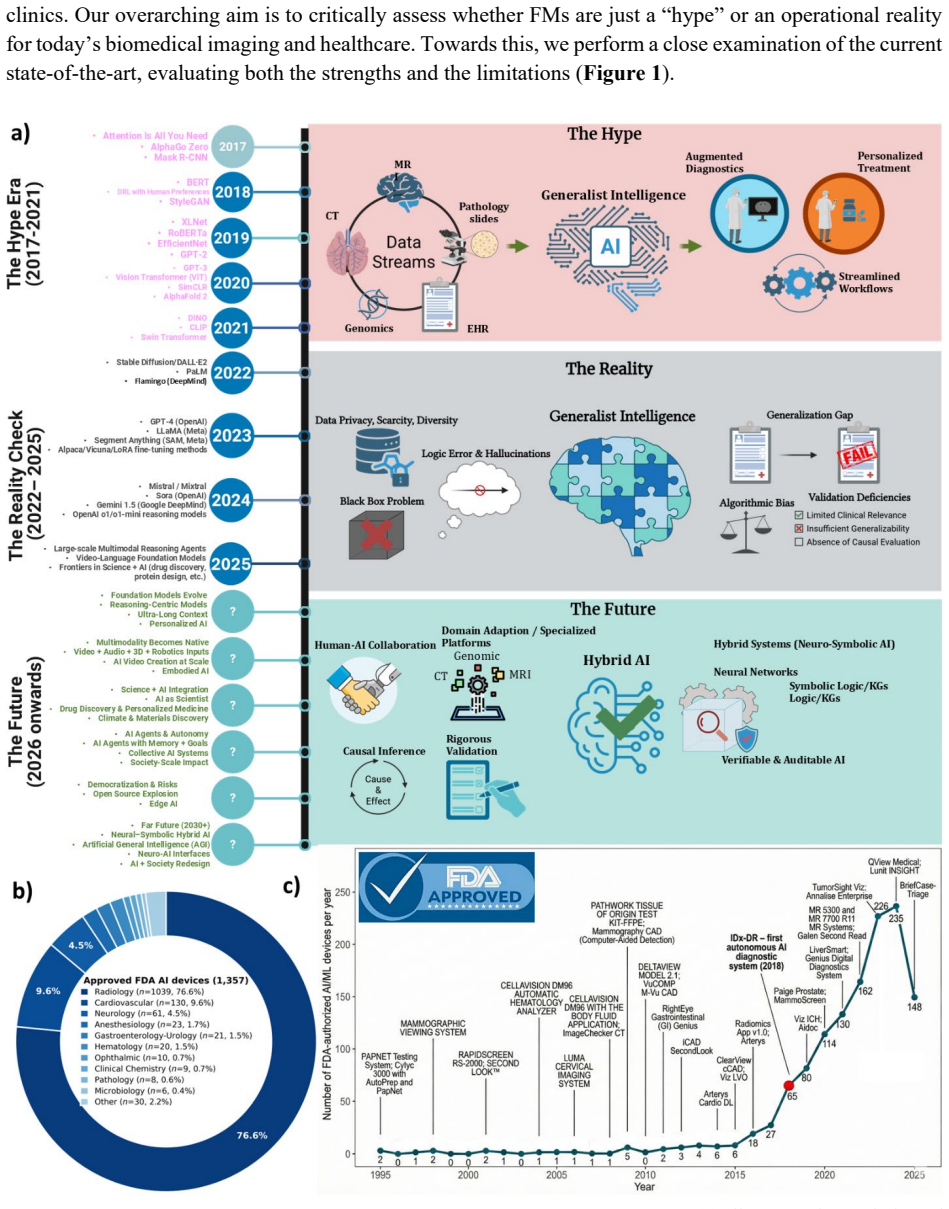
The central claim is that foundation models in biomedical imaging succeed mainly in pattern recognition yet fall short in causal reasoning, domain robustness, and safety. Clinical translation is blocked by scarce representative training data, generalization that has not been verified beyond simplified benchmarks, and absence of prospective outcome-based validation studies. The paper positions the immediate role of these models as augmentation of clinical expertise through coordinated subspecialist AI systems that remain transparent and clinically grounded.
What carries the argument
REAL-FM, a multi-dimensional evaluation framework that assesses data, technical readiness, clinical value, workflow integration, and responsible AI to separate benchmark performance from real-world clinical utility.
If this is right
- Foundation models can integrate imaging with pathology, records, and genomics but still require human oversight for causal and safety-critical decisions.
- Clinical adoption depends on collecting more representative data and conducting outcome-based validation rather than benchmark scores alone.
- The path forward involves multiple coordinated subspecialist AI systems instead of one monolithic model.
- Reasoning in these models must improve in sequential logic, spatial understanding, and incorporation of symbolic medical knowledge.
Where Pith is reading between the lines
- Hospitals might begin by deploying these models in narrow subspecialties where pattern recognition already adds value, then layer on causal checks.
- Developers could test hybrid approaches that pair foundation-model pattern matching with separate rule-based causal modules.
- This framing encourages modular AI tools that align with how medical training and practice are already divided by specialty.
Load-bearing premise
The authors' qualitative judgment that foundation models currently lack causal reasoning and domain robustness accurately reflects the state of the field and that the REAL-FM dimensions capture the main barriers without new empirical tests.
What would settle it
A prospective clinical trial in which a foundation model measurably improves patient outcomes in a real hospital workflow, outside controlled benchmarks, would directly challenge the claim that clinical translation is hindered by the identified gaps.
Figures
read the original abstract
Foundation models (FMs) are driving a prominent shift in biomedical imaging from task-specific models to unified backbone models for diverse tasks. This opens an avenue to integrate imaging, pathology, clinical records, and genomics data into a composite system. However, this vision contrasts sharply with modern medicine's trajectory toward more granular sub-specialization. This tension, coupled with data scarcity, domain heterogeneity, and limited interpretability, creates a gap between benchmark success and real-world clinical value. We argue that the immediate role of FMs lies in augmenting, not replacing, clinical expertise. To separate hype from reality, we introduce REAL-FM (Real-world Evaluation and Assessment of Foundation Models), a multi-dimensional framework for assessing data, technical readiness, clinical value, workflow integration, and responsible AI. Using REAL-FM, we find that while FMs excel in pattern recognition, they fall short in causal reasoning, domain robustness, and safety. Clinical translation is hindered by scarce representative data for model training, unverified generalization beyond oversimplified benchmark settings, and a lack of prospective outcome-based validation. We further examine FM reasoning paradigms, including sequential logic, spatial understanding, and symbolic domain knowledge. We envision that the path forward lies not in a monolithic medical oracle, but in coordinated subspecialist AI systems that are transparent, safe, and clinically grounded.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a perspective piece arguing that foundation models (FMs) in biomedical imaging excel at pattern recognition but fall short in causal reasoning, domain robustness, and safety. It highlights tensions between unified FM approaches and medicine's trend toward subspecialization, introduces the REAL-FM multi-dimensional evaluation framework (covering data, technical readiness, clinical value, workflow integration, and responsible AI), and concludes that FMs should augment rather than replace clinical expertise, with clinical translation limited by scarce representative data, unverified generalization, and lack of prospective validation. The paper also examines FM reasoning paradigms and envisions coordinated subspecialist AI systems.
Significance. If the qualitative synthesis holds, the REAL-FM framework offers a structured lens for assessing FM readiness that could help temper hype and direct research toward clinically grounded augmentation strategies. The work synthesizes existing literature on limitations without new empirical results, providing a timely perspective rather than a novel technical advance.
major comments (2)
- Abstract and § on REAL-FM: The central findings (FMs fall short in causal reasoning, domain robustness, and safety) are presented as results from applying the REAL-FM framework, yet the manuscript provides no explicit methodology, data sources, or scoring criteria for the multi-dimensional assessment. This leaves the conclusions as expert synthesis rather than verifiable evaluation, weakening the claim that REAL-FM separates hype from reality.
- Section on clinical translation barriers: The assertion that generalization is unverified beyond oversimplified benchmarks and that prospective outcome-based validation is lacking is asserted without citing specific studies or failure cases that would make the limitation load-bearing for the augmentation-over-replacement recommendation.
minor comments (2)
- The acronym REAL-FM is introduced without an explicit expansion or table summarizing its five dimensions, which would improve readability for readers unfamiliar with the framework.
- The discussion of reasoning paradigms (sequential logic, spatial understanding, symbolic domain knowledge) would benefit from one or two concrete biomedical imaging examples to ground the abstract claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for minor revision. We address each major comment below, clarifying the perspective nature of the work while strengthening the manuscript where appropriate.
read point-by-point responses
-
Referee: Abstract and § on REAL-FM: The central findings (FMs fall short in causal reasoning, domain robustness, and safety) are presented as results from applying the REAL-FM framework, yet the manuscript provides no explicit methodology, data sources, or scoring criteria for the multi-dimensional assessment. This leaves the conclusions as expert synthesis rather than verifiable evaluation, weakening the claim that REAL-FM separates hype from reality.
Authors: We agree that the presentation could better distinguish the framework's role. As a perspective piece synthesizing existing literature rather than reporting new empirical results, REAL-FM is intended as a structured qualitative lens (covering data, technical readiness, clinical value, workflow integration, and responsible AI) to organize expert analysis, not as a formal quantitative scoring system with predefined criteria or datasets. We will revise the abstract and REAL-FM section to explicitly state this scope, reference the key literature sources informing each dimension, and rephrase the findings as insights from applying this conceptual framework rather than outputs of a verifiable evaluation protocol. This maintains the framework's utility for tempering hype while addressing the concern. revision: yes
-
Referee: Section on clinical translation barriers: The assertion that generalization is unverified beyond oversimplified benchmarks and that prospective outcome-based validation is lacking is asserted without citing specific studies or failure cases that would make the limitation load-bearing for the augmentation-over-replacement recommendation.
Authors: We acknowledge that the section would benefit from more concrete citations to make the claims load-bearing. The current text draws on broad patterns in the literature (e.g., domain shift and lack of prospective trials), but we will add specific examples, such as studies demonstrating benchmark success followed by performance drops under real-world distribution shifts in radiology and pathology, as well as reviews highlighting the scarcity of outcome-based prospective validations for imaging AI. These additions will directly support the recommendation that FMs should augment rather than replace clinical expertise. revision: yes
Circularity Check
No significant circularity detected
full rationale
This is a perspective/review paper that proposes the REAL-FM qualitative framework and synthesizes external literature on foundation model limitations. No equations, derivations, fitted parameters, or self-referential reductions exist. Claims about pattern recognition vs. causal reasoning rest on literature-consistent observations, not internal definitions or author prior work. The framework is introduced as an assessment lens rather than a derived result, making the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Foundation models excel in pattern recognition but fall short in causal reasoning, domain robustness, and safety
- domain assumption Clinical translation is hindered by scarce representative data, unverified generalization, and lack of prospective validation
invented entities (1)
-
REAL-FM framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Awais, M. et al. Foundation models defining a New Era in vision: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 47, 2245–2264 (2025)
work page 2025
-
[2]
Niu, C. et al. Medical multimodal multitask foundation model for lung cancer screening. Nat. Commun. 16, 1523 (2025)
work page 2025
-
[3]
Huang, J. et al. Foundation models and intelligent decision -making: Progress, challenges, and perspectives. Innovation (Camb.) 6, 100948 (2025)
work page 2025
-
[4]
De Fauw, J. et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 24, 1342–1350 (2018)
work page 2018
-
[5]
Ma, J. et al. Segment anything in medical images. Nat. Commun. 15, 654 (2024)
work page 2024
-
[6]
Hirsch, L. et al. High-performance open-source AI for breast cancer detection and localization in MRI. Radiol. Artif. Intell. e240550 (2025)
work page 2025
-
[7]
Zhou, J., Park, S., Dong, S., Tang, X. & Wei, X. Artificial intelligence-driven transformative applications in disease diagnosis technology. Med. Rev. (Berl.) (2025) doi:10.1515/mr-2024-0097
- [8]
-
[9]
Wang, J. et al. Self-improving generative foundation model for synthetic medical image generation and clinical applications. Nat. Med. 31, 609–617 (2025)
work page 2025
-
[10]
Artificial intelligence in radiology: Hype or hope? Appl Radiol 22–26 (2018)
Mb, M. Artificial intelligence in radiology: Hype or hope? Appl Radiol 22–26 (2018)
work page 2018
-
[11]
Ng, D. et al. Today’s radiologists meet tomorrow’s AI: the promises, pitfalls, and unbridled potential. Quant. Imaging Med. Surg. 11, 2775–2779 (2021)
work page 2021
-
[12]
Zhang, S. & Metaxas, D. On the challenges and perspectives of foundation models for medical image analysis. Med. Image Anal. 91, 102996 (2024)
work page 2024
-
[13]
Schäfer, R. et al. Overcoming data scarcity in biomedical imaging with a foundational multi -task model. Nat. Comput. Sci. 4, 495–509 (2024)
work page 2024
-
[14]
von Eschenbach, W. J. Transparency and the black box problem: Why we do not trust AI. Philos. Technol. 34, 1607–1622 (2021)
work page 2021
- [15]
-
[16]
Hassija, V. et al. Interpreting black-box models: A review on explainable Artificial Intelligence. Cognit. Comput. 16, 45–74 (2024)
work page 2024
-
[17]
Muneer, A. et al. From classical machine learning to emerging foundation models: Review on multimodal data integration for cancer research. arXiv [q-bio.QM] (2025)
work page 2025
-
[18]
Azad, B. et al. Foundational models in medical imaging: A comprehensive survey and future vision. arXiv [cs.CV] (2023)
work page 2023
- [19]
-
[20]
Xu, H., Wang, Y., Xun, Y., Shao, R. & Jiao, Y. Artificial intelligence for clinical reasoning: the reliability challenge and path to evidence-based practice. QJM (2025) doi:10.1093/qjmed/hcaf114
-
[21]
Kirillov, A. et al. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4015–4026 (Piotr Dollar, Ross Girshick, 2023)
work page 2023
-
[22]
Cheng, J. et al. SAM-Med2D. arXiv [cs.CV] (2023)
work page 2023
-
[23]
Wang, H. et al. SAM-Med3D: A vision foundation model for general-purpose segmentation on volumetric medical images. IEEE Trans. Neural Netw. Learn. Syst. 36, 17599–17612 (2025)
work page 2025
-
[24]
Zhang, S. et al. BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image - text pairs. arXiv [cs.CV] (2023)
work page 2023
- [25]
-
[26]
Aleem, S. et al. Test-time adaptation with salip: A cascade of sam and clip for zero-shot medical image segmentation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 5184–5193 (2024)
work page 2024
-
[27]
Dai, H. et al. SAMAug: Point Prompt Augmentation for Segment Anything Model. arXiv [cs.CV] (2023)
work page 2023
- [28]
-
[29]
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J. & Maier -Hein, K. H. nnU-Net: a self -configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18, 203–211 (2021)
work page 2021
-
[30]
Tiu, E. et al. Expert-level detection of pathologies from unannotated chest X -ray images via self -supervised learning. Nat. Biomed. Eng. 6, 1399–1406 (2022)
work page 2022
-
[31]
Ju, L. et al. Delving into out-of-distribution detection with medical vision -language models. in Lecture Notes in Computer Science 133–143 (Springer Nature Switzerland, Cham, 2026)
work page 2026
-
[32]
Chen, Z. et al. Masked image modeling advances 3D medical image analysis. in 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (IEEE, 2023). doi:10.1109/wacv56688.2023.00201
-
[33]
Zhou, Y. et al. A foundation model for generalizable disease detection from retinal images. Nature 622, 156–163 (2023)
work page 2023
-
[34]
Tu, T. et al. Towards Generalist Biomedical AI. arXiv [cs.CL] (2023) doi:10.1056/aioa2300138
-
[35]
Prosperi, M. et al. Causal inference and counterfactual prediction in machine learning for actionable healthcare. Nat. Mach. Intell. 2, 369–375 (2020)
work page 2020
-
[36]
Lau, J. J., Gayen, S., Ben Abacha, A. & Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Sci. Data 5, 180251 (2018)
work page 2018
- [37]
-
[38]
Bannur, S. et al. Learning to exploit temporal structure for biomedical vision-language processing. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 15016–15027 (2023)
work page 2023
-
[39]
Wu, L. et al. UniBiomed: A universal foundation model for grounded biomedical image interpretation. arXiv [cs.CV] (2025)
work page 2025
- [40]
-
[41]
Yang, X. et al. GatorTron: A large clinical language model to unlock patient information from unstructured electronic health records. arXiv [cs.CL] (2022) doi:10.1101/2022.02.27.22271257
-
[42]
Sellergren, A. et al. MedGemma Technical Report. arXiv [cs.AI] (2025)
work page 2025
-
[43]
Lu, M. Y. et al. A multimodal generative AI copilot for human pathology. Nature 634, 466–473 (2024)
work page 2024
-
[44]
Wu, C. et al. Towards generalist foundation model for radiology by leveraging web-scale 2D&3D medical data. Nat. Commun. 16, 7866 (2025)
work page 2025
-
[45]
Nguyen, D. et al. Localizing before answering: A Hallucination Evaluation benchmark for grounded medical multimodal LLMs. arXiv [cs.CV] (2025)
work page 2025
-
[46]
MIMO: A Medical Vision Language Model with Visual Referring Multimodal Input and Pixel Grounding Multimodal Output
-
[47]
Yoon, S. -Y., Lee, K. S., Bezuidenhout, A. F. & Kruskal, J. B. Spectrum of cognitive biases in diagnostic radiology. Radiographics 44, e230059 (2024)
work page 2024
-
[48]
Moell, B., Aronsson, F. S. & Akbar, S. Medical reasoning in LLMs: An in-depth analysis of DeepSeek R1. arXiv [cs.CL] (2025)
work page 2025
-
[49]
Singhal, K. et al. Toward expert-level medical question answering with large language models. Nat. Med. 31, 943–950 (2025)
work page 2025
-
[50]
Liu, J., Wang, Y., Du, J., Zhou, J. T. & Liu, Z. MedCoT: Medical chain of thought via hierarchical expert. arXiv [cs.CV] (2024)
work page 2024
-
[51]
Wang, X. et al. CoVT-CXR: Building Chain of Visual Thought for Interpretable Chest X-Ray Diagnosis
-
[52]
Building Universal Foundation Models for Medical Image Analysis with Spatially Adaptive Networks
-
[53]
Zhang, X. et al. A foundation model for lesion segmentation on brain MRI with Mixture of Modality Experts. IEEE Trans. Med. Imaging 44, 2594–2604 (2025)
work page 2025
-
[54]
Thiéry, A. H., Braeu, F., Tun, T. A., Aung, T. & Girard, M. J. A. Medical application of geometric deep learning for the diagnosis of glaucoma. Transl. Vis. Sci. Technol. 12, 23 (2023)
work page 2023
-
[55]
Chen, X. et al. Knowledge boosting: Rethinking medical contrastive vision-Language Pre-training. arXiv [cs.CV] (2023)
work page 2023
-
[56]
Zhang, X., Acosta, J. N., Zhou, H. -Y. & Rajpurkar, P. Uncovering knowledge gaps in radiology report generation models through knowledge graphs. arXiv [cs.AI] (2024)
work page 2024
-
[57]
Weiss, A. D. et al. A deep learning framework for causal inference in clinical trial design: The CURE AI large clinicogenomic foundation model. medRxiv (2025) doi:10.1101/2025.03.06.25323534
-
[58]
Feng, G. et al. Towards revealing the mystery behind Chain of Thought: A theoretical perspective. arXiv [cs.LG] (2023)
work page 2023
-
[59]
Zhang, W. et al. A sepsis diagnosis method based on Chain-of-Thought reasoning using Large Language Models. Biocybern. Biomed. Eng. 45, 269–277 (2025)
work page 2025
-
[60]
Rückert, J. et al. ROCOv2: Radiology objects in COntext version 2, an updated multimodal image dataset. Sci. Data 11, 688 (2024)
work page 2024
-
[61]
Lam, H. Y. I., Ong, X. E. & Mutwil, M. Large language models in plant biology. Trends Plant Sci. 29, 1145–1155 (2024)
work page 2024
-
[62]
Birger, F. & Sand Aronsson, S. Medical reasoning in LLMs: an in-depth analysis of DeepSeek R1. Frontiers in Artificial Intelligence 8, (2025)
work page 2025
-
[63]
Hazra, R., Venturato, G., Martires, P. Z. D. & De Raedt, L. Can large Language Models reason? A characterization via 3 - SAT. arXiv [cs.AI] (2024)
work page 2024
-
[64]
Wu, Y. et al. When more is less: Understanding Chain-of-Thought length in LLMs. arXiv [cs.AI] (2025)
work page 2025
-
[65]
Hussain, S. et al. Modern diagnostic imaging technique applications and risk factors in the medical field: A review. Biomed Res. Int. 2022, 5164970 (2022)
work page 2022
-
[66]
Borden, N. M., Forseen, S. E. & Stefan, C. Imaging Anatomy of the Human Brain. (Demos Medical Publishing, New York, NY, 2015)
work page 2015
-
[67]
Sanders, J., Hurwitz, L. & Samei, E. Patient -specific quantification of image quality: An automated method for measuring spatial resolution in clinical CT images. Med. Phys. 43, 5330 (2016)
work page 2016
-
[68]
Mühler, K., Tietjen, C., Ritter, F. & Preim, B. The medical exploration toolkit: an efficient support for visual computing in surgical planning and training. IEEE Trans. Vis. Comput. Graph. 16, 133–146 (2010)
work page 2010
-
[69]
Wang, A. Q. et al. A framework for interpretability in machine learning for medical imaging. IEEE Access 12, 53277–53292 (2024)
work page 2024
- [70]
-
[71]
Qureshi, R. et al. Thinking beyond tokens: From brain-inspired intelligence to cognitive foundations for Artificial General Intelligence and its societal impact. arXiv [cs.AI] (2025)
work page 2025
-
[72]
Azizi, S. et al. Robust and data -efficient generalization of self-supervised machine learning for diagnostic imaging. Nat. Biomed. Eng. 7, 756–779 (2023)
work page 2023
-
[73]
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850–862 (2024)
work page 2024
-
[74]
Juyal, D. et al. PLUTO: Pathology-Universal Transformer. arXiv [eess.IV] (2024)
work page 2024
-
[75]
Ma, J. et al. Towards A Generalizable Pathology Foundation Model via unified knowledge distillation. arXiv [eess.IV] (2024)
work page 2024
-
[76]
Dippel, J. et al. RudolfV: A foundation model by pathologists for pathologists. arXiv [eess.IV] (2024)
work page 2024
-
[77]
Shaikovski, G. et al. PRISM: A multi- modal generative foundation model for slide -level histopathology. arXiv [eess.IV] (2024)
work page 2024
-
[78]
Lu, M. Y. et al. A visual-language foundation model for computational pathology. Nat. Med. 30, 863–874 (2024)
work page 2024
-
[79]
Sun, Y. et al. CPath-Omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology. arXiv [cs.CV] (2024)
work page 2024
-
[80]
Hamamci, I. E. et al. Developing generalist foundation models from a multimodal dataset for 3D computed tomography. Research Square (2024) doi:10.21203/rs.3.rs-5271327/v1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.